Souveraineté des données par microservice
Conseil
Ce contenu est un extrait du livre électronique « .NET Microservices Architecture for Containerized .NET Applications », disponible sur .NET Docs ou sous forme de PDF téléchargeable gratuitement et pouvant être lu hors ligne.

L’architecture en microservices obéit à une règle importante, à savoir que chaque microservice doit posséder les données et la logique de son domaine. Au même titre qu’une application complète, chaque microservice doit posséder sa logique et ses données dans un cycle de vie autonome, avec un déploiement indépendant par microservice.
Cela signifie que le modèle conceptuel du domaine varie d’un sous-système ou d’un microservice à l’autre. Par exemple, dans le cas des applications d’entreprise, l’application de gestion de la relation client, le sous-système de vente transactionnelle et le sous-système d’assistance à la clientèle appellent chacun les attributs et les données d’une entité client unique, et utilisent chacun un contexte délimité (BC, Bounded Context) différent.
Ce principe est similaire dans la Conception pilotée par le domaine (DDD, Domain-Driven Design), où chaque contexte délimité ou sous-système ou service autonome doit posséder son modèle de domaine (données, logique et comportement). Chaque contexte délimité DDD correspond à un microservice d’entreprise (un ou plusieurs services). Le modèle Contexte délimité est traité de manière plus détaillée dans la section suivante.
D’un autre côté, l’approche traditionnelle (données monolithiques) utilisée dans de nombreuses applications consiste à avoir une seule base de données centralisée ou seulement quelques-unes. Il s’agit souvent d’une base de données SQL normalisée, utilisée pour l’ensemble de l’application et tous ses sous-systèmes internes (figure 4-7).
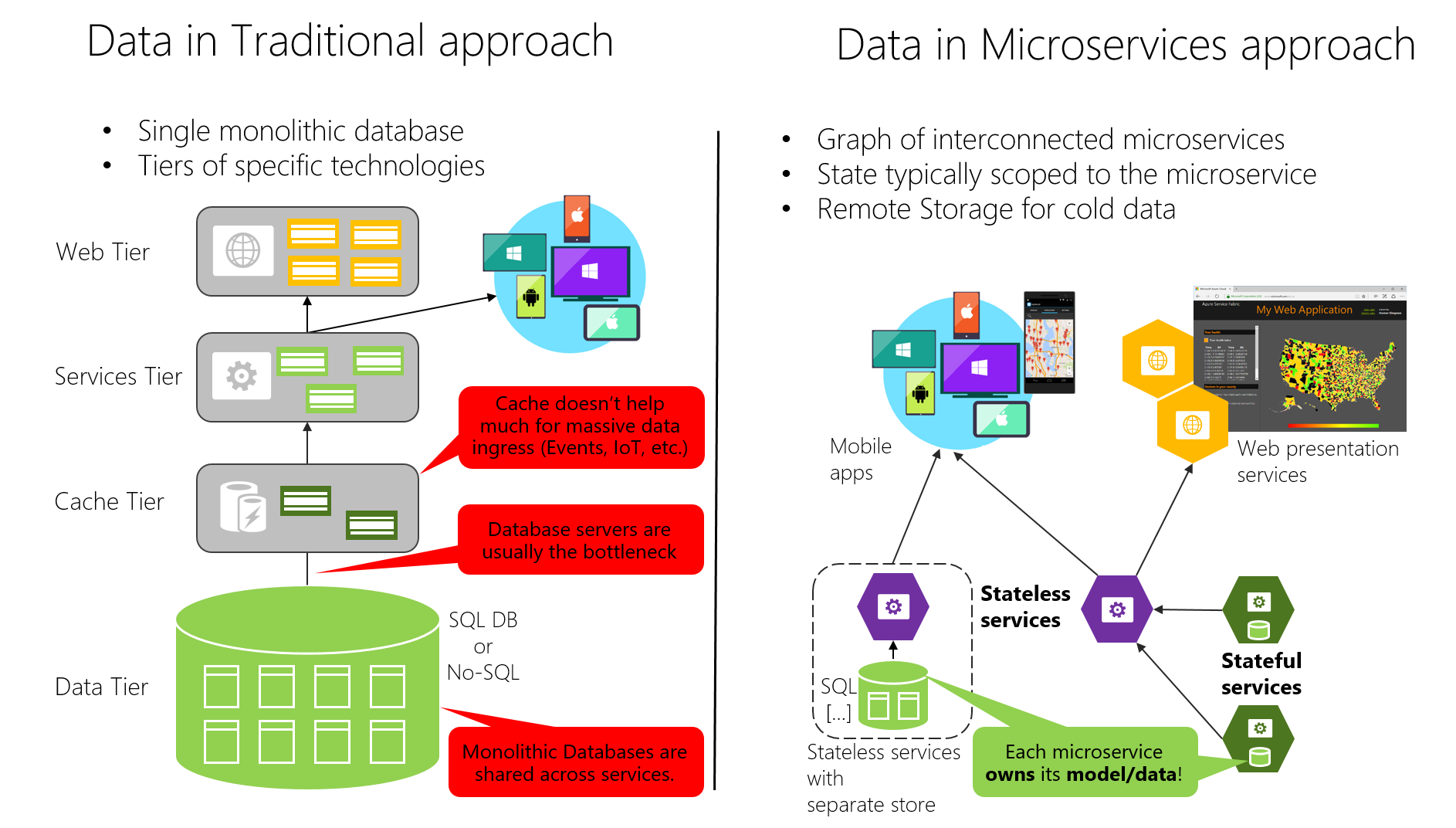
Figure 4-7. Comparaison de la souveraineté des données : base de données monolithique et microservices
Dans l’approche classique, il existe une seule base de données partagée entre tous les services, généralement dans une architecture à plusieurs niveaux. Dans l’approche basée sur les microservices, chaque microservice comporte son modèle/ses données. À première vue, l’approche consistant à utiliser une base de données centralisée est plus simple et prend en charge la réutilisation des entités dans différents sous-systèmes à des fins de cohérence. Mais en réalité, vous vous retrouvez avec des tables énormes qui sont au service de différents sous-systèmes, et qui incluent des attributs et des colonnes superflus dans la plupart des cas. Tout se passe comme si vous utilisiez la même carte pour faire une petite promenade à pied, faire un trajet en voiture d’une journée et apprendre la géographie.
Une application monolithique, qui comprend généralement une seule base de données relationnelle, offre deux avantages importants : les transactions ACID et le langage SQL, ces deux éléments fonctionnant sur toutes les tables et toutes les données relatives à votre application. Cette approche vous permet d’écrire facilement une requête qui combine les données de plusieurs tables.
Toutefois, l’accès aux données devient bien plus compliqué lorsque vous passez à une architecture de microservices. Même lorsque vous utilisez des transactions ACID dans un microservice ou un contexte délimité, il est essentiel de considérer que les données détenues par chaque microservice sont privées à ce microservice et doivent uniquement être accessibles de manière synchrone via ses points de terminaison d’API (REST, gRPC, SOAP, etc.) ou de manière asynchrone via la messagerie (AMQP ou similaire).
L’encapsulation des données garantit que les microservices sont faiblement couplés et qu’ils peuvent évoluer indépendamment les uns des autres. Si plusieurs services accèdent aux mêmes données, les mises à jour du schéma nécessitent l’application de mises à jour coordonnées à tous les services, ce qui peut compromettre l’autonomie du cycle de vie des microservices. Toutefois, les structures de données distribuées ne vous permettent pas d’effectuer une même transaction ACID sur plusieurs microservices. Vous devez donc recourir à la cohérence à terme quand un processus d’entreprise s’étend sur plusieurs microservices. Cela est beaucoup plus difficile à implémenter que de simples jointures SQL, car vous ne pouvez pas créer de contraintes d’intégrité ni utiliser de transactions distribuées entre des bases de données distinctes, comme nous l’allons l’expliquer plus tard. De même, de nombreuses autres fonctionnalités propres aux bases de données relationnelles ne sont pas disponibles à l’échelle de plusieurs microservices.
Pour aller encore plus loin, des microservices différents utilisent souvent différents genres de bases de données. Les applications modernes stockent et traitent différents genres de données. Une base de données relationnelle ne constitue pas toujours le meilleur choix. Pour certains cas d’usage, une base de données NoSQL comme Azure CosmosDB ou MongoDB peut offrir un modèle de données plus pratique ainsi qu’un meilleur niveau de performance et de scalabilité qu’une base de données SQL comme SQL Server ou Azure SQL Database. Dans d’autres cas, une base de données relationnelle reste la meilleure approche. Les applications basées sur des microservices utilisent donc souvent un mélange de bases de données SQL et NoSQL, une approche parfois appelée « persistance polyglotte ».
Une architecture partitionnée avec persistance polyglotte pour le stockage de données présente de nombreux avantages, notamment des services faiblement couplés et de meilleurs résultats en termes de performances, de scalabilité, de coûts et de facilité de gestion. Toutefois, elle peut entraîner des problèmes de gestion des données distribuée, comme indiqué dans « Identification des limites du modèle de domaine » plus loin dans ce chapitre.
Relation entre les microservices et le modèle Contexte délimité
Le concept de microservice dérive du modèle de Contexte délimité (BC, Bounded Context) présenté dans la conception pilotée par le domaine (DDD, Domain-Driven Design). La conception DDD gère les modèles volumineux en les divisant en plusieurs contextes délimités et en définissant leurs limites de manière explicite. Chaque contexte délimité doit avoir son propre modèle et sa propre base de données. De même, chaque microservice possède ses données connexes. Chaque contexte délimité a aussi généralement son propre langage omniprésent pour faciliter la communication entre les développeurs de logiciels et les experts du domaine.
Les termes du langage omniprésent (principalement des entités de domaine) peuvent avoir d’autres noms dans différents contextes délimités, même quand différentes entités de domaine partagent la même identité (c’est-à-dire l’ID unique utilisé pour lire l’entité dans le stockage). Par exemple, dans le contexte délimité d’un profil utilisateur, l’entité de domaine User peut partager l’identité avec l’entité de domaine Buyer dans le contexte délimité de la commande.
Un microservice est donc similaire à un contexte délimité, mais il indique également qu’il est un service distribué. Il se présente sous la forme d’un processus distinct pour chaque contexte délimité et doit utiliser les protocoles distribués indiqués précédemment, notamment HTTP/HTTPS, WebSockets ou AMQP. Toutefois, le modèle Contexte délimité ne spécifie pas si le contexte délimité est un service distribué, ou s’il s’agit simplement d’une limite logique (par exemple un sous-système générique) dans une application à déploiement monolithique.
Il est important de souligner que la définition d’un service pour chaque contexte délimité est un bon point de départ. Mais cela ne doit en aucun cas restreindre votre conception. Parfois, vous devez concevoir un contexte délimité ou un microservice d’entreprise composé de plusieurs services physiques. En fin de compte, les deux modèles (Contexte délimité et microservice) sont étroitement liés.
La conception DDD tire parti des microservices en obtenant les limites réelles sous la forme de microservices distribués. Mais le fait de ne pas partager le modèle entre microservices dans un contexte délimité peut aussi être ce que vous recherchez.
Ressources supplémentaires
Chris Richardson. Pattern: Database per service
https://microservices.io/patterns/data/database-per-service.htmlMartin Fowler. BoundedContext
https://martinfowler.com/bliki/BoundedContext.htmlMartin Fowler. PolyglotPersistence
https://martinfowler.com/bliki/PolyglotPersistence.htmlAlberto Brandolini. Strategic Domain Driven Design with Context Mapping
https://www.infoq.com/articles/ddd-contextmapping
Commentaires
Bientôt disponible : Tout au long de 2024, nous allons supprimer progressivement GitHub Issues comme mécanisme de commentaires pour le contenu et le remplacer par un nouveau système de commentaires. Pour plus d’informations, consultez https://aka.ms/ContentUserFeedback.
Envoyer et afficher des commentaires pour