Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Conseil
Ce contenu est un extrait du livre électronique « .NET Microservices Architecture for Containerized .NET Applications », disponible sur .NET Docs ou sous forme de PDF téléchargeable gratuitement et pouvant être lu hors ligne.

Dans la plupart des cas, vous pouvez considérer qu’un conteneur est une instance d’un processus. Un processus ne conserve pas un état persistant. Si un conteneur peut écrire dans son stockage local, supposer qu’une instance sera présente indéfiniment revient à supposer qu’un seul emplacement en mémoire pourra perdurer. Vous devez partir de l’hypothèse que les images conteneur, par exemple les processus, ont plusieurs instances ou qu’elles vont finir par être tuées. Si elles sont managées à l’aide d’un orchestrateur de conteneurs, vous devez supposer qu’elles peuvent être déplacés d’un nœud (ou d’une machine virtuelle) vers un autre.
Les solutions suivantes sont utilisées pour gérer les données dans les applications Docker :
À partir de l’hôte Docker, sous forme de volumes Docker :
Les volumes sont stockés dans une zone du système de fichiers hôte managée par Docker.
Les montages de liaison peuvent être mappés à n’importe quel dossier du système de fichiers hôte. L’accès ne peut donc pas être contrôlé à partir du processus Docker, ce qui peut poser un risque pour la sécurité, car un conteneur peut accéder aux dossiers sensibles du système d’exploitation.
Les montages tmpfs sont semblables à des dossiers virtuels qui existent uniquement dans la mémoire de l’hôte et qui ne sont jamais écrits dans le système de fichiers.
À partir du stockage distant :
Le service Stockage Azure, qui fournit un stockage géographiquement distribuable, offrant une bonne solution de persistance à long terme pour les conteneurs.
Des bases de données relationnelles distantes, comme Azure SQL Database, ou des bases de données NoSQL, comme Azure Cosmos DB, ou des services de cache, comme Redis.
À partir du conteneur Docker :
- Système de fichiers en superposition. Cette fonctionnalité Docker implémente une tâche de copie sur écriture qui stocke les informations mises à jour dans le système de fichiers racine du conteneur. Ces informations « reposent » sur l’image d’origine sur laquelle le conteneur est basé. Si le conteneur est supprimé du système, ces modifications sont perdues. Ainsi, bien qu’il soit possible d’enregistrer l’état d’un conteneur dans son stockage local, la conception d’un système selon cette solution est en conflit avec le principe de conception des conteneurs, lesquels sont par défaut sans état.
Toutefois, l’utilisation de volumes Docker constitue désormais la meilleure façon de gérer des données locales dans Docker. Pour plus d’informations sur le stockage dans les conteneurs, consultez Pilotes de stockage Docker et À propos des pilotes de stockage.
Ces options sont détaillées ci-dessous :
Les volumes sont des répertoires mappés du système d’exploitation hôte à des répertoires situés dans les conteneurs. Quand le code du conteneur a accès au répertoire, cet accès se fait en réalité à un répertoire sur le système d’exploitation hôte. Ce répertoire n’est pas lié à la durée de vie du conteneur, il est managé par Docker et isolé de la fonctionnalité principale de la machine hôte. Ainsi, les volumes de données sont conçus pour rendre des données persistantes indépendamment de la durée de vie du conteneur. Si vous supprimez un conteneur ou une image de l’hôte Docker, les données rendues persistantes dans le volume de données ne sont pas supprimées.
Les volumes peuvent être nommés ou anonymes (par défaut). Les volumes nommés correspondent à l’évolution des conteneurs de volumes de données. Ils facilitent le partage de données entre les conteneurs. Les volumes prennent également en charge les pilotes de volume, qui permettent entre autres de stocker des données sur des hôtes distants.
Les montages de liaison existent depuis longtemps. Ils permettent de mapper des dossiers à un point de montage d’un conteneur. Les montages de liaison ont plus de limitations que les volumes et présentent certains problèmes de sécurité importants. Les volumes sont donc l’option recommandée.
Les montages tmpfs sont essentiellement des dossiers virtuels qui résident uniquement dans la mémoire de l’hôte et qui ne sont jamais écrits dans le système de fichiers. Ils sont rapides et sécurisés, mais ils consomment de la mémoire et sont conçus uniquement pour des données temporaires non persistantes.
Comme le montre la figure 4-5, les volumes Docker standard peuvent être stockés en dehors des conteneurs eux-mêmes, mais dans les limites physiques du serveur ou de la machine virtuelle hôte. Toutefois, les conteneurs Docker ne peuvent pas accéder à un volume d’un serveur hôte ou d’une machine virtuelle depuis un autre serveur hôte ou une autre machine virtuelle. En d’autres termes, avec ces volumes, il n’est pas possible de gérer les données partagées entre des conteneurs qui s’exécutent sur des hôtes Docker distincts. Toutefois, cela est possible avec un pilote de volume qui prend en charge les hôtes distants.
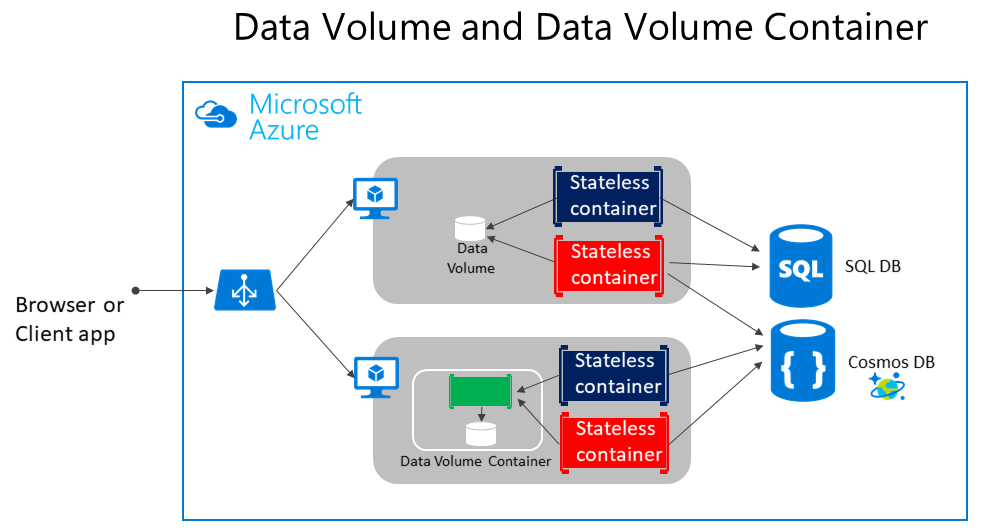
Figure 4-5. Volumes et sources de données externes pour applications conteneurisées
Les volumes peuvent être partagés entre les conteneurs, mais uniquement sur le même hôte, sauf si vous utilisez un pilote distant qui prend en charge les hôtes distants. De plus, quand des conteneurs Docker sont managés par un orchestrateur, ils peuvent être « déplacés » entre les hôtes, en fonction des optimisations effectuées par le cluster. Il n’est donc pas recommandé d’utiliser des volumes de données pour les données métier. Toutefois, ils constituent un bon mécanisme pour travailler avec des fichiers de trace, des fichiers temporels ou des fichiers similaires qui n’ont pas d’impact sur la cohérence des données métier.
Des sources de données distantes et des outils de mise en cache, comme Azure SQL Database, Azure Cosmos DB ou un cache à distance comme Redis, peuvent être utilisés dans des applications en conteneur de la même façon qu’ils sont utilisés dans des développements sans conteneurs. Il s’agit d’un moyen éprouvé pour stocker des données d’application métier.
Stockage Azure. Les données métier doivent généralement être placées dans des ressources ou des bases de données externes, comme le service Stockage Azure. Concrètement, Stockage Azure fournit les services suivants dans le cloud :
Le stockage Blob stocke les données d’objets non structurées. Un objet blob peut être n’importe quel type de données texte ou binaires, comme des fichiers de document ou multimédias (fichiers image, audio et vidéo). Blob Storage est parfois appelé stockage d’objets.
Stockage Fichier offre un stockage partagé pour les applications héritées avec le protocole SMB standard. Les machines virtuelles et les services cloud Azure peuvent partager des données de fichiers entre des composants d’application via des partages montés. Les applications locales peuvent accéder aux données des fichiers d’un partage via l’API REST du service Fichier.
Le stockage de tables stocke les jeux de données structurés. Stockage Table est un magasin de données clé-attribut NoSQL, qui permet le développement rapide et un accès rapide à de grandes quantités de données.
Bases de données relationnelles et bases de données NoSQL. Les bases de données externes qu’il est possible de choisir sont nombreuses : bases de données relationnelles comme SQL Server, PostgreSQL, Oracle ou bases de données NoSQL comme Azure Cosmos DB, MongoDB, etc. Ces bases de données ne seront pas expliquées dans le cadre de ce guide, car elles s’inscrivent dans un tout autre sujet.
Collaborer avec nous sur GitHub
La source de ce contenu se trouve sur GitHub, où vous pouvez également créer et examiner les problèmes et les demandes de tirage. Pour plus d’informations, consultez notre guide du contributeur.