Notes
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
S’applique aux : ✔️ Machines virtuelles Linux ✔️ Machines virtuelles Windows ✔️ Groupes identiques flexibles ✔️ Groupes identiques uniformes
L’interface de passage de messages (MPI) est une bibliothèque ouverte et une norme de facto pour la parallélisation de la mémoire distribuée. Elle est couramment utilisée dans de nombreuses charges de travail HPC. Les charges de travail HPC sur les machines virtuelles RDMA Série HB et Série N peuvent utiliser MPI pour communiquer sur le réseau InfiniBand à faible latence et à bande passante élevée.
- Les tailles des machines virtuelles SR-IOV activées sur Azure permettent d’utiliser presque tous les qualificateurs de MPI avec Mellanox OFED.
- Sur les machines virtuelles non compatibles SR-IOV, les implémentations MPI prises en charge utilisent l’interface Microsoft Network Direct (ND) pour la communication entre les machines virtuelles. Par conséquent, seules les versions Microsoft MPI (MS-MPI) 2012 R2 ou ultérieures et Intel MPI 5.x sont supportées. Les versions ultérieures (2017, 2018) de la bibliothèque runtime MPI Intel peuvent ne pas être compatibles avec les pilotes Azure RDMA.
Pour les machines virtuelles compatibles SR-IOV RDMA, images de machine virtuelle Ubuntu-HPC et images de machine virtuelle AlmaLinux-HPC conviennent. Ces images de machine virtuelle sont optimisées et préchargées avec les pilotes OFED pour RDMA ainsi que les diverses bibliothèques MPI et packages de calcul scientifique couramment utilisés. elles constituent le moyen le plus simple de commencer.
Les exemples de cette procédure illustrent la syntaxe RHEL, mais les étapes sont générales et peuvent être utilisées pour tout système d’exploitation compatible, par exemple Ubuntu (18.04, 20.04, 22.04) et SLES (12 SP4 et 15 SP4). Vous trouverez plus d’exemples sur la configuration d’autres implémentations MPI sur d’autres distributions dans le référentiel azhpc-images.
Notes
L’exécution de travaux MPI sur des machines virtuelles compatibles SR-IOV avec certaines bibliothèques MPI (par exemple Platform MPI) peut nécessiter l’installation de clés de partition (p-keys) sur un locataire pour l’isolation et la sécurité. Suivez les étapes de la section Découvrir les clés de partition pour en savoir plus sur la détermination des valeurs des p-keys et leur configuration correcte pour un travail MPI avec la bibliothèque MPI.
Notes
Les extraits de code ci-dessous sont des exemples. Nous vous recommandons d’utiliser les dernières versions stables des packages ou de faire référence au référentiel azhpc-images.
Choix de la bibliothèque MPI
Si une application HPC recommande une bibliothèque MPI particulière, essayez d’abord cette version. Si vous disposez d’une certaine flexibilité quant au choix de votre MPI et que vous souhaitez obtenir des performances optimales, essayez HPC-X. Dans l’ensemble, l’interface MPI HPC-X offre les meilleures performances en utilisant l’infrastructure UCX pour l’interface InfiniBand et tire parti de toutes les capacités matérielles et logicielles de Mellanox InfiniBand. De plus, HPC-X et OpenMPI sont compatibles avec l’ABI. Vous pouvez donc exécuter dynamiquement une application HPC avec HPC-X qui a été créée avec OpenMPI. De même, Intel MPI, MVAPICH et MPICH sont compatibles avec l’ABI.
La figure suivante illustre l’architecture des bibliothèques MPI les plus courantes.
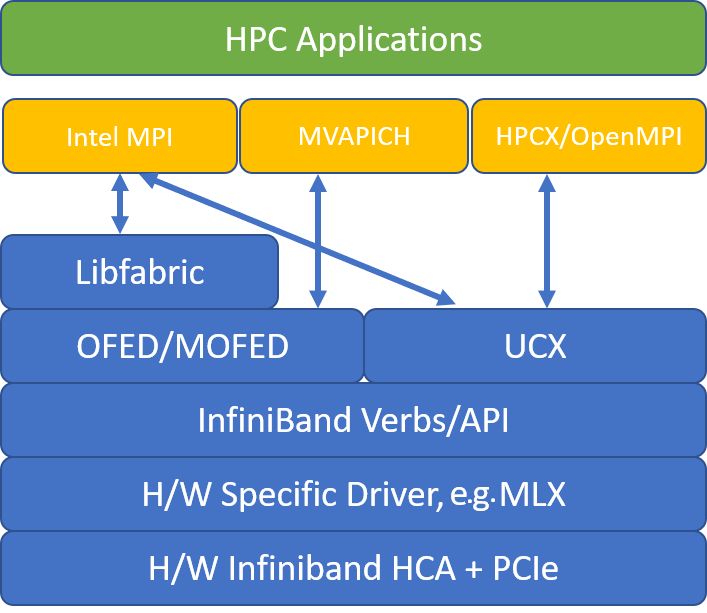
HPC-X
Le kit d’outils logiciels HPC-X contient UCX et HCOLL et peut être créé sur UCX.
HPCX_VERSION="v2.6.0"
HPCX_DOWNLOAD_URL=https://azhpcstor.blob.core.windows.net/azhpc-images-store/hpcx-v2.6.0-gcc-MLNX_OFED_LINUX-5.0-1.0.0.0-redhat7.7-x86_64.tbz
wget --retry-connrefused --tries=3 --waitretry=5 $HPCX_DOWNLOAD_URL
tar -xvf hpcx-${HPCX_VERSION}-gcc-MLNX_OFED_LINUX-5.0-1.0.0.0-redhat7.7-x86_64.tbz
mv hpcx-${HPCX_VERSION}-gcc-MLNX_OFED_LINUX-5.0-1.0.0.0-redhat7.7-x86_64 ${INSTALL_PREFIX}
HPCX_PATH=${INSTALL_PREFIX}/hpcx-${HPCX_VERSION}-gcc-MLNX_OFED_LINUX-5.0-1.0.0.0-redhat7.7-x86_64
La commande suivante illustre certains arguments mpirun recommandés pour HPC-X et OpenMPI.
mpirun -n $NPROCS --hostfile $HOSTFILE --map-by ppr:$NUMBER_PROCESSES_PER_NUMA:numa:pe=$NUMBER_THREADS_PER_PROCESS -report-bindings $MPI_EXECUTABLE
où :
| Paramètre | Description |
|---|---|
NPROCS |
Spécifie le nombre de processus MPI. Par exemple : -n 16. |
$HOSTFILE |
Spécifie un fichier contenant le nom d'hôte ou l'adresse IP, pour indiquer l'emplacement d'exécution des processus MPI. Par exemple : --hostfile hosts. |
$NUMBER_PROCESSES_PER_NUMA |
Spécifie le nombre de processus MPI exécutés dans chaque domaine NUMA. Par exemple, pour spécifier quatre processus MPI par NUMA, vous utilisez --map-by ppr:4:numa:pe=1. |
$NUMBER_THREADS_PER_PROCESS |
Spécifie le nombre de threads par processus MPI. Par exemple, pour spécifier un processus MPI et quatre threads par NUMA, vous utilisez --map-by ppr:1:numa:pe=4. |
-report-bindings |
Imprime le mappage des processus MPI aux cœurs, ce qui est utile pour vérifier que l’épinglage de votre processus MPI est correct. |
$MPI_EXECUTABLE |
Spécifie le fichier exécutable MPI généré avec la liaison dans les bibliothèques MPI. Les wrappers de compilateur MPI effectuent cette opération automatiquement. Par exemple, mpicc ou mpif90. |
Voici un exemple d’exécution du micropoint de référence de la latence OSU :
${HPCX_PATH}mpirun -np 2 --map-by ppr:2:node -x UCX_TLS=rc ${HPCX_PATH}/ompi/tests/osu-micro-benchmarks-5.3.2/osu_latency
Optimisation des collectifs MPI
Les primitives de communication de collectifs MPI fournissent un moyen flexible et portable d’implémenter des opérations de communication de groupe. Elles sont largement utilisées dans plusieurs applications scientifiques parallèles et ont un impact significatif sur les performances globales d’application. Reportez-vous à l'article TechCommunity pour plus d’informations sur les paramètres de configuration afin d’optimiser les performances de communication collective à l’aide de HPC-X et de la bibliothèque HCOLL pour la communication collective.
Par exemple, si vous soupçonnez votre application MPI étroitement couplée d’effectuer une quantité excessive de communications collectives, vous pouvez essayer d’activer les hiérarchies collectives (HCOLL). Pour activer ces fonctionnalités, utilisez les paramètres suivants.
-mca coll_hcoll_enable 1 -x HCOLL_MAIN_IB=<MLX device>:<Port>
Notes
Avec HPC-X 2.7.4+, il peut être nécessaire de passer explicitement LD_LIBRARY_PATH si la version UCX sur MOFED est différente de celle de HPC-X.
OpenMPI
Installez UCX comme décrit ci-dessus. HCOLL fait partie du kit d’outils logiciels HPC-X et ne nécessite pas d’installation spéciale.
Vous pouvez installer OpenMPI à partir des packages disponibles dans le référentiel.
sudo yum install –y openmpi
Nous vous recommandons de créer une dernière version stable d’OpenMPI avec UCX.
OMPI_VERSION="4.0.3"
OMPI_DOWNLOAD_URL=https://download.open-mpi.org/release/open-mpi/v4.0/openmpi-${OMPI_VERSION}.tar.gz
wget --retry-connrefused --tries=3 --waitretry=5 $OMPI_DOWNLOAD_URL
tar -xvf openmpi-${OMPI_VERSION}.tar.gz
cd openmpi-${OMPI_VERSION}
./configure --prefix=${INSTALL_PREFIX}/openmpi-${OMPI_VERSION} --with-ucx=${UCX_PATH} --with-hcoll=${HCOLL_PATH} --enable-mpirun-prefix-by-default --with-platform=contrib/platform/mellanox/optimized && make -j$(nproc) && make install
Pour des performances optimales, exécutez OpenMPI avec ucx et hcoll. Consultez également l’exemple avec HPC-X.
${INSTALL_PREFIX}/bin/mpirun -np 2 --map-by node --hostfile ~/hostfile -mca pml ucx --mca btl ^vader,tcp,openib -x UCX_NET_DEVICES=mlx5_0:1 -x UCX_IB_PKEY=0x0003 ./osu_latency
Vérifiez votre clé de partition comme indiqué ci-dessus.
Intel MPI
Téléchargez la version Intel MPI de votre choix. La version 2019 d’Intel MPI est passée de l’infrastructure Open Fabrics Alliance (OFA) à l’infrastructure Open Fabrics Interfaces (OFI) et prend actuellement en charge libfabric. Il existe deux fournisseurs pour la prise en charge InfiniBand : mlx et verbs. Modifiez la variable d’environnement I_MPI_FABRICS selon la version.
- Intel MPI 2019 et 2021 : utilisez
I_MPI_FABRICS=shm:ofi,I_MPI_OFI_PROVIDER=mlx. Le fournisseurmlxutilise UCX. Il a été noté que l’utilisation de verbes était instable et moins performante. Consultez l’article TechCommunity pour plus de détails. - Intel MPI 2018 : utilisez
I_MPI_FABRICS=shm:ofa - Intel MPI 2016 : utilisez
I_MPI_DAPL_PROVIDER=ofa-v2-ib0
Voici quelques suggestions d’arguments mpirun pour MPI 2019 update 5+.
export FI_PROVIDER=mlx
export I_MPI_DEBUG=5
export I_MPI_PIN_DOMAIN=numa
mpirun -n $NPROCS -f $HOSTFILE $MPI_EXECUTABLE
où :
| Paramètre | Description |
|---|---|
FI_PROVIDER |
Spécifie le fournisseur libfabric à utiliser, ce qui aura un impact sur l’API, le protocole et le réseau utilisés. « verbs » est une autre option, mais « mlx » offre généralement de meilleures performances. |
I_MPI_DEBUG |
Spécifie le niveau de sortie de débogage supplémentaire, ce qui peut fournir des détails sur l’emplacement d’épinglage des processus, ainsi que sur le protocole et le réseau utilisés. |
I_MPI_PIN_DOMAIN |
Spécifie la façon dont vous souhaitez épingler vos processus. Par exemple, vous pouvez épingler au niveau des cœurs, sockets ou domaines NUMA. Dans cet exemple, vous définissez cette variable d’environnement sur « numa », ce qui signifie que les processus seront épinglés au niveau des domaines de nœud NUMA. |
Optimisation des collectifs MPI
Vous pouvez essayer d’autres options, en particulier si les opérations collectives prennent beaucoup de temps. Intel MPI 2019 update 5+ prend en charge le fournisseur mlx et utilise le framework UCX pour communiquer avec InfiniBand. Il prend également en charge HCOLL.
export FI_PROVIDER=mlx
export I_MPI_COLL_EXTERNAL=1
Machines virtuelles non SR-IOV
Pour les machines virtuelles non SR-IOV, voici un exemple de téléchargement de la version d’évaluation gratuite du runtime 5.x :
wget http://registrationcenter-download.intel.com/akdlm/irc_nas/tec/9278/l_mpi_p_5.1.3.223.tgz
Pour les étapes d’installation, consultez le Guide d’installation de la bibliothèque Intel MPI. Vous pouvez aussi activer ptrace pour les processus non-racine et non-débogueur (nécessaire pour les versions les plus récentes d’Intel MPI).
echo 0 | sudo tee /proc/sys/kernel/yama/ptrace_scope
SUSE Linux
Pour les versions d’images de machines virtuelles SUSE Linux Enterprise Server - SLES 12 SP3 pour HPC, SLES 12 SP3 pour HPC (Premium), SLES 12 SP1 pour HPC, SLES 12 SP1 pour HPC (Premium), SLES 12 SP4 et SLES 15, les pilotes RDMA sont installés et les packages Intel MPI sont distribués sur la machine virtuelle. Installez Intel MPI en exécutant la commande suivante :
sudo rpm -v -i --nodeps /opt/intelMPI/intel_mpi_packages/*.rpm
MVAPICH
Voici un exemple de construction de MVAPICH2. Notez que des versions plus récentes que celle utilisée ci-dessous peuvent être disponibles.
wget http://mvapich.cse.ohio-state.edu/download/mvapich/mv2/mvapich2-2.3.tar.gz
tar -xv mvapich2-2.3.tar.gz
cd mvapich2-2.3
./configure --prefix=${INSTALL_PREFIX}
make -j 8 && make install
Voici un exemple d’exécution du micropoint de référence de la latence OSU :
${INSTALL_PREFIX}/bin/mpirun_rsh -np 2 -hostfile ~/hostfile MV2_CPU_MAPPING=48 ./osu_latency
La liste suivante contient plusieurs arguments mpirun recommandés.
export MV2_CPU_BINDING_POLICY=scatter
export MV2_CPU_BINDING_LEVEL=numanode
export MV2_SHOW_CPU_BINDING=1
export MV2_SHOW_HCA_BINDING=1
mpirun -n $NPROCS -f $HOSTFILE $MPI_EXECUTABLE
où :
| Paramètre | Description |
|---|---|
MV2_CPU_BINDING_POLICY |
Spécifie la stratégie de liaison à utiliser, ce qui aura une incidence sur la façon dont les processus sont épinglés aux ID des cœurs. Dans ce cas, vous spécifiez scatter, afin que les processus soient répartis uniformément entre les domaines NUMA. |
MV2_CPU_BINDING_LEVEL |
Spécifie où épingler les processus. Dans ce cas, vous l’avez défini sur « numanode », ce qui signifie que les processus sont épinglés aux unités de domaines NUMA. |
MV2_SHOW_CPU_BINDING |
Spécifie si vous souhaitez obtenir des informations de débogage sur l’emplacement où les processus sont épinglés. |
MV2_SHOW_HCA_BINDING |
Spécifie si vous souhaitez obtenir des informations de débogage sur l’adaptateur de canal hôte (HCA) utilisé pour chaque processus. |
Platform MPI
Installez les packages requis pour Platform MPI Community Edition.
sudo yum install libstdc++.i686
sudo yum install glibc.i686
Download platform MPI at https://www.ibm.com/developerworks/downloads/im/mpi/index.html
sudo ./platform_mpi-09.01.04.03r-ce.bin
Suivez le processus d’installation.
MPICH
Installez UCX comme décrit ci-dessus. Créez MPICH.
wget https://www.mpich.org/static/downloads/3.3/mpich-3.3.tar.gz
tar -xvf mpich-3.3.tar.gz
cd mpich-3.3
./configure --with-ucx=${UCX_PATH} --prefix=${INSTALL_PREFIX} --with-device=ch4:ucx
make -j 8 && make install
Exécution de MPICH.
${INSTALL_PREFIX}/bin/mpiexec -n 2 -hostfile ~/hostfile -env UCX_IB_PKEY=0x0003 -bind-to hwthread ./osu_latency
Vérifiez votre clé de partition comme indiqué ci-dessus.
OSU MPI Benchmarks
Téléchargez OSU MPI Benchmarks et décompressez le fichier.
wget http://mvapich.cse.ohio-state.edu/download/mvapich/osu-micro-benchmarks-5.5.tar.gz
tar –xvf osu-micro-benchmarks-5.5.tar.gz
cd osu-micro-benchmarks-5.5
Créez des bancs d’essai à l’aide d’une bibliothèque MPI particulière :
CC=<mpi-install-path/bin/mpicc>CXX=<mpi-install-path/bin/mpicxx> ./configure
make
MPI Benchmarks se trouve dans le dossier mpi/.
Découvrir les clés de partition
Découvrez les clés de partition (p-keys) pour communiquer avec d’autres machines virtuelles au sein du même locataire (groupe à haute disponibilité ou groupe de machines virtuelles identiques).
/sys/class/infiniband/mlx5_0/ports/1/pkeys/0
/sys/class/infiniband/mlx5_0/ports/1/pkeys/1
La plus grande des deux est la clé de locataire, qui doit être utilisée avec MPI. Exemple : Si les éléments suivants sont les p-keys, 0x800b doit être utilisé avec MPI.
cat /sys/class/infiniband/mlx5_0/ports/1/pkeys/0
0x800b
cat /sys/class/infiniband/mlx5_0/ports/1/pkeys/1
0x7fff
Remarque : les interfaces sont nommées comme mlx5_ib* dans les images de machine virtuelle HPC.
Notez également que tant que le locataire (groupe à haute disponibilité ou groupe de machines virtuelles identiques) existe, les PKEY restent les mêmes. Cela est vrai même lorsque les nœuds sont ajoutés ou supprimés. Les nouveaux locataires obtiennent des PKEYs différents.
Configurez un nombre limite d’utilisateurs pour MPI
Configurez un nombre limite d’utilisateurs pour MPI.
cat << EOF | sudo tee -a /etc/security/limits.conf
* hard memlock unlimited
* soft memlock unlimited
* hard nofile 65535
* soft nofile 65535
EOF
Configurez les clés SSH pour MPI
Configurer les clés SSH pour les types de MPI qui en ont besoin.
ssh-keygen -f /home/$USER/.ssh/id_rsa -t rsa -N ''
cat << EOF > /home/$USER/.ssh/config
Host *
StrictHostKeyChecking no
EOF
cat /home/$USER/.ssh/id_rsa.pub >> /home/$USER/.ssh/authorized_keys
chmod 600 /home/$USER/.ssh/authorized_keys
chmod 644 /home/$USER/.ssh/config
La syntaxe ci-dessus suppose un répertoire personnel partagé, sinon le répertoire .ssh doit être copié sur chaque nœud.
Étapes suivantes
- En savoir plus sur les machines virtuelles Série HB et Série N avec InfiniBand
- Consultez la Présentation de la série HBv3 et la Présentation de la série HC.
- Lisez Placement optimal du processus d’interface de passage de messages pour les machines virtuelles de la série HB.
- Consultez les dernières annonces, des exemples de charge de travail HPC et les résultats des performances sur les blogs de la communauté Azure Compute Tech.
- Pour une vision plus globale de l’architecture d’exécution des charges de travail HPC, consultez Calcul haute performance (HPC) sur Azure.