Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Conseil / Astuce
Ce contenu est un extrait de l’eBook, Architecting Cloud Native .NET Applications pour Azure, disponible sur .NET Docs ou en tant que PDF téléchargeable gratuitement qui peut être lu hors connexion.

Le mantra préféré des consultants logiciels est de répondre à « Cela dépend » de toute question posée. Ce n'est pas parce que les consultants en logiciels aiment ne pas prendre de position. C’est parce qu’il n’y a pas de vraie réponse à toutes les questions dans les logiciels. Il n’y a pas de droit absolu et de tort, mais plutôt un équilibre entre les opposés.
Prenons, par exemple, les deux grandes écoles de développement d’applications web : applications monopage (SPA) et applications côté serveur. D’une part, l’expérience utilisateur a tendance à être meilleure avec les fournisseurs de services et la quantité de trafic vers le serveur web peut être réduite, ce qui permet de les héberger sur quelque chose aussi simple que l’hébergement statique. En revanche, les SPAs ont tendance à être plus lentes à développer et plus difficiles à tester. Quel est le bon choix ? Eh bien, cela dépend de votre situation.
Les applications natives cloud ne sont pas immunitaires à cette même dichotomie. Ils ont des avantages clairs en termes de vitesse de développement, de stabilité et d’extensibilité, mais leur gestion peut être un peu plus difficile.
Il y a des années, il n’était pas rare que le processus de déplacement d’une application du développement à la production prenne un mois, voire plus. Les entreprises ont publié des logiciels sur une cadence de 6 mois ou même chaque année. Il n’est pas nécessaire de regarder plus loin que Microsoft Windows pour avoir une idée de la cadence des versions acceptables avant les jours toujours verts de Windows 10. Cinq ans sont passés entre Windows XP et Vista, trois autres entre Vista et Windows 7.
Il est maintenant assez bien établi qu’être en mesure de publier rapidement des logiciels donne aux entreprises en déplacement rapide un énorme avantage sur leurs concurrents plus paresseux. C’est pour cette raison que les mises à jour majeures apportées à Windows 10 sont maintenant toutes les six mois environ.
Les modèles et les pratiques qui permettent des versions plus rapides et plus fiables pour fournir de la valeur à l’entreprise sont collectivement appelées DevOps. Ils se composent d’un large éventail d’idées couvrant l’ensemble du cycle de vie du développement logiciel, de la spécification d’une application jusqu’à la livraison et à l’exploitation de cette application.
DevOps a émergé avant les microservices et il est probable que le mouvement vers des services plus petits, plus adaptés aux services à usage n’aurait pas été possible sans DevOps pour rendre la publication et l’exploitation non seulement une, mais de nombreuses applications en production plus facile.
Figure 10-1 : DevOps et microservices.
Grâce à de bonnes pratiques DevOps, il est possible de réaliser les avantages des applications natives cloud sans suffocer sous une montagne de travail qui exploite réellement les applications.
Il n’y a pas de marteau doré quand il s’agit de DevOps. Personne ne peut vendre une solution complète et globale pour la publication et l’exploitation d’applications de haute qualité. Cela est dû au fait que chaque application est sauvagement différente de toutes les autres. Toutefois, il existe des outils qui peuvent faire de DevOps une proposition beaucoup moins intimidante. L’un de ces outils est appelé Azure DevOps.
Azure DevOps
Azure DevOps a une longue histoire. Ses origines remontent à l'époque où Team Foundation Server a été mis en ligne pour la première fois, à travers les divers changements de nom : Visual Studio Online et Visual Studio Team Services. Au fil des années, elle est devenue beaucoup plus que ses prédécesseurs.
Azure DevOps est divisé en cinq composants principaux :

Figure 10-2 - Azure DevOps.
Azure Repos - Gestion du code source qui prend en charge le vénérable contrôle de version de Team Foundation (TFVC) et le favori de l'industrie, Git. Les pull requests fournissent un moyen d’activer le codage social en encourageant la discussion sur les modifications au fur et à mesure de leur réalisation.
Azure Boards : fournit un outil de suivi des éléments de travail et de problème qui s’efforce de permettre aux utilisateurs de choisir les flux de travail qui fonctionnent le mieux pour eux. Il est fourni avec un certain nombre de modèles préconfigurés, y compris ceux qui prennent en charge les styles de développement SCRUM et Kanban.
Azure Pipelines : système de gestion de build et de mise en production qui prend en charge une intégration étroite avec Azure. Les builds peuvent être exécutées sur différentes plateformes de Windows à Linux vers macOS. Les agents de build peuvent être provisionnés dans le cloud ou localement.
Plans de test Azure : aucune personne de l’assurance qualité n’est laissée derrière avec la gestion des tests et la prise en charge exploratoire des tests proposées par la fonctionnalité Plans de test.
Artefacts Azure : flux de paquets qui permet aux entreprises de créer leurs propres versions internes, telles que NuGet, npm et autres. Il sert de double objectif d’agir en tant que cache de packages en amont en cas de défaillance d’un référentiel centralisé.
L’unité organisationnelle de niveau supérieur dans Azure DevOps est appelée Projet. Dans chaque projet, les différents composants, tels qu’Azure Artifacts, peuvent être activés et désactivés. Chacun de ces composants offre différents avantages pour les applications natives cloud. Les trois plus utiles sont les dépôts, les tableaux et les pipelines. Si les utilisateurs souhaitent gérer leur code source dans une autre pile de référentiels, comme GitHub, mais toujours tirer parti d’Azure Pipelines et d’autres composants, cela est parfaitement possible.
Heureusement, les équipes de développement ont de nombreuses options lors de la sélection d’un référentiel. L’un d’eux est GitHub.
GitHub Actions (actions de GitHub)
Fondé en 2009, GitHub est un référentiel web largement populaire pour l’hébergement de projets, de documentation et de code. De nombreuses grandes entreprises technologiques, comme Apple, Amazon, Google et les grandes entreprises utilisent GitHub. GitHub utilise le système de contrôle de version distribué open source nommé Git comme base. Par-dessus, il ajoute ensuite son propre ensemble de fonctionnalités, notamment le suivi des défauts, les demandes de fonctionnalité et de tirage, la gestion des tâches et les wikis pour chaque codebase.
À mesure que GitHub évolue, il ajoute également des fonctionnalités DevOps. Par exemple, GitHub possède son propre pipeline d’intégration continue/livraison continue (CI/CD), appelé GitHub Actions. GitHub Actions est un outil d’automatisation de flux de travail alimenté par la communauté. Elle permet aux équipes DevOps de s’intégrer à leurs outils existants, de combiner et de mettre en correspondance de nouveaux produits et de se connecter à leur cycle de vie logiciel, y compris les partenaires CI/CD existants.
GitHub compte plus de 40 millions d’utilisateurs, ce qui en fait le plus grand hôte de code source dans le monde. En octobre 2018, Microsoft a acheté GitHub. Microsoft s’est engagé à ce que GitHub reste une plateforme ouverte que tout développeur peut connecter et étendre. Elle continue à fonctionner en tant qu’entreprise indépendante. GitHub propose des plans pour les comptes d’entreprise, d’équipe, professionnels et gratuits.
Gestion des sources
L’organisation du code pour une application native cloud peut être difficile. Au lieu d’une application géante unique, les applications natives cloud ont tendance à être constituées d’un web d’applications plus petites qui communiquent entre elles. Comme pour toutes les choses dans l’informatique, la meilleure disposition du code reste une question ouverte. Il existe des exemples d’applications réussies utilisant différents types de dispositions, mais deux variantes semblent avoir la plus populaire.
Avant de descendre dans le contrôle de code source proprement dit, il est probablement utile de décider du nombre de projets appropriés. Au sein d’un seul projet, plusieurs dépôts et pipelines de build sont pris en charge. Les tableaux sont un peu plus compliqués, mais les tâches peuvent également être facilement affectées à plusieurs équipes au sein d’un même projet. Il est possible de prendre en charge des centaines, voire des milliers de développeurs, sur un seul projet Azure DevOps. Cela est probablement la meilleure approche, car elle fournit un emplacement unique pour que tous les développeurs puissent travailler et réduit la confusion dans la recherche d'une application lorsque les développeurs ne sont pas certains dans quel projet elle réside.
Le fractionnement du code pour les microservices au sein du projet Azure DevOps peut être légèrement plus difficile.
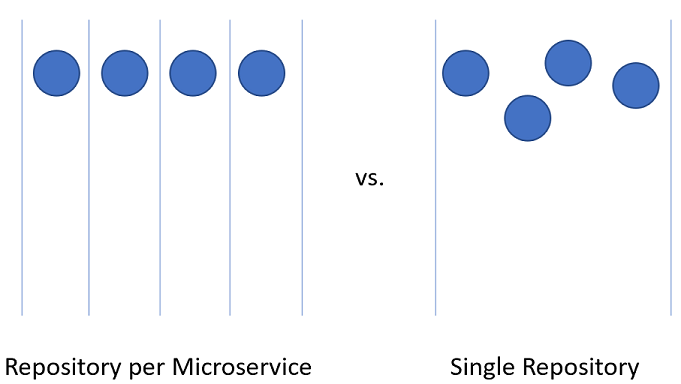
Figure 10-3 - Un et plusieurs référentiels.
Dépôt par microservice
À première vue, cette approche semble être l’approche la plus logique pour fractionner le code source pour les microservices. Chaque référentiel peut contenir le code nécessaire pour générer le microservice. Les avantages de cette approche sont facilement visibles :
- Les instructions de création et de maintenance de l’application peuvent être ajoutées à un fichier README à la racine de chaque dépôt. Lorsque vous parcourez les référentiels, il est facile de trouver ces instructions, ce qui réduit le temps de démarrage pour les développeurs.
- Chaque service se trouve à un endroit logique, facilement trouvé en sachant le nom du service.
- Les builds peuvent facilement être configurées afin qu’elles soient déclenchées uniquement lorsqu’une modification est apportée au référentiel propriétaire.
- Le nombre de modifications entrant dans un référentiel est limité au petit nombre de développeurs travaillant sur le projet.
- La sécurité est facile à configurer en limitant les dépôts auxquels les développeurs disposent d’autorisations de lecture et d’écriture.
- Les paramètres au niveau du référentiel peuvent être modifiés par l’équipe propriétaire avec un minimum de discussions avec d’autres personnes.
L’une des principales idées derrière les microservices est que les services doivent être en silo et séparés les uns des autres. Lorsque vous utilisez la conception pilotée par le domaine pour décider des limites des services, les services agissent comme des limites transactionnelles. Les mises à jour de base de données ne doivent pas s’étendre sur plusieurs services. Cette collection de données associées est appelée contexte limité. Cette idée est reflétée par l’isolation des données de microservice vers une base de données distincte et autonome du reste des services. Il est très judicieux de porter cette idée jusqu’au code source.
Toutefois, cette approche n’est pas sans ses problèmes. L'un des problèmes de développement les plus épineux de notre époque est la gestion des dépendances. Considérez le nombre de fichiers qui composent le répertoire moyen node_modules . Une nouvelle installation de quelque chose comme create-react-app est susceptible d’apporter avec elle des milliers de packages. La question de la gestion de ces dépendances est difficile.
Si une dépendance est mise à jour, les packages en aval doivent également mettre à jour cette dépendance. Malheureusement, cela prend du travail de développement de sorte que, invariablement, le node_modules répertoire se retrouve avec plusieurs versions d’un seul package, chacune une dépendance d’un autre package versionné à une cadence légèrement différente. Lors du déploiement d’une application, quelle version d’une dépendance doit être utilisée ? La version actuellement en production ? La version qui est actuellement en bêta, mais qui devrait être en production lorsque le consommateur commencera à l'utiliser ? Problèmes difficiles qui ne sont pas résolus uniquement à l’aide de microservices.
Il existe des bibliothèques qui dépendent d’un large éventail de projets. En divisant les microservices avec un dans chaque référentiel, les dépendances internes peuvent être résolues au mieux à l’aide du référentiel interne, Azure Artifacts. Les builds pour les bibliothèques envoieront leurs dernières versions dans Azure Artifacts pour une consommation interne. Le projet en aval doit toujours être mis à jour manuellement pour prendre une dépendance sur les packages nouvellement mis à jour.
Un autre inconvénient se présente lors du déplacement du code entre les services. Même si ce serait bien commode de penser que le premier découpage d’une application en microservices est correcte à 100 %, la réalité est que nous sommes rarement clairvoyants au point de ne commettre aucune erreur dans le découpage. Par conséquent, les fonctionnalités et le code qui les pilote doivent passer de service en service : de référentiel en référentiel. Lorsque vous passez d’un référentiel à un autre, le code perd son historique. Il existe de nombreux cas, en particulier en cas d’audit, où l’historique complet d’un élément de code est inestimable.
L’inconvénient final et le plus important est la coordination des changements. Dans une application de microservices vraie, il ne doit y avoir aucune dépendance de déploiement entre les services. Il doit être possible de déployer les services A, B et C dans n’importe quel ordre, car ils ont un couplage libre. En réalité, il existe toutefois des moments où il est souhaitable d’apporter une modification qui traverse plusieurs référentiels en même temps. Certains exemples incluent la mise à jour d’une bibliothèque pour fermer un trou de sécurité ou modifier un protocole de communication utilisé par tous les services.
Pour effectuer une modification entre référentiels, vous devez effectuer une validation sur chaque référentiel en succession. Chaque modification dans chaque référentiel devra faire l'objet d'une requête de tirage et être examinée séparément. Cette activité peut être difficile à coordonner.
Une alternative à l’utilisation de nombreux référentiels consiste à regrouper tout le code source dans un géant référentiel unique, omniscient.
Référentiel unique
Dans cette approche, parfois appelée monorépository, tout le code source de chaque service est placé dans le même référentiel. D'abord, cette approche semble être une idée épouvantable qui risque de rendre la gestion du code source rébarbatif. Toutefois, il existe des avantages marqués pour travailler de cette façon.
Le premier avantage est qu’il est plus facile de gérer les dépendances entre les projets. Au lieu de compter sur un flux d’artefacts externe, les projets peuvent importer directement les uns les autres. Cela signifie que les mises à jour sont instantanées et que les versions en conflit sont susceptibles d’être trouvées au moment de la compilation sur la station de travail du développeur. Cela a pour effet de déplacer certains tests d’intégration vers la gauche.
Lorsque vous déplacez du code entre des projets, il est désormais plus facile de conserver l’historique, car les fichiers seront détectés comme ayant été déplacés plutôt que réécrits.
Un autre avantage est que des modifications de grande envergure qui dépassent les limites des services peuvent être apportées en un seul commit. Cette activité réduit la surcharge d’avoir potentiellement des dizaines de modifications à examiner individuellement.
De nombreux outils peuvent effectuer une analyse statique du code pour détecter les pratiques de programmation non sécurisées ou l’utilisation problématique des API. Dans un monde à plusieurs référentiels, chaque référentiel doit être itéré pour trouver les problèmes qui y sont rencontrés. Le référentiel unique permet d’exécuter l’analyse en un seul endroit.
Il existe également de nombreux inconvénients à l’approche du dépôt unique. L’un des plus inquiétants est que l’utilisation d’un référentiel unique soulève des préoccupations de sécurité. Si le contenu d’un référentiel est divulgué dans un modèle de référentiel par service, la quantité de code perdue est minimale. Avec un dépôt unique, tout ce que l’entreprise possède peut être perdu. Il y a eu beaucoup d'exemples dans le passé de ce phénomène, qui ont déraillé l'ensemble des efforts de développement des jeux. Le fait d’avoir plusieurs dépôts expose moins de surface d’exposition, ce qui est une caractéristique souhaitable dans la plupart des pratiques de sécurité.
La taille du référentiel unique est susceptible de devenir inmanageable rapidement. Cela présente des implications intéressantes sur les performances. Il peut être nécessaire d’utiliser des outils spécialisés tels que Virtual File System pour Git, qui a été initialement conçu pour améliorer l’expérience des développeurs sur l’équipe Windows.
Souvent, l’argument d’utilisation d’un référentiel unique se résume à un argument que Facebook ou Google utilise cette méthode pour la disposition du code source. Si l’approche est suffisante pour ces entreprises, alors, sûrement, c’est l’approche correcte pour toutes les entreprises. La vérité de la question est que peu d’entreprises opèrent sur quelque chose comme l’échelle de Facebook ou Google. Les problèmes qui se produisent à ces échelles sont différents de ceux auxquels la plupart des développeurs seront confrontés. Ce qui est bon pour l’oie peut ne pas être bon pour le gander.
À la fin, l’une ou l’autre solution peut être utilisée pour héberger le code source pour les microservices. Toutefois, dans la plupart des cas, la gestion et la surcharge d’ingénierie de l’exploitation dans un référentiel unique ne valent pas les avantages moindres. Le fractionnement du code sur plusieurs référentiels favorise une meilleure séparation des préoccupations et encourage l’autonomie entre les équipes de développement.
Structure de répertoire standard
Quel que soit le débat sur des référentiels uniques ou multiples, chaque service aura son propre répertoire. L’une des meilleures optimisations pour permettre aux développeurs de traverser rapidement les projets consiste à maintenir une structure de répertoire standard.
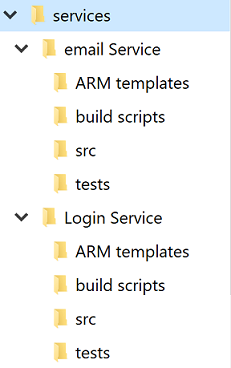
Figure 10-4 - Structure de répertoire standard.
Chaque fois qu’un projet est créé, un modèle qui met en place la structure appropriée doit être utilisé. Ce modèle peut également inclure des éléments utiles comme un fichier README squelette et un azure-pipelines.yml. Dans toute architecture de microservice, un degré élevé de variance entre les projets rend les opérations en bloc sur les services plus difficiles.
Il existe de nombreux outils qui peuvent fournir des modèles pour un répertoire entier, contenant plusieurs répertoires de code source. Yeoman est populaire dans le monde JavaScript et GitHub ont récemment publié des modèles de référentiel, qui fournissent une grande partie des mêmes fonctionnalités.
Gestion des tâches
La gestion des tâches dans n’importe quel projet peut être difficile. À l’avance, il existe de nombreuses questions à répondre au type de flux de travail à configurer pour garantir une productivité optimale des développeurs.
Les applications natives cloud ont tendance à être plus petites que les produits logiciels traditionnels, ou au moins elles sont divisées en services plus petits. Le suivi des problèmes ou des tâches liés à ces services reste aussi important qu’avec tout autre projet logiciel. Personne ne veut perdre le suivi d’un élément de travail ou expliquer à un client que son problème n’a pas été correctement enregistré. Les tableaux sont configurés au niveau du projet, mais dans chaque projet, des zones peuvent être définies. Celles-ci permettent de décomposer les problèmes en plusieurs composants. L’avantage de conserver tout le travail de l’application dans un seul endroit est qu’il est facile de déplacer des éléments de travail d’une équipe à un autre, car ils sont mieux compris.
Azure DevOps est fourni avec un certain nombre de modèles populaires préconfigurés. Dans la configuration la plus simple, il suffit de savoir ce qui se trouve dans la liste de tâches en attente, ce sur quoi les gens travaillent et ce qui est fait. Il est important d'avoir cette visibilité sur le processus de création de logiciels, afin que le travail puisse être hiérarchisé et que les tâches terminées puissent être signalées au client. Bien sûr, peu de projets logiciels collent à un processus aussi simple que to do, doinget done. Il ne faut pas longtemps pour que les utilisateurs commencent à ajouter des étapes comme QA ou Detailed Specification au processus.
L’une des parties les plus importantes des méthodologies Agile est l’auto-introspection à intervalles réguliers. Ces révisions sont destinées à fournir des informations sur les problèmes auxquels l’équipe est confrontée et sur la façon dont elles peuvent être améliorées. Cela signifie souvent changer le flux de problèmes et de fonctionnalités par le biais du processus de développement. Il est donc parfaitement sain d’étendre les présentations des tableaux avec des phases supplémentaires.
Les phases des tableaux ne constituent pas le seul outil organisationnel. Selon la configuration de la carte, il existe une hiérarchie d’éléments de travail. L’élément le plus granulaire qui peut apparaître sur un tableau est une tâche. Par défaut, une tâche contient des champs pour un titre, une description, une priorité, une estimation de travail restant et la possibilité de lier à d’autres éléments de travail ou éléments de développement (branches, commits, pull requests, builds, etc.). Les éléments de travail peuvent être classés dans différentes zones de l’application et différentes itérations (sprints) pour faciliter leur recherche.
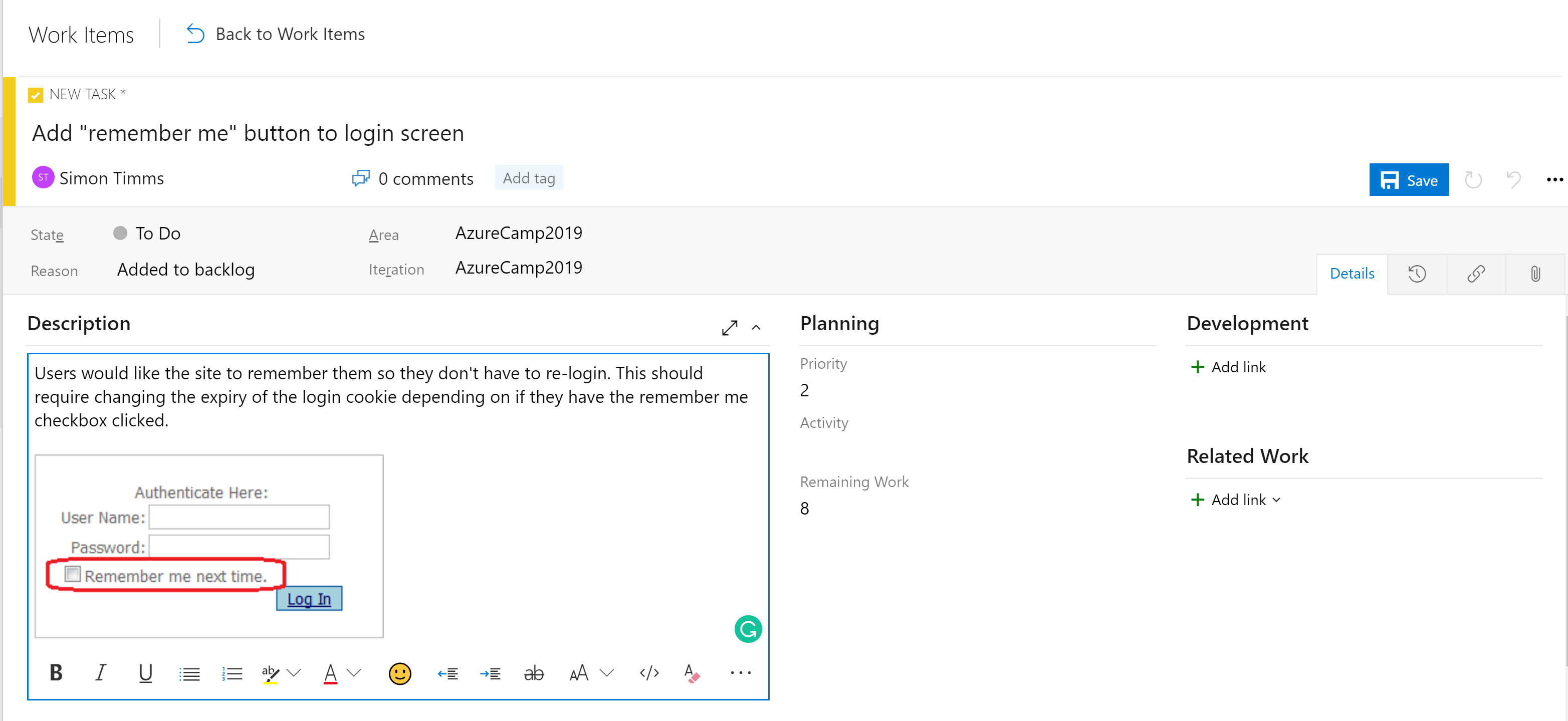
Figure 10-5 - Tâche dans Azure DevOps.
Le champ de description prend en charge les styles normaux attendus (gras, italique, souligné et barré) et la possibilité d’insérer des images. Cela en fait un outil puissant à utiliser pour établir les tâches ou résoudre les bogues.
Les tâches peuvent être regroupées dans des fonctionnalités qui définissent une unité de travail plus grande. Les caractéristiques, à leur tour, peuvent être regroupées en épopées. La classification des tâches dans cette hiérarchie facilite considérablement la compréhension du déploiement d'une grande fonctionnalité.

Figure 10-6 - Élément de travail dans Azure DevOps.
Il existe différents types de vues sur les problèmes dans Azure Boards. Les éléments qui ne sont pas encore planifiés apparaissent dans le backlog. Dès lors, ils peuvent être assignés à un sprint. Un sprint est une boîte de temps pendant laquelle il est prévu qu’une certaine quantité de travail sera terminée. Ce travail peut inclure des tâches, mais également la résolution des tickets. Une fois là, l’ensemble du sprint peut être géré à partir de la section du tableau Sprint. Cette vue montre comment le travail progresse et inclut un graphique d’avancement pour donner une estimation toujours à jour sur les chances de réussite du sprint.
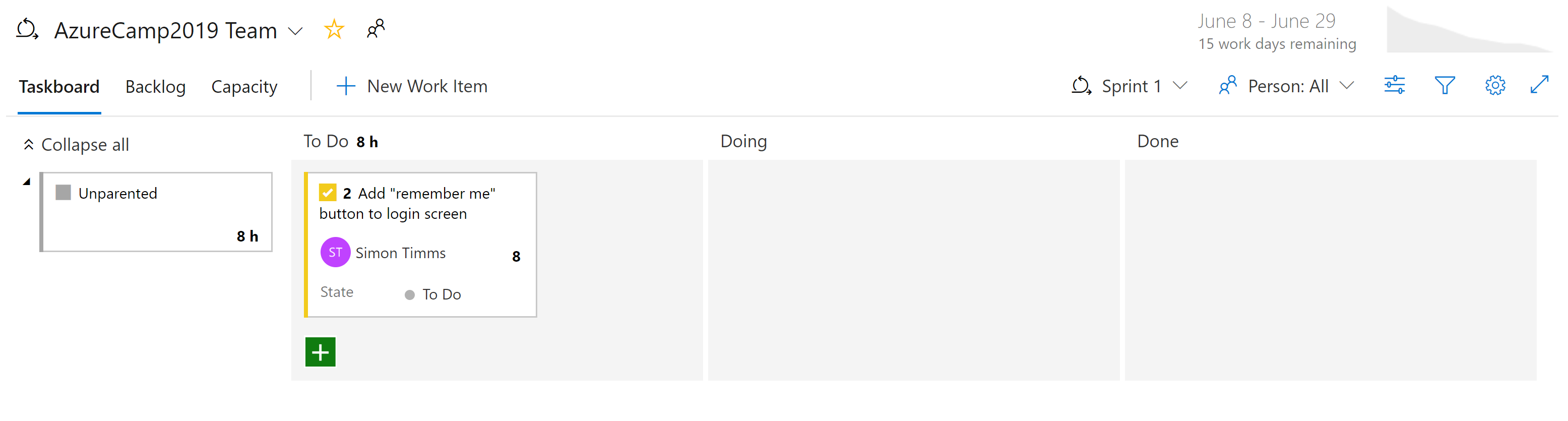
Figure 10-7 - Tableau dans Azure DevOps.
À présent, il doit être évident qu’il y a beaucoup de puissance dans les boards dans Azure DevOps. Pour les développeurs, il existe des vues claires sur ce qui est en cours. Pour les gestionnaires de projets, les vues sur le travail à venir ainsi qu’une vue d’ensemble du travail existant. Pour les responsables, il y a beaucoup de rapports sur la ressource et la capacité. Malheureusement, il n’y a rien de magique sur les applications natives cloud qui éliminent la nécessité de suivre le travail. Mais si vous devez suivre le travail, il existe quelques endroits où l’expérience est meilleure que dans Azure DevOps.
Pipelines CI/CD
Presque aucun changement dans le cycle de vie du développement logiciel a été si révolutionnaire que l’avènement de l’intégration continue (CI) et de la livraison continue (CD). La création et l’exécution de tests automatisés sur le code source d’un projet dès qu’une modification est validée permettent de détecter les erreurs tôt. Avant l’avènement des builds d’intégration continue, il n’est pas rare d’extraire du code à partir du référentiel et de trouver qu’il n’a pas réussi de tests ou qu’il n’a même pas pu être généré. Cela a conduit à identifier l'origine de la rupture.
Traditionnellement, l’expédition de logiciels vers l’environnement de production nécessite une documentation complète et une liste d’étapes. Chacune de ces étapes devait être effectuée manuellement dans un processus très sujette aux erreurs.

Figure 10-8 - Liste de contrôle.
La sœur de l’intégration continue est la livraison continue, où les packages fraîchement construits sont déployés dans un environnement. Le processus manuel ne peut pas être mis à l’échelle pour correspondre à la vitesse de développement afin que l’automatisation devienne plus importante. Les listes de contrôle sont remplacées par des scripts qui peuvent exécuter les mêmes tâches plus rapidement et plus précisément que n’importe quel humain.
L’environnement auquel la livraison continue peut être un environnement de test ou, comme le fait de nombreuses grandes entreprises technologiques, il peut s’agir de l’environnement de production. Ce dernier nécessite un investissement dans des tests de haute qualité qui peuvent donner confiance qu’un changement ne va pas interrompre la production pour les utilisateurs. De la même façon que l’intégration continue intercepte tôt les problèmes dans le code, la livraison continue intercepte tôt les problèmes dans le processus de déploiement.
L’importance de l’automatisation du processus de génération et de livraison est accentuée par les applications natives cloud. Les déploiements se produisent plus fréquemment et dans plus d'environnements, de sorte que le déploiement manuel devient presque impossible.
Azure Builds
Azure DevOps fournit un ensemble d’outils pour faciliter l’intégration et le déploiement continus que jamais. Ces outils se trouvent sous Azure Pipelines. La première d’entre elles est Azure Builds, qui est un outil permettant d’exécuter des définitions de build basées sur YAML à grande échelle. Les utilisateurs peuvent apporter leurs propres machines de build (idéal pour les cas où le build nécessite un environnement configuré méticuleusement), ou utiliser une machine à partir d’un pool constamment actualisé de machines virtuelles hébergées par Azure. Ces agents de build hébergés sont préinstallés avec un large éventail d’outils de développement non seulement pour le développement .NET, mais pour tout, de Java à Python vers le développement iPhone.
DevOps inclut un large éventail de définitions de build prêtes à l’emploi qui peuvent être personnalisées pour n’importe quelle build. Les définitions de build sont définies dans un fichier appelé azure-pipelines.yml et archivé dans le référentiel afin qu’elles puissent être versionnée avec le code source. Cela facilite beaucoup l’apport de modifications au pipeline de build dans une branche, car celles-ci peuvent être vérifiées juste dans cette branche. L’exemple azure-pipelines.yml de création d’une application web ASP.NET sur une infrastructure complète est illustré dans la figure 10-9.
name: $(rev:r)
variables:
version: 9.2.0.$(Build.BuildNumber)
solution: Portals.sln
artifactName: drop
buildPlatform: any cpu
buildConfiguration: release
pool:
name: Hosted VisualStudio
demands:
- msbuild
- visualstudio
- vstest
steps:
- task: NuGetToolInstaller@0
displayName: 'Use NuGet 4.4.1'
inputs:
versionSpec: 4.4.1
- task: NuGetCommand@2
displayName: 'NuGet restore'
inputs:
restoreSolution: '$(solution)'
- task: VSBuild@1
displayName: 'Build solution'
inputs:
solution: '$(solution)'
msbuildArgs: '-p:DeployOnBuild=true -p:WebPublishMethod=Package -p:PackageAsSingleFile=true -p:SkipInvalidConfigurations=true -p:PackageLocation="$(build.artifactstagingdirectory)\\"'
platform: '$(buildPlatform)'
configuration: '$(buildConfiguration)'
- task: VSTest@2
displayName: 'Test Assemblies'
inputs:
testAssemblyVer2: |
**\$(buildConfiguration)\**\*test*.dll
!**\obj\**
!**\*testadapter.dll
platform: '$(buildPlatform)'
configuration: '$(buildConfiguration)'
- task: CopyFiles@2
displayName: 'Copy UI Test Files to: $(build.artifactstagingdirectory)'
inputs:
SourceFolder: UITests
TargetFolder: '$(build.artifactstagingdirectory)/uitests'
- task: PublishBuildArtifacts@1
displayName: 'Publish Artifact'
inputs:
PathtoPublish: '$(build.artifactstagingdirectory)'
ArtifactName: '$(artifactName)'
condition: succeededOrFailed()
Figure 10-9 - Exemple de azure-pipelines.yml
Cette définition de build utilise un certain nombre de tâches intégrées qui rendent la création de builds aussi simple que la construction d’un ensemble Lego (plus simple que le géant Millennium Falcon). Par exemple, la tâche NuGet restaure les packages NuGet, tandis que la tâche VSBuild appelle les outils de génération Visual Studio pour effectuer la compilation réelle. Il existe des centaines de tâches différentes disponibles dans Azure DevOps, avec des milliers d’autres qui sont conservées par la communauté. Il est probable que, quelles que soient les tâches de construction que vous cherchez à exécuter, quelqu’un en a déjà créé.
Les builds peuvent être déclenchées manuellement, par un enregistrement, selon un calendrier ou par l’achèvement d’une autre build. Dans la plupart des cas, créer une build à chaque archivage est souhaitable. Les builds peuvent être filtrées afin que différentes builds s’exécutent sur différentes parties du référentiel ou sur différentes branches. Cela ouvre des scénarios tels que l’exécution de builds rapides avec des tests réduits sur les demandes de tirage et l’exécution d’une suite de régressions complète sur le tronc toutes les nuits.
Le résultat final d’une build est une collection de fichiers appelés artefacts de build. Ces artefacts peuvent être transmis à l’étape suivante du processus de génération ou ajoutés à un flux Azure Artifacts, afin qu’ils puissent être consommés par d’autres builds.
Mises en production Azure DevOps
Les processus de construction prennent soin de compiler le logiciel dans un package prêt à être distribué, mais les artéfacts doivent toujours être envoyés vers un environnement de test pour compléter le déploiement continu. Pour cela, Azure DevOps utilise un outil distinct appelé Releases. L’outil Releases utilise la même bibliothèque de tâches que celle qui était disponible pour la build, mais introduit un concept de « phases ». Une phase est un environnement isolé dans lequel le package est installé. Par exemple, un produit peut utiliser un développement, une assurance qualité et un environnement de production. Le code est remis en continu dans l’environnement de développement dans lequel les tests automatisés peuvent être exécutés sur celui-ci. Une fois que ces tests réussissent, la version passe dans l'environnement de test qualité pour les tests manuels. Enfin, le code est envoyé à la production où il est visible pour tout le monde.

Figure 10-10 - Pipeline de mise en production
Chaque étape de la build peut être déclenchée automatiquement par l’achèvement de la phase précédente. Toutefois, dans de nombreux cas, cela n’est pas souhaitable. Le déplacement du code en production peut nécessiter l’approbation de quelqu’un. L'outil Releases prend en charge ce processus en permettant aux approbateurs d'intervenir à chaque étape du pipeline de mise en production. Les règles peuvent être configurées de façon qu'une personne ou un groupe spécifique de personnes doive approuver une version avant qu'elle ne passe en production. Ces portes permettent de vérifier manuellement la qualité et de respecter les exigences réglementaires relatives au contrôle de ce qui passe en production.
Tout le monde obtient un pipeline de build
Il n’y a aucun coût pour configurer de nombreux pipelines de build. Il est donc avantageux d’avoir au moins un pipeline de build par microservice. Dans l’idéal, les microservices sont déployables indépendamment dans n’importe quel environnement, de sorte que chacun d’eux puisse être libéré via son propre pipeline sans libérer une masse de code non lié est parfaite. Chaque pipeline peut avoir son propre ensemble d’approbations permettant des variations dans le processus de génération pour chaque service.
Versioning des mises en production
L’un des inconvénients de l’utilisation de la fonctionnalité Releases est qu’elle ne peut pas être définie dans un fichier azure-pipelines.yml archivé. Il existe de nombreuses raisons pour lesquelles vous pourriez vouloir faire cela, qu'il s'agisse de disposer de définitions par branche des versions ou d'inclure un modèle de base de version dans votre template de projet. Heureusement, le travail est en cours pour déplacer une partie de la prise en charge des étapes dans le composant Build. Cette version sera appelée build multi-phases et la première version est désormais disponible !
Collaborer avec nous sur GitHub
La source de ce contenu se trouve sur GitHub, où vous pouvez également créer et examiner les problèmes et les demandes de tirage. Pour plus d’informations, consultez notre guide du contributeur.