Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Cet article est destiné à toute personne qui envisage de déployer une passerelle de données locale dans un scénario critique pour l’entreprise. Une passerelle de données locale est critique pour l’entreprise si elle est essentielle au fonctionnement normal de votre entreprise et gère les données critiques pour l’entreprise.
Si les passerelles critiques pour l’entreprise ne sont pas gérées correctement, vous risquez d’rencontrer des requêtes ayant échoué ou de ralentir les performances. Lorsque vous planifiez, mettez à l’échelle et gérez correctement votre solution de passerelle critique pour l’entreprise, la probabilité d’un problème d’impact sur l’entreprise peut être réduite.
Terminologie
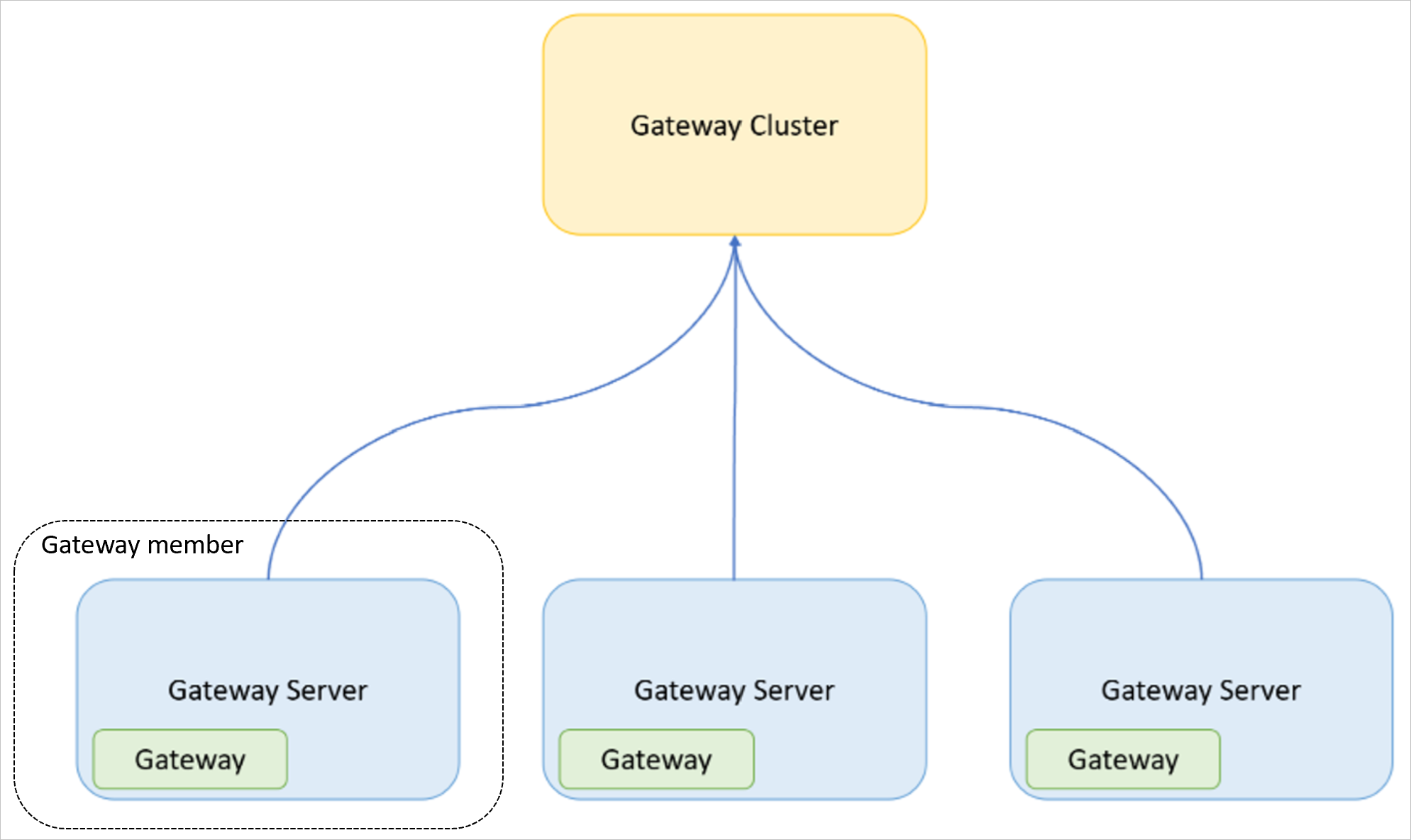
Les termes importants suivants sont utilisés dans cet article :
- Passerelle : application de passerelle de données locale installée sur un ordinateur.
- Serveur de passerelle : un ordinateur Windows (machine virtuelle ou ordinateur physique/serveur) sur lequel l’application de passerelle de données locale est installée.
- Cluster de passerelles : ensemble de passerelles qui fonctionnent ensemble (et pouvant faire l'objet d'un équilibrage de charge).
- Membre de passerelle : passerelle qui fait partie d’un cluster de passerelle.
L’image suivante illustre la relation entre les concepts définis ci-dessus.
Recommandations pour les passerelles critiques pour l’entreprise
Pour les passerelles critiques pour l’entreprise, les passerelles doivent être déployées et gérées correctement pour garantir une haute disponibilité, de bonnes performances et une scalabilité pouvant être maintenue. Le déploiement incorrect de passerelles peut entraîner des performances médiocres, des requêtes ayant échoué et des difficultés à diagnostiquer les problèmes potentiels. Cela peut également entraver votre capacité à étendre et développer les passerelles à mesure que l'utilisation augmente.
Pour garantir une scalabilité optimale, des performances et du débit, suivez les recommandations des sections suivantes.
Connaître toutes vos clés de récupération du pare-feu
Vérifiez que toutes les clés de récupération de passerelle sont connues et conservées dans un endroit sûr. Sans clé de récupération, les passerelles ne peuvent pas être récupérées ou rétrogradées. Cette limitation est par nature. Si vous perdez vos clés de récupération, la seule option consiste à créer de nouvelles passerelles et à recréer les sources de données. En outre, vous ne pouvez pas ajouter de nouvelles passerelles au cluster sans la clé de récupération, ce qui limiterait la scalabilité future.
Stockez vos clés de récupération dans un emplacement sécurisé, tout comme vous le feriez pour stocker les informations d’identification d’administration, telles qu’un mot de passe sécurisé, accessible uniquement par les administrateurs autorisés.
Si vous ne connaissez actuellement pas toutes vos clés de récupération de passerelle, il s’agit d’un risque commercial important. Créez immédiatement des clusters de passerelle et commencez à migrer des charges de travail vers les nouveaux clusters de passerelle.
Charges de travail de développement et charges de travail critiques pour l’entreprise
Séparez les charges de travail de développement des charges de travail critiques pour l’entreprise en configurant un ou plusieurs clusters de passerelle de développement et un ou plusieurs clusters de passerelle de production.
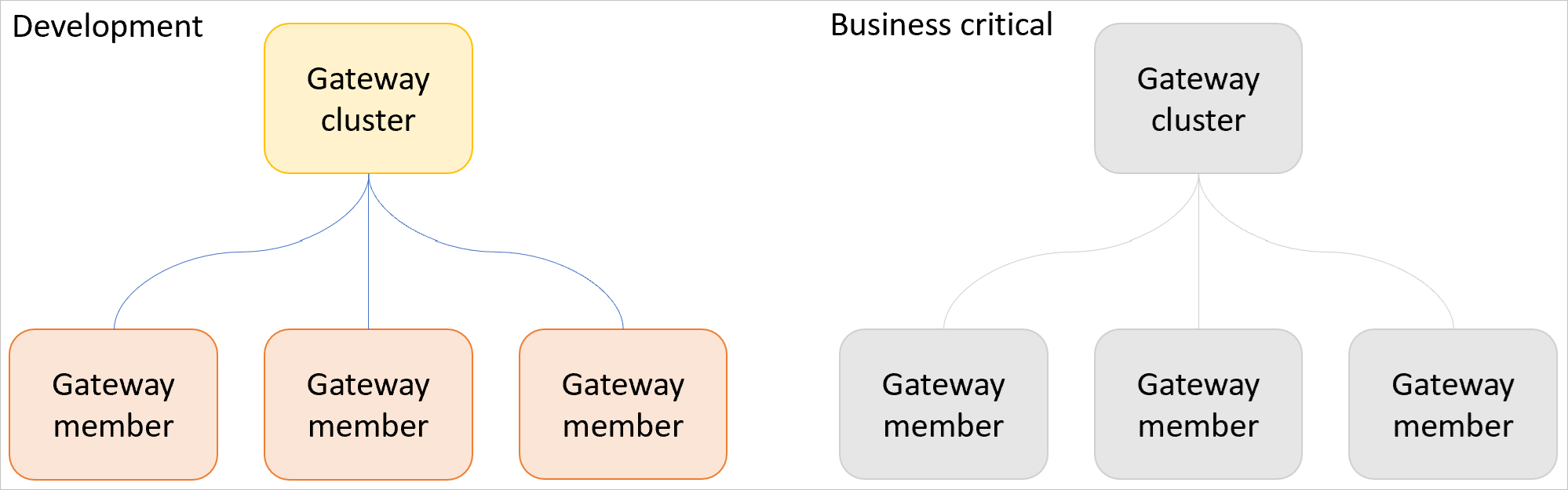
Utilisez un cluster de passerelle de développement pour tester de nouveaux modèles sémantiques, rapports, requêtes, et ainsi de suite. Une fois qu’une nouvelle charge de travail a été vérifiée, migrez-la vers un cluster de passerelle critique pour l’entreprise. Ce processus empêche les charges de travail nouvelles, non testées ou expérimentales d’avoir des répercussions sur les performances sur les charges de travail de production.
Utilisez également vos clusters de passerelle de développement pour tester les nouvelles mises à jour de passerelle avant d’appliquer des mises à jour à vos clusters de passerelle critiques pour l’entreprise. Les nouvelles mises à jour de passerelle doivent être déployées pendant au moins 24 heures dans le ou les clusters de passerelle de développement avant d’être utilisées sur les clusters de passerelle critiques pour l’entreprise.
Utiliser plusieurs clusters de passerelle
Si vous créez un cluster de passerelle pour un grand nombre d’utilisateurs de votre organisation, vous devez créer plusieurs clusters de passerelle basés sur des unités commerciales ou plus petits pour limiter tout impact potentiel sur les performances d’un petit sous-ensemble d’utilisateurs.
Nous vous déconseillons d’utiliser un seul cluster de passerelle critique pour l’entreprise (sauf si la société est petite). Dans un scénario de cluster de passerelle unique, un utilisateur peut concevoir l’envoi d’une requête qui entraîne un impact significatif sur les performances de tout le trafic sur la passerelle. Si la passerelle est utilisée dans l’ensemble de l’entreprise, l’impact sur les performances peut affecter l’ensemble de l’entreprise. En outre, lorsqu’un cluster de passerelle est utilisé dans l’ensemble d’une entreprise, il peut être plus difficile d’identifier la requête susceptible d’entraîner un problème de performances lors de l’utilisation de la fonctionnalité d’analyse des performances de la passerelle .

Utiliser les fonctionnalités de haute disponibilité et d’équilibrage de charge de la passerelle
Utilisez toujours les fonctionnalités de haute disponibilité et d’équilibrage de charge de la passerelle pour n’importe quel cluster de passerelle critique pour l’entreprise.
- Haute disponibilité : élimine un point de défaillance unique.
- Équilibrage de charge : répartit automatiquement la charge de travail sur tous les serveurs de passerelle du cluster.
Configurez un minimum de deux passerelles par cluster de passerelle si une passerelle est hors connexion pour une raison quelconque. Cette configuration garantit qu’une seule défaillance de passerelle n’entraîne pas l’échec de l’ensemble du cluster de passerelle. En outre, les limites de processeur, de mémoire, de concurrence peuvent être activées sur les passerelles pour mieux répartir la charge sur le cluster de passerelle.
Planifier et gérer l’extensibilité du cluster de passerelle
La configuration d’un cluster de passerelle à l’aide de nos instructions matérielles et logicielles recommandées garantit que le cluster s’exécute avec de bonnes performances. Les passerelles qui ne sont pas correctement mises à l’échelle peuvent entraîner des performances médiocres. Il existe de nombreux facteurs que vous devez prendre en compte pour avoir de bonnes performances sur votre cluster de passerelle.
Déterminer les spécifications matérielles du serveur de passerelle
Les spécifications du serveur de passerelle (processeur, mémoire, disque, et ainsi de suite) constituent un facteur important, comme dans la plupart des cas, les transformations Power Query sont appliquées aux données sur le serveur de passerelle. Par conséquent, un serveur de passerelle doit disposer de suffisamment de ressources, de mémoire et de puissance de traitement pour gérer toutes les transformations de données.
Lorsque vous devez choisir une taille de serveur, il existe deux métriques qui sont les plus importantes : la mémoire et le processeur. Vous avez besoin de suffisamment de mémoire et de puissance processeur pour traiter les étapes de transformation des données Power Query sur la passerelle. Il est important que votre serveur de passerelle soit suffisamment puissant pour traiter la charge de travail la plus élevée dont vous disposez. Si le serveur de passerelle n’est pas en mesure de gérer la charge de travail, votre requête directe ou l’actualisation des données échoue. Il est également important de comprendre le nombre de requêtes exécutées en même temps.
Ces différentes options de requête ont un effet différent sur votre serveur de passerelle.
| Type de requête | Facteur de limite |
|---|---|
| Importer | Mémoire |
| Requête Directe | CPU (Unité centrale de traitement) |
| LiveConnect | CPU (Unité centrale de traitement) |
Pendant une importation, l’ensemble des données doit être interrogé et traité, ce qui est une tâche gourmande en mémoire. Cette importation prend souvent plus de temps. DirectQueries et LiveConnections consomment généralement beaucoup de ressources processeur. Dans la plupart des cas, les requêtes directes sont exécutées plusieurs fois pour traiter uniquement une petite partie des données. Étant donné que seules une petite partie des données sont traitées, ces requêtes directes ne sont normalement pas une tâche importante en mémoire. Toutefois, étant donné que les requêtes sont exécutées plusieurs fois à la demande, cela peut être gourmand en processeur.
Selon votre charge de travail, envisagez d’optimiser votre serveur de passerelle pour la mémoire ou l’unité centrale.
Quand étendre un cluster de passerelle
La mise à l’échelle est un aspect important d’un cluster de passerelle critique pour l’entreprise. À mesure que votre utilisation du cluster de passerelles croît, celui-ci doit être augmenté et/ou élargi pour garantir de bonnes performances. Nous vous recommandons de commencer à effectuer une extension horizontale d’un cluster de passerelles si vous avez précédemment augmenté la capacité des passerelles dans le cluster.
La mise à l’échelle et la distribution de la charge du trafic entre des nœuds individuels au sein d’un cluster est un processus complexe qui varie en fonction de chaque scénario individuel. Bien qu’il n’existe aucun modèle définitif pour s’assurer que tout le trafic de passerelle est correctement servicené, les limites répertoriées ci-dessous indiquent un besoin de mise à l’échelle. En général, nous vous recommandons de privilégier l'extensibilité horizontale (ajout de nœuds au cluster) à l'extensibilité verticale (augmentation de l'UC, de la RAM ou de l'espace disque sur des nœuds individuels). Le scale-out tend à être plus efficace dans l’ensemble de la capacité du système à gérer le trafic supplémentaire. Le scale-out a également un impact positif sur la bande passante totale que le cluster peut traiter, tandis que le scale-up ne le fait généralement pas. Lorsqu’un ou plusieurs nœuds de passerelle montrent des signes d'atteinte des seuils suivants, l'extension du cluster devrait être sérieusement envisagée.
CPU : Le CPU dépasse 80% pendant des périodes prolongées ; cependant, les pics courts occasionnels (moins de 5 minutes) qui poussent le CPU à sa capacité maximale n'ont rien d'anormal.
RAM : la mémoire disponible tombe régulièrement en dessous de 20%.
Disque : l’espace disque libre est inférieur à 5 Go fréquemment. Ce creux peut également indiquer qu’il est nécessaire de configurer la mise en cache ou le spooling de répertoires de façon plus stratégique.
Concurrence : exécution simultanée de plus de 40 requêtes sur un seul nœud.
Étant donné que les actualisations et les requêtes distribuées entre les nœuds de passerelle peuvent avoir des profils très différents, nous vous recommandons également d’effectuer un examen supplémentaire sur des travaux longs ou gourmands en mémoire. L’optimisation des requêtes dans de tels cas peut avoir un impact considérable sur les performances et l’extensibilité, non seulement pour les rapports individuels et les actualisations, mais sur le système dans son ensemble. Nous vous recommandons d’isoler les actualisations en question sur un cluster de passerelle dédié unique pour évaluer les caractéristiques de performances et d’effectuer une optimisation à l’aide de diagnostics de plan de requête, d’indicateurs de repli et de toutes les autres recommandations de performances publiées. Cette isolation réduit la quantité de données récupérées et la quantité de post-traitement requise. Cette isolation peut également être utilisée comme stratégie à long terme pour isoler des tâches ETL de longue durée sur un cluster de passerelle dédié afin de réduire la concurrence avec d’autres actualisations régulières au sein de l’organisation.
Montée en puissance d’un cluster de passerelle
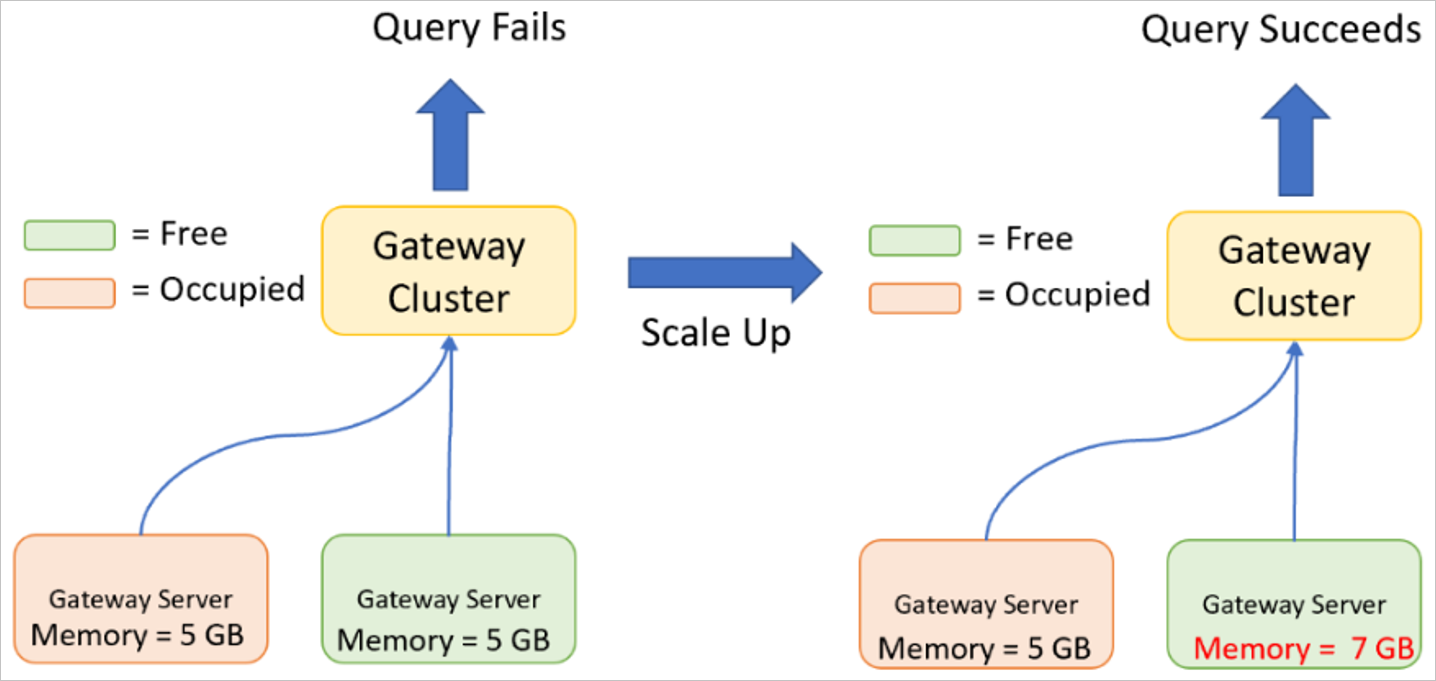
Le scale-up est lorsque vous augmentez les spécifications (processeur, mémoire, disque, et ainsi de suite) de vos serveurs de passerelle.
Le scale-up peut être nécessaire si le processeur maximal ou la mémoire est atteint lorsque la passerelle exécute une ou plusieurs requêtes. Une requête ne peut être exécutée que sur un seul serveur de passerelle, c’est pourquoi le serveur de passerelle doit disposer de suffisamment de ressources disponibles pour traiter l’intégralité de la requête, ainsi que les données obtenues.
Mise à l’échelle d’un cluster de passerelle
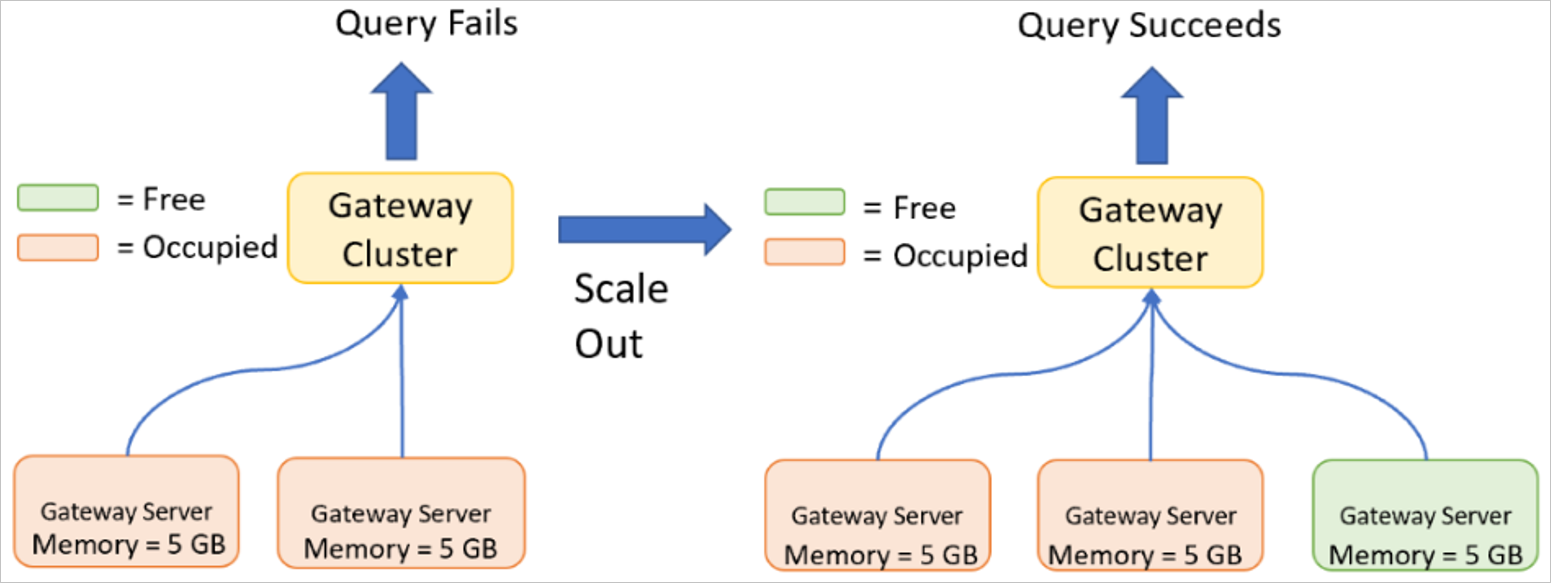
Le scale-out est nécessaire si le serveur de passerelle a déjà des spécifications élevées (en d’autres termes, le serveur de passerelle a déjà été mis à l’échelle), ou si vous avez atteint les limites de ce qu’un serveur de passerelle unique peut gérer en raison du nombre de requêtes simultanées exécutées. L’augmentation de la charge à grande échelle sur l’ensemble des membres de la passerelle est une bonne indication que la mise à l’échelle d’un cluster en ajoutant des nœuds est la bonne décision. Quand la mise à l’échelle d'un cluster de passerelles fournit des seuils spécifiques qui indiquent quand il est temps de procéder à la mise à l’échelle. Pour plus d’informations sur l'extension horizontale, consultez Utiliser les fonctionnalités de haute disponibilité et d’équilibrage de charge de la passerelle.
Mise à l’échelle en créant des clusters de passerelles
Si l’utilisation des ressources de votre cluster de passerelle est élevée ou qu’un nombre exceptionnellement élevé d’utilisateurs s’appuient sur un cluster de passerelle, un nouveau cluster de passerelle peut être créé. Un sous-ensemble de la charge de travail peut ensuite être migré vers le nouveau cluster de passerelle. Lorsqu’un grand nombre d’utilisateurs s’appuient sur un cluster de passerelle unique, la probabilité qu’un utilisateur puisse envoyer une requête qui entraîne un impact significatif sur les performances sur l’ensemble du cluster de passerelle augmente considérablement.
Un nombre exceptionnellement élevé d’utilisateurs qui s’appuient sur un seul cluster de passerelle est un indicateur indiquant qu’un nouveau cluster de passerelle doit être créé.
Supervision et résolution des problèmes de performances de la passerelle
Il est important de surveiller les performances globales des passerelles critiques pour l’entreprise à l’aide de la fonctionnalité de supervision des performances de la passerelle . Vous pouvez également utiliser cette fonctionnalité pour résoudre les problèmes de performances, identifier les goulots d’étranglement et identifier les requêtes qui ont un impact sur les performances globales de la passerelle. Cette fonctionnalité est également un outil important pour vous aider à déterminer quand mettre à l’échelle un cluster de passerelle.
Si vous identifiez une requête comme ayant un impact important sur la passerelle, ce qui entraîne des performances globales médiocres, vous pourrez peut-être réécrire la requête afin d’être plus efficace et de réduire l’impact sur les performances.
Si Microsoft identifie des performances médiocres causées par une passerelle ou un composant lié à la passerelle, tel qu’une capacité Power BI Premium surchargée, le composant surchargé doit être corrigé en mettant à l’échelle ou en réduisant la charge. Microsoft n’examine pas les performances médiocres lorsqu’une passerelle ou un composant lié à la passerelle est surchargé.