Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
L’équipe Azure Synapse Studio a créé deux nouvelles API de montage/démontage dans le package Microsoft Spark Utilities (mssparkutils). Vous pouvez utiliser ces API pour attacher le stockage à distance (Azure Blob Storage, Azure Data Lake Storage Gen2 ou Azure partage de fichiers) à tous les nœuds de travail (nœud de pilote et nœuds Worker). Une fois le stockage en place, vous pouvez utiliser l’API de fichier local pour accéder aux données comme s’il est stocké dans le système de fichiers local. Pour plus d’informations, consultez Introduction pour Microsoft Utilitaires Spark.
L’article vous montre comment utiliser des API de montage/démontage dans votre espace de travail. Vous apprendrez ce qui suit :
- Comment monter Data Lake Storage Gen2, Blob Storage ou Azure partage de fichiers.
- Comment accéder aux fichiers sous le point de montage via l’API de système de fichiers local.
- Comment accéder aux fichiers sous le point de montage à l’aide de l’API
mssparkutils fs. - Comment accéder aux fichiers sous le point de montage à l’aide de l’API de lecture Spark.
- Comment démonter le point de montage.
Avertissement
Azure Data Lake Storage Gen1 stockage n’est pas pris en charge. Vous pouvez migrer vers Data Lake Storage Gen2 en suivant les instructions de migration de Azure Data Lake Storage Gen1 vers Gen2 avant d’utiliser les API de montage.
Monter le stockage
Cette section montre comment monter Data Lake Storage Gen2 étape par étape comme exemple. Le montage Blob Storage et Azure partage de fichiers fonctionne de la même façon.
L’exemple suppose que vous avez un compte Data Lake Storage Gen2 nommé storegen2. Le compte a un conteneur nommé mycontainer sur lequel vous souhaitez monter /test dans votre pool Spark.
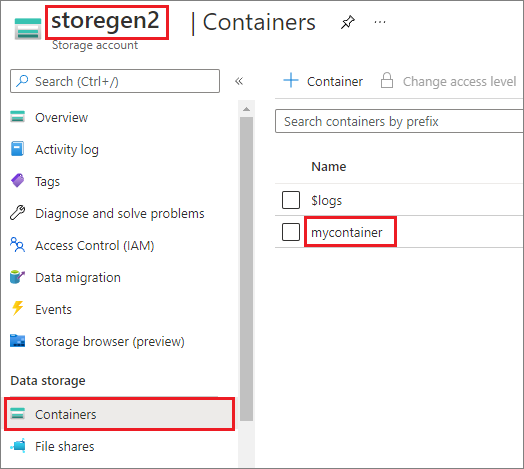
Pour monter le conteneur appelé mycontainer, mssparkutils doit d’abord vérifier si vous disposez de l’autorisation d’accéder au conteneur. Actuellement, Azure Synapse Analytics prend en charge trois méthodes d’authentification pour l’opération de montage du déclencheur : linkedService, accountKey et sastoken.
Monter à l’aide d’un service lié (recommandé)
Nous vous recommandons de monter un déclencheur via un service lié. Cette méthode évite les fuites de sécurité, car mssparkutils ne stocke aucun secrète ou aucune valeur d’authentification elle-même. Au lieu de cela, mssparkutils récupère toujours les valeurs d’authentification du service lié pour demander des données d’objet blob à partir du stockage distant.
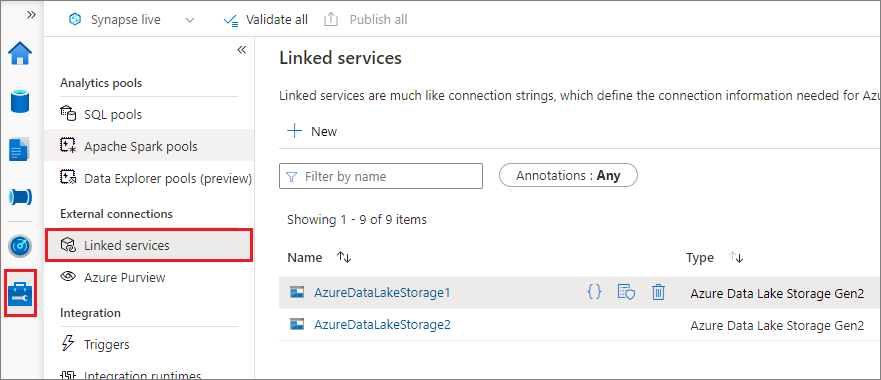
Vous pouvez créer un service lié pour Data Lake Storage Gen2 ou Blob Storage. Actuellement, Azure Synapse Analytics prend en charge deux méthodes d’authentification lorsque vous créez un service lié :
Créer un service lié à l’aide d’une clé de compte
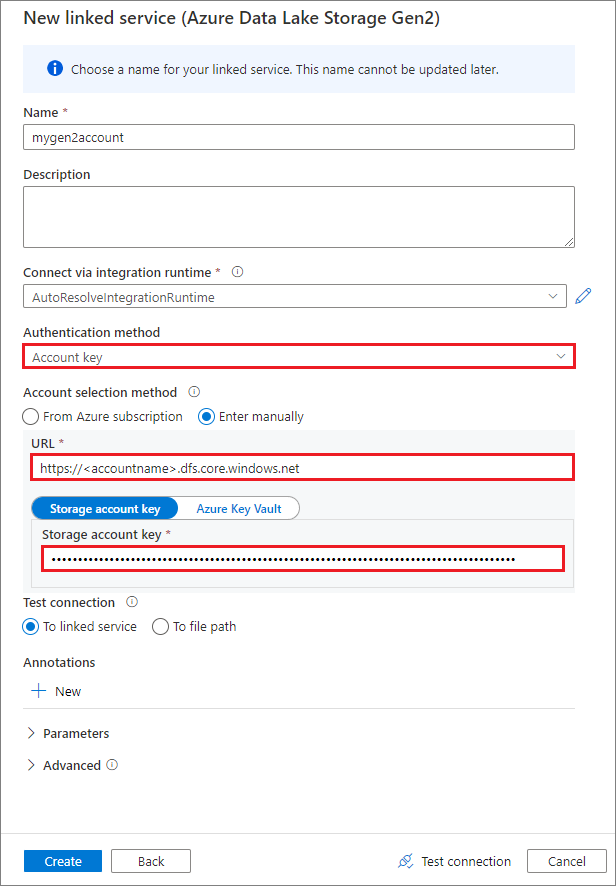
Créer un service lié à l’aide d’une identité managée affectée par le système

Important
- Si le service lié ci-dessus créé à Azure Data Lake Storage Gen2 utilise un point de terminaison privé managed private endpoint (avec un dfs URI), nous devons créer un autre point de terminaison privé managé secondaire à l’aide du Azure Blob Storage option (avec un URI blob) pour vous assurer que le code interne fsspec/adlfs peut se connecter à l’aide de l’interface BlobServiceClient.
- Si le point de terminaison privé managé secondaire n’est pas configuré correctement, un message d’erreur tel que ServiceRequestError : Impossible de se connecter à l’hôte [storageaccountname].blob.core.windows.net:443 ssl:True [Nom ou service inconnu] s’affiche

Notes
Si vous créez un service lié utilisant une identité managée comme la méthode d’authentification, assurez-vous que le fichier MSI de l’espace de travail a le rôle Contributeur aux données Blob du stockage du conteneur monté.
Une fois que vous avez créé le service lié, vous pouvez facilement monter le conteneur dans votre pool Spark à l’aide du code Python suivant :
mssparkutils.fs.mount(
"abfss://mycontainer@<accountname>.dfs.core.windows.net",
"/test",
{"linkedService": "mygen2account"}
)
Notes
Il se peut que vous deviez importer mssparkutils s’il n’est pas disponible :
from notebookutils import mssparkutils
Nous ne vous recommandons pas de monter un dossier racine, quelle que soit la méthode d’authentification que vous utilisez.
Paramètres de montage :
- fileCacheTimeout : les objets blob sont mis en cache dans le dossier temporaire local pendant 120 secondes par défaut. Parallèlement, BlobFuse ne vérifie pas si le fichier est à jour ou non. Le paramètre peut être défini pour modifier le délai d’expiration par défaut. Lorsque plusieurs clients modifient des fichiers en même temps, afin d’éviter les incohérences entre les fichiers locaux et distants, nous vous recommandons de raccourcir le temps de mise en cache, ou même de le remplacer par 0, et de toujours obtenir les derniers fichiers à partir du serveur.
- timeout : le délai d’expiration de l’opération de montage est de 120 secondes par défaut. Le paramètre peut être défini pour modifier le délai d’expiration par défaut. Lorsque le nombre d’exécuteurs est trop élevé ou que le montage expire, nous vous recommandons d’augmenter la valeur.
- étendue : ce paramètre est utilisé pour spécifier l’étendue du montage. La valeur par défaut est « travail ». Si l’étendue est définie sur « travail », le montage est visible uniquement pour le cluster actuel. Si l’étendue est définie sur « espace de travail », le montage est visible pour tous les blocs-notes de l’espace de travail actuel, et le point de montage est automatiquement créé s’il n’existe pas. Ajoutez les mêmes paramètres à l’API démonte pour démonter le point de montage. Le montage au niveau de l’espace de travail est pris en charge uniquement pour l’authentification du service lié.
Vous pouvez utiliser ces paramètres comme suit :
mssparkutils.fs.mount(
"abfss://mycontainer@<accountname>.dfs.core.windows.net",
"/test",
{"linkedService":"mygen2account", "fileCacheTimeout": 120, "timeout": 120}
)
Montage via un jeton de signature d’accès partagé ou une clé de compte
Outre le montage via un service lié, mssparkutils prend en charge le passage explicite d’une clé de compte ou d’un jeton de signature d’accès partagé (SAP) en tant que paramètre pour monter la cible.
Pour des raisons de sécurité, nous vous recommandons d’utiliser des identités managées et Microsoft Entra l’authentification au lieu de clés de compte ou de jetons SAP lorsque cela est possible. Si vous devez utiliser des clés de compte, stockez-les dans Azure Key Vault (comme l’illustre l’exemple de capture d’écran suivant). Vous pouvez ensuite les récupérer à l’aide de l’API mssparkutil.credentials.getSecret. Pour plus d’informations, consultez Autoriser l’accès aux données dans Azure Storage.
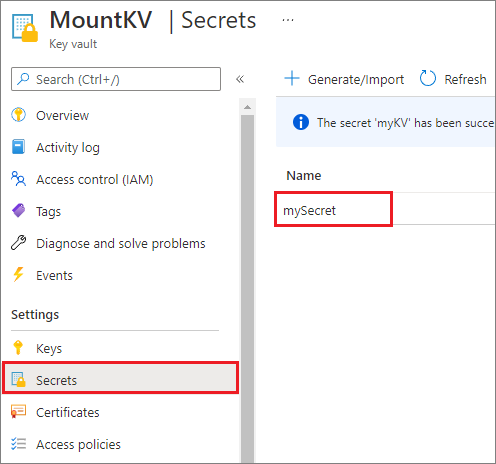
Voici l’exemple de code :
from notebookutils import mssparkutils
accountKey = mssparkutils.credentials.getSecret("MountKV","mySecret")
mssparkutils.fs.mount(
"abfss://mycontainer@<accountname>.dfs.core.windows.net",
"/test",
{"accountKey":accountKey}
)
Notes
Par souci de sécurité, ne stockez pas d’informations d’identification dans du code.
Accéder aux fichiers sous le point de montage à l’aide de l’API mssparkutils fs
L'objectif principal de l'opération de montage est de permettre aux clients d'accéder aux données stockées dans un compte de stockage distant en utilisant une API de système de fichiers local. Vous pouvez également accéder aux données à l’aide de l’API mssparkutils fs avec un chemin d’accès monté en tant que paramètre. Le format de chemin d’accès utilisé ici est un peu différent.
En supposant que vous avez monté le conteneur Data Lake Storage Gen2 mycontainer sur /test à l'aide de l'API de montage. Lors de l’accès aux données via une API de système de fichiers local :
- Pour les versions Spark inférieures ou égales à 3.3, le format de chemin est
/synfs/{jobId}/test/{filename}. - Pour les versions Spark supérieures ou égales à 3.4, le format de chemin est
/synfs/notebook/{jobId}/test/{filename}.
Nous vous recommandons d’utiliser un mssparkutils.fs.getMountPath() pour obtenir le chemin d’accès précis :
path = mssparkutils.fs.getMountPath("/test")
Notes
Lorsque vous montez le stockage avec workspace étendue, le point de montage est créé sous le /synfs/workspace dossier. Et vous devez utiliser mssparkutils.fs.getMountPath("/test", "workspace") pour obtenir le chemin d’accès précis.
Lorsque vous souhaitez accéder aux données à l’aide de l’API mssparkutils fs , le format de chemin d’accès est semblable à ceci : synfs:/notebook/{jobId}/test/{filename}. Vous pouvez voir que le synfs est utilisé comme schéma dans ce cas, au lieu d’une partie du chemin d’accès monté. Bien sûr, vous pouvez également utiliser le schéma du système de fichiers local pour accéder aux données. Par exemple : file:/synfs/notebook/{jobId}/test/{filename}.
Les trois exemples suivants montrent comment accéder à un fichier avec un chemin d’accès au point de montage à l’aide de mssparkutils fs.
Lister des répertoires :
mssparkutils.fs.ls(f'file:{mssparkutils.fs.getMountPath("/test")}')Lisez le contenu du fichier :
mssparkutils.fs.head(f'file:{mssparkutils.fs.getMountPath("/test")}/myFile.csv')Créer un répertoire :
mssparkutils.fs.mkdirs(f'file:{mssparkutils.fs.getMountPath("/test")}/myDir')
Accéder aux fichiers sous le point de montage à l’aide de l’API de lecture Spark
Vous pouvez fournir un paramètre pour accéder aux données via l’API de lecture Spark. Le format de chemin d’accès est le même lorsque vous utilisez l’API mssparkutils fs .
Lire un fichier à partir d’un compte de stockage Data Lake Storage Gen2 monté
L’exemple suivant suppose qu’un compte de stockage Data Lake Storage Gen2 a déjà été monté, puis que vous lisez le fichier à l’aide d’un chemin de montage :
%%pyspark
df = spark.read.load(f'file:{mssparkutils.fs.getMountPath("/test")}/myFile.csv', format='csv')
df.show()
Notes
Lorsque vous montez le stockage à l’aide d’un service lié, vous devez toujours définir explicitement la configuration du service lié Spark avant d’utiliser le schéma synfs pour accéder aux données. Pour plus d’informations, reportez-vous à Stockage ADLS Gen2 avec des services liés.
Lire un fichier à partir d’un compte Blob Storage monté
Si vous avez monté un compte Blob Storage et que vous souhaitez y accéder à l’aide de mssparkutils ou de l’API Spark, vous devez configurer explicitement le jeton SAP via la configuration Spark avant de tenter de monter le conteneur à l’aide de l’API de montage :
Pour accéder à un compte Blob Storage à l’aide de
mssparkutilsou de l’API Spark après un montage de déclencheur, mettez à jour la configuration Spark comme indiqué dans l’exemple de code suivant. Vous pouvez contourner cette étape si vous souhaitez accéder à la configuration Spark uniquement à l’aide de l’API de fichier local après le montage.blob_sas_token = mssparkutils.credentials.getConnectionStringOrCreds("myblobstorageaccount") spark.conf.set('fs.azure.sas.mycontainer.<blobStorageAccountName>.blob.core.windows.net', blob_sas_token)Créez le service lié
myblobstorageaccountet montez le compte Blob Storage à l’aide du service lié :%%spark mssparkutils.fs.mount( "wasbs://mycontainer@<blobStorageAccountName>.blob.core.windows.net", "/test", Map("linkedService" -> "myblobstorageaccount") )Montez le conteneur Blob Storage, puis lisez le fichier à l’aide d’un chemin de montage via l’API de fichier local :
# mount the Blob Storage container, and then read the file by using a mount path with open(mssparkutils.fs.getMountPath("/test") + "/myFile.txt") as f: print(f.read())Lisez les données du conteneur Blob Storage monté via l’API de lecture Spark :
%%spark // mount blob storage container and then read file using mount path val df = spark.read.text(f'file:{mssparkutils.fs.getMountPath("/test")}/myFile.txt') df.show()
Démonter le point de montage
Utilisez le code suivant pour démonter votre point de montage (/test dans cet exemple) :
mssparkutils.fs.unmount("/test")
Limitations connues
Le mécanisme de démontage n’est pas automatique. Une fois l’exécution de l’application terminée, pour démonter le point de montage afin de libérer l’espace disque, vous devez appeler explicitement une API de démontage dans votre code. Sinon, le point de montage existera toujours dans le nœud une fois l’exécution de l’application terminée.
Le montage d’un compte de stockage Data Lake Storage Gen1 n’est pas pris en charge pour l’instant.