Optimisation des performances avec l'index columnstore en cluster ordonné dans Azure Synapse Analytics
S'applique à :Azure Synapse Analytics (pool SQL dédié uniquement)
Lorsque des utilisateurs interrogent une table columnstore dans le pool SQL dédié, l’optimiseur vérifie les valeurs minimales et maximales stockées dans chaque segment. Les segments en dehors des limites du prédicat de la requête ne sont pas lus à partir du disque vers la mémoire. Une requête peut se terminer plus rapidement si le nombre de segments à lire et leur taille totale sont faibles.
Remarque
Cet article s’applique à : Azure Synapse Analytics (pool SQL dédié uniquement) Pour plus d'informations sur les index columnstore ordonnés dans SQL Server et d'autres plates-formes SQL, voir Optimisation des performances avec les index columnstore ordonnés en cluster.
Index columnstore cluster ordonné et non ordonné
Par défaut, pour chaque table créée sans option d’index, un composant interne (générateur d’index) crée un index columnstore cluster non ordonné dessus. Les données incluses dans chaque colonne sont compressées dans un segment de rowgroup distinct de l’index columnstore cluster. Des métadonnées existent sur la plage de valeurs de chaque segment, si bien que les segments qui se trouvent en dehors des limites du prédicat de la requête ne sont pas lus à partir du disque pendant l’exécution de la requête. Un index columnstore cluster offre le niveau de compression de données le plus élevé et réduit la taille des segments à lire si bien que les requêtes peuvent s’exécuter plus rapidement. En revanche, étant donné que le générateur d’index ne trie pas les données avant de les compresser dans des segments, les segments peuvent avoir des plages de valeurs qui se chevauchent, ce qui oblige les requêtes à lire plus de segments à partir du disque et prolongent donc leur durée d’exécution.
Index columnstore en cluster ordonnés en activant l’élimination efficace des segments, ce qui entraîne des performances beaucoup plus rapides en ignorant de grandes quantités de données triées qui ne correspondent pas au prédicat de requête. Lors de la création d’un index columnstore cluster ordonné, le moteur du pool SQL dédié trie les données existantes en mémoire sur la ou les clés d’ordre avant que le générateur d’index ne les compresse dans des segments d’index. Avec les données triées, le chevauchement de segments est réduit, ce qui permet aux requêtes d’éliminer plus efficacement des segments et donc d’accélérer leurs performances, car le nombre de segments à lire à partir du disque est plus petit. Si toutes les données peuvent être triées en mémoire simultanément, le chevauchement de segments peut être évité. En raison des tables volumineuses dans les entrepôts de données, ce scénario ne se produit pas souvent.
Pour vérifier les plages de segments d’une colonne, exécutez la commande suivante avec le nom de la table et le nom de la colonne :
SELECT o.name, pnp.index_id,
cls.row_count, pnp.data_compression_desc,
pnp.pdw_node_id, pnp.distribution_id, cls.segment_id,
cls.column_id,
cls.min_data_id, cls.max_data_id,
cls.max_data_id-cls.min_data_id as difference
FROM sys.pdw_nodes_partitions AS pnp
JOIN sys.pdw_nodes_tables AS Ntables ON pnp.object_id = NTables.object_id AND pnp.pdw_node_id = NTables.pdw_node_id
JOIN sys.pdw_table_mappings AS Tmap ON NTables.name = TMap.physical_name AND substring(TMap.physical_name,40, 10) = pnp.distribution_id
JOIN sys.objects AS o ON TMap.object_id = o.object_id
JOIN sys.pdw_nodes_column_store_segments AS cls ON pnp.partition_id = cls.partition_id AND pnp.distribution_id = cls.distribution_id
JOIN sys.columns as cols ON o.object_id = cols.object_id AND cls.column_id = cols.column_id
WHERE o.name = '<Table Name>' and cols.name = '<Column Name>' and TMap.physical_name not like '%HdTable%'
ORDER BY o.name, pnp.distribution_id, cls.min_data_id;
Notes
Dans une table avec index columnstore cluster ordonnée, les nouvelles données résultant du même lot d’opérations DML ou de chargement de données sont triées dans ce lot : il n’y a pas de tri global de toutes les données de la table. Les utilisateurs peuvent reconstruire l’index columnstore cluster ordonné pour trier toutes les données de la table. Dans un pool SQL dédié, la reconstruction (REBUILD) de l’index columnstore est une opération hors connexion. Pour une table partitionnée, la reconstruction est effectuée une partition à la fois. Les données de la partition en cours de reconstruction sont « hors connexion » et ne sont pas disponibles tant que la reconstruction n’est pas terminée pour cette partition.
Performances des requêtes
Le gain de performance d’une requête d’un index columnstore cluster ordonné dépend des modèles de requête, de la taille des données, de la façon dont les données sont triées, de la structure physique des segments, et du DWU et de la classe de ressources choisis pour l’exécution de la requête. Les utilisateurs doivent passer en revue tous ces facteurs avant de choisir les colonnes de tri lors de la conception d’une table à index columnstore cluster ordonné.
Les requêtes avec tous ces modèles s’exécutent généralement plus rapidement avec des index columnstore cluster ordonnés.
- Les requêtes ont des prédicats d’égalité, d’inégalité ou de plage
- Les colonnes de prédicat et les colonnes d’index columnstore cluster ordonné sont les mêmes.
Dans cet exemple, la table T1 a un index columnstore cluster ordonné dans la séquence Col_C, Col_B et Col_A.
CREATE CLUSTERED COLUMNSTORE INDEX MyOrderedCCI ON T1
ORDER (Col_C, Col_B, Col_A);
Les performances de la requête 1 et de la requête 2 peuvent tirer meilleur parti de l’ICC trié par rapport aux autres requêtes, car elles référencent toutes les colonnes ICC ordonnées.
-- Query #1:
SELECT * FROM T1 WHERE Col_C = 'c' AND Col_B = 'b' AND Col_A = 'a';
-- Query #2
SELECT * FROM T1 WHERE Col_B = 'b' AND Col_C = 'c' AND Col_A = 'a';
-- Query #3
SELECT * FROM T1 WHERE Col_B = 'b' AND Col_A = 'a';
-- Query #4
SELECT * FROM T1 WHERE Col_A = 'a' AND Col_C = 'c';
Performances du chargement des données
Les performances du chargement des données dans une table à index columnstore cluster ordonné sont similaires à celles d’une table partitionnée. Le chargement des données dans une table à index columnstore cluster ordonné peut prendre plus de temps que dans une table à index columnstore cluster non-ordonné en raison de l’opération de tri des données. Toutefois, les requêtes peuvent s’exécuter plus rapidement après avec l’index columnstore cluster ordonné.
Voici un exemple de comparaison des performances du chargement des données dans des tables avec des schémas différents.
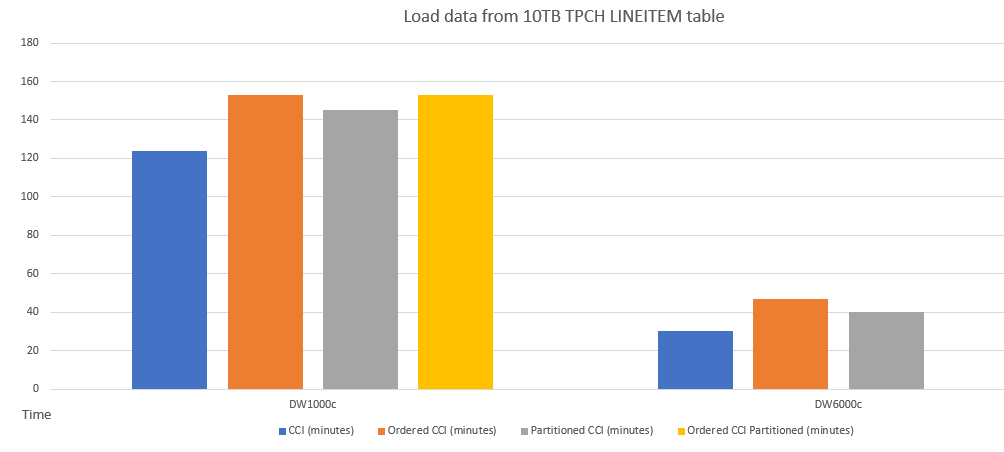
Voici un exemple de comparaison des performances de requête entre index columnstore cluster et index columnstore cluster ordonné.
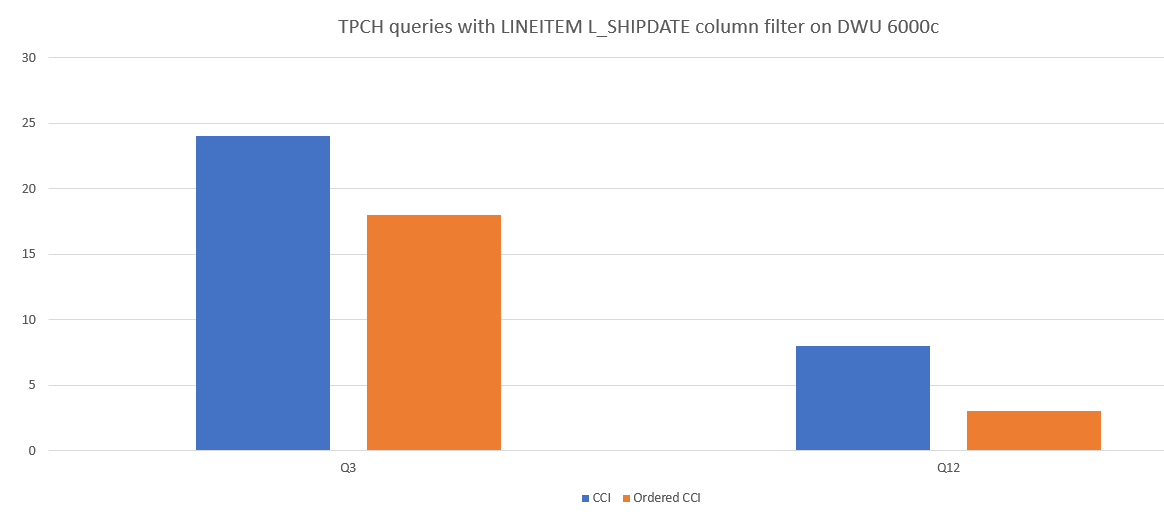
Réduire le chevauchement de segments
Le nombre de segments qui se chevauchent dépend de la taille des données à trier, de la mémoire disponible et du paramètre de degré maximal de parallélisme (MAXDOP) durant la création d’un index columnstore cluster ordonné. Les stratégies suivantes réduisent le chevauchement des segments lors de la création d’un index columnstore cluster (CCI) ordonné.
Utilisez la classe de ressources
xlargercsur un DWU supérieur afin d’autoriser davantage de mémoire pour le tri des données avant que le générateur d’index compresse les données en segments. Une fois dans un segment d’index, l’emplacement physique des données n’est plus modifiable. Il n’y a pas de tri des données au sein d’un segment ou entre des segments.Créez un index columnstore cluster ordonné avec
OPTION (MAXDOP = 1). Chaque thread utilisé pour la création d’un index columnstore cluster ordonné fonctionne sur un sous-ensemble des données et les trie localement. Il n’y a pas de tri global sur les données triées par différents threads. L’utilisation de threads parallèles peut réduire le temps nécessaire à la création d’un index columnstore cluster ordonné, mais génère plus de segments qui se chevauchent que l’utilisation d’un thread unique. L’utilisation d’une seule opération avec threads offre la qualité de compression la plus élevée. Par exemple :
CREATE TABLE Table1 WITH (DISTRIBUTION = HASH(c1), CLUSTERED COLUMNSTORE INDEX ORDER(c1) )
AS SELECT * FROM ExampleTable
OPTION (MAXDOP 1);
Notes
Actuellement, dans les pools SQL dédiés dans Azure Synapse Analytics, l’option MAXDOP n’est prise en charge que lors de la création d’une table CCI ordonnée à l’aide de la commande CREATE TABLE AS SELECT. La création d’un CCI ordonné via les commandes CREATE INDEX ou CREATE TABLE ne prend pas en charge l’option MAXDOP. Cette limitation ne s’applique pas aux versions SQL Server 2022 et ultérieures, où vous pouvez spécifier MAXDOP avec les commandes CREATE INDEX ou CREATE TABLE.
- Pré-triez les données par clé ou clés de tri avant de les charger dans des tables.
Voici un exemple de distribution de table à index columnstore cluster ordonné sans aucun segment qui se chevauche après l’application des recommandations ci-dessus. La table avec index columnstore cluster ordonné est créée dans une base de données DWU1000c via CTAS à partir d’une table de segments de mémoire de 20 Go utilisant MAXDOP 1 et xlargerc. L’index columnstore cluster ordonné est ordonné sur une colonne BIGINT sans doublons.
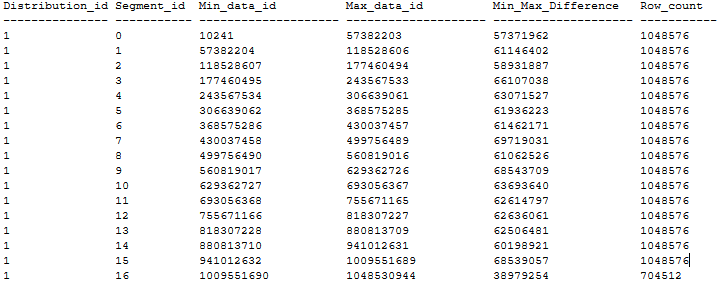
Créer un index columnstore cluster ordonné sur des tables volumineuses
La création d’un index columnstore cluster ordonné est une opération hors connexion. Pour des tables sans partitions, les données ne sont pas accessibles aux utilisateurs tant que le processus de création de l’index columnstore cluster ordonné n’est pas terminé. Pour des tables partitionnées, dans la mesure où le moteur crée la partition d’index columnstore cluster ordonné par partition, les utilisateurs peuvent quand même accéder aux données dans les partitions pour lesquelles la création du index columnstore cluster ordonné n’est pas en cours. Vous pouvez utiliser cette option pour minimiser le temps d’arrêt lors de la création d’un index columnstore cluster ordonné sur des tables volumineuses :
- Créez des partitions sur la grande table cible (appelée
Table_A). - Créez une table d’index columnstore cluster ordonné vide (appelée
Table_B) avec les mêmes table et schéma de partition queTable_A. - Basculez une partition de
Table_AversTable_B. - Exécutez
ALTER INDEX <Ordered_CCI_Index> ON <Table_B> REBUILD PARTITION = <Partition_ID>pour régénérer la partition basculée surTable_B. - Répétez les étapes 3 et 4 pour chaque partition dans
Table_A. - Une fois toutes les partitions basculées de
Table_AversTable_Bet régénérées, laissezTable_Aet renommezTable_BenTable_A.
Conseil
Pour une table de pool SQL dédiée avec un index columnstore cluster ordonné, ALTER INDEX REBUILD re-trie les données en utilisant tempdb. Surveillez tempdb pendant les opérations de régénération. Si vous avez besoin de davantage d’espace tempdb, effectuez un scale-up du pool. Réeffectuez un scale down une fois la reconstruction d’index terminée.
Pour une table de pool SQL dédiée avec un index columnstore cluster ordonné, ALTER INDEX REORGANIZE ne retrie pas les données. Pour retrier les données, utilisez ALTER INDEX REBUILD.
Pour plus d’informations sur la maintenance des index columnstore cluster ordonnés, consultez Optimisation des index columnstore cluster.
Différences dans les fonctionnalités de SQL Server 2022
SQL Server 2022 (16.x) a introduit des index columnstore cluster ordonnés similaires à la fonctionnalité dans des pools dédiés Azure Synapse.
- Actuellement, seuls SQL Server 2022 (16.x) et versions ultérieures prennent en charge les fonctionnalités améliorées d’élimination de segment de columnstore cluster pour les types de données string, binary et guid, et le type de données datetimeoffset pour une échelle supérieure à deux. Précédemment, cette élimination de segment était appliquée aux types de données numériques, de date et d’heure et au type de données datetimeoffset avec une échelle inférieure ou égale à deux.
- Actuellement, seul SQL Server 2022 (16.x) et versions ultérieures prend en charge l’élimination de rowgroup de columnstore cluster pour le préfixe de prédicats
LIKE, par exemplecolumn LIKE 'string%'. L’élimination des segments n’est pas prise en charge pour l’utilisation hors préfixe de LIKE, par exemplecolumn LIKE '%string'.
Pour plus d’informations, consultez Nouveautés des index columnstore.
Exemples
R. Pour vérifier les colonnes ordonnées et le numéro d’ordre :
SELECT object_name(c.object_id) table_name, c.name column_name, i.column_store_order_ordinal
FROM sys.index_columns i
JOIN sys.columns c ON i.object_id = c.object_id AND c.column_id = i.column_id
WHERE column_store_order_ordinal <>0;
B. Pour modifier un numéro de colonne, ajouter ou supprimer des colonnes dans la liste des ordres ou passer d’un index columnstore cluster à un index columnstore cluster ordonné :
CREATE CLUSTERED COLUMNSTORE INDEX InternetSales ON dbo.InternetSales
ORDER (ProductKey, SalesAmount)
WITH (DROP_EXISTING = ON);
Étapes suivantes
- Pour obtenir des conseils supplémentaires, consultez la vue d’ensemble du développement.
- Index columnstore : Vue d’ensemble
- Nouveautés des index columnstore
- Index columnstore - Guide de conception
- Index columnstore - Performances des requêtes