Tutoriel : Créer une application Apache Spark avec IntelliJ en utilisant un espace de travail Synapse
Ce tutoriel vous montre comment utiliser le plug-in Azure Toolkit for IntelliJ pour développer des applications Apache Spark, qui sont écrites en Scala, puis les envoyer directement à un pool Apache Spark serverless à partir de l’environnement de développement intégré (IDE) IntelliJ. Vous pouvez utiliser le plug-in de différentes manières :
- Développer et soumettre une application Scala Spark sur un pool Spark.
- Accéder aux ressources de vos pools Spark.
- Développer et exécuter une application Scala Spark localement.
Dans ce tutoriel, vous allez apprendre à :
- Utiliser le plug-in Azure Toolkit for IntelliJ
- Développer des applications Apache Spark
- Envoyer l’application aux pools Spark
Prérequis
Plug-in du kit de ressources Azure 3.27.0-2019.2, à installer à partir du dépôt de plug-ins IntelliJ
Plug-in Scala, à installer à partir du dépôt de plug-ins IntelliJ.
Le prérequis suivant concerne seulement les utilisateurs Windows :
Quand vous exécutez l’application Spark Scala locale sur un ordinateur Windows, vous pouvez obtenir une exception, comme l’explique le document SPARK-2356. Cette exception est liée à l’absence du fichier WinUtils.exe sur Windows. Pour résoudre cette erreur, téléchargez le fichier exécutable WinUtils vers un emplacement tel que C:\WinUtils\bin. Ajoutez ensuite la variable d’environnement HADOOP_HOME et définissez la valeur de la variable sur C:\WinUtils.
Créer une application Spark Scala pour un pool Spark
Démarrez IntelliJ IDEA, puis sélectionnez Create New Project (Créer un projet) pour ouvrir la fenêtre New Project (Nouveau projet).
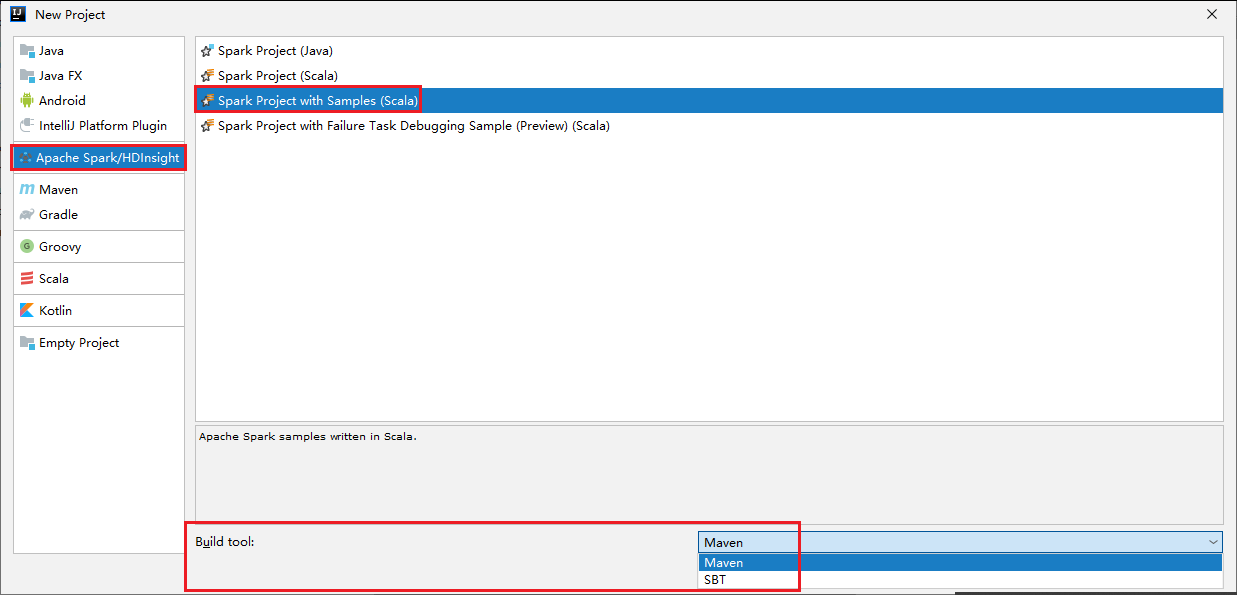
Sélectionnez Apache Spark/HDInsight dans le volet gauche.
Sélectionnez Spark Project avec exemples (Scala) [Projet Spark (Scala)] dans la fenêtre principale.
Dans la liste déroulante Build tool (Outil de build), sélectionnez l’un des types suivants :
- Maven pour la prise en charge de l’Assistant de création de projets Scala.
- SBT pour gérer les dépendances et la génération du projet Scala.
Sélectionnez Suivant.
Dans la fenêtre New Project (Nouveau projet), entrez les informations suivantes :
Propriété Description Nom du projet Entrez un nom. Ce didacticiel utilise myApp.Emplacement du projet Entrez l’emplacement où vous souhaitez enregistrer votre projet. Project SDK (SDK du projet) Ce champ peut être vide si vous utilisez IDEA pour la première fois. Sélectionnez New... (Nouveau) et accédez à votre JDK. Version de Spark L’Assistant de création intègre la version correcte des SDK Spark et Scala. Ici, vous pouvez choisir la version Spark dont vous avez besoin. 
Sélectionnez Terminer. Vous devrez peut-être patienter quelques minutes avant que le projet soit disponible.
Le projet Spark crée automatiquement un artefact. Pour afficher l’artefact, effectuez les opérations suivantes :
a. À partir de la barre de menus, accédez à File>Project Structure.
b. Dans la fenêtre Project Structure, sélectionnez Artifacts.
c. Sélectionnez Cancel (Annuler) après avoir visualisé l’artefact.

Recherchez LogQuery à partir de myApp>src>main>scala>sample>LogQuery. Ce tutoriel utilise LogQuery pour s’exécuter.

Vous connecter à vos pools Spark
Connectez-vous à l’abonnement Azure pour vous connecter à vos pools Spark.
Connectez-vous à votre abonnement Azure :
Dans la barre de menus, accédez à Affichage>Fenêtres Outil>Azure Explorer.

Dans Azure Explorer, cliquez avec le bouton droit sur le nœud Azure, puis sélectionnez Se connecter.

Dans la boîte de dialogue Connexion à Azure, choisissez Connexion à l’appareil, puis sélectionnez Connexion.
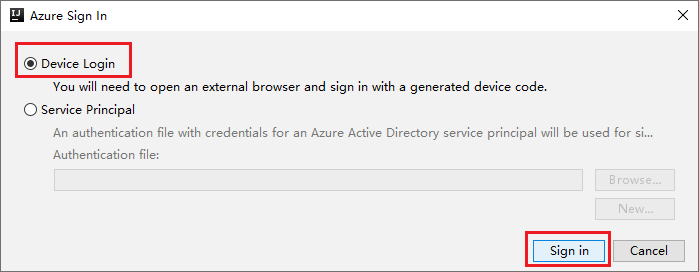
Dans la boîte de dialogue Connexion à l’appareil Azure, sélectionnez Copier et ouvrir.

Dans l’interface du navigateur, collez le code, puis sélectionnez Suivant.

Entrez vos informations d’identification Azure, puis fermez le navigateur.

Une fois que vous êtes connecté, la boîte de dialogue Sélectionner des abonnements répertorie tous les abonnements Azure associés aux informations d’identification. Sélectionnez votre abonnement, puis choisissez Sélectionner.

Dans Azure Explorer, développez Apache Spark on Synapse pour voir les espaces de travail de vos abonnements.

Pour voir les pools Spark, vous pouvez développer un espace de travail.

Exécuter à distance une application Spark Scala sur un pool Spark
Après avoir créé une application Scala, vous pouvez l’exécuter à distance.
Ouvrez la fenêtre Run/Debug Configurations (Exécuter/déboguer les configurations) en sélectionnant l’icône.

Dans la boîte de dialogue Run/Debug Configurations (Exécuter/déboguer les configurations), sélectionnez + , puis sélectionnez Apache Spark on Synapse.

Dans la fenêtre Run/Debug Configurations (Exécuter/déboguer les configurations), entrez les valeurs suivantes, puis sélectionnez OK :
Propriété Valeur Spark pools Sélectionnez les pools Spark sur lesquels vous souhaitez exécuter votre application. Sélectionner un artefact à envoyer Conservez le paramètre par défaut. Main class name La valeur par défaut est la classe principale du fichier sélectionné. Vous pouvez changer la classe en sélectionnant les points de suspension ( ... ), puis en choisissant une autre classe. Configurations du travail Vous pouvez changer la clé et les valeurs par défaut. Pour plus d’informations, consultez API REST Apache Livy. Arguments de ligne de commande Vous pouvez entrer des arguments séparés par un espace pour la classe main, si nécessaire. JAR référencés et fichiers référencés vous pouvez entrer les chemins des fichiers jar et des fichiers référencés, si vous en avez. Vous pouvez également parcourir les fichiers dans le système de fichiers virtuel Azure, qui ne prend en charge que le cluster ADLS Gen2. Pour plus d'informations : Configuration Apache Spark et Guide pratique pour charger des ressources sur un cluster. Stockage des chargements de travaux Développez pour afficher des options supplémentaires. Type de stockage Sélectionnez Utiliser l’objet blob Azure pour charger ou Utiliser le compte de stockage par défaut du cluster pour charger à partir de la liste déroulante. Compte de stockage Entrez votre compte de stockage. Clé de stockage Entrez votre clé de stockage. Conteneur de stockage Sélectionnez votre conteneur de stockage dans la liste déroulante après avoir entré les valeurs Compte de stockage et Clé de stockage. 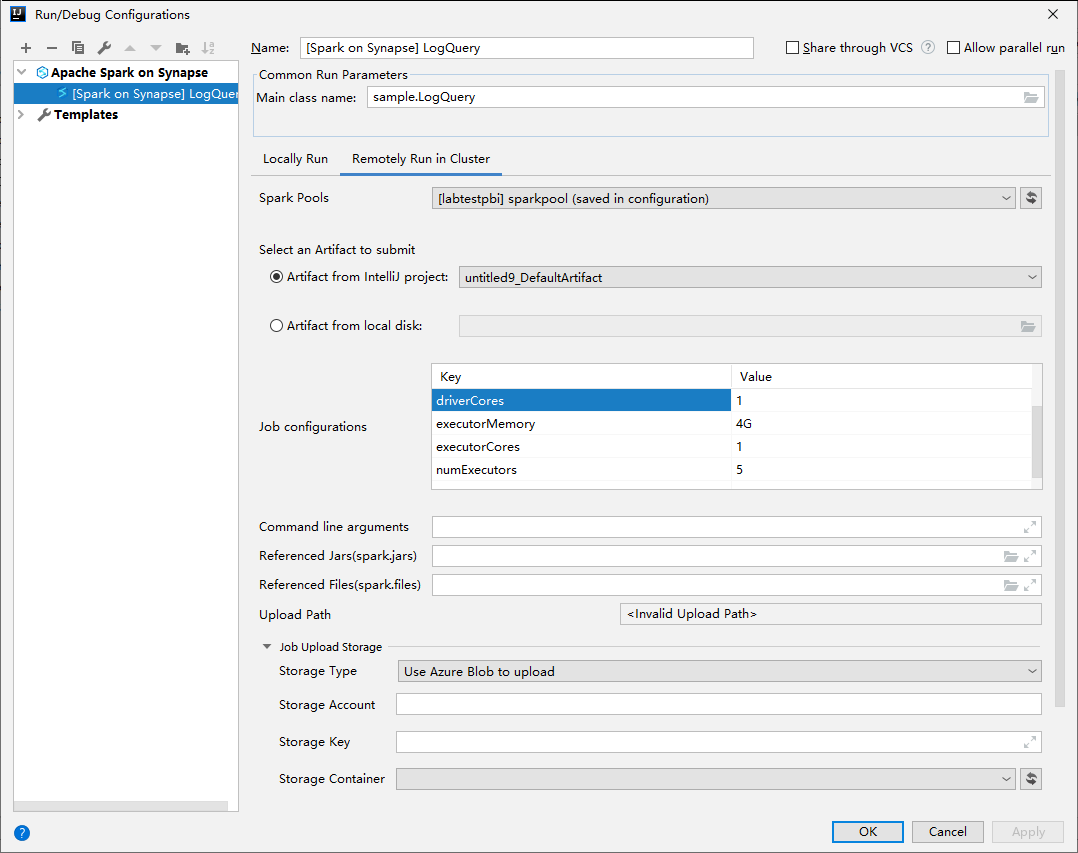
Sélectionnez l’icône SparkJobRun pour envoyer votre projet au pool Spark sélectionné. L’onglet Remote Spark Job in Cluster (Travail Spark distant dans le cluster) affiche la progression de l’exécution du travail au bas de la page. Vous pouvez arrêter l’application en sélectionnant le bouton rouge.


Exécuter et déboguer les applications Apache Spark localement
Vous pouvez suivre les instructions ci-dessous pour configurer l’exécution et le débogage locaux de votre travail Apache Spark.
Scénario 1 : Effectuer une exécution locale
Ouvrez la boîte de dialogue Exécuter/Déboguer les configurations, puis sélectionnez le signe plus (+). Sélectionnez ensuite l’option Apache Spark on Synapse. Entrez les informations sur le nom (Name) et le nom principal de la classe (Main class name) à enregistrer.

- Les variables d’environnement et l’emplacement de WinUtils.exe ne concernent que les utilisateurs Windows.
- Variables d’environnement : la variable d’environnement système peut être détectée automatiquement si vous l’avez définie avant et que vous n’avez pas besoin de l’ajouter manuellement.
- Emplacement de WinUtils.exe : Vous pouvez spécifier l’emplacement de WinUtils en sélectionnant l’icône de dossier à droite.
Sélectionnez ensuite le bouton de lecture locale.

Une fois l’exécution locale terminée, si le script contient une sortie, vous pouvez vérifier le fichier de sortie à partir de data>default.

Scénario 2 : Effectuer un débogage local
Ouvrez le script LogQuery, puis définissez des points d’arrêt.
Sélectionnez l’icône Local debug (Débogage local) pour effectuer le débogage local.

Accéder à l’espace de travail Synapse et le gérer
Vous pouvez effectuer différentes opérations dans Azure Explorer au sein d’Azure Toolkit for IntelliJ. Dans la barre de menus, accédez à Affichage>Fenêtres Outil>Azure Explorer.
Lancer l’espace de travail
Dans Azure Explorer, accédez à Apache Spark on Synapse, puis développez-le.
Cliquez avec le bouton droit sur un espace de travail, puis sélectionnez Launch workspace (Lancer l’espace de travail) ; le site web s’ouvre.


Console Spark
Vous pouvez exécuter la console locale Spark (Scala) ou exécuter la console de sessions interactives Spark Livy (Scala).
Console locale Spark (Scala)
Veillez à respecter les prérequis WINUTILS.EXE.
Dans la barre de menus, accédez à Run>Edit Configurations... .
Dans la fenêtre Run/Debug Configurations (Exécuter/déboguer des configurations), dans le volet gauche, accédez à Apache Spark on Synapse>[Spark on Synapse] myApp.
Dans la fenêtre principale, sélectionnez l’onglet Locally Run.
Entrez les valeurs suivantes, puis sélectionnez OK :
Propriété Valeur Variables d'environnement Vérifiez que la valeur de HADOOP_HOME est correcte. WINUTILS.exe location Vérifiez que le chemin est correct. 
Dans le projet, accédez à myApp>src>main>scala>myApp.
Dans la barre de menus, accédez à Tools>Spark console>Run Spark Local Console(Scala) .
Deux boîtes de dialogue peuvent s’afficher pour vous demander si vous souhaitez corriger automatiquement les dépendances. Si c’est le cas, sélectionnez Correction automatique.

La console doit ressembler à l’image ci-dessous. Dans la fenêtre de la console, tapez
sc.appName, puis appuyez sur Ctrl + Entrée. Le résultat s’affiche. Vous pouvez arrêter l’exécution de la console locale en sélectionnant le bouton rouge.
Console de sessions interactives Spark Livy (Scala)
Elle est uniquement prise en charge sur IntelliJ 2018.2 et 2018.3.
Dans la barre de menus, accédez à Run>Edit Configurations... .
Dans la fenêtre Run/Debug Configurations (Exécuter/déboguer des configurations), dans le volet gauche, accédez à Apache Spark on Synapse>[Spark on Synapse] myApp.
Dans la fenêtre principale, sélectionnez l’onglet Remotely Run in Cluster.
Entrez les valeurs suivantes, puis sélectionnez OK :
Propriété Valeur Main class name Sélectionnez le nom de la classe Main. Spark pools Sélectionnez les pools Spark sur lesquels vous souhaitez exécuter votre application. 
Dans le projet, accédez à myApp>src>main>scala>myApp.
Dans la barre de menus, accédez à Tools>Spark console>Run Spark Livy Interactive Session Console(Scala) .
La console doit ressembler à l’image ci-dessous. Dans la fenêtre de la console, tapez
sc.appName, puis appuyez sur Ctrl + Entrée. Le résultat s’affiche. Vous pouvez arrêter l’exécution de la console locale en sélectionnant le bouton rouge.
Envoyer la sélection vers la console Spark
Vous pouvez voir le résultat du script en envoyant du code vers la console locale ou la console de sessions interactives Livy (Scala). Pour cela, vous pouvez mettre en surbrillance du code dans le fichier Scala, puis cliquer avec le bouton droit sur Send Selection To Spark Console (Envoyer la sélection vers la console Spark). Le code sélectionné est envoyé vers la console pour être exécuté. Le résultat s’affiche après le code dans la console. La console va vérifie les éventuelles erreurs.
