Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Conseil / Astuce
Ce contenu est un extrait du livre électronique 'Architecture des microservices .NET pour les applications .NET conteneurisées', disponible sur .NET Docs ou en tant que PDF téléchargeable gratuitement, lisible hors ligne.

Défi n° 1 : Comment définir les limites de chaque microservice
La définition des limites de microservice est probablement le premier défi que toute personne rencontre. Chaque microservice doit être une partie de votre application et chaque microservice doit être autonome avec tous les avantages et défis qu’il transmet. Mais comment identifier ces limites ?
Tout d’abord, vous devez vous concentrer sur les modèles de domaine logiques de l’application et les données associées. Essayez d’identifier des îlots de données découplés et différents contextes au sein de la même application. Chaque contexte peut avoir un langage métier différent (termes commerciaux différents). Les contextes doivent être définis et gérés indépendamment. Les termes et entités utilisés dans ces différents contextes peuvent sembler similaires, mais vous pouvez découvrir que, dans un contexte particulier, un concept d’entreprise avec un autre est utilisé à des fins différentes dans un autre contexte, et peut même avoir un nom différent. Par exemple, un utilisateur peut être appelé utilisateur dans le contexte d’identité ou d’appartenance, en tant que client dans un contexte CRM, en tant qu’acheteur dans un contexte de commande, etc.
La façon dont vous identifiez les limites entre plusieurs contextes d’application avec un domaine différent pour chaque contexte est exactement la façon dont vous pouvez identifier les limites pour chaque microservice métier et son modèle de domaine et ses données connexes. Vous tentez toujours de réduire le couplage entre ces microservices. Ce guide décrit plus en détail cette conception d’identification et de modèle de domaine dans la section Identification des limites de modèle de domaine pour chaque microservice ultérieurement.
Défi n°2 : Comment créer des requêtes qui récupèrent des données à partir de plusieurs microservices
Un deuxième défi consiste à implémenter des requêtes qui récupèrent des données de plusieurs microservices, tout en évitant la communication chatteuse vers les microservices à partir d’applications clientes distantes. Par exemple, il peut s’agir d’un seul écran d’une application mobile qui doit afficher les informations utilisateur appartenant au panier, au catalogue et aux microservices d’identité utilisateur. Un autre exemple serait un rapport complexe impliquant de nombreuses tables situées dans plusieurs microservices. La solution appropriée dépend de la complexité des requêtes. Toutefois, dans tous les cas, vous aurez besoin d’un moyen d’agréger des informations si vous souhaitez améliorer l’efficacité des communications de votre système. Les solutions les plus populaires sont les suivantes.
Passerelle d’API. Pour une agrégation de données simple à partir de plusieurs microservices qui possèdent différentes bases de données, l’approche recommandée est un microservice d’agrégation appelé passerelle d’API. Toutefois, vous devez être prudent sur l’implémentation de ce modèle, car il peut s’agir d’un point d’étranglement dans votre système, et il peut violer le principe de l’autonomie des microservices. Pour atténuer cette possibilité, vous pouvez avoir plusieurs passerelles d’API affinées qui se concentrent chacune sur une « tranche » verticale ou un secteur d’activité du système. Le modèle de passerelle d’API est expliqué plus en détail dans la section Passerelle d’API plus loin.
Fédération GraphQL Une option à prendre en compte si vos microservices utilisent déjà GraphQL est la fédération GraphQL. La fédération vous permet de définir des « sous-graphes » à partir d’autres services et de les composer en un « supergraphe » agrégé qui agit comme un schéma autonome.
CQRS (Command Query Responsibility Segregation) avec des tables de requête/lectures. Une autre solution pour l’agrégation de données à partir de plusieurs microservices est le modèle d’affichage matérialisé. Dans cette approche, vous générez, à l’avance (préparez les données dénormalisées avant que les requêtes réelles ne se produisent), une table en lecture seule avec les données détenues par plusieurs microservices. Le tableau a un format adapté aux besoins de l’application cliente.
Considérez quelque chose comme l’écran d’une application mobile. Si vous disposez d’une base de données unique, vous pouvez rassembler les données de cet écran à l’aide d’une requête SQL qui effectue une jointure complexe impliquant plusieurs tables. Toutefois, lorsque vous avez plusieurs bases de données et que chaque base de données appartient à un microservice différent, vous ne pouvez pas interroger ces bases de données et créer une jointure SQL. Votre requête complexe devient un défi. Vous pouvez répondre à l’exigence à l’aide d’une approche CQRS : vous créez une table dénormalisée dans une autre base de données utilisée uniquement pour les requêtes. La table peut être conçue spécifiquement pour les données dont vous avez besoin pour la requête complexe, avec une relation un-à-un entre les champs nécessaires à l’écran de votre application et les colonnes de la table de requête. Elle peut également servir pour les rapports.
Cette approche résout non seulement le problème d’origine (comment interroger et joindre des microservices), mais elle améliore également considérablement les performances par rapport à une jointure complexe, car vous avez déjà les données dont l’application a besoin dans la table de requête. Bien sûr, l’utilisation de CQRS (séparation des responsabilités en matière de commande et de requête) avec des tables de requêtes/lectures signifie davantage de travail de développement et l’application d’une cohérence à terme. Néanmoins, les exigences en matière de performances et d’extensibilité élevée dans les scénarios collaboratifs (ou les scénarios concurrentiels, selon le point de vue) sont celles où vous devez appliquer CQRS avec plusieurs bases de données.
« Données à froid » dans les bases de données centrales. Pour les rapports et requêtes complexes qui peuvent ne pas nécessiter de données en temps réel, une approche courante consiste à exporter vos « données chaudes » (données transactionnelles des microservices) en tant que « données froides » dans des bases de données volumineuses qui sont utilisées uniquement pour la création de rapports. Ce système de base de données central peut être un système basé sur Big Data, comme Hadoop ; un entrepôt de données tel qu’un entrepôt basé sur Azure SQL Data Warehouse ; ou même une base de données SQL unique utilisée uniquement pour les rapports (si la taille n’est pas un problème).
N’oubliez pas que cette base de données centralisée serait utilisée uniquement pour les requêtes et les rapports qui n’ont pas besoin de données en temps réel. Les mises à jour et transactions d’origine, comme source de vérité, doivent être dans vos données de microservices. La façon dont vous synchronisez les données consisterait à utiliser la communication pilotée par les événements (décrite dans les sections suivantes) ou à l’aide d’autres outils d’importation/exportation de l’infrastructure de base de données. Si vous utilisez la communication pilotée par les événements, ce processus d’intégration est similaire à la façon dont vous propagez des données comme décrit précédemment pour les tables de requête CQRS.
Toutefois, si la conception de votre application implique l’agrégation constante d’informations provenant de plusieurs microservices pour les requêtes complexes, il peut s’agir d’un problème de conception -a microservice doit être aussi isolé que possible d’autres microservices. (Cela exclut les rapports/analyses qui doivent toujours utiliser des bases de données centrales à froid.) Le fait d’avoir ce problème peut souvent être une raison de fusionner des microservices. Vous devez équilibrer l’autonomie de l’évolution et du déploiement de chaque microservice avec des dépendances fortes, la cohésion et l’agrégation des données.
Défi n°3 : Comment assurer la cohérence entre plusieurs microservices
Comme indiqué précédemment, les données détenues par chaque microservice sont privées à ce microservice et sont accessibles uniquement à l’aide de son API de microservice. Par conséquent, un défi présenté est la façon d’implémenter des processus métier de bout en bout tout en conservant la cohérence entre plusieurs microservices.
Pour analyser ce problème, examinons un exemple tiré de l’application de référence eShopOnContainers. Le microservice Catalog conserve des informations sur tous les produits, y compris le prix du produit. Le microservice Basket gère les données temporelles sur les articles de produits que les utilisateurs ajoutent à leurs paniers d’achat, ce qui inclut le prix des articles au moment où ils ont été ajoutés au panier. Lorsque le prix d’un produit est mis à jour dans le catalogue, ce prix doit également être mis à jour dans les paniers actifs qui contiennent ce même produit, plus le système doit probablement avertir l’utilisateur indiquant que le prix d’un article particulier a changé depuis qu’il l’a ajouté à son panier.
Dans une version hypothétique monolithique de cette application, lorsque le prix change dans la table produits, le sous-système du catalogue peut simplement utiliser une transaction ACID pour mettre à jour le prix actuel dans la table Basket.
Toutefois, dans une application basée sur des microservices, les tables Product et Basket appartiennent à leurs microservices respectifs. Aucun microservice ne doit jamais inclure de tables/stockage appartenant à un autre microservice dans ses propres transactions, pas même dans les requêtes directes, comme indiqué sur la figure 4-9.
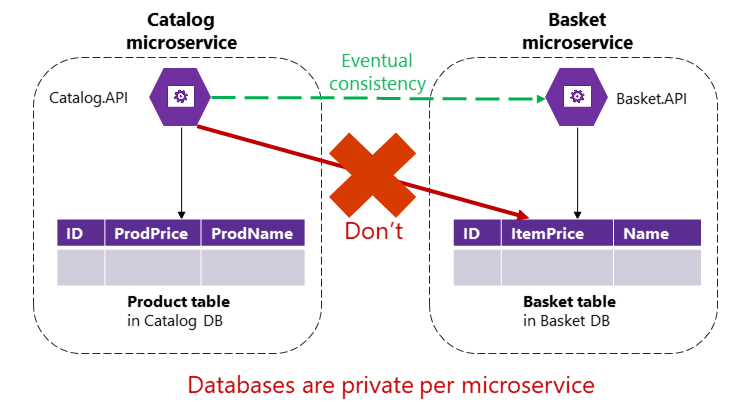
Figure 4-9. Un microservice ne peut pas accéder directement à une table dans un autre microservice
Le microservice Catalog ne doit pas mettre à jour la table Basket directement, car la table Basket appartient au microservice Basket. Pour mettre à jour le microservice Basket, le microservice Catalog doit probablement utiliser la cohérence éventuelle basée sur une communication asynchrone, telle que les événements d'intégration (messages et communication événementielle). C’est ainsi que l’application de référence eShopOnContainers effectue ce type de cohérence entre les microservices.
Comme le montre le théorème CAP, vous devez choisir entre la disponibilité et la cohérence forte d’ACID. La plupart des scénarios basés sur des microservices demandent la disponibilité et la haute scalabilité, par opposition à une cohérence forte. Les applications stratégiques doivent rester opérationnelles et les développeurs peuvent contourner une cohérence forte en utilisant des techniques pour travailler avec une cohérence faible ou éventuelle. Il s’agit de l’approche adoptée par la plupart des architectures basées sur des microservices.
De plus, les transactions de validation en deux phases ou de style ACID ne sont pas seulement contre les principes de microservices ; La plupart des bases de données NoSQL (comme Azure Cosmos DB, MongoDB, etc.) ne prennent pas en charge les transactions de validation en deux phases, généralement dans les scénarios de bases de données distribuées. Toutefois, il est essentiel de maintenir la cohérence des données entre les services et les bases de données. Ce défi est également lié à la façon de propager les modifications entre plusieurs microservices lorsque certaines données doivent être redondantes, par exemple lorsque vous devez avoir le nom ou la description du produit dans le microservice Catalog et le microservice Basket.
Une bonne solution pour ce problème consiste à utiliser la cohérence éventuelle entre les microservices articulés par le biais d’une communication pilotée par les événements et d’un système de publication et d’abonnement. Ces rubriques sont abordées dans la section Communication asynchrone pilotée par les événements plus loin dans ce guide.
Défi n°4 : Comment concevoir la communication entre les limites de microservice
La communication entre les limites des microservices est un véritable défi. Dans ce contexte, la communication ne fait pas référence au protocole que vous devez utiliser (HTTP et REST, AMQP, messagerie, etc.). Au lieu de cela, il traite du style de communication que vous devez utiliser, et surtout de la façon dont vos microservices doivent être couplés. Selon le niveau de couplage, lorsque l’échec se produit, l’impact de cette défaillance sur votre système varie considérablement.
Dans un système distribué comme une application basée sur des microservices, avec tant d’artefacts qui se déplacent et avec des services distribués sur de nombreux serveurs ou hôtes, les composants échoueront. Une défaillance partielle et même des pannes plus importantes se produisent. Vous devez donc concevoir vos microservices et la communication entre eux en tenant compte des risques courants dans ce type de système distribué.
Une approche populaire consiste à implémenter des microservices HTTP (REST), en raison de leur simplicité. Une approche basée sur HTTP est parfaitement acceptable ; le problème est lié à la façon dont vous l’utilisez. Si vous utilisez des requêtes et des réponses HTTP uniquement pour interagir avec vos microservices à partir d’applications clientes ou de passerelles d’API, c’est correct. Toutefois, si vous créez de longues chaînes d’appels HTTP synchrones entre les microservices, la communication entre leurs limites comme si les microservices étaient des objets dans une application monolithique, votre application rencontrera des problèmes.
Par exemple, imaginez que votre application cliente effectue un appel d’API HTTP à un microservice individuel comme le microservice Ordering. Si le microservice Ordering appelle à son tour des microservices supplémentaires à l’aide de HTTP dans le même cycle de requête/réponse, vous créez une chaîne d’appels HTTP. Il pourrait sembler raisonnable initialement. Toutefois, il existe des points importants à prendre en compte lors de la descente de ce chemin :
Blocage et faible performance. En raison de la nature synchrone de HTTP, la requête d’origine n’obtient pas de réponse tant que tous les appels HTTP internes ne sont pas terminés. Imaginez si le nombre de ces appels augmente considérablement et, en même temps, l’un des appels HTTP intermédiaires à un microservice est bloqué. Le résultat est que les performances sont affectées et que l’extensibilité globale sera affectée de manière exponentielle à mesure que les requêtes HTTP supplémentaires augmentent.
Couplage de microservices avec HTTP. Les microservices métier ne doivent pas être couplés à d’autres microservices métier. Dans l’idéal, ils ne doivent pas « savoir » l’existence d’autres microservices. Si votre application s’appuie sur le couplage de microservices comme dans l’exemple, l’obtention de l’autonomie par microservice sera presque impossible.
Échec dans un microservice. Si vous avez implémenté une chaîne de microservices liées par des appels HTTP, lorsque l’un des microservices échoue (et finalement, ils échouent), la chaîne entière de microservices échoue. Un système basé sur un microservice doit être conçu pour continuer à fonctionner aussi bien que possible pendant les défaillances partielles. Même si vous implémentez une logique cliente qui utilise des nouvelles tentatives avec des mécanismes d’interruption exponentielle ou de disjoncteur, plus les chaînes d’appels HTTP sont complexes, plus il est complexe d’implémenter une stratégie d’échec basée sur HTTP.
En fait, si vos microservices internes communiquent en créant des chaînes de requêtes HTTP comme décrit, il peut être soutenu que vous disposez d’une application monolithique, mais basée sur HTTP entre les processus au lieu de mécanismes de communication intraprocessus.
Par conséquent, afin d’appliquer l’autonomie des microservices et d’avoir une meilleure résilience, vous devez réduire l’utilisation de chaînes de communication de requête/réponse entre les microservices. Il est recommandé d’utiliser uniquement l’interaction asynchrone pour la communication interservices, soit en utilisant une communication asynchrone basée sur des messages et des événements, soit en utilisant l’interrogation HTTP (asynchrone) indépendamment du cycle de requête/réponse HTTP d’origine.
L’utilisation de la communication asynchrone est expliquée avec des détails supplémentaires plus loin dans ce guide dans les sections Intégration du microservice asynchrone applique l’autonomie du microservice et la communication asynchrone basée sur les messages.
Ressources supplémentaires
Théorème CAP
https://en.wikipedia.org/wiki/CAP_theoremCohérence éventuelle
https://en.wikipedia.org/wiki/Eventual_consistencyIntroduction à la cohérence des données
https://learn.microsoft.com/previous-versions/msp-n-p/dn589800(v=pandp.10)Martin Fowler. CQRS (Segregation des responsabilités de commande et de requête)
https://martinfowler.com/bliki/CQRS.htmlVue matérialisée
https://learn.microsoft.com/azure/architecture/patterns/materialized-viewCharles Row. ACID et BASE : Le pH de décalage du traitement des transactions de base de données
https://www.dataversity.net/acid-vs-base-the-shifting-ph-of-database-transaction-processing/Transaction de compensation
https://learn.microsoft.com/azure/architecture/patterns/compensating-transactionUdi Dahan. Composition orientée service
https://udidahan.com/2014/07/30/service-oriented-composition-with-video/
Collaborer avec nous sur GitHub
La source de ce contenu se trouve sur GitHub, où vous pouvez également créer et examiner les problèmes et les demandes de tirage. Pour plus d’informations, consultez notre guide du contributeur.