Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
C++ vous permet de spécifier plusieurs fonctions du même nom dans la même étendue. Ces fonctions sont appelées fonctions surchargées ou surcharges. Les fonctions surchargées vous permettent de fournir différentes sémantiques pour une fonction, en fonction des types et du nombre de ses arguments.
Par exemple, considérez une print fonction qui prend un std::string argument. Cette fonction peut effectuer des tâches très différentes d’une fonction qui prend un argument de type double. La surcharge vous empêche d’avoir à utiliser des noms tels que print_string ou print_double. Au moment de la compilation, le compilateur choisit la surcharge à utiliser en fonction des types et du nombre d’arguments transmis par l’appelant. Si vous appelez print(42.0), la void print(double d) fonction est appelée. Si vous appelez print("hello world"), la void print(std::string) surcharge est appelée.
Vous pouvez surcharger les fonctions membres et les fonctions libres. Le tableau suivant montre quelles parties d’une déclaration de fonction C++ utilise pour différencier les groupes de fonctions portant le même nom dans la même étendue.
Considérations en matière de surcharge
| Élément de déclaration de fonction | Utilisé pour surcharger ? |
|---|---|
| Type de retour de la fonction | Non |
| Nombre d’arguments | Oui |
| Type d’arguments | Oui |
| Présence ou absence de points de suspension | Oui |
Utilisation de typedef noms |
Non |
| Limites de tableau non spécifiées | Non |
const ou volatile |
Oui, lorsqu’elle est appliquée à l’ensemble de la fonction |
Qualificateurs de référence (& et &&) |
Oui |
Exemple
L’exemple suivant illustre comment utiliser des surcharges de fonction :
// function_overloading.cpp
// compile with: /EHsc
#include <iostream>
#include <math.h>
#include <string>
// Prototype three print functions.
int print(std::string s); // Print a string.
int print(double dvalue); // Print a double.
int print(double dvalue, int prec); // Print a double with a
// given precision.
using namespace std;
int main(int argc, char *argv[])
{
const double d = 893094.2987;
if (argc < 2)
{
// These calls to print invoke print( char *s ).
print("This program requires one argument.");
print("The argument specifies the number of");
print("digits precision for the second number");
print("printed.");
exit(0);
}
// Invoke print( double dvalue ).
print(d);
// Invoke print( double dvalue, int prec ).
print(d, atoi(argv[1]));
}
// Print a string.
int print(string s)
{
cout << s << endl;
return cout.good();
}
// Print a double in default precision.
int print(double dvalue)
{
cout << dvalue << endl;
return cout.good();
}
// Print a double in specified precision.
// Positive numbers for precision indicate how many digits
// precision after the decimal point to show. Negative
// numbers for precision indicate where to round the number
// to the left of the decimal point.
int print(double dvalue, int prec)
{
// Use table-lookup for rounding/truncation.
static const double rgPow10[] = {
10E-7, 10E-6, 10E-5, 10E-4, 10E-3, 10E-2, 10E-1,
10E0, 10E1, 10E2, 10E3, 10E4, 10E5, 10E6 };
const int iPowZero = 6;
// If precision out of range, just print the number.
if (prec < -6 || prec > 7)
{
return print(dvalue);
}
// Scale, truncate, then rescale.
dvalue = floor(dvalue / rgPow10[iPowZero - prec]) *
rgPow10[iPowZero - prec];
cout << dvalue << endl;
return cout.good();
}
Le code précédent montre les surcharges de la fonction dans l’étendue print du fichier.
L’argument par défaut n’est pas considéré comme faisant partie du type de fonction. Par conséquent, il n’est pas utilisé pour sélectionner des fonctions surchargées. Deux fonctions qui diffèrent uniquement de par leurs arguments par défaut sont considérées comme des définitions distinctes plutôt que comme des fonctions surchargées.
Les arguments par défaut ne peuvent pas être fournis pour les opérateurs surchargés.
Correspondance d’arguments
Le compilateur sélectionne la fonction surchargée à appeler en fonction de la meilleure correspondance entre les déclarations de fonction dans l’étendue actuelle aux arguments fournis dans l’appel de fonction. Si une fonction appropriée est trouvée, elle est appelée. « Approprié » dans ce contexte signifie soit :
Une correspondance exacte a été trouvée.
Une conversion ordinaire a été exécutée.
Une promotion intégrale a été exécutée.
Une conversion standard vers le type d’argument souhaité existe.
Une conversion définie par l’utilisateur (un opérateur de conversion ou un constructeur) vers le type d’argument souhaité existe.
Des arguments représentés par une ellipse ont été détectés.
Le compilateur crée un ensemble de fonctions candidates pour chaque argument. Les fonctions candidates sont des fonctions dans lesquelles l’argument réel dans cette position peut être converti vers le type de l’argument formel.
Un ensemble des « meilleures fonctions correspondantes » est généré pour chaque argument, et la fonction sélectionnée correspond à l’intersection de tous les ensembles. Si l'intersection contient plusieurs fonctions, la surcharge est ambiguë et génère une erreur. La fonction qui est finalement sélectionnée est toujours une meilleure correspondance que toutes les autres fonctions du groupe pour au moins un argument. S’il n’existe aucun gagnant clair, l’appel de fonction génère une erreur du compilateur.
Prenons les déclarations suivantes (les fonctions sont marquées Variant 1, Variant 2 et Variant 3, afin de les identifier dans la discussion suivante) :
Fraction &Add( Fraction &f, long l ); // Variant 1
Fraction &Add( long l, Fraction &f ); // Variant 2
Fraction &Add( Fraction &f, Fraction &f ); // Variant 3
Fraction F1, F2;
Prenons l'instruction suivante :
F1 = Add( F2, 23 );
L'instruction précédente génère deux ensembles :
Set 1 : Fonctions candidates qui ont le premier argument de type Fraction |
Set 2 : Fonctions candidates dont le deuxième argument peut être converti en type int |
|---|---|
| Variant 1 | Variant 1 (int peut être converti à long l’aide d’une conversion standard) |
| Variant 3 |
Les fonctions de l’ensemble 2 sont des fonctions qui ont des conversions implicites du type de paramètre réel au type de paramètre formel. L’une de ces fonctions a le plus petit « coût » pour convertir le type de paramètre réel en son type de paramètre formel correspondant.
L'intersection de ces deux ensembles est Variant 1. Voici un exemple d'appel de fonction ambigu :
F1 = Add( 3, 6 );
L'appel de fonction précédent génère les ensembles suivants :
Set 1 : Fonctions candidates qui ont le premier argument de type int |
Set 2 : Fonctions candidates qui ont le deuxième argument de type int |
|---|---|
Variant 2 (int peut être converti à long l’aide d’une conversion standard) |
Variant 1 (int peut être converti à long l’aide d’une conversion standard) |
Étant donné que l’intersection de ces deux ensembles est vide, le compilateur génère un message d’erreur.
Pour la correspondance d’arguments, une fonction avec n arguments par défaut est traitée comme des fonctions distinctes n+1, chacune avec un nombre différent d’arguments.
Les points de suspension (...) jouent le rôle de caractère générique ; il correspond à n’importe quel argument réel. Cela peut entraîner de nombreux ensembles ambigus, si vous ne concevez pas vos ensembles de fonctions surchargés avec des soins extrêmes.
Remarque
L’ambiguïté des fonctions surchargées ne peut pas être déterminée tant qu’un appel de fonction n’est pas rencontré. À ce stade, les ensembles sont générés pour chaque argument dans l'appel de fonction, et vous pouvez déterminer si une surcharge non équivoque existe. Cela signifie que les ambiguïtés peuvent rester dans votre code jusqu’à ce qu’elles soient évoquées par un appel de fonction particulier.
Différences de type d’argument
Les fonctions surchargées distinguent les types d’arguments qui acceptent différents initialiseurs. Par conséquent, un argument d’un type donné et une référence à ce type sont considérés comme identiques pour les besoins de la surcharge. Ils sont considérés comme les mêmes parce qu’ils prennent les mêmes initialiseurs. Par exemple, max( double, double ) est considéré comme identique à max( double &, double & ). La déclaration de deux de ces fonctions provoque une erreur.
Pour la même raison, les arguments de fonction d’un type modifié par const ou volatile ne sont pas traités différemment du type de base à des fins de surcharge.
Toutefois, le mécanisme de surcharge de fonction peut distinguer les références qualifiées par const et volatile les références au type de base. Il rend le code tel que le suivant possible :
// argument_type_differences.cpp
// compile with: /EHsc /W3
// C4521 expected
#include <iostream>
using namespace std;
class Over {
public:
Over() { cout << "Over default constructor\n"; }
Over( Over &o ) { cout << "Over&\n"; }
Over( const Over &co ) { cout << "const Over&\n"; }
Over( volatile Over &vo ) { cout << "volatile Over&\n"; }
};
int main() {
Over o1; // Calls default constructor.
Over o2( o1 ); // Calls Over( Over& ).
const Over o3; // Calls default constructor.
Over o4( o3 ); // Calls Over( const Over& ).
volatile Over o5; // Calls default constructor.
Over o6( o5 ); // Calls Over( volatile Over& ).
}
Sortie
Over default constructor
Over&
Over default constructor
const Over&
Over default constructor
volatile Over&
Les pointeurs vers const et volatile les objets sont également considérés comme différents des pointeurs vers le type de base à des fins de surcharge.
Correspondance et conversions d'argument
Lorsque le compilateur tente de mettre en correspondance les arguments réels et les arguments des déclarations de fonction, il peut fournir des conversions standard ou définies par l’utilisateur pour obtenir le type correct si aucune correspondance exacte n’est trouvée. L'application des conversions est soumise aux règles ci-dessous.
Les séquences de conversions qui contiennent plusieurs conversions définies par l’utilisateur ne sont pas prises en compte.
Les séquences de conversions qui peuvent être raccourcies en supprimant les conversions intermédiaires ne sont pas prises en compte.
La séquence résultante de conversions, le cas échéant, est appelée la meilleure séquence correspondante. Il existe plusieurs façons de convertir un objet de type en type intunsigned long à l’aide de conversions standard (décrites dans les conversions standard) :
intConvertissez de verslonget delongversunsigned long.Convertir en
intunsigned long.
Bien que la première séquence atteigne l’objectif souhaité, il n’est pas la meilleure séquence correspondante, car une séquence plus courte existe.
Le tableau suivant montre un groupe de conversions appelées conversions triviales. Les conversions triviales ont un effet limité sur la séquence choisie par le compilateur comme meilleure correspondance. L’effet des conversions triviales est décrit après la table.
Conversions triviales
| Type d’argument | Type converti |
|---|---|
type-name |
type-name& |
type-name& |
type-name |
type-name[] |
type-name* |
type-name(argument-list) |
(*type-name)(argument-list) |
type-name |
const type-name |
type-name |
volatile type-name |
type-name* |
const type-name* |
type-name* |
volatile type-name* |
La séquence dans laquelle les conversions sont tentées est la suivante :
Correspondance exacte. Une correspondance exacte entre les types avec lesquels la fonction est appelée et les types déclarés dans le prototype de fonction est toujours la meilleure correspondance. Les séquences de conversions ordinaires sont classées comme correspondances exactes. Toutefois, les séquences qui n’effectuent aucune de ces conversions sont considérées comme meilleures que les séquences qui convertissent :
Du pointeur, au pointeur vers
const(type-name*versconst type-name*).Du pointeur, au pointeur vers
volatile(type-name*versvolatile type-name*).De référence, à référencer
const(type-name&àconst type-name&).De référence, à référencer
volatile(type-name&àvolatile type&).
Correspondance avec des promotions. Toute séquence non classifiée comme une correspondance exacte qui contient uniquement des promotions intégrales, des conversions en
floatetdoubledes conversions triviales est classée comme une correspondance à l’aide de promotions. Bien qu'elle ne soit pas aussi appropriée qu'une correspondance exacte, une correspondance avec des promotions est meilleure qu'une correspondance avec des conversions standard.Correspondance avec des conversions standard. Toute séquence non classée comme correspondance exacte ou correspondance avec des promotions et qui contient uniquement des conversions standard et des conversions ordinaires est classée comme correspondance avec des conversions standard. Dans cette catégorie, les règles ci-dessous s'appliquent.
La conversion d’un pointeur vers une classe dérivée, vers un pointeur vers une classe de base directe ou indirecte est préférable à la conversion en
void *ouconst void *.La conversion d'un pointeur vers une classe dérivée, vers un pointeur vers une classe de base génère une correspondance d'autant meilleure que la classe de base est proche d'une classe de base directe. Supposons que la hiérarchie de classes soit comme indiqué dans la figure suivante :

Graphique montrant les conversions préférées.
La conversion du type D* vers le type C* est préférable à une conversion du type D* vers le type B*. De même, la conversion du type D* vers le type B* est préférable à une conversion du type D* vers le type A*.
Cette même règle s'applique aux conversions de référence. La conversion du type D& vers le type C& est préférable à une conversion du type D& vers le type B&, et ainsi de suite.
Cette même règle s'applique aux conversions de pointeur vers membre. La conversion du type T D::* vers le type T C::* est préférable à une conversion du type T D::* vers le type T B::*, et ainsi de suite (où T est le type du membre).
La règle précédente s’applique uniquement à un chemin de dérivation donné. Examinez le graphique présenté dans l'illustration ci-dessous.
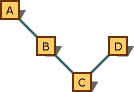
Graphique d’héritage multiple qui affiche les conversions préférées.
La conversion du type C* vers le type B* est préférable à une conversion du type C* vers le type A*. Cela provient du fait qu’ils se trouvent dans le même chemin et que B* est plus proche. Toutefois, la conversion de type en type C*D* n’est pas préférable à la conversion en type A*; il n’existe aucune préférence, car les conversions suivent différents chemins.
Correspondance avec des conversions définies par l'utilisateur. Cette séquence ne peut pas être classifiée comme une correspondance exacte, une correspondance à l’aide de promotions ou une correspondance à l’aide de conversions standard. Pour être classifiée comme une correspondance avec des conversions définies par l’utilisateur, la séquence doit contenir uniquement des conversions définies par l’utilisateur, des conversions standard ou des conversions triviales. Une correspondance avec des conversions définies par l’utilisateur est considérée comme une meilleure correspondance qu’une correspondance avec des points de suspension (
...) mais pas aussi bonne qu’une correspondance avec des conversions standard.Correspondance avec des points de suspension. Toute séquence qui correspond à des points de suspension dans la déclaration est classée comme correspondance avec des points de suspension. C’est considéré comme le match le plus faible.
Les conversions définies par l'utilisateur sont appliquées s'il n'existe aucune promotion ou conversion intégrée. Ces conversions sont sélectionnées en fonction du type de l’argument mis en correspondance. Prenez le code suivant :
// argument_matching1.cpp
class UDC
{
public:
operator int()
{
return 0;
}
operator long();
};
void Print( int i )
{
}
UDC udc;
int main()
{
Print( udc );
}
Les conversions définies par l’utilisateur disponibles pour la classe UDC proviennent du type et du type intlong. Par conséquent, le compilateur considère les conversions pour le type de l'objet qui est mis en correspondance : UDC. Une conversion vers int existe, et elle est sélectionnée.
Pendant le processus de mise en correspondance d’arguments, les conversions standard peuvent être appliquées à l’argument et au résultat d’une conversion définie par l’utilisateur. Par conséquent, le code suivant fonctionne :
void LogToFile( long l );
...
UDC udc;
LogToFile( udc );
Dans cet exemple, le compilateur appelle une conversion définie par l’utilisateur, operator longpour convertir udc en type long. Si aucune conversion définie par l’utilisateur en type long n’a été définie, le compilateur convertit d’abord le type en type UDCint à l’aide de la conversion définie par operator int l’utilisateur. Ensuite, il applique la conversion standard du type en type intlong pour correspondre à l’argument de la déclaration.
Si des conversions définies par l’utilisateur sont requises pour correspondre à un argument, les conversions standard ne sont pas utilisées lors de l’évaluation de la meilleure correspondance. Même si plusieurs fonctions candidates nécessitent une conversion définie par l’utilisateur, les fonctions sont considérées comme égales. Par exemple :
// argument_matching2.cpp
// C2668 expected
class UDC1
{
public:
UDC1( int ); // User-defined conversion from int.
};
class UDC2
{
public:
UDC2( long ); // User-defined conversion from long.
};
void Func( UDC1 );
void Func( UDC2 );
int main()
{
Func( 1 );
}
Les deux versions nécessitent Func une conversion définie par l’utilisateur pour convertir le type int en argument de type de classe. Les conversions possibles sont indiquées ci-dessous.
Convertir du type en type
intUDC1(conversion définie par l’utilisateur).Convertir du type en type
intlong; puis convertir en typeUDC2(conversion en deux étapes).
Même si la seconde nécessite une conversion standard et la conversion définie par l’utilisateur, les deux conversions sont toujours considérées comme égales.
Remarque
Les conversions définies par l’utilisateur sont considérées comme des conversions par construction ou conversion par initialisation. Le compilateur considère les deux méthodes comme égales lorsqu’elle détermine la meilleure correspondance.
Correspondance des arguments et pointeur this
Les fonctions membres de classe sont traitées différemment, selon qu’elles sont déclarées comme static.
static les fonctions n’ont pas d’argument implicite qui fournit le this pointeur. Elles sont donc considérées comme ayant un argument inférieur à celui des fonctions membres régulières. Sinon, ils sont déclarés de façon identique.
Les fonctions membres qui ne nécessitent pas static que le pointeur implicite this corresponde au type d’objet via lequel la fonction est appelée. Ou, pour les opérateurs surchargés, ils nécessitent que le premier argument corresponde à l’objet auquel l’opérateur est appliqué. Pour plus d’informations sur les opérateurs surchargés, consultez Opérateurs surchargés.
Contrairement à d’autres arguments dans les fonctions surchargées, le compilateur n’introduit aucun objet temporaire et tente aucune conversion lors de la tentative de correspondance avec l’argument this pointeur.
Lorsque l’opérateur -> de sélection de membre est utilisé pour accéder à une fonction membre de classe class_name, l’argument this pointeur a un type de class_name * const. Si les membres sont déclarés en tant que const ou volatile, les types sont const class_name * const et volatile class_name * const, respectivement.
L'opérateur de sélection de membres . fonctionne exactement de la même façon, sauf qu'un opérateur (d'adresse) & implicite est préfixé au nom de l'objet. L'exemple suivant illustre cela :
// Expression encountered in code
obj.name
// How the compiler treats it
(&obj)->name
L'opérande gauche des opérateurs (pointeur vers membre) ->* et .* est traité de la même façon que les opérateurs (sélection de membres) . et -> en ce qui concerne la correspondance d'arguments.
Qualificateurs de référence sur les fonctions membres
Les qualificateurs de référence permettent de surcharger une fonction membre selon que l’objet pointé par this est une valeur rvalue ou une lvalue. Utilisez cette fonctionnalité pour éviter les opérations de copie inutiles dans les scénarios où vous choisissez de ne pas fournir d’accès au pointeur aux données. Par exemple, supposons que la classe C initialise certaines données dans son constructeur et retourne une copie de ces données dans la fonction get_data()membre. Si un objet de type C est une valeur rvalue sur le point d’être détruit, le compilateur choisit la get_data() && surcharge, qui se déplace au lieu de copier les données.
#include <iostream>
#include <vector>
using namespace std;
class C
{
public:
C() {/*expensive initialization*/}
vector<unsigned> get_data() &
{
cout << "lvalue\n";
return _data;
}
vector<unsigned> get_data() &&
{
cout << "rvalue\n";
return std::move(_data);
}
private:
vector<unsigned> _data;
};
int main()
{
C c;
auto v = c.get_data(); // get a copy. prints "lvalue".
auto v2 = C().get_data(); // get the original. prints "rvalue"
return 0;
}
Restrictions sur la surcharge
Plusieurs restrictions régissent un ensemble acceptable de fonctions surchargées :
Deux fonctions d’un ensemble de fonctions surchargées doivent avoir des listes d’arguments différentes.
La surcharge des fonctions qui ont des listes d’arguments des mêmes types, en fonction du type de retour seul, est une erreur.
Section spécifique à Microsoft
Vous pouvez surcharger
operator newen fonction du type de retour, en particulier en fonction du modificateur de modèle mémoire spécifié.FIN de la section spécifique à Microsoft
Les fonctions membres ne peuvent pas être surchargées uniquement, car l’une est et l’autre n’est
staticpasstatic.typedefles déclarations ne définissent pas de nouveaux types ; ils introduisent des synonymes pour les types existants. Ils n’affectent pas le mécanisme de surcharge. Prenez le code suivant :typedef char * PSTR; void Print( char *szToPrint ); void Print( PSTR szToPrint );Les deux fonctions précédentes ont des listes d’arguments identiques.
PSTRest un synonyme de typechar *. Dans la portée du membre, ce code génère une erreur.Les types énumérés sont des types distincts et peuvent être utilisés pour établir une distinction entre les fonctions surchargées.
Les types « tableau de » et « pointeur vers » sont considérés comme identiques à des fins de distinction entre les fonctions surchargées, mais uniquement pour les tableaux unidimensionnels. Ces fonctions surchargées sont en conflit et génèrent un message d’erreur :
void Print( char *szToPrint ); void Print( char szToPrint[] );Pour les tableaux de dimensions supérieures, les dimensions secondaires et ultérieures sont considérées comme faisant partie du type. Ils sont utilisés pour distinguer les fonctions surchargées :
void Print( char szToPrint[] ); void Print( char szToPrint[][7] ); void Print( char szToPrint[][9][42] );
Surcharge, substitution et masquage
Toutes les deux déclarations de fonction du même nom dans la même étendue peuvent faire référence à la même fonction, ou à deux fonctions surchargées discrètes. Si les listes d’arguments des déclarations contiennent des arguments de types équivalents (comme décrit dans la section précédente), les déclarations de fonction font référence à la même fonction. Sinon, elles font référence à deux fonctions différentes qui sont sélectionnées à l'aide de la surcharge.
L’étendue de classe est strictement observée. Une fonction déclarée dans une classe de base n’est pas dans la même étendue qu’une fonction déclarée dans une classe dérivée. Si une fonction d’une classe dérivée est déclarée avec le même nom qu’une virtual fonction dans la classe de base, la fonction de classe dérivée remplace la fonction de classe de base. Pour plus d’informations, consultez Virtual Functions.
Si la fonction de classe de base n’est pas déclarée comme virtual, la fonction de classe dérivée est dite pour la masquer . La substitution et le masquage sont distincts de la surcharge.
L’étendue de bloc est strictement observée. Une fonction déclarée dans l’étendue de fichier n’est pas dans la même étendue qu’une fonction déclarée localement. Si une fonction déclarée localement a le même nom qu'une fonction déclarée avec portée de fichier, la fonction déclarée localement masque la fonction déclarée avec portée de fichier au lieu de provoquer la surcharge. Par exemple :
// declaration_matching1.cpp
// compile with: /EHsc
#include <iostream>
using namespace std;
void func( int i )
{
cout << "Called file-scoped func : " << i << endl;
}
void func( char *sz )
{
cout << "Called locally declared func : " << sz << endl;
}
int main()
{
// Declare func local to main.
extern void func( char *sz );
func( 3 ); // C2664 Error. func( int ) is hidden.
func( "s" );
}
Le code précédent montre deux définitions de la fonction func. La définition qui accepte un argument de type char * est locale à main cause de l’instruction extern . Par conséquent, la définition qui accepte un argument de type int est masquée et le premier appel à func est en erreur.
Pour les fonctions membres surchargées, différents privilèges d'accès peuvent être accordés à différentes versions de la fonction. Ils sont toujours considérés comme étant dans l’étendue de la classe englobante et sont donc des fonctions surchargées. Prenons le code suivant, dans lequel la fonction membre Deposit est surchargée ; une version est publique, l'autre privée.
Cet exemple sert à fournir une classe Account dans laquelle un mot de passe correct est requis pour effectuer des dépôts. C’est fait à l’aide de la surcharge.
Appel à l’appel Deposit de Account::Deposit la fonction membre privée. Cet appel est correct, car Account::Deposit il s’agit d’une fonction membre et a accès aux membres privés de la classe.
// declaration_matching2.cpp
class Account
{
public:
Account()
{
}
double Deposit( double dAmount, char *szPassword );
private:
double Deposit( double dAmount )
{
return 0.0;
}
int Validate( char *szPassword )
{
return 0;
}
};
int main()
{
// Allocate a new object of type Account.
Account *pAcct = new Account;
// Deposit $57.22. Error: calls a private function.
// pAcct->Deposit( 57.22 );
// Deposit $57.22 and supply a password. OK: calls a
// public function.
pAcct->Deposit( 52.77, "pswd" );
}
double Account::Deposit( double dAmount, char *szPassword )
{
if ( Validate( szPassword ) )
return Deposit( dAmount );
else
return 0.0;
}