Configurer Pacemaker sur Red Hat Enterprise Linux dans Azure
Cet article explique comment configurer un cluster Pacemaker de base sur Red Hat Enterprise Server (RHEL). Les instructions couvrent RHEL 7, RHEL 8 et RHEL 9.
Prérequis
Commencez par lire les notes et publications SAP suivantes :
- Note SAP 1928533, qui contient :
- Liste des tailles de machine virtuelle Azure prises en charge pour le déploiement de logiciels SAP.
- Des informations importantes sur la capacité en fonction de la taille des machines virtuelles Azure.
- Combinaisons de logiciels et de systèmes d’exploitation SAP (SYSTÈME d’exploitation) et de bases de données prises en charge.
- La version du noyau SAP requise pour Windows et Linux sur Microsoft Azure.
- La note SAP 2015553 répertorie les conditions préalables au déploiement de logiciels SAP pris en charge par SAP sur Azure.
- Note SAP 2002167 recommande les paramètres du système d’exploitation pour Red Hat Enterprise Linux.
- Note SAP 3108316 recommande les paramètres du système d’exploitation pour Red Hat Enterprise Linux 9.x.
- La note SAP 2009879 conseille sur SAP HANA pour Red Hat Enterprise Linux.
- La note SAP 3108302 contient des instructions SAP HANA pour Red Hat Enterprise Linux 9.x.
- La note SAP 2178632 contient des informations détaillées sur toutes les métriques de surveillance rapportées pour SAP sur Azure.
- La note SAP 2191498 contient la version requise de l’agent hôte SAP pour Linux sur Azure.
- La note SAP 2243692 contient des informations sur les licences SAP sur Linux dans Azure.
- La note SAP 1999351 contient des informations supplémentaires sur le dépannage de l’extension Azure Enhanced Monitoring pour SAP.
- Le WIKI de la communauté SAP contient toutes les notes SAP requises pour Linux.
- Planification et implémentation de machines virtuelles Azure pour SAP sur Linux
- Déploiement de machines virtuelles Azure pour SAP sur Linux (cet article)
- Déploiement SGBD de machines virtuelles Azure pour SAP sur Linux
- Réplication du système SAP HANA dans un cluster Pacemaker
- Documentation RHEL générale :
- Documentation RHEL spécifique à Azure :
- Stratégies de support pour les clusters À haute disponibilité RHEL - Microsoft Azure Machines Virtuelles en tant que membres du cluster
- Installation et configuration d’un cluster à haute disponibilité Red Hat Enterprise Linux 7.4 (et versions ultérieures) sur Microsoft Azure
- Considérations relatives à l’adoption de RHEL 8 - Haute disponibilité et clusters
- Configure SAP S/4HANA ASCS/ERS with Standalone Enqueue Server 2 (ENSA2) in Pacemaker on RHEL 7.6 (Configurer SAP S/4HANA ASC/ERS avec le serveur de file d’attente autonome 2 (ENSA2) dans Pacemaker sur RHEL 7.6)
- Offres RHEL pour SAP sur Azure
Installation du cluster
Remarque
Red Hat ne prend pas en charge un espion émulé par logiciel. Red Hat ne prend pas en charge SBD sur des plateformes cloud. Pour plus d’informations, consultez Stratégies de support pour les clusters À haute disponibilité RHEL - sbd et fence_sbd.
Le seul mécanisme de délimitation pris en charge pour les clusters Pacemaker RHEL sur Azure est un agent de clôture Azure.
Les éléments suivants sont précédés de :
- [A] : applicable à tous les nœuds
- [1] : applicable uniquement au nœud 1
- [2] : applicable uniquement au nœud 2
Les différences dans les commandes ou la configuration entre RHEL 7 et RHEL 8/RHEL 9 sont marquées dans le document.
[A] Inscrire. Cette étape est facultative. Si vous utilisez des images avec haute disponibilité RHEL SAP, cette étape n’est pas nécessaire.
Par exemple, si vous déployez sur RHEL 7, inscrivez votre machine virtuelle et attachez-la à un pool qui contient des référentiels pour RHEL 7.
sudo subscription-manager register # List the available pools sudo subscription-manager list --available --matches '*SAP*' sudo subscription-manager attach --pool=<pool id>Lorsque vous attachez un pool à une image RHEL de paiement à l’utilisation Place de marché Azure, vous êtes effectivement double facturé pour votre utilisation de RHEL. Vous êtes facturé une fois pour l’image de paiement à l’utilisation et une fois pour le droit RHEL dans le pool que vous attachez. Pour atténuer cette situation, Azure fournit désormais des images RHEL bring-your-own-subscription. Pour plus d’informations, consultez Images Azure bring-your-own-subscription (Apportez votre propre abonnement) de Red Hat Enterprise Linux.
[A] Activer RHEL pour les référentiels SAP. Cette étape est facultative. Si vous utilisez des images avec haute disponibilité RHEL SAP, cette étape n’est pas nécessaire.
Pour installer les packages requis sur RHEL 7, activez les référentiels suivants :
sudo subscription-manager repos --disable "*" sudo subscription-manager repos --enable=rhel-7-server-rpms sudo subscription-manager repos --enable=rhel-ha-for-rhel-7-server-rpms sudo subscription-manager repos --enable=rhel-sap-for-rhel-7-server-rpms sudo subscription-manager repos --enable=rhel-ha-for-rhel-7-server-eus-rpms[A] Installez le module complémentaire RHEL HA.
sudo yum install -y pcs pacemaker fence-agents-azure-arm nmap-ncatImportant
Nous vous recommandons les versions suivantes de l’agent de clôture Azure (ou version ultérieure) pour que les clients bénéficient d’un temps de basculement plus rapide, si un arrêt de ressource échoue ou que les nœuds de cluster ne peuvent plus communiquer entre eux :
RHEL 7.7 ou version ultérieure utilise la dernière version disponible du package d’agents de clôture.
RHEL 7.6 : fence-agents-4.2.1-11.el7_6.8
RHEL 7.5 : fence-agents-4.0.11-86.el7_5.8
RHEL 7.4 : fence-agents-4.0.11-66.el7_4.12
Pour plus d’informations, consultez la machine virtuelle Azure s’exécutant en tant que membre de cluster haute disponibilité RHEL prend beaucoup de temps pour être clôturée, ou l’isolation échoue/expire avant l’arrêt de la machine virtuelle.
Important
Nous vous recommandons les versions suivantes de l’agent de clôture Azure (ou version ultérieure) pour les clients qui souhaitent utiliser des identités managées pour les ressources Azure au lieu de noms de principal de service pour l’agent de clôture :
RHEL 8.4 : clôture-agents-4.2.1-54.el8.
RHEL 8.2 : fence-agents-4.2.1-41.el8_2.4
RHEL 8.1 : fence-agents-4.2.1-30.el8_1.4
RHEL 7.9 : fence-agents-4.2.1-41.el7_9.4.
Important
Sur RHEL 9, nous vous recommandons les versions de package suivantes (ou version ultérieure) pour éviter les problèmes liés à l’agent de clôture Azure :
fence-agents-4.10.0-20.el9_0.7
fence-agents-common-4.10.0-20.el9_0.6
ha-cloud-support-4.10.0-20.el9_0.6.x86_64.rpm
Vérifiez la version de l’agent de clôture Azure. Si nécessaire, mettez-le à jour vers la version minimale requise ou ultérieure.
# Check the version of the Azure Fence Agent sudo yum info fence-agents-azure-armImportant
Si vous devez mettre à jour l’agent de clôture Azure et si vous utilisez un rôle personnalisé, veillez à mettre à jour le rôle personnalisé pour inclure l’action powerOff. Pour plus d’informations, consultez Créer un rôle personnalisé pour l’agent de clôture.
Si vous effectuez un déploiement sur RHEL 9, installez également les agents de ressources pour le déploiement cloud.
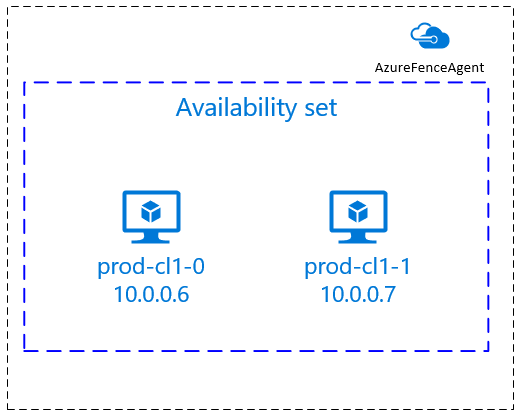
sudo yum install -y resource-agents-cloud[A] Configurer la résolution du nom d’hôte.
Vous pouvez utiliser un serveur DNS ou modifier le fichier
/etc/hostssur tous les nœuds. Cet exemple vous explique comment utiliser le fichier/etc/hosts. Remplacez l’adresse IP et le nom d’hôte dans les commandes suivantes.Important
Si vous utilisez des noms d’hôte dans la configuration du cluster, il est essentiel d’avoir une résolution de nom d’hôte fiable. La communication du cluster échoue si les noms ne sont pas disponibles, ce qui peut entraîner des retards de basculement de cluster.
L’avantage de l’utilisation
/etc/hostsest que votre cluster devient indépendant du DNS, ce qui peut être un point unique d’échecs également.sudo vi /etc/hostsInsérez les lignes suivantes dans
/etc/hosts. Changez l’adresse IP et le nom d’hôte en fonction de votre environnement.# IP address of the first cluster node 10.0.0.6 prod-cl1-0 # IP address of the second cluster node 10.0.0.7 prod-cl1-1[A] Remplacez le
haclustermot de passe par le même mot de passe.sudo passwd hacluster[A] Ajoutez des règles de pare-feu pour Pacemaker.
Ajoutez les règles de pare-feu suivantes à toutes les communications de cluster entre les nœuds de cluster.
sudo firewall-cmd --add-service=high-availability --permanent sudo firewall-cmd --add-service=high-availability[A] Activer les services de cluster de base.
Exécutez les commandes suivantes pour activer le service Pacemaker et le démarrer.
sudo systemctl start pcsd.service sudo systemctl enable pcsd.service[1] Créer un cluster Pacemaker.
Exécutez les commandes suivantes pour authentifier les nœuds et créer le cluster. Définissez le jeton sur 30000 pour permettre la maintenance de la conservation de la mémoire. Pour plus d’informations, consultez cet article pour Linux.
Si vous créez un cluster sur RHEL 7.x, utilisez les commandes suivantes :
sudo pcs cluster auth prod-cl1-0 prod-cl1-1 -u hacluster sudo pcs cluster setup --name nw1-azr prod-cl1-0 prod-cl1-1 --token 30000 sudo pcs cluster start --allSi vous créez un cluster sur RHEL 8.x/RHEL 9.x, utilisez les commandes suivantes :
sudo pcs host auth prod-cl1-0 prod-cl1-1 -u hacluster sudo pcs cluster setup nw1-azr prod-cl1-0 prod-cl1-1 totem token=30000 sudo pcs cluster start --allVérifiez l’état du cluster en exécutant la commande suivante :
# Run the following command until the status of both nodes is online sudo pcs status # Cluster name: nw1-azr # WARNING: no stonith devices and stonith-enabled is not false # Stack: corosync # Current DC: prod-cl1-1 (version 1.1.18-11.el7_5.3-2b07d5c5a9) - partition with quorum # Last updated: Fri Aug 17 09:18:24 2018 # Last change: Fri Aug 17 09:17:46 2018 by hacluster via crmd on prod-cl1-1 # # 2 nodes configured # 0 resources configured # # Online: [ prod-cl1-0 prod-cl1-1 ] # # No resources # # Daemon Status: # corosync: active/disabled # pacemaker: active/disabled # pcsd: active/enabled[A] Définir les votes attendus.
# Check the quorum votes pcs quorum status # If the quorum votes are not set to 2, execute the next command sudo pcs quorum expected-votes 2Conseil
Si vous créez un cluster multinode, autrement dit, un cluster avec plus de deux nœuds, ne définissez pas les votes sur 2.
[1] Autoriser les actions de clôture simultanées.
sudo pcs property set concurrent-fencing=true
Créer un appareil d’escrime
L’appareil d’délimitation utilise une identité managée pour une ressource Azure ou un principal de service pour autoriser sur Azure.
Pour créer une identité managée (MSI), créez une identité managée affectée par le système pour chaque machine virtuelle du cluster. Si une identité managée affectée par le système existe déjà, elle est utilisée. N’utilisez pas les identités managées affectées par l’utilisateur avec Pacemaker pour l’instant. Un appareil de clôture, basé sur une identité managée, est pris en charge sur RHEL 7.9 et RHEL 8.x/RHEL 9.x.
[1] Créer un rôle personnalisé pour l’agent d’isolation
L’identité managée et le principal de service n’ont pas les autorisations nécessaires pour accéder à vos ressources Azure par défaut. Vous devez accorder à l’identité managée ou aux autorisations de principal de service pour démarrer et arrêter (désactiver) toutes les machines virtuelles du cluster. Si vous n’avez pas encore créé le rôle personnalisé, vous pouvez le créer à l’aide de PowerShell ou d’Azure CLI.
Utilisez le contenu suivant pour le fichier d’entrée. Vous devez adapter le contenu à vos abonnements, c’est-à-dire remplacer et yyyyyyyy-yyyy-yyyy-yyyy-yyyyyyyyyyyy par xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx les ID de votre abonnement. Si vous n’avez qu’un seul abonnement, supprimez la deuxième entrée dans AssignableScopes.
{
"Name": "Linux Fence Agent Role",
"description": "Allows to power-off and start virtual machines",
"assignableScopes": [
"/subscriptions/xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx",
"/subscriptions/yyyyyyyy-yyyy-yyyy-yyyy-yyyyyyyyyyyy"
],
"actions": [
"Microsoft.Compute/*/read",
"Microsoft.Compute/virtualMachines/powerOff/action",
"Microsoft.Compute/virtualMachines/start/action"
],
"notActions": [],
"dataActions": [],
"notDataActions": []
}
[A] Attribuer le rôle personnalisé
Utilisez une identité managée ou un principal de service.
Attribuez le rôle Linux Fence Agent Role personnalisé créé dans la dernière section à chaque identité managée des machines virtuelles du cluster. Chaque identité managée affectée par le système de machine virtuelle a besoin du rôle attribué pour la ressource de chaque machine virtuelle du cluster. Pour plus d’informations, consultez Attribuer à une identité managée un accès à une ressource à l’aide du Portail Azure. Vérifiez que l’attribution de rôle d’identité managée de chaque machine virtuelle contient toutes les machines virtuelles du cluster.
Important
N’oubliez pas que l’affectation et la suppression de l’autorisation avec des identités managées peuvent être retardées jusqu’à ce qu’elles soient effectives.
[1] Créer les appareils d’isolation
Après avoir modifié les autorisations pour les machines virtuelles, vous pouvez configurer les appareils d’escrime dans le cluster.
sudo pcs property set stonith-timeout=900
Remarque
L’option pcmk_host_map est requise uniquement dans la commande si les noms d’hôte RHEL et les noms de machine virtuelle Azure ne sont pas identiques. Spécifiez le mappage au format nom-d-hôte:nom-machine-virtuelle.
Consultez la section en gras dans les commandes. Pour plus d’informations, consultez Quel format dois-je utiliser pour spécifier des mappages de nœuds pour l’escrime des appareils dans pcmk_host_map ?.
Pour RHEL 7.x, utilisez la commande suivante pour configurer l’appareil de délimitation :
sudo pcs stonith create rsc_st_azure fence_azure_arm msi=true resourceGroup="resource group" \
subscriptionId="subscription id" pcmk_host_map="prod-cl1-0:prod-cl1-0-vm-name;prod-cl1-1:prod-cl1-1-vm-name" \
power_timeout=240 pcmk_reboot_timeout=900 pcmk_monitor_timeout=120 pcmk_monitor_retries=4 pcmk_action_limit=3 pcmk_delay_max=15 \
op monitor interval=3600
Pour RHEL 8.x/9.x, utilisez la commande suivante pour configurer l’appareil de clôture :
# Run following command if you are setting up fence agent on (two-node cluster and pacemaker version greater than 2.0.4-6.el8) OR (HANA scale out)
sudo pcs stonith create rsc_st_azure fence_azure_arm msi=true resourceGroup="resource group" \
subscriptionId="subscription id" pcmk_host_map="prod-cl1-0:prod-cl1-0-vm-name;prod-cl1-1:prod-cl1-1-vm-name" \
power_timeout=240 pcmk_reboot_timeout=900 pcmk_monitor_timeout=120 pcmk_monitor_retries=4 pcmk_action_limit=3 \
op monitor interval=3600
# Run following command if you are setting up fence agent on (two-node cluster and pacemaker version less than 2.0.4-6.el8)
sudo pcs stonith create rsc_st_azure fence_azure_arm msi=true resourceGroup="resource group" \
subscriptionId="subscription id" pcmk_host_map="prod-cl1-0:prod-cl1-0-vm-name;prod-cl1-1:prod-cl1-1-vm-name" \
power_timeout=240 pcmk_reboot_timeout=900 pcmk_monitor_timeout=120 pcmk_monitor_retries=4 pcmk_action_limit=3 pcmk_delay_max=15 \
op monitor interval=3600
Si vous utilisez un appareil d’escrime basé sur la configuration du principal de service, lisez Change from SPN to MSI for Pacemaker clusters by using Azure fencing and learn how to convert to managed identity configuration.
Conseil
- Pour éviter les courses de clôture au sein d’un cluster pacemaker à deux nœuds, vous pouvez configurer la propriété du
priority-fencing-delaycluster. Cette propriété introduit un délai supplémentaire dans un délimiteur de nœud qui a une priorité de ressource totale supérieure lorsqu’un scénario split-brain se produit. Pour plus d’informations, consultez Pacemaker peut-il clôturer le nœud de cluster avec le moins de ressources en cours d’exécution ?. - La propriété
priority-fencing-delays’applique à Pacemaker version 2.0.4-6.el8 ou ultérieure et sur un cluster à deux nœuds. Si vous configurez la propriété depriority-fencing-delaycluster, vous n’avez pas besoin de définir lapcmk_delay_maxpropriété. Toutefois, si la version Pacemaker est inférieure à 2.0.4-6.el8, vous devez définir lapcmk_delay_maxpropriété. - Pour obtenir des instructions sur la définition de la propriété du
priority-fencing-delaycluster, consultez les documents SAP ASCS/ERS/ERS et SAP HANA scale-up HA respectifs.
Les opérations de monitoring et d’isolation sont désérialisées. Par conséquent, s’il existe une opération de surveillance plus longue et un événement d’escrime simultané, il n’y a aucun délai pour le basculement du cluster, car l’opération de surveillance est déjà en cours d’exécution.
[1] Activer l’utilisation d’un appareil d’isolation
sudo pcs property set stonith-enabled=true
Conseil
L’agent de clôture Azure nécessite une connectivité sortante aux points de terminaison publics. Pour plus d’informations avec les solutions possibles, consultez la connectivité de point de terminaison public pour les machines virtuelles à l’aide d’ilB standard.
Configuration de Pacemaker pour les événements planifiés Azure
Azure propose des événements planifiés. Les événements planifiés sont envoyés via le service de métadonnées et permettent à l’application de se préparer à ces événements.
L’agent azure-events-az de ressources Pacemaker surveille les événements Azure planifiés. Si des événements sont détectés et que l’agent de ressources détermine qu’un autre nœud de cluster est disponible, il définit un attribut d’intégrité de cluster.
Lorsque l’attribut d’intégrité du cluster est défini pour un nœud, la contrainte d’emplacement déclenche et toutes les ressources dont les noms ne commencent health- pas sont migrés à partir du nœud avec l’événement planifié. Une fois que le nœud de cluster affecté est libre d’exécuter des ressources de cluster, l’événement planifié est reconnu et peut exécuter son action, par exemple un redémarrage.
[A] Vérifiez que le package de l’agent
azure-events-azest déjà installé et à jour.RHEL 8.x: sudo dnf info resource-agents RHEL 9.x: sudo dnf info resource-agents-cloudConfiguration minimale requise pour la version :
- RHEL 8.4 :
resource-agents-4.1.1-90.13 - RHEL 8.6 :
resource-agents-4.9.0-16.9 - RHEL 8.8 :
resource-agents-4.9.0-40.1 - RHEL 9.0 :
resource-agents-cloud-4.10.0-9.6 - RHEL 9.2 et versions ultérieures :
resource-agents-cloud-4.10.0-34.1
- RHEL 8.4 :
[1] Configurez les ressources dans Pacemaker.
#Place the cluster in maintenance mode sudo pcs property set maintenance-mode=true[1] Définissez la stratégie et la contrainte de nœud d’intégrité du cluster Pacemaker.
sudo pcs property set node-health-strategy=custom sudo pcs constraint location 'regexp%!health-.*' \ rule score-attribute='#health-azure' \ defined '#uname'Important
Ne définissez aucune autre ressource dans le cluster en commençant
health-par les ressources décrites dans les étapes suivantes.[1] Définissez la valeur initiale des attributs de cluster. Exécutez pour chaque nœud de cluster et pour les environnements de scale-out, y compris la machine virtuelle de créateur majoritaire.
sudo crm_attribute --node prod-cl1-0 --name '#health-azure' --update 0 sudo crm_attribute --node prod-cl1-1 --name '#health-azure' --update 0[1] Configurez les ressources dans Pacemaker. Vérifiez que les ressources commencent par
health-azure.sudo pcs resource create health-azure-events \ ocf:heartbeat:azure-events-az op monitor interval=10s sudo pcs resource clone health-azure-events allow-unhealthy-nodes=trueRetirez le mode maintenance du cluster Pacemaker.
sudo pcs property set maintenance-mode=falseEffacez les erreurs lors de l’activation et vérifiez que les
health-azure-eventsressources ont démarré correctement sur tous les nœuds de cluster.sudo pcs resource cleanupL’exécution de requête de première fois pour les événements planifiés peut prendre jusqu’à deux minutes. Les tests Pacemaker avec des événements planifiés peuvent utiliser des actions de redémarrage ou de redéploiement pour les machines virtuelles du cluster. Pour plus d’informations, consultez Événements planifiés.
Configuration d’isolation facultative
Conseil
Cette section s’applique uniquement si vous souhaitez configurer l’appareil fence_kdumpd’escrime spécial.
Si vous avez besoin de collecter des informations de diagnostic au sein de la machine virtuelle, il peut être utile de configurer un autre appareil de clôture en fonction de l’agent fence_kdumpde clôture. L’agent fence_kdump peut détecter qu’un nœud a entré la récupération d’incident kdump et peut permettre au service de récupération d’incident de se terminer avant l’appel d’autres méthodes de clôture. Notez que fence_kdump ce n’est pas un remplacement pour les mécanismes de clôture traditionnels, comme l’agent de clôture Azure, lorsque vous utilisez des machines virtuelles Azure.
Important
N’oubliez pas que lorsqu’il fence_kdump est configuré en tant qu’appareil d’escrime de premier niveau, il introduit des retards dans les opérations d’escrime et, respectivement, des retards dans le basculement des ressources d’application.
Si un vidage sur incident est détecté avec succès, l’clôture est retardée jusqu’à ce que le service de récupération d’incident se termine. Si le nœud défaillant est inaccessible ou s’il ne répond pas, l’escrime est retardée par le temps déterminé, le nombre configuré d’itérations et le fence_kdump délai d’expiration. Pour plus d’informations, consultez Comment faire configurer fence_kdump dans un cluster Red Hat Pacemaker ?.
Le délai d’expiration proposé fence_kdump peut être adapté à l’environnement spécifique.
Nous vous recommandons de configurer fence_kdump l’clôture uniquement si nécessaire pour collecter des diagnostics au sein de la machine virtuelle et toujours en combinaison avec des méthodes de clôture traditionnelles, telles que l’agent de clôture Azure.
Les articles red Hat Ko suivants contiennent des informations importantes sur la configuration de fence_kdump l’escrime :
- Consultez Comment faire configurer fence_kdump dans un cluster Red Hat Pacemaker ?.
- Découvrez comment configurer/gérer des niveaux de délimitation dans un cluster RHEL avec Pacemaker.
- Consultez fence_kdump échoue avec le délai d’expiration après X secondes dans un cluster RHEL 6 ou 7 haute disponibilité avec kexec-tools antérieur à 2.0.14.
- Pour plus d’informations sur la modification du délai d’expiration par défaut, consultez Comment faire configurer kdump pour une utilisation avec le module complémentaire RHEL 6, 7, 8 HA ?.
- Pour plus d’informations sur la réduction du délai de basculement lorsque vous utilisez
fence_kdump, voir Puis-je réduire le délai attendu du basculement lors de l’ajout de fence_kdump configuration ?.
Exécutez les étapes facultatives suivantes pour ajouter fence_kdump en tant que configuration d’escrime de premier niveau, en plus de la configuration de l’agent de clôture Azure.
[A] Vérifiez qu’il
kdumpest actif et configuré.systemctl is-active kdump # Expected result # active[A] Installez l’agent de clôture
fence_kdump.yum install fence-agents-kdump[1] Créez un
fence_kdumpappareil d’escrime dans le cluster.pcs stonith create rsc_st_kdump fence_kdump pcmk_reboot_action="off" pcmk_host_list="prod-cl1-0 prod-cl1-1" timeout=30[1] Configurez les niveaux d’clôture afin que le
fence_kdumpmécanisme d’escrime soit engagé en premier.pcs stonith create rsc_st_kdump fence_kdump pcmk_reboot_action="off" pcmk_host_list="prod-cl1-0 prod-cl1-1" pcs stonith level add 1 prod-cl1-0 rsc_st_kdump pcs stonith level add 1 prod-cl1-1 rsc_st_kdump pcs stonith level add 2 prod-cl1-0 rsc_st_azure pcs stonith level add 2 prod-cl1-1 rsc_st_azure # Check the fencing level configuration pcs stonith level # Example output # Target: prod-cl1-0 # Level 1 - rsc_st_kdump # Level 2 - rsc_st_azure # Target: prod-cl1-1 # Level 1 - rsc_st_kdump # Level 2 - rsc_st_azure[A] Autorisez les ports requis par
fence_kdumple biais du pare-feu.firewall-cmd --add-port=7410/udp firewall-cmd --add-port=7410/udp --permanent[A] Vérifiez que le
initramfsfichier image contient les fichiers ethostslesfence_kdumpfichiers. Pour plus d’informations, consultez Comment faire configurer fence_kdump dans un cluster Red Hat Pacemaker ?.lsinitrd /boot/initramfs-$(uname -r)kdump.img | egrep "fence|hosts" # Example output # -rw-r--r-- 1 root root 208 Jun 7 21:42 etc/hosts # -rwxr-xr-x 1 root root 15560 Jun 17 14:59 usr/libexec/fence_kdump_send[A] Effectuez la
fence_kdump_nodesconfiguration pour/etc/kdump.conféviterfence_kdumpd’échouer avec un délai d’expiration pour certaineskexec-toolsversions. Pour plus d’informations, consultez fence_kdump expire lorsque fence_kdump_nodes n’est pas spécifié avec kexec-tools version 2.0.15 ou ultérieure et fence_kdump échoue avec « délai d’expiration après X secondes » dans un cluster RHEL 6 ou 7 haute disponibilité avec kexec-tools versions antérieures à 2.0.14. L’exemple de configuration d’un cluster à deux nœuds est présenté ici. Après avoir apporté une modification/etc/kdump.conf, l’image kdump doit être régénérée. Pour régénérer, redémarrez lekdumpservice.vi /etc/kdump.conf # On node prod-cl1-0 make sure the following line is added fence_kdump_nodes prod-cl1-1 # On node prod-cl1-1 make sure the following line is added fence_kdump_nodes prod-cl1-0 # Restart the service on each node systemctl restart kdumpTestez la configuration en bloquant un nœud. Pour plus d’informations, consultez Comment faire configurer fence_kdump dans un cluster Red Hat Pacemaker ?.
Important
Si le cluster est déjà en utilisation productive, planifiez le test en conséquence, car le blocage d’un nœud a un impact sur l’application.
echo c > /proc/sysrq-trigger
Étapes suivantes
- Consultez Planification et implémentation de machines virtuelles Azure pour SAP.
- Consultez Déploiement de machines virtuelles Azure pour SAP.
- Consultez Déploiement SGBD de machines virtuelles Azure pour SAP.
- Pour savoir comment établir la haute disponibilité et planifier la récupération d’urgence de SAP HANA sur des machines virtuelles Azure, consultez la haute disponibilité de SAP HANA sur Azure Machines Virtuelles.