Note
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier les répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de changer de répertoire.
Conseil / Astuce
Ce contenu est un extrait du livre électronique 'Architecture des microservices .NET pour les applications .NET conteneurisées', disponible sur .NET Docs ou en tant que PDF téléchargeable gratuitement, lisible hors ligne.

Comme indiqué précédemment, vous devez gérer les erreurs qui peuvent prendre un certain temps de récupération, comme cela peut se produire lorsque vous essayez de vous connecter à un service ou une ressource distant. La gestion de ce type d’erreur peut améliorer la stabilité et la résilience d’une application.
Dans un environnement distribué, les appels aux ressources et services distants peuvent échouer en raison d’erreurs temporaires, telles que les connexions réseau lentes et les délais d’expiration, ou si les ressources répondent lentement ou sont temporairement indisponibles. Ces erreurs se corrigent généralement après un court laps de temps, et une application cloud robuste doit être prête à les gérer à l’aide d’une stratégie telle que le « modèle nouvelle tentative ».
Toutefois, il peut également arriver que des erreurs soient dues à des événements imprévus qui peuvent prendre beaucoup plus de temps pour corriger. Ces erreurs peuvent aller d’une perte partielle de connectivité à la défaillance complète d’un service. Dans ces situations, il peut être inutile qu’une application recommence continuellement une opération peu susceptible de réussir.
Au lieu de cela, l’application doit être codée pour accepter que l’opération a échoué et gérer l’échec en conséquence.
Une utilisation imprudente des réessais HTTP peut entraîner une attaque par déni de service (DoS) au sein de votre propre logiciel. En cas d’échec ou d’exécution lente d’un microservice, plusieurs clients peuvent réessayer à plusieurs reprises les demandes ayant échoué. Cela crée un risque dangereux d’augmenter exponentiellement le trafic ciblé sur le service défaillant.
Par conséquent, vous avez besoin d’une sorte de barrière de défense afin que les demandes excessives s’arrêtent quand il n’est pas utile de continuer à essayer. Cette barrière de défense est précisément le disjoncteur.
L’objectif du modèle Disjoncteur est différent de celui du « modèle Nouvelle tentative ». Le « modèle nouvelle tentative » permet à une application de réessayer une opération dans l’attente que l’opération aboutisse. Le modèle de Circuit Breaker empêche une application d’effectuer une opération qui est susceptible d’échouer. Une application peut combiner ces deux modèles. Toutefois, la logique de nouvelle tentative doit être sensible à toute exception retournée par le disjoncteur, et elle doit abandonner les tentatives de nouvelle tentative si le disjoncteur indique qu’une erreur n’est pas temporaire.
Implémenter le modèle de disjoncteur avec IHttpClientFactory et Polly
Comme lors de l'implémentation de mécanismes de réessai, l'approche recommandée pour les disjoncteurs consiste à utiliser les bibliothèques .NET éprouvées telles que Polly et son intégration native avec IHttpClientFactory.
L’ajout d’une stratégie de disjoncteur dans votre pipeline d’intergiciel sortant IHttpClientFactory est aussi simple que l’ajout d’un fragment de code incrémentiel individuel à ce que vous avez déjà lorsque vous utilisez IHttpClientFactory.
Le seul ajout ici au code utilisé pour les nouvelles tentatives d’appel HTTP est le code dans lequel vous ajoutez la stratégie Disjoncteur à la liste des stratégies à utiliser, comme indiqué dans le code incrémentiel suivant.
// Program.cs
var retryPolicy = GetRetryPolicy();
var circuitBreakerPolicy = GetCircuitBreakerPolicy();
builder.Services.AddHttpClient<IBasketService, BasketService>()
.SetHandlerLifetime(TimeSpan.FromMinutes(5)) // Sample: default lifetime is 2 minutes
.AddHttpMessageHandler<HttpClientAuthorizationDelegatingHandler>()
.AddPolicyHandler(retryPolicy)
.AddPolicyHandler(circuitBreakerPolicy);
La AddPolicyHandler() méthode est ce qui ajoute des stratégies aux HttpClient objets que vous utiliserez. Dans ce cas, elle ajoute une stratégie Polly pour un disjoncteur.
Pour avoir une approche plus modulaire, la politique de circuit disjoncteur est définie dans une méthode distincte appelée GetCircuitBreakerPolicy(), comme le montre le code suivant :
// also in Program.cs
static IAsyncPolicy<HttpResponseMessage> GetCircuitBreakerPolicy()
{
return HttpPolicyExtensions
.HandleTransientHttpError()
.CircuitBreakerAsync(5, TimeSpan.FromSeconds(30));
}
Dans l’exemple de code ci-dessus, la politique de disjoncteur est configurée de sorte qu’elle interrompt ou ouvre le circuit lorsqu’il y a eu cinq erreurs consécutives lors du réessai des requêtes HTTP. Quand cela se produit, le circuit est rompu pendant 30 secondes : durant ce laps de temps, le disjoncteur met immédiatement les appels en échec au lieu de les transmettre. La stratégie interprète automatiquement les exceptions pertinentes et les codes d’état HTTP comme des erreurs.
Les disjoncteurs doivent également être utilisés pour rediriger les demandes vers une infrastructure de secours si vous avez rencontré des problèmes dans une ressource particulière déployée dans un environnement différent de l’application cliente ou du service qui effectue l’appel HTTP. De cette façon, s’il existe une panne dans le centre de données qui affecte uniquement vos microservices principaux, mais pas vos applications clientes, les applications clientes peuvent rediriger vers les services de secours. Polly planifie une nouvelle stratégie pour automatiser ce scénario de stratégie de basculement.
Toutes ces fonctionnalités s'appliquent aux situations où vous gérez le basculement depuis le code .NET, plutôt que de le laisser gérer automatiquement par Azure, avec une transparence de localisation.
D’un point de vue d’utilisation, lorsque vous utilisez HttpClient, il n’est pas nécessaire d’ajouter quelque chose de nouveau ici, car le code est le même que lors de l’utilisation HttpClient avec IHttpClientFactory, comme indiqué dans les sections précédentes.
Tester les réessais HTTP et les coupe-circuits dans eShopOnContainers
Chaque fois que vous démarrez la solution eShopOnContainers dans un hôte Docker, il doit démarrer plusieurs conteneurs. Certains conteneurs sont plus lents à démarrer et à initialiser, comme le conteneur SQL Server. Cela est particulièrement vrai la première fois que vous déployez l’application eShopOnContainers dans Docker, car elle doit configurer les images et la base de données. Le fait que certains conteneurs démarrent plus lentement que d'autres peut provoquer des exceptions HTTP initialement, même si vous définissez des dépendances entre les conteneurs au niveau de docker-compose, comme expliqué dans les sections précédentes. Ces dépendances Docker Compose entre les conteneurs sont uniquement au niveau processus. Le processus de point d’entrée du conteneur peut être démarré, mais SQL Server peut ne pas être prêt pour les requêtes. Le résultat peut être une cascade d’erreurs et l’application peut obtenir une exception lorsqu’elle tente de consommer ce conteneur particulier.
Vous pouvez également voir ce type d’erreur au démarrage lorsque l’application est déployée sur le cloud. Dans ce cas, les orchestrateurs peuvent déplacer des conteneurs d’un nœud ou d’une machine virtuelle vers une autre (autrement dit, démarrer de nouvelles instances) lors de l’équilibrage du nombre de conteneurs sur les nœuds du cluster.
La façon dont « eShopOnContainers » résout ces problèmes lors du démarrage de tous les conteneurs consiste à utiliser le modèle Nouvelle tentative illustré précédemment.
Tester le disjoncteur dans eShopOnContainers
Il existe plusieurs façons de briser/ouvrir le circuit et de le tester avec eShopOnContainers.
Une option consiste à réduire le nombre autorisé de nouvelles tentatives à 1 dans la stratégie de disjoncteur et à redéployer toute la solution dans Docker. Avec une nouvelle tentative unique, il est possible qu’une requête HTTP échoue pendant le déploiement, que le disjoncteur s’ouvre et que vous obtenez une erreur.
Une autre option consiste à utiliser un intergiciel personnalisé implémenté dans le microservice Basket . Lorsque ce middleware est activé, il intercepte toutes les requêtes HTTP et retourne le code d’état 500. Vous pouvez activer l’intergiciel en effectuant une requête GET à l’URI défaillant, comme suit :
GET http://localhost:5103/failing
Cette requête retourne l’état actuel du middleware. Si l’intergiciel est activé, la requête renvoie le code d’état 500. Si l’intergiciel est désactivé, il n’y a aucune réponse.GET http://localhost:5103/failing?enable
Cette requête active l’intergiciel.GET http://localhost:5103/failing?disable
Cette requête désactive l’intergiciel.
Par exemple, une fois l’application en cours d’exécution, vous pouvez activer l’intergiciel en effectuant une requête à l’aide de l’URI suivant dans n’importe quel navigateur. Notez que le microservice de commande utilise le port 5103.
http://localhost:5103/failing?enable
Vous pouvez ensuite vérifier l’état à l’aide de l’URI http://localhost:5103/failing, comme illustré dans la figure 8-5.
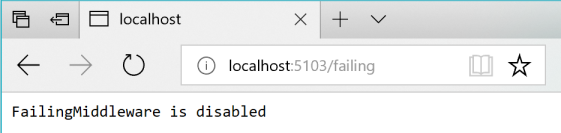
Figure 8-5. Vérification de l’état du middleware ASP.NET en état de "défaillance" : dans ce cas, désactivé.
À ce stade, le microservice Basket répond avec le code d’état 500 chaque fois que vous l’appelez.
Une fois l’intergiciel en cours d’exécution, vous pouvez essayer d’effectuer une commande à partir de l’application web MVC. Étant donné que les demandes échouent, le circuit s’ouvre.
Dans l’exemple suivant, vous pouvez voir que l’application web MVC a un bloc catch dans la logique du processus consistant à passer une commande. Si le code intercepte une exception de circuit ouvert, il affiche un message convivial qui indique à l'utilisateur d'attendre.
public class CartController : Controller
{
//…
public async Task<IActionResult> Index()
{
try
{
var user = _appUserParser.Parse(HttpContext.User);
//Http requests using the Typed Client (Service Agent)
var vm = await _basketSvc.GetBasket(user);
return View(vm);
}
catch (BrokenCircuitException)
{
// Catches error when Basket.api is in circuit-opened mode
HandleBrokenCircuitException();
}
return View();
}
private void HandleBrokenCircuitException()
{
TempData["BasketInoperativeMsg"] = "Basket Service is inoperative, please try later on. (Business message due to Circuit-Breaker)";
}
}
Voici un résumé. La stratégie de nouvelle tentative tente plusieurs fois d’effectuer la requête HTTP et obtient des erreurs HTTP. Quand le nombre maximal de nouvelles tentatives pour la stratégie Disjoncteur est atteint (dans le cas présent, 5), l’application lève une exception BrokenCircuitException. Le résultat est un message convivial, comme illustré dans la figure 8-6.
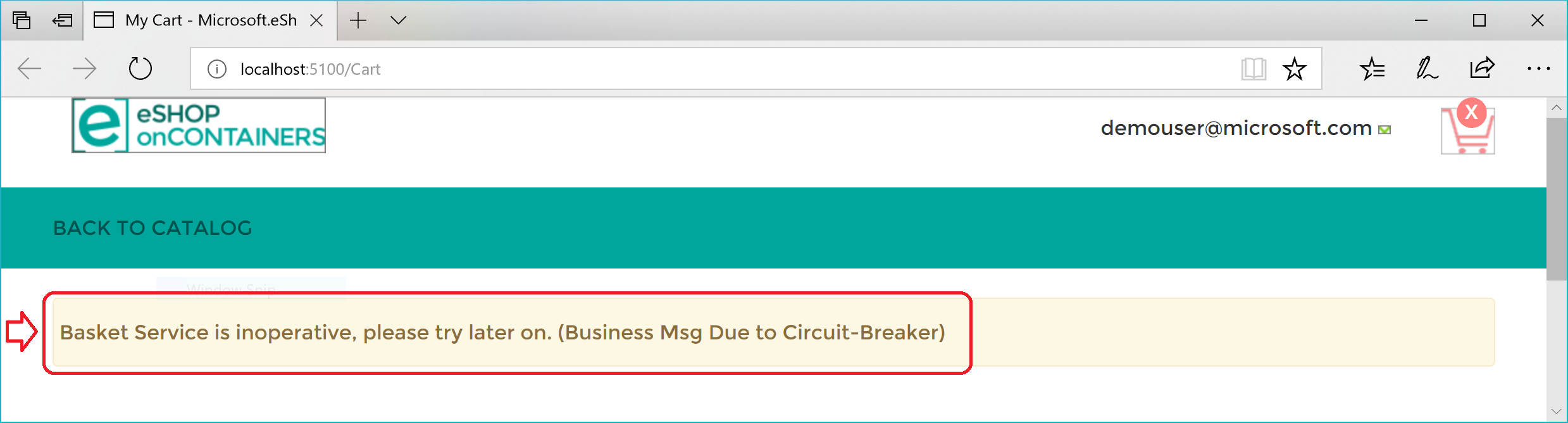
Figure 8-6. Disjoncteur envoyant une erreur à l’interface utilisateur
Vous pouvez implémenter une logique différente pour quand ouvrir/interrompre le circuit. Vous pouvez également essayer une requête HTTP sur un autre microservice back-end s’il existe un centre de données de secours ou un système back-end redondant.
Enfin, une autre possibilité pour le CircuitBreakerPolicy est d’utiliser Isolate (qui force l’ouverture et maintient ouvert le circuit) et Reset (qui le ferme à nouveau). Ces solutions peuvent être utilisées pour créer un point de terminaison HTTP d’utilitaire qui appelle Isolate et Reset directement sur la stratégie. Un tel point de terminaison HTTP peut également être utilisé, correctement sécurisé, en production pour isoler temporairement un système en aval, par exemple lorsque vous souhaitez le mettre à niveau. Ou bien il peut déclencher le circuit manuellement pour protéger un système en aval que vous soupçonnez d’avoir provoqué l’erreur.
Ressources supplémentaires
-
Modèle Disjoncteur
https://learn.microsoft.com/azure/architecture/patterns/circuit-breaker
Collaborez avec nous sur GitHub
La source de ce contenu se trouve sur GitHub, où vous pouvez également créer et examiner des problèmes et des demandes de tirage. Pour plus d’informations, consultez notre guide du contributeur.