Notes
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Les stratégies réseau permettent une micro-segmentation des pods tout comme les groupes de sécurité réseau (NSG) fournissent une micro-segmentation des machines virtuelles. L’implémentation du Gestionnaire de stratégies réseau Azure prend en charge la spécification d’une stratégie réseau Kubernetes standard. Vous pouvez utiliser des étiquettes pour sélectionner un groupe de pods et définir une liste de règles d’entrée et de sortie pour filtrer le trafic vers et depuis ces pods. Découvrez plus en détail les stratégies réseau Kubernetes dans la documentation Kubernetes.
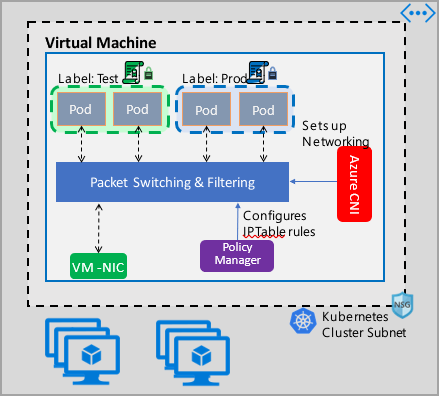
L’implémentation de la gestion des stratégies réseau Azure fonctionne avec Azure CNI qui fournit l’intégration de réseau virtuel pour les conteneurs. Le Gestionnaire de stratégies réseau est pris en charge sur Linux et Windows Server. L’implémentation applique le filtrage du trafic en configurant des règles d’autorisation et de refus d’IP basées sur les stratégies définies dans les IPTables Linux ou les ACLPolicies du service de réseau hôte (HNS) pour Windows Server.
Planification de la sécurité pour votre cluster Kubernetes
Quand vous implémentez la sécurité de votre cluster, utilisez des groupes de sécurité réseau (NSG) pour filtrer le trafic entrant et sortant de votre sous-réseau de cluster (trafic Nord-Sud). Utilisez le Gestionnaire de stratégies réseau Azure pour le trafic entre les pods de votre cluster (trafic Est-Ouest).
Utilisation du Gestionnaire de stratégies réseau Azure
Le Gestionnaire de stratégies réseau Azure peut être utilisé des manières suivantes pour permettre la micro-segmentation des pods.
Azure Kubernetes Service (AKS)
Le Gestionnaire de stratégies réseau est disponible en mode natif dans AKS et peut être activé au moment de la création du cluster.
Pour plus d’informations, consultez Sécuriser le trafic entre les pods avec des stratégies réseau dans Azure Kubernetes Service (AKS).
Clusters Kubernetes DIY (à déployer soi-même) dans Azure
Pour les clusters DIY, installez d’abord le plug-in CNI et activez-le sur chaque machine virtuelle d’un cluster. Pour obtenir des instructions détaillées, consultez Déployer le plug-in pour un cluster Kubernetes que vous déployez vous-même.
Une fois le cluster déployé, exécutez la commande suivante kubectl pour télécharger et appliquer le daemon set du Gestionnaire de stratégies réseau Azure au cluster.
Pour Linux :
kubectl apply -f https://raw.githubusercontent.com/Azure/azure-container-networking/master/npm/azure-npm.yaml
Pour Windows :
kubectl apply -f https://raw.githubusercontent.com/Azure/azure-container-networking/master/npm/examples/windows/azure-npm.yaml
La solution est également open source et le code est disponible dans le dépôt Azure Container Networking.
Monitorer et visualiser les configurations réseau avec Azure NPM
Le Gestionnaire de stratégies réseau Azure comprend des métriques Prometheus informatives qui vous permettent de monitorer et de mieux comprendre vos configurations. Il fournit des visualisations intégrées dans le portail Azure ou les laboratoires Grafana. Vous pouvez commencer à collecter ces métriques en utilisant Azure Monitor ou un serveur Prometheus.
Avantages des métriques du Gestionnaire de stratégies réseau Azure
Auparavant, les utilisateurs pouvaient uniquement découvrir leur configuration réseau avec les commandes iptables et ipset exécutées à l’intérieur d’un nœud de cluster, ce qui génère une sortie détaillée et difficile à comprendre.
Globalement, les métriques fournissent ce qui suit :
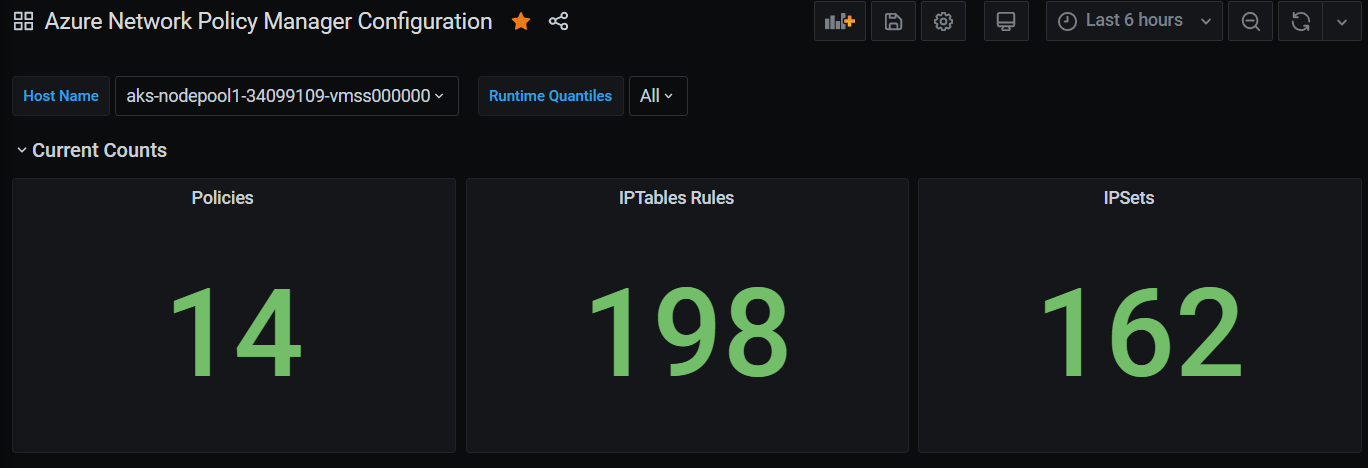
Nombre de stratégies, de règles ACL, d’ipsets, d’entrées ipset et d’entrées dans n’importe quel ipset donné
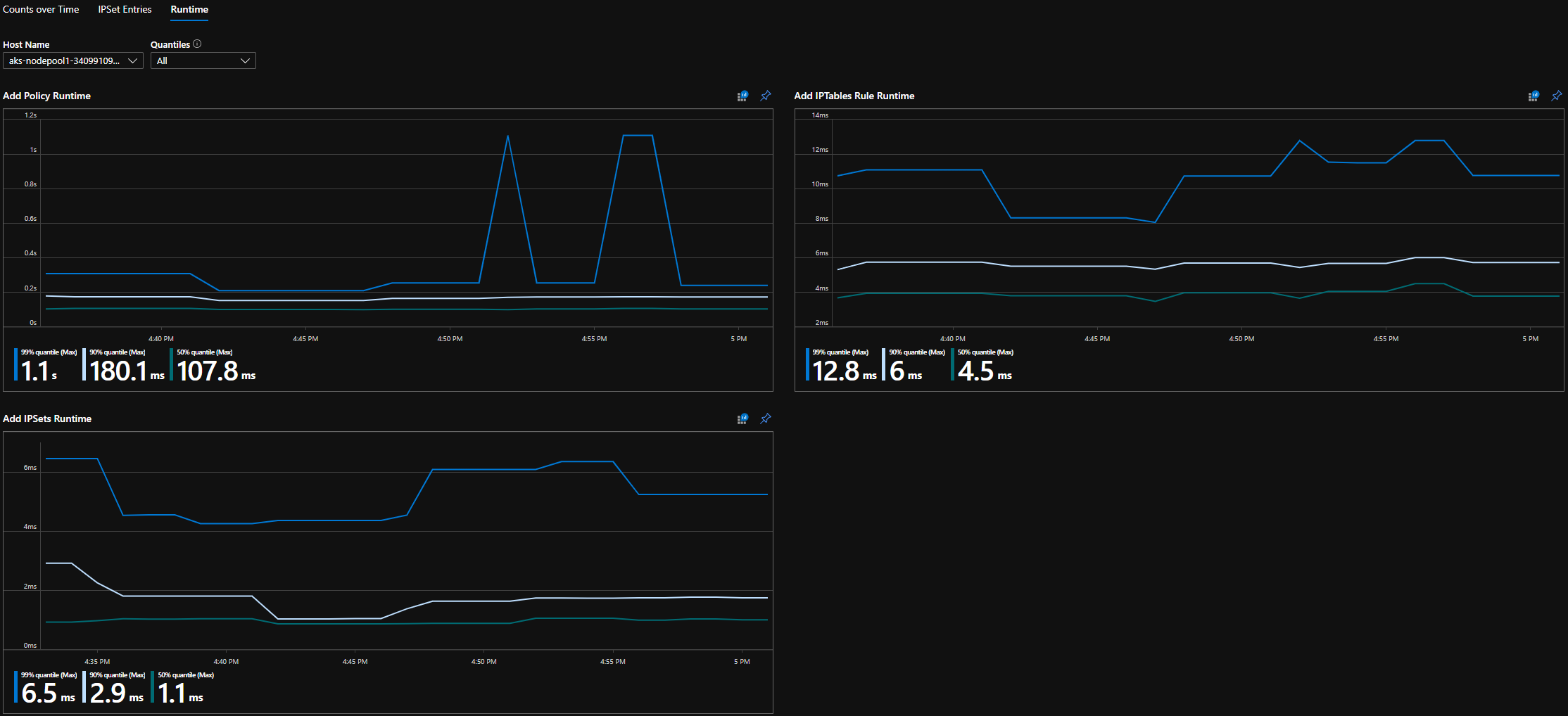
Temps d’exécution pour les appels de système d’exploitation individuels et la gestion des événements de ressources Kubernetes (médiane, 90e centile et 99e centile)
Informations sur les échecs pour la gestion des événements de ressources Kubernetes (ces événements échouent quand un appel de système d’exploitation échoue)
Exemples de cas d’usage des métriques
Alertes via Prometheus AlertManager
Consultez une configuration pour ces alertes dans l’exemple suivant.
Alerte en cas d’échec du Gestionnaire de stratégies réseau avec un appel de système d’exploitation ou pendant la traduction d’une stratégie réseau.
Alerte lorsque la durée médiane d’application des modifications pour un événement de création est supérieure à 100 millisecondes.
Visualisations et débogage via notre tableau de bord Grafana ou workbook Azure Monitor
Découvrez le nombre de règles IPTables créées par vos stratégies (un nombre important de règles IPTables peut légèrement augmenter la latence).
Mettez en corrélation le nombre de clusters (par exemple, les listes de contrôle d’accès) aux temps d’exécution.
Obtenez le nom convivial d’un ipset dans une règle IPTables donnée (par exemple,
azure-npm-487392représentepodlabel-role:database).
Métriques prises en charge
Voici la liste des métriques prises en charge. Toute étiquette quantile présente les valeurs possibles 0.5, 0.9 et 0.99. Toute étiquette had_error présente les valeurs possibles false et true, indiquant si l’opération a réussi ou échoué.
| Nom de métrique | Description | Type de métrique Prometheus | Étiquettes |
|---|---|---|---|
npm_num_policies |
nombre de stratégies réseau | Jauge | - |
npm_num_iptables_rules |
nombre de règles IPTables | Jauge | - |
npm_num_ipsets |
nombre d’IPSets | Jauge | - |
npm_num_ipset_entries |
nombre d’entrées d’adresse IP dans tous les IPSets | Jauge | - |
npm_add_iptables_rule_exec_time |
runtime pour l’ajout d’une règle IPTables | Résumé | quantile |
npm_add_ipset_exec_time |
runtime pour l’ajout d’un IPSet | Résumé | quantile |
npm_ipset_counts (avancé) |
nombre d’entrées dans chaque IPSet individuel | GaugeVec |
set_name & set_hash |
npm_add_policy_exec_time |
runtime pour l’ajout d’une stratégie réseau | Résumé |
quantile & had_error |
npm_controller_policy_exec_time |
runtime pour la mise à jour/suppression d’une stratégie réseau | Résumé |
quantile & had_error & operation (avec des valeurs update ou delete) |
npm_controller_namespace_exec_time |
runtime pour la création/mise à jour/suppression d’un espace de noms | Résumé |
quantile & had_error & operation (avec des valeurs create, updateou delete) |
npm_controller_pod_exec_time |
runtime pour la création/mise à jour/suppression d’un pod | Résumé |
quantile & had_error & operation (avec des valeurs create, updateou delete) |
Il existe également des métriques « exec_time_count » et « exec_time_sum » pour chaque métrique récapitulative « exec_time ».
Les métriques peuvent être scrapées via Azure Monitor pour conteneurs ou via Prometheus.
Configurer pour Azure Monitor
La première étape consiste à activer Azure Monitor pour conteneurs sur votre cluster Kubernetes. Les étapes sont accessibles dans Vue d’ensemble d’Azure Monitor pour conteneurs. Une fois que vous avez activé Azure Monitor pour conteneurs, configurez ConfigMap Azure Monitor pour conteneurs pour activer l’intégration du Gestionnaire de stratégies réseau et la collecte des métriques Prometheus du Gestionnaire de stratégies réseau.
ConfigMap Azure Monitor pour conteneurs a une section integrations avec des paramètres permettant de collecter les métriques du Gestionnaire de stratégies réseau.
Ces paramètres sont désactivés par défaut dans l’objet ConfigMap. Activez le paramètre de base collect_basic_metrics = true pour collecter les métriques de base du Gestionnaire de stratégies réseau. Activez le paramètre avancé collect_advanced_metrics = true pour collecter les métriques avancées en plus des métriques de base.
Après avoir modifié l’objet ConfigMap, enregistrez-le localement et appliquez-le à votre cluster comme suit.
kubectl apply -f container-azm-ms-agentconfig.yaml
L’extrait de code suivant est tiré du ConfigMap Azure Monitor pour conteneurs et montre l’intégration du Gestionnaire de stratégies réseau activée avec la collecte des métriques avancées.
integrations: |-
[integrations.azure_network_policy_manager]
collect_basic_metrics = false
collect_advanced_metrics = true
Les métriques avancées sont facultatives et leur activation active automatiquement la collecte des métriques de base. Les métriques avancées comprennent actuellement uniquement Network Policy Manager_ipset_counts.
En savoir plus sur les paramètres de collecte Azure Monitor pour conteneurs dans ConfigMap.
Options de visualisation pour Azure Monitor
Une fois la collecte des métriques du Gestionnaire de stratégies réseau activée, vous pouvez voir les métriques dans le portail Azure en utilisant les insights de conteneur ou dans Grafana.
Consultation dans le portail Azure sous les insights du cluster
Ouvrez le portail Azure. Une fois que vous êtes dans la section Insights de votre cluster, accédez à Workbooks et ouvrez Configuration du Gestionnaire de stratégies réseau.
En plus de voir le workbook, vous pouvez également interroger directement les métriques Prometheus dans « Journaux » sous la section Insights. Par exemple, cette requête renvoie toutes les métriques collectées.
| where TimeGenerated > ago(5h)
| where Name contains "npm_"
Vous pouvez également interroger directement les métriques dans Log Analytics. Pour plus d’informations, consultez Bien démarrer avec les requêtes Log Analytics.
Consultation dans le tableau de bord Grafana
Configurez votre serveur Grafana et configurez une source de données Log Analytics comme décrit ici. Ensuite, importez le tableau de bord Grafana avec un serveur principal Log Analytics dans vos laboratoires Grafana.
Le tableau de bord comporte des objets visuels similaires à ceux du classeur Azure. Vous pouvez ajouter des panneaux au graphique et visualiser les métriques du Gestionnaire de stratégies réseau à partir du tableau InsightsMetrics.
Configurer le serveur Prometheus
Certains utilisateurs peuvent choisir de collecter les métriques avec un serveur Prometheus au lieu d’Azure Monitor pour conteneurs. Il vous suffit d’ajouter deux travaux à votre configuration de scrapage pour collecter les métriques du Gestionnaire de stratégies réseau.
Pour installer un serveur Prometheus, ajoutez ce dépôt Helm sur votre cluster :
helm repo add stable https://kubernetes-charts.storage.googleapis.com
helm repo update
Ajoutez ensuite un serveur :
helm install prometheus stable/prometheus -n monitoring \
--set pushgateway.enabled=false,alertmanager.enabled=false, \
--set-file extraScrapeConfigs=prometheus-server-scrape-config.yaml
où prometheus-server-scrape-config.yaml se compose de :
- job_name: "azure-npm-node-metrics"
metrics_path: /node-metrics
kubernetes_sd_configs:
- role: node
relabel_configs:
- source_labels: [__address__]
action: replace
regex: ([^:]+)(?::\d+)?
replacement: "$1:10091"
target_label: __address__
- job_name: "azure-npm-cluster-metrics"
metrics_path: /cluster-metrics
kubernetes_sd_configs:
- role: service
relabel_configs:
- source_labels: [__meta_kubernetes_namespace]
regex: kube-system
action: keep
- source_labels: [__meta_kubernetes_service_name]
regex: npm-metrics-cluster-service
action: keep
# Comment from here to the end to collect advanced metrics: number of entries for each IPSet
metric_relabel_configs:
- source_labels: [__name__]
regex: npm_ipset_counts
action: drop
Vous pouvez également remplacer le travail azure-npm-node-metrics par le contenu suivant ou l’incorporer dans un travail préexistant pour les pods Kubernetes :
- job_name: "azure-npm-node-metrics-from-pod-config"
metrics_path: /node-metrics
kubernetes_sd_configs:
- role: pod
relabel_configs:
- source_labels: [__meta_kubernetes_namespace]
regex: kube-system
action: keep
- source_labels: [__meta_kubernetes_pod_annotationpresent_azure_Network Policy Manager_scrapeable]
action: keep
- source_labels: [__address__]
action: replace
regex: ([^:]+)(?::\d+)?
replacement: "$1:10091"
target_label: __address__
Configurer des alertes pour AlertManager
Si vous utilisez un serveur Prometheus, vous pouvez configurer AlertManager de la façon suivante. Voici un exemple de configuration des deux règles d’alerte décrites précédemment :
groups:
- name: npm.rules
rules:
# fire when Network Policy Manager has a new failure with an OS call or when translating a Network Policy (suppose there's a scraping interval of 5m)
- alert: AzureNetwork Policy ManagerFailureCreatePolicy
# this expression says to grab the current count minus the count 5 minutes ago, or grab the current count if there was no data 5 minutes ago
expr: (npm_add_policy_exec_time_count{had_error='true'} - (npm_add_policy_exec_time_count{had_error='true'} offset 5m)) or npm_add_policy_exec_time_count{had_error='true'}
labels:
severity: warning
addon: azure-npm
annotations:
summary: "Azure Network Policy Manager failed to handle a policy create event"
description: "Current failure count since Network Policy Manager started: {{ $value }}"
# fire when the median time to apply changes for a pod create event is more than 100 milliseconds.
- alert: AzurenpmHighControllerPodCreateTimeMedian
expr: topk(1, npm_controller_pod_exec_time{operation="create",quantile="0.5",had_error="false"}) > 100.0
labels:
severity: warning
addon: azure-Network Policy Manager
annotations:
summary: "Azure Network Policy Manager controller pod create time median > 100.0 ms"
# could have a simpler description like the one for the alert above,
# but this description includes the number of pod creates that were handled in the past 10 minutes,
# which is the retention period for observations when calculating quantiles for a Prometheus Summary metric
description: "value: [{{ $value }}] and observation count: [{{ printf `(npm_controller_pod_exec_time_count{operation='create',pod='%s',had_error='false'} - (npm_controller_pod_exec_time_count{operation='create',pod='%s',had_error='false'} offset 10m)) or npm_controller_pod_exec_time_count{operation='create',pod='%s',had_error='false'}` $labels.pod $labels.pod $labels.pod | query | first | value }}] for pod: [{{ $labels.pod }}]"
Options de visualisation pour Prometheus
Quand vous utilisez un serveur Prometheus, seul le tableau de bord Grafana est pris en charge.
Si vous ne l’avez pas déjà fait, configurez votre serveur Grafana et configurez une source de données Prometheus. Ensuite, importez notre tableau de bord Grafana avec un serveur principal Prometheus dans vos laboratoires Grafana.
Les visuels de ce tableau de bord sont identiques à ceux du tableau de bord avec un back-end Container Insights/Log Analytics.
Exemples de tableaux de bord
Voici quelques exemples de tableau de bord pour les métriques du Gestionnaire de stratégies réseau dans Container Insights (CI) et Grafana.
Nombre de récapitulatifs CI
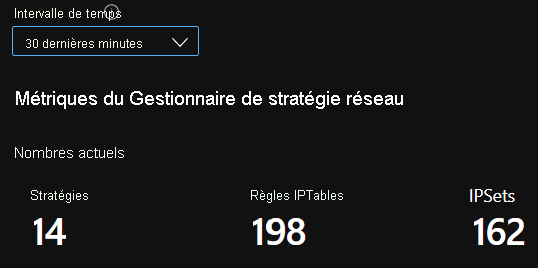
Nombres CI dans le temps

Entrées IPSet CI

Quantiles du runtime CI
Nombre de récapitulatifs du tableau de bord Grafana
Nombres du tableau de bord Grafana dans le temps

Entrées IPSet du tableau de bord Grafana

Quantiles de runtime du tableau de bord Grafana

Étapes suivantes
Découvrez en détail Azure Kubernetes Service.
Découvrez en détail la mise en réseau de conteneurs.
Déployez le plug-in pour des clusters Kubernetes ou des conteneurs Docker.