Connecteur de pools SQL dédiés Azure Synapse pour Apache Spark
Introduction
Le Connecteur de pools SQL dédié Azure Synapse pour Apache Spark dans Azure Synapse Analytics permet de transférer efficacement des jeux de données volumineux entre le runtime Apache Spark et le pool SQL dédié. Le connecteur est fourni en tant que bibliothèque par défaut avec l’espace de travail Azure Synapse. Le connecteur est implémenté à l’aide du langage Scala. Le connecteur prend en charge Scala et Python. Pour utiliser le Connecteur avec d’autres choix de langage de notebook, utilisez la commande magique Spark - %%spark.
Globalement, le connecteur offre les fonctionnalités suivantes :
- Lire un pool SQL dédié Azure Synapse :
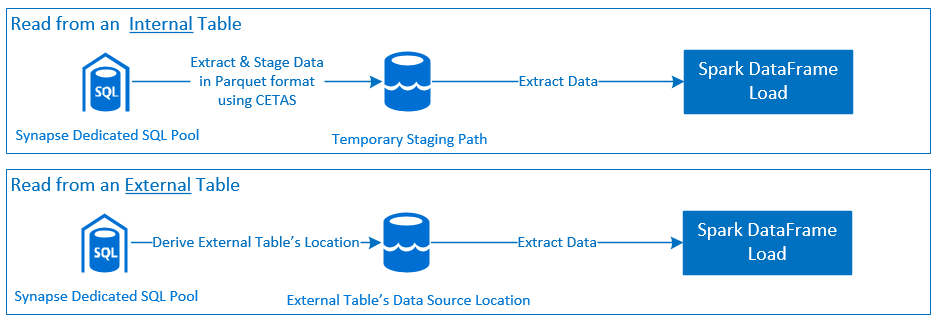
- Lire des grands jeux de données à partir de tables de pool SQL dédié Synapse (internes et externes) et de vues.
- Prise en charge complète du pushdown des prédicats, où les filtres sur les tableaux sont mappés au pushdown des prédicats SQL correspondant.
- Prise en charge du nettoyage de colonne.
- Prise en charge du pushdown.
- Écrire dans un pool SQL dédié Azure Synapse :
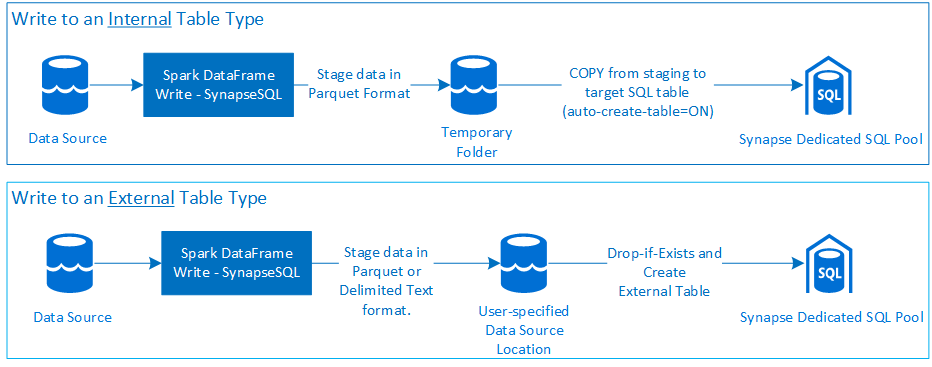
- Ingérer de grandes quantités de données de volume dans des types de tables internes et externes.
- Prend en charge les préférences de mode d’enregistrement de DataFrame suivantes :
AppendErrorIfExistsIgnoreOverwrite
- L’écriture dans un type de table externe prend en charge le format de fichier texte Parquet et délimité (par exemple, CSV).
- Pour écrire des données dans des tables internes, le connecteur utilise désormais l’instruction COPY à la place de l’approche CETAS/CTAS.
- Améliorations pour optimiser les performances du débit d’écriture de bout en bout.
- Introduit un gestionnaire d’appel différé facultatif (un argument de fonction Scala) que les clients peuvent utiliser pour recevoir des métriques après écriture.
- Citons, par exemple, le nombre d’enregistrements, la durée d’exécution d’une certaine action et la raison de l’échec.
Approche de l’orchestration
Lire
Write
Prérequis
Les conditions préalables telles que la configuration des ressources Azure requises et les étapes pour les configurer sont décrites dans cette section.
Ressources Azure
Examinez et configurez les ressources Azure dépendantes suivantes :
- Azure Data Lake Storage : utilisé comme compte de stockage principal pour l’espace de travail Azure Synapse.
- Espace de travail Azure Synapse : créez des notebooks, créez et déployez des workflows d’entrée-sortie basés sur DataFrame.
- Le pool SQL dédié (anciennement SQL DW) fournit des fonctionnalités d’entreposage de données d’entreprise.
- Pool Spark serverless Azure Synapse : runtime Spark dans lequel les tâches sont exécutées en tant qu’applications Spark.
Préparation de la base de données
Connectez-vous à la base de données du Pool SQL dédié Synapse et exécutez les instructions de configuration suivantes :
Créez un utilisateur de base de données mappé à l’identité d’utilisateur Microsoft Entra utilisée pour se connecter à l’espace de travail Azure Synapse.
CREATE USER [username@domain.com] FROM EXTERNAL PROVIDER;Créez un schéma dans lequel les tables seront définies, de sorte que le connecteur puisse écrire et lire les tables respectives.
CREATE SCHEMA [<schema_name>];
Authentification
Authentification basée sur Microsoft Entra ID
L’authentification basée sur Microsoft Entra ID est une approche d’authentification intégrée. L’utilisateur doit se connecter à l’espace de travail Azure Synapse Analytics.
Authentification de base
Une approche d’authentification de base nécessite que l’utilisateur configure les options username et password. Pour en savoir plus sur les paramètres de configuration appropriés pour la lecture et l’écriture de tables dans un pool SQL dédié Azure Synapse, reportez-vous à la section Options de configuration.
Autorisation
Azure Data Lake Storage Gen2
il existe deux façons d’accorder des autorisations d’accès à un compte de stockage Azure Data Lake Storage Gen2 :
- Rôle du contrôle d’accès en fonction du rôle : Rôle Contributeur de données Blob du stockage
- Attribuer les autorisations
Storage Blob Data Contributor Roleà l’utilisateur pour lire, écrire et supprimer des conteneurs d’objets blob de stockage Azure. - RBAC offre une approche de contrôle grossière au niveau du conteneur.
- Attribuer les autorisations
-
Listes de contrôle d’accès (ACL)
- L’approche ACL permet d’obtenir des contrôles précis sur des chemins d’accès et/ou des fichiers spécifiques dans un dossier donné.
- Les vérifications des listes de contrôle d’accès ne sont pas appliquées si l’utilisateur a déjà reçu des autorisations à l’aide de l’approche RBAC.
- Il existe deux principaux types d’autorisations ACL :
- Autorisations d’accès (appliquées à un niveau ou objet spécifique).
- Autorisations par défaut (appliquées automatiquement pour tous les objets enfants au moment de leur création).
- Les types d’autorisations incluent :
-
Executepermet de traverser ou de parcourir les hiérarchies de dossiers. -
Readpermet la lecture. -
Writepermet l’écriture.
-
- Il est important de configurer les listes de contrôle d’accès de sorte que le connecteur puisse écrire et lire à partir des emplacements de stockage.
Remarque
Si vous souhaitez exécuter des notebooks à l’aide de pipelines de l’espace de travail Synapse, vous devez également accorder les autorisations d’accès listées ci-dessus à l’identité managée par défaut de l’espace de travail Synapse. Le nom d’identité managée par défaut de l’espace de travail est identique au nom de l’espace de travail.
Pour utiliser l’espace de travail Synapse avec des comptes de stockage sécurisés, un point de terminaison privé managé doit être configuré à partir du notebook. Le point de terminaison privé managé doit être approuvé à partir de la section
Private endpoint connectionsdu compte de stockage ADLS Gen2, dans le voletNetworking.
Azure Synapse : pool SQL dédié
Pour permettre une interaction réussie avec le Pool SQL dédié Azure Synapse, l’autorisation suivante est nécessaire, sauf si vous êtes un utilisateur également configuré en tant qu’Active Directory Admin sur le point de terminaison SQL dédié :
Scénario de lecture
Accordez à l’utilisateur le rôle
db_exporteren utilisant la procédure stockée systèmesp_addrolemember.EXEC sp_addrolemember 'db_exporter', [<your_domain_user>@<your_domain_name>.com];
Scénario d’écriture
- Le connecteur utilise la commande de copie pour écrire des données de mise en lots dans l’emplacement géré de la table interne.
Configurez les autorisations requises décrites ici.
Voici un extrait de code d’accès rapide :
--Make sure your user has the permissions to CREATE tables in the [dbo] schema GRANT CREATE TABLE TO [<your_domain_user>@<your_domain_name>.com]; GRANT ALTER ON SCHEMA::<target_database_schema_name> TO [<your_domain_user>@<your_domain_name>.com]; --Make sure your user has ADMINISTER DATABASE BULK OPERATIONS permissions GRANT ADMINISTER DATABASE BULK OPERATIONS TO [<your_domain_user>@<your_domain_name>.com]; --Make sure your user has INSERT permissions on the target table GRANT INSERT ON <your_table> TO [<your_domain_user>@<your_domain_name>.com]
- Le connecteur utilise la commande de copie pour écrire des données de mise en lots dans l’emplacement géré de la table interne.
Documentation de l’API
Connecteur de pools SQL dédiés Azure Synapse pour Apache Spark - Documentation de l’API.
Options de configuration
Pour démarrer et orchestrer correctement l’opération de lecture ou d’écriture, le Connecteur attend certains paramètres de configuration. La définition d’objet com.microsoft.spark.sqlanalytics.utils.Constants fournit une liste de constantes standardisées pour chaque clé de paramètre.
Voici la liste des options de configuration en fonction du scénario d’utilisation :
-
Lire à l’aide de l’authentification basée sur Microsoft Entra ID
- Les informations d'identification sont mappées automatiquement et l'utilisateur n'est pas tenu de fournir des options de configuration spécifiques.
- L’argument de nom de table en trois parties sur la méthode
synapsesqlest requis pour lire à partir de la table correspondante dans le Pool SQL dédié Azure Synapse.
-
Lire en utilisant l’authentification de base
- Point de terminaison SQL dédié Azure Synapse
-
Constants.SERVER: point de terminaison de Pool SQL dédié Azure Synapse (nom de domaine complet du serveur) -
Constants.USER: nom d’utilisateur SQL. -
Constants.PASSWORD: mot de passe d’utilisateur SQL.
-
- Point de terminaison Azure Data Lake Storage (Gen 2) - Dossiers de préproduction
-
Constants.DATA_SOURCE: le chemin de stockage défini sur le paramètre d’emplacement de la source de données est utilisé pour la préproduction des données.
-
- Point de terminaison SQL dédié Azure Synapse
-
Écrire à l’aide de l’authentification basée sur Microsoft Entra ID
- Point de terminaison SQL dédié Azure Synapse
- Par défaut, le Connecteur déduit le point de terminaison SQL dédié Synapse à l’aide du nom de base de données défini sur le paramètre de nom de table en trois parties de la méthode
synapsesql. - Les utilisateurs peuvent également utiliser l’option
Constants.SERVERpour spécifier le point de terminaison SQL. Vérifiez que le point de terminaison héberge la base de données correspondante avec le schéma respectif.
- Par défaut, le Connecteur déduit le point de terminaison SQL dédié Synapse à l’aide du nom de base de données défini sur le paramètre de nom de table en trois parties de la méthode
- Point de terminaison Azure Data Lake Storage (Gen 2) - Dossiers de préproduction
- Pour le type de table interne :
- Configurez l’option
Constants.TEMP_FOLDERouConstants.DATA_SOURCE. - Si l’utilisateur a choisi de fournir l’option
Constants.DATA_SOURCE, le dossier de préproduction est dérivé à l’aide de la valeurlocationde la source de données. - Si les deux sont fournies, la valeur de l’option
Constants.TEMP_FOLDERest utilisée. - En l’absence d’une option de dossier de préproduction, le Connecteur en dérive un en fonction de la configuration du runtime :
spark.sqlanalyticsconnector.stagingdir.prefix.
- Configurez l’option
- Pour le type de table externe :
-
Constants.DATA_SOURCEest une option de configuration requise. - Le connecteur utilise le chemin de stockage défini sur le paramètre d’emplacement de la source de données en association avec l’argument
locationde la méthodesynapsesqlet dérive le chemin absolu pour conserver les données de la table externe. - Si l’argument
locationde la méthodesynapsesqln’est pas spécifié, le connecteur dérive la valeur d’emplacement sous la forme<base_path>/dbName/schemaName/tableName.
-
- Pour le type de table interne :
- Point de terminaison SQL dédié Azure Synapse
-
Écrire en utilisant l’authentification de base
- Point de terminaison SQL dédié Azure Synapse
-
Constants.SERVER: point de terminaison de Pool SQL dédié Azure Synapse (nom de domaine complet du serveur). -
Constants.USER: nom d’utilisateur SQL. -
Constants.PASSWORD: mot de passe d’utilisateur SQL. -
Constants.STAGING_STORAGE_ACCOUNT_KEYassocié au compte de stockage qui hébergeConstants.TEMP_FOLDERS(types de tables internes uniquement) ouConstants.DATA_SOURCE.
-
- Point de terminaison Azure Data Lake Storage (Gen 2) - Dossiers de préproduction
- Les informations d’identification de l’authentification de base SQL ne s’appliquent pas à l’accès aux points de terminaison de stockage.
- Par conséquent, veillez à attribuer les autorisations d’accès au stockage pertinentes, comme décrit dans la section Azure Data Lake Storage Gen2.
- Point de terminaison SQL dédié Azure Synapse
Modèles de code
Cette section présente les modèles de code de référence pour décrire comment utiliser et appeler le connecteur de pool SQL dédié Azure Synapse pour Apache Spark.
Notes
Utilisation du connecteur dans Python
- Le connecteur est pris en charge uniquement dans Python pour Spark 3. Pour Spark 2.4 (non pris en charge), nous pouvons utiliser l’API de connecteur Scala pour interagir avec le contenu d’un DataFrame dans PySpark en utilisant DataFrame.createOrReplaceTempView ou DataFrame.createOrReplaceGlobalTempView. Consultez la section Utilisation de données matérialisées entre les cellules.
- Le descripteur de rappel n’est pas disponible dans Python.
Lire un pool SQL dédié Azure Synapse
Demande de lecture - Signature de la méthode synapsesql
Lire à partir d’une table à l’aide de l’authentification basée sur Microsoft Entra ID
//Use case is to read data from an internal table in Synapse Dedicated SQL Pool DB
//Azure Active Directory based authentication approach is preferred here.
import org.apache.spark.sql.DataFrame
import com.microsoft.spark.sqlanalytics.utils.Constants
import org.apache.spark.sql.SqlAnalyticsConnector._
//Read from existing internal table
val dfToReadFromTable:DataFrame = spark.read.
//If `Constants.SERVER` is not provided, the `<database_name>` from the three-part table name argument
//to `synapsesql` method is used to infer the Synapse Dedicated SQL End Point.
option(Constants.SERVER, "<sql-server-name>.sql.azuresynapse.net").
//Defaults to storage path defined in the runtime configurations
option(Constants.TEMP_FOLDER, "abfss://<container_name>@<storage_account_name>.dfs.core.windows.net/<some_base_path_for_temporary_staging_folders>").
//Three-part table name from where data will be read.
synapsesql("<database_name>.<schema_name>.<table_name>").
//Column-pruning i.e., query select column values.
select("<some_column_1>", "<some_column_5>", "<some_column_n>").
//Push-down filter criteria that gets translated to SQL Push-down Predicates.
filter(col("Title").startsWith("E")).
//Fetch a sample of 10 records
limit(10)
//Show contents of the dataframe
dfToReadFromTable.show()
Lire à partir d’une requête à l’aide de l’authentification basée sur Microsoft Entra ID
Remarque
Restrictions pendant la lecture dans une requête :
- Le nom de table et la requête ne peuvent pas être spécifiés simultanément.
- Seules certaines requêtes sont autorisées. Les requêtes SQL DDL et DML ne sont pas autorisées.
- Les options de sélection et de filtre sur le dataframe ne font pas l’objet d’un pushdown sur le pool SQL dédié quand une requête est spécifiée.
- La lecture à partir d'une requête n'est disponible que dans Spark 3.
//Use case is to read data from an internal table in Synapse Dedicated SQL Pool DB
//Azure Active Directory based authentication approach is preferred here.
import org.apache.spark.sql.DataFrame
import com.microsoft.spark.sqlanalytics.utils.Constants
import org.apache.spark.sql.SqlAnalyticsConnector._
// Read from a query
// Query can be provided either as an argument to synapsesql or as a Constant - Constants.QUERY
val dfToReadFromQueryAsOption:DataFrame = spark.read.
// Name of the SQL Dedicated Pool or database where to run the query
// Database can be specified as a Spark Config - spark.sqlanalyticsconnector.dw.database or as a Constant - Constants.DATABASE
option(Constants.DATABASE, "<database_name>").
//If `Constants.SERVER` is not provided, the `<database_name>` from the three-part table name argument
//to `synapsesql` method is used to infer the Synapse Dedicated SQL End Point.
option(Constants.SERVER, "<sql-server-name>.sql.azuresynapse.net").
//Defaults to storage path defined in the runtime configurations
option(Constants.TEMP_FOLDER, "abfss://<container_name>@<storage_account_name>.dfs.core.windows.net/<some_base_path_for_temporary_staging_folders>")
//query from which data will be read
.option(Constants.QUERY, "select <column_name>, count(*) as cnt from <schema_name>.<table_name> group by <column_name>")
synapsesql()
val dfToReadFromQueryAsArgument:DataFrame = spark.read.
// Name of the SQL Dedicated Pool or database where to run the query
// Database can be specified as a Spark Config - spark.sqlanalyticsconnector.dw.database or as a Constant - Constants.DATABASE
option(Constants.DATABASE, "<database_name>")
//If `Constants.SERVER` is not provided, the `<database_name>` from the three-part table name argument
//to `synapsesql` method is used to infer the Synapse Dedicated SQL End Point.
option(Constants.SERVER, "<sql-server-name>.sql.azuresynapse.net").
//Defaults to storage path defined in the runtime configurations
option(Constants.TEMP_FOLDER, "abfss://<container_name>@<storage_account_name>.dfs.core.windows.net/<some_base_path_for_temporary_staging_folders>")
//query from which data will be read
.synapsesql("select <column_name>, count(*) as counts from <schema_name>.<table_name> group by <column_name>")
//Show contents of the dataframe
dfToReadFromQueryAsOption.show()
dfToReadFromQueryAsArgument.show()
Lire dans une table en utilisant l’authentification de base
//Use case is to read data from an internal table in Synapse Dedicated SQL Pool DB
//Azure Active Directory based authentication approach is preferred here.
import org.apache.spark.sql.DataFrame
import com.microsoft.spark.sqlanalytics.utils.Constants
import org.apache.spark.sql.SqlAnalyticsConnector._
//Read from existing internal table
val dfToReadFromTable:DataFrame = spark.read.
//If `Constants.SERVER` is not provided, the `<database_name>` from the three-part table name argument
//to `synapsesql` method is used to infer the Synapse Dedicated SQL End Point.
option(Constants.SERVER, "<sql-server-name>.sql.azuresynapse.net").
//Set database user name
option(Constants.USER, "<user_name>").
//Set user's password to the database
option(Constants.PASSWORD, "<user_password>").
//Set name of the data source definition that is defined with database scoped credentials.
//Data extracted from the table will be staged to the storage path defined on the data source's location setting.
option(Constants.DATA_SOURCE, "<data_source_name>").
//Three-part table name from where data will be read.
synapsesql("<database_name>.<schema_name>.<table_name>").
//Column-pruning i.e., query select column values.
select("<some_column_1>", "<some_column_5>", "<some_column_n>").
//Push-down filter criteria that gets translated to SQL Push-down Predicates.
filter(col("Title").startsWith("E")).
//Fetch a sample of 10 records
limit(10)
//Show contents of the dataframe
dfToReadFromTable.show()
Lire dans une requête en utilisant l’authentification de base
//Use case is to read data from an internal table in Synapse Dedicated SQL Pool DB
//Azure Active Directory based authentication approach is preferred here.
import org.apache.spark.sql.DataFrame
import com.microsoft.spark.sqlanalytics.utils.Constants
import org.apache.spark.sql.SqlAnalyticsConnector._
// Name of the SQL Dedicated Pool or database where to run the query
// Database can be specified as a Spark Config or as a Constant - Constants.DATABASE
spark.conf.set("spark.sqlanalyticsconnector.dw.database", "<database_name>")
// Read from a query
// Query can be provided either as an argument to synapsesql or as a Constant - Constants.QUERY
val dfToReadFromQueryAsOption:DataFrame = spark.read.
//Name of the SQL Dedicated Pool or database where to run the query
//Database can be specified as a Spark Config - spark.sqlanalyticsconnector.dw.database or as a Constant - Constants.DATABASE
option(Constants.DATABASE, "<database_name>").
//If `Constants.SERVER` is not provided, the `<database_name>` from the three-part table name argument
//to `synapsesql` method is used to infer the Synapse Dedicated SQL End Point.
option(Constants.SERVER, "<sql-server-name>.sql.azuresynapse.net").
//Set database user name
option(Constants.USER, "<user_name>").
//Set user's password to the database
option(Constants.PASSWORD, "<user_password>").
//Set name of the data source definition that is defined with database scoped credentials.
//Data extracted from the SQL query will be staged to the storage path defined on the data source's location setting.
option(Constants.DATA_SOURCE, "<data_source_name>").
//Query where data will be read.
option(Constants.QUERY, "select <column_name>, count(*) as counts from <schema_name>.<table_name> group by <column_name>" ).
synapsesql()
val dfToReadFromQueryAsArgument:DataFrame = spark.read.
//Name of the SQL Dedicated Pool or database where to run the query
//Database can be specified as a Spark Config - spark.sqlanalyticsconnector.dw.database or as a Constant - Constants.DATABASE
option(Constants.DATABASE, "<database_name>").
//If `Constants.SERVER` is not provided, the `<database_name>` from the three-part table name argument
//to `synapsesql` method is used to infer the Synapse Dedicated SQL End Point.
option(Constants.SERVER, "<sql-server-name>.sql.azuresynapse.net").
//Set database user name
option(Constants.USER, "<user_name>").
//Set user's password to the database
option(Constants.PASSWORD, "<user_password>").
//Set name of the data source definition that is defined with database scoped credentials.
//Data extracted from the SQL query will be staged to the storage path defined on the data source's location setting.
option(Constants.DATA_SOURCE, "<data_source_name>").
//Query where data will be read.
synapsesql("select <column_name>, count(*) as counts from <schema_name>.<table_name> group by <column_name>")
//Show contents of the dataframe
dfToReadFromQueryAsOption.show()
dfToReadFromQueryAsArgument.show()
Écrire dans un pool SQL dédié Azure Synapse
Demande d’écriture - Signature de la méthode synapsesql
synapsesql(tableName:String,
tableType:String = Constants.INTERNAL,
location:Option[String] = None,
callBackHandle=Option[(Map[String, Any], Option[Throwable])=>Unit]):Unit
Écrire à l’aide de l’authentification basée sur Microsoft Entra ID
Voici un exemple de modèle de code complet qui explique comment utiliser le Connecteur pour les scénarios d’écriture :
//Add required imports
import org.apache.spark.sql.DataFrame
import org.apache.spark.sql.SaveMode
import com.microsoft.spark.sqlanalytics.utils.Constants
import org.apache.spark.sql.SqlAnalyticsConnector._
//Define read options for example, if reading from CSV source, configure header and delimiter options.
val pathToInputSource="abfss://<storage_container_name>@<storage_account_name>.dfs.core.windows.net/<some_folder>/<some_dataset>.csv"
//Define read configuration for the input CSV
val dfReadOptions:Map[String, String] = Map("header" -> "true", "delimiter" -> ",")
//Initialize DataFrame that reads CSV data from a given source
val readDF:DataFrame=spark.
read.
options(dfReadOptions).
csv(pathToInputSource).
limit(1000) //Reads first 1000 rows from the source CSV input.
//Setup and trigger the read DataFrame for write to Synapse Dedicated SQL Pool.
//Fully qualified SQL Server DNS name can be obtained using one of the following methods:
// 1. Synapse Workspace - Manage Pane - SQL Pools - <Properties view of the corresponding Dedicated SQL Pool>
// 2. From Azure Portal, follow the bread-crumbs for <Portal_Home> -> <Resource_Group> -> <Dedicated SQL Pool> and then go to Connection Strings/JDBC tab.
//If `Constants.SERVER` is not provided, the value will be inferred by using the `database_name` in the three-part table name argument to the `synapsesql` method.
//Like-wise, if `Constants.TEMP_FOLDER` is not provided, the connector will use the runtime staging directory config (see section on Configuration Options for details).
val writeOptionsWithAADAuth:Map[String, String] = Map(Constants.SERVER -> "<dedicated-pool-sql-server-name>.sql.azuresynapse.net",
Constants.TEMP_FOLDER -> "abfss://<storage_container_name>@<storage_account_name>.dfs.core.windows.net/<some_temp_folder>")
//Setup optional callback/feedback function that can receive post write metrics of the job performed.
var errorDuringWrite:Option[Throwable] = None
val callBackFunctionToReceivePostWriteMetrics: (Map[String, Any], Option[Throwable]) => Unit =
(feedback: Map[String, Any], errorState: Option[Throwable]) => {
println(s"Feedback map - ${feedback.map{case(key, value) => s"$key -> $value"}.mkString("{",",\n","}")}")
errorDuringWrite = errorState
}
//Configure and submit the request to write to Synapse Dedicated SQL Pool (note - default SaveMode is set to ErrorIfExists)
//Sample below is using AAD-based authentication approach; See further examples to leverage SQL Basic auth.
readDF.
write.
//Configure required configurations.
options(writeOptionsWithAADAuth).
//Choose a save mode that is apt for your use case.
mode(SaveMode.Overwrite).
synapsesql(tableName = "<database_name>.<schema_name>.<table_name>",
//For external table type value is Constants.EXTERNAL
tableType = Constants.INTERNAL,
//Optional parameter that is used to specify external table's base folder; defaults to `database_name/schema_name/table_name`
location = None,
//Optional parameter to receive a callback.
callBackHandle = Some(callBackFunctionToReceivePostWriteMetrics))
//If write request has failed, raise an error and fail the Cell's execution.
if(errorDuringWrite.isDefined) throw errorDuringWrite.get
Écrire en utilisant l’authentification de base
L’extrait de code suivant remplace la définition d’écriture décrite dans la section Écrire en utilisant l’authentification basée sur Microsoft Entra ID pour envoyer une requête d’écriture à l’aide de l’approche d’authentification de base SQL :
//Define write options to use SQL basic authentication
val writeOptionsWithBasicAuth:Map[String, String] = Map(Constants.SERVER -> "<dedicated-pool-sql-server-name>.sql.azuresynapse.net",
//Set database user name
Constants.USER -> "<user_name>",
//Set database user's password
Constants.PASSWORD -> "<user_password>",
//Required only when writing to an external table. For write to internal table, this can be used instead of TEMP_FOLDER option.
Constants.DATA_SOURCE -> "<Name of the datasource as defined in the target database>"
//To be used only when writing to internal tables. Storage path will be used for data staging.
Constants.TEMP_FOLDER -> "abfss://<storage_container_name>@<storage_account_name>.dfs.core.windows.net/<some_temp_folder>")
//Configure and submit the request to write to Synapse Dedicated SQL Pool.
readDF.
write.
options(writeOptionsWithBasicAuth).
//Choose a save mode that is apt for your use case.
mode(SaveMode.Overwrite).
synapsesql(tableName = "<database_name>.<schema_name>.<table_name>",
//For external table type value is Constants.EXTERNAL
tableType = Constants.INTERNAL,
//Not required for writing to an internal table
location = None,
//Optional parameter.
callBackHandle = Some(callBackFunctionToReceivePostWriteMetrics))
Dans une approche d’authentification de base, pour lire des données à partir d’un chemin de stockage source, d’autres options de configuration sont nécessaires. L’extrait de code suivant fournit un exemple de lecture d’une source de données Azure Data Lake Storage Gen2 à l’aide des informations d’identification du principal de service :
//Specify options that Spark runtime must support when interfacing and consuming source data
val storageAccountName="<storageAccountName>"
val storageContainerName="<storageContainerName>"
val subscriptionId="<AzureSubscriptionID>"
val spnClientId="<ServicePrincipalClientID>"
val spnSecretKeyUsedAsAuthCred="<spn_secret_key_value>"
val dfReadOptions:Map[String, String]=Map("header"->"true",
"delimiter"->",",
"fs.defaultFS" -> s"abfss://$storageContainerName@$storageAccountName.dfs.core.windows.net",
s"fs.azure.account.auth.type.$storageAccountName.dfs.core.windows.net" -> "OAuth",
s"fs.azure.account.oauth.provider.type.$storageAccountName.dfs.core.windows.net" ->
"org.apache.hadoop.fs.azurebfs.oauth2.ClientCredsTokenProvider",
"fs.azure.account.oauth2.client.id" -> s"$spnClientId",
"fs.azure.account.oauth2.client.secret" -> s"$spnSecretKeyUsedAsAuthCred",
"fs.azure.account.oauth2.client.endpoint" -> s"https://login.microsoftonline.com/$subscriptionId/oauth2/token",
"fs.AbstractFileSystem.abfss.impl" -> "org.apache.hadoop.fs.azurebfs.Abfs",
"fs.abfss.impl" -> "org.apache.hadoop.fs.azurebfs.SecureAzureBlobFileSystem")
//Initialize the Storage Path string, where source data is maintained/kept.
val pathToInputSource=s"abfss://$storageContainerName@$storageAccountName.dfs.core.windows.net/<base_path_for_source_data>/<specific_file (or) collection_of_files>"
//Define data frame to interface with the data source
val df:DataFrame = spark.
read.
options(dfReadOptions).
csv(pathToInputSource).
limit(100)
Modes d’enregistrement de DataFrame pris en charge
Les modes d’enregistrement suivants sont pris en charge lors de l’écriture de données sources dans une table de destination dans un pool SQL dédié Azure Synapse :
- ErrorIfExists (mode d’enregistrement par défaut)
- Si la table de destination existe, l’écriture est abandonnée avec une exception renvoyée à l’appelé. Sinon, une nouvelle table est créée avec les données des dossiers intermédiaires.
- Ignorer
- Si la table de destination existe, l’écriture ignore la demande d’écriture sans retourner d’erreur. Sinon, une nouvelle table est créée avec les données des dossiers intermédiaires.
- Remplacer
- Si la table de destination existe, les données existantes dans la destination sont remplacées par les données des dossiers intermédiaires. Sinon, une nouvelle table est créée avec les données des dossiers intermédiaires.
- Ajouter
- Si la table de destination existe, les nouvelles données sont ajoutées à celle-ci. Sinon, une nouvelle table est créée avec les données des dossiers intermédiaires.
Descripteur de rappel de demande d’écriture
Les nouvelles modifications de l’API de chemin d’accès d’écriture ont introduit une fonctionnalité expérimentale pour fournir au client un mappage clé->valeur de métriques postérieures à l’écriture. Les clés des métriques sont définies dans la nouvelle définition d’objet : Constants.FeedbackConstants. Vous pouvez récupérer les métriques sous la forme d’une chaîne JSON en passant le descripteur de rappel (une Scala Function). Voici la signature de fonction :
//Function signature is expected to have two arguments - a `scala.collection.immutable.Map[String, Any]` and an Option[Throwable]
//Post-write if there's a reference of this handle passed to the `synapsesql` signature, it will be invoked by the closing process.
//These arguments will have valid objects in either Success or Failure case. In case of Failure the second argument will be a `Some(Throwable)`.
(Map[String, Any], Option[Throwable]) => Unit
Voici quelques métriques notables (présentées en casse mixte) :
WriteFailureCauseDataStagingSparkJobDurationInMillisecondsNumberOfRecordsStagedForSQLCommitSQLStatementExecutionDurationInMillisecondsrows_processed
Voici un exemple de chaîne JSON avec des métriques postérieures à l’écriture :
{
SparkApplicationId -> <spark_yarn_application_id>,
SQLStatementExecutionDurationInMilliseconds -> 10113,
WriteRequestReceivedAtEPOCH -> 1647523790633,
WriteRequestProcessedAtEPOCH -> 1647523808379,
StagingDataFileSystemCheckDurationInMilliseconds -> 60,
command -> "COPY INTO [schema_name].[table_name] ...",
NumberOfRecordsStagedForSQLCommit -> 100,
DataStagingSparkJobEndedAtEPOCH -> 1647523797245,
SchemaInferenceAssertionCompletedAtEPOCH -> 1647523790920,
DataStagingSparkJobDurationInMilliseconds -> 5252,
rows_processed -> 100,
SaveModeApplied -> TRUNCATE_COPY,
DurationInMillisecondsToValidateFileFormat -> 75,
status -> Completed,
SparkApplicationName -> <spark_application_name>,
ThreePartFullyQualifiedTargetTableName -> <database_name>.<schema_name>.<table_name>,
request_id -> <query_id_as_retrieved_from_synapse_dedicated_sql_db_query_reference>,
StagingFolderConfigurationCheckDurationInMilliseconds -> 2,
JDBCConfigurationsSetupAtEPOCH -> 193,
StagingFolderConfigurationCheckCompletedAtEPOCH -> 1647523791012,
FileFormatValidationsCompletedAtEPOCHTime -> 1647523790995,
SchemaInferenceCheckDurationInMilliseconds -> 91,
SaveModeRequested -> Overwrite,
DataStagingSparkJobStartedAtEPOCH -> 1647523791993,
DurationInMillisecondsTakenToGenerateWriteSQLStatements -> 4
}
Autres exemples de code
Utilisation de données matérialisées entre les cellules
Vous pouvez utiliser createOrReplaceTempView de Spark DataFrame pour accéder aux données extraites dans une autre cellule, en inscrivant une vue temporaire.
- Cellule où les données sont extraites (avec, par exemple, la préférence de langage de notebook
Scala)
//Necessary imports
import org.apache.spark.sql.DataFrame
import org.apache.spark.sql.SaveMode
import com.microsoft.spark.sqlanalytics.utils.Constants
import org.apache.spark.sql.SqlAnalyticsConnector._
//Configure options and read from Synapse Dedicated SQL Pool.
val readDF = spark.read.
//Set Synapse Dedicated SQL End Point name.
option(Constants.SERVER, "<synapse-dedicated-sql-end-point>.sql.azuresynapse.net").
//Set database user name.
option(Constants.USER, "<user_name>").
//Set database user's password.
option(Constants.PASSWORD, "<user_password>").
//Set name of the data source definition that is defined with database scoped credentials.
option(Constants.DATA_SOURCE,"<data_source_name>").
//Set the three-part table name from which the read must be performed.
synapsesql("<database_name>.<schema_name>.<table_name>").
//Optional - specify number of records the DataFrame would read.
limit(10)
//Register the temporary view (scope - current active Spark Session)
readDF.createOrReplaceTempView("<temporary_view_name>")
- À présent, remplacez la préférence de langage sur le notebook par
PySpark (Python)et extrayez les données de la vue inscrite<temporary_view_name>
spark.sql("select * from <temporary_view_name>").show()
Gestion des réponses
L’appel de synapsesql a deux états finaux possibles : Réussite ou État d’échec. Cette section décrit comment gérer la réponse à une demande pour chaque scénario.
Réponse à une demande de lecture
Une fois l’opération terminée, l’extrait de la réponse de lecture s’affiche dans la sortie de la cellule. Tout échec dans la cellule active annule également les exécutions de cellules suivantes. Des informations détaillées sur les erreurs sont disponibles dans les journaux des applications Spark.
Réponse à une demande d’écriture
Par défaut, une réponse d’écriture est imprimée dans la sortie de la cellule. En cas d’échec, la cellule active est marquée comme ayant échoué et les exécutions de cellules suivantes sont abandonnées. L’autre approche consiste à passer l’option de descripteur de rappel à la méthode synapsesql. Le descripteur de rappel fournit un accès programmatique à la réponse d’écriture.
Autres considérations
- Lors de la lecture à partir des tables de pool SQL dédié Azure Synapse :
- Envisagez d’appliquer les filtres nécessaires sur le DataFrame pour tirer parti de la fonctionnalité de nettoyage des colonnes du Connecteur.
- Un scénario de lecture ne prend pas en charge la clause
TOP(n-rows)lors de la délimitation des instructions de requêteSELECT. Le choix de limiter les données consiste à utiliser la clause limit(.) de DataFrame.- Reportez-vous l’exemple de la section Utiliser des données matérialisées entre les cellules.
- Lors de l’écriture dans des tables de pool SQL dédié Azure Synapse :
- Pour les types de tables internes :
- Les tables sont créées avec une distribution de données ROUND_ROBIN.
- Les types de colonnes sont déduits du DataFrame qui lit les données à partir de la source. Les colonnes de chaîne sont mappées à
NVARCHAR(4000).
- Pour les types de tables externes :
- Le parallélisme initial du DataFrame pilote l’organisation des données pour la table externe.
- Les types de colonnes sont déduits du DataFrame qui lit les données à partir de la source.
- Vous pouvez obtenir une meilleure distribution des données entre exécuteurs en réglant
spark.sql.files.maxPartitionByteset le paramètrerepartitionde DataFrame. - Lors de l’écriture de jeux de données volumineux, il est important de tenir compte de l’impact du paramètre Niveau de performance DWU qui limite la taille des transactions.
- Pour les types de tables internes :
- Supervisez les tendances d’utilisation d’Azure Data Lake Storage Gen2 pour repérer les comportements de limitation qui peuvent avoir un impact sur les performances de lecture et d’écriture.