Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Azure Synapse Analytics est un service d’analytique qui regroupe l’entreposage des données d’entreprise et l’analytique de Big Data. Il vous permet d'interroger les données selon vos conditions.
Notes
Pour plus d’informations sur Azure Synapse Analytics, regardez cette vidéo expliquant les améliorations du déplacement des données.
Composants de l’architecture SQL Synapse
Le pool SQL dédié (anciennement SQL DW) tire parti d'une architecture Scale-out pour répartir le traitement informatique des données sur plusieurs nœuds. L’unité d’échelle est une abstraction de la puissance de calcul connue sous le nom de Data Warehouse Unit. Le calcul est séparé du stockage, ce qui permet d’adapter l’échelle du calcul indépendamment des données présentes dans le système.
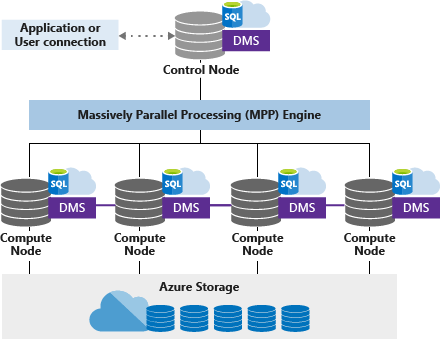
Le pool SQL dédié (anciennement SQL DW) utilise une architecture basée sur des nœuds. Les applications se connectent et envoient des commandes T-SQL à un nœud de contrôle. Le nœud de contrôle héberge le moteur de requêtes distribuées, qui optimise les requêtes pour un traitement en parallèle, puis transmet les opérations aux nœuds de calcul qui accomplissent leur travail en parallèle.
Les nœuds de calcul stockent toutes les données utilisateur dans un stockage Azure et exécutent les requêtes parallèles. Le service de déplacement de données (DMS) est un service interne de niveau système, qui déplace les données entre les nœuds en fonction des besoins pour exécuter des requêtes en parallèle et retourner des résultats précis.
Avec le stockage et le calcul découplés, lorsque vous utilisez un pool SQL dédié (anciennement SQL DW), vous pouvez :
- Dimensionner de façon indépendante la puissance de calcul, sans prendre en considération vos besoins de stockage.
- Augmenter ou réduire la puissance de calcul dans un pool SQL dédié (anciennement SQL DW) sans déplacer les données.
- Suspendre la capacité de calcul tout en maintenant les données intactes, si bien que vous payez uniquement le stockage.
- Reprendre le calcul pendant les heures d’utilisation.
Stockage Azure
Un pool SQL dédié SQL (anciennement SQL DW) utilise le Stockage Azure pour protéger vos données utilisateur. Étant donné que vos données sont stockées et gérées par Stockage Azure, votre consommation de stockage est facturée séparément. Les données sont partitionnées en distributions pour optimiser les performances du système. Vous pouvez choisir le modèle de partitionnement à utiliser pour distribuer les données lorsque vous définissez la table. Les modèles de partitionnement pris en charge sont les suivants :
- Hachage
- Tourniquet (round robin)
- Réplication
Nœud de contrôle
Le nœud de contrôle est le cerveau de l’architecture. Il s’agit du nœud frontal qui interagit avec toutes les applications et les connexions. Le moteur de requêtes distribuées s'exécute sur le nœud de contrôle pour optimiser et coordonner les requêtes parallèles. Quand vous envoyez une requête T-SQL, le nœud de contrôle la transforme en plusieurs requêtes distinctes qui s’exécutent sur chaque distribution en parallèle.
Nœuds de calcul
Les nœuds de calcul fournissent la puissance de calcul. Les distributions sont mappées aux nœuds de calcul pour traitement. À mesure que vous payez pour davantage de ressources de calcul, les distributions sont remappées aux nœuds de calcul disponibles. Le nombre de nœuds calcul (entre 1 et 60) est déterminé par le niveau de service pour SQL Synapse.
Chaque nœud de calcul a un ID de nœud visible dans les vues système. Vous pouvez voir l’ID de nœud de calcul en effectuant une recherche dans la colonne node_id des vues système dont le nom commence par sys.pdw_nodes. Pour obtenir la liste de ces vues système, consultez Vues système Synapse SQL.
Service de déplacement de données
Le service de déplacement des données (DMS) est la technologie de transport de données qui coordonne le déplacement de données entre les nœuds de calcul. Certaines requêtes nécessitent un déplacement de données pour garantir que les requêtes parallèles renvoient des résultats précis. Quand un déplacement de données est requis, le service de déplacement des données veille à ce que les bonnes données aillent au bon emplacement.
Distributions
Une distribution est l’unité de base de stockage et de traitement pour des requêtes parallèles s’exécutant sur des données distribuées. Quand Synapse SQL exécute une requête, le travail est divisé en 60 requêtes plus petites qui s’exécutent en parallèle.
Chacune de ces 60 requêtes s’exécute sur l’une des distributions de données. Chaque nœud de calcul gère une ou plusieurs des 60 distributions. Un pool SQL dédié (anciennement SQL DW) disposant des ressources de calcul maximales possède une distribution par nœud de calcul. Un pool SQL dédié (anciennement SQL DW) disposant des ressources de calcul minimales possède toutes les distributions sur un nœud de calcul.
Notes
Pour obtenir des suggestions relative à la meilleure stratégie de distribution de tables à utiliser en fonction de vos charges de travail, consultez Azure Synapse SQL Distribution Advisor.
Tables distribuées par hachage
Une table distribuée de hachage peut offrir les meilleures performances de requête pour des jointures et agrégations sur des tables volumineuses.
Pour partitionner des données dans une table distribuée de hachage, une fonction de hachage est utilisée pour attribuer de manière déterministe chaque ligne à une distribution. Dans la définition de la table, une des colonnes est désignée comme colonne de distribution. La fonction de hachage utilise les valeurs figurant dans la colonne de distribution pour assigner chaque ligne à une distribution.
Le diagramme suivant illustre comment une table complète (non distribuée) est stockée sous forme de table distribuée par hachage.

- Chaque ligne appartient à une distribution.
- Un algorithme de hachage déterministe attribue chaque ligne à une distribution.
- Le nombre de lignes de table par distribution varie selon la taille des tables.
Des critères de performances, tels que la distinction, l’asymétrie des données et les types des requêtes exécutées sur le système, conditionnent le choix de la colonne de distribution.
Tables distribuées par tourniquet
Une table de type tourniquet (round robin) est la table la plus simple à créer. Elle offre des performances rapides quand elle est utilisée en tant que table intermédiaire pour les chargements.
Une table distribuée de type tourniquet (round robin) distribue uniformément les données sur la table, mais sans optimisation. Une distribution est tout d’abord choisie au hasard. Ensuite, des tampons de lignes sont affectés aux distributions de manière séquentielle. Le chargement de données dans une table de type tourniquet (round robin) est rapide, mais les performances des requête peuvent souvent être meilleures avec des tables distribuées de hachage. Des jointures sur des tables de type tourniquet (round robin) nécessitent un remaniement des données, qui nécessite un temps supplémentaire.
Tables répliquées
Une table répliquée offre les performances de requête les plus rapides pour des petites tables.
Une copie complète d’une table répliquée est mise en cache sur chaque nœud de calcul. Par conséquent, la réplication d’une table a pour effet d’éviter la nécessité de transférer des données entre nœuds de calcul avant une jointure ou une agrégation. Des tables répliquées sont utilisées de façon optimale avec des tables de petite taille. Un espace de stockage supplémentaire est nécessaire, et une surcharge additionnelle est engagée lors de l’écriture de données, ce qui rend peu pratique l’usage de tables volumineuses.
Le diagramme ci-dessous présente une table répliquée qui est mise en cache sur la première distribution sur chaque nœud de calcul.

Contenu connexe
Maintenant que vous en savez un peu plus sur Azure Synapse, apprenez à créer rapidement un pool SQL dédié (anciennement SQL DW) et à charger des exemples de données. Si vous débutez avec Azure, les concepts fondamentaux d’Azure peuvent vous être utiles lorsque vous rencontrez une nouvelle terminologie. Ou bien, consultez ces autres ressources d’Azure Synapse.