Concevoir la couche de persistance de l’infrastructure
Conseil
Ce contenu est un extrait du livre électronique « .NET Microservices Architecture for Containerized .NET Applications », disponible sur .NET Docs ou sous forme de PDF téléchargeable gratuitement et pouvant être lu hors ligne.

Les composants de persistance des données fournissent l’accès aux données hébergées dans les limites d’un microservice (autrement dit, la base de données d’un microservice). Ils contiennent l’implémentation réelle des composants tels que les dépôts et les classes d’unité de travail, comme les objets DbContext Entity Framework (EF) personnalisés. EF DbContext implémente les modèles Référentiel et Unité de travail.
Le modèle Dépôt
Le modèle Référentiel est un modèle de conception basée sur le domaine destiné à maintenir les problèmes de persistance en dehors du modèle de domaine du système. Une ou plusieurs abstractions de persistance (interfaces) sont définies dans le modèle de domaine, et ces abstractions ont des implémentations sous la forme d’adaptateurs propres à la persistance définis ailleurs dans l’application.
Les implémentations de référentiels sont des classes qui encapsulent la logique nécessaire pour accéder aux sources de données. Elles centralisent les fonctionnalités d’accès aux données communes, en fournissant une meilleure maintenabilité et en découplant l’infrastructure ou la technologie utilisée pour accéder aux bases de données à partir du modèle de domaine. Si vous utilisez un mappeur objet-relationnel (ORM, Object-Relational Mapper) comme Entity Framework, le code à implémenter est simplifié grâce à LINQ et à un typage fort. Ainsi, vous pouvez vous concentrer sur la logique de persistance des données plutôt que sur le raccordement de l’accès aux données.
Le modèle Dépôt est une façon bien décrite d’utiliser une source de données. Dans l’ouvrage Patterns of Enterprise Application Architecture, Martin Fowler décrit un dépôt comme suit :
Un dépôt effectue les tâches d’un intermédiaire entre les couches du modèle de domaine et le mappage de données, en agissant d’une manière similaire à un ensemble d’objets de domaine dans la mémoire. Les objets clients génèrent des requêtes de façon déclarative et les envoient aux dépôts pour obtenir des réponses. D’un point de vue conceptuel, un dépôt encapsule un ensemble d’objets stockés dans la base de données et les opérations pouvant être effectuées sur ces derniers, en fournissant un moyen plus proche de la couche de persistance. Les dépôts, par ailleurs, prennent en charge l’objectif de séparation, claire et dans un seul sens, de la dépendance entre le domaine de travail et l’allocation ou le mappage de données.
Définir un seul dépôt par agrégat
Pour chaque agrégat ou racine d’agrégat, vous devez créer une seule classe de dépôt. Vous pourrez peut-être tirer parti des génériques C# pour réduire le nombre total de classes concrètes que vous devez tenir à jour (comme illustré plus loin dans ce chapitre). Dans un microservice basé sur des modèles de conception pilotée par le domaine (DDD, Domain-Driven Design), le seul canal que vous devez utiliser pour mettre à jour la base de données doit être les référentiels. En effet, ils ont une relation un-à-un avec la racine d’agrégat, qui contrôle les invariants et la cohérence transactionnelle de l’agrégat. Il est possible d’interroger la base de données par le biais d’autres canaux (selon une approche CQRS par exemple), car les requêtes ne changent pas l’état de la base de données. Toutefois, la zone transactionnelle (à savoir les mises à jour) doit toujours être contrôlée par les dépôts et les racines d’agrégat.
En bref, un dépôt vous permet de renseigner les données en mémoire provenant de la base de données sous la forme d’entités de domaine. Une fois que les entités sont en mémoire, elles peuvent être modifiées et de nouveau rendues persistantes dans la base de données par le biais de transactions.
Comme indiqué précédemment, si vous utilisez le modèle architectural CQS/CQRS, les requêtes initiales sont effectuées par des requêtes latérales en dehors du modèle de domaine, effectuées par de simples instructions SQL à l’aide de Dapper. Cette approche est beaucoup plus souple que les dépôts, car vous pouvez interroger et joindre les tables dont vous avez besoin, et ces requêtes ne sont pas limitées par des règles issues des agrégats. Ces données accèdent à la couche présentation ou à l’application cliente.
Si l’utilisateur apporte des modifications, les données à mettre à jour passent de l’application cliente ou de la couche présentation à la couche Application (comme un service API web). Quand vous recevez une commande dans un gestionnaire de commandes, vous utilisez des référentiels pour obtenir de la base de données les données à mettre à jour. Vous les mettez à jour en mémoire avec les informations passées avec les commandes, puis vous ajoutez ou vous mettez à jour les données (entités de domaine) dans la base de données via une transaction.
Il est important de souligner à nouveau que vous devez définir seulement un référentiel pour chaque racine d’agrégat, comme illustré dans la figure 7-17. Pour atteindre l’objectif de la racine d’agrégat visant à maintenir la cohérence transactionnelle entre tous les objets au sein de l’agrégat, vous ne devez jamais créer un dépôt pour chaque table dans la base de données.
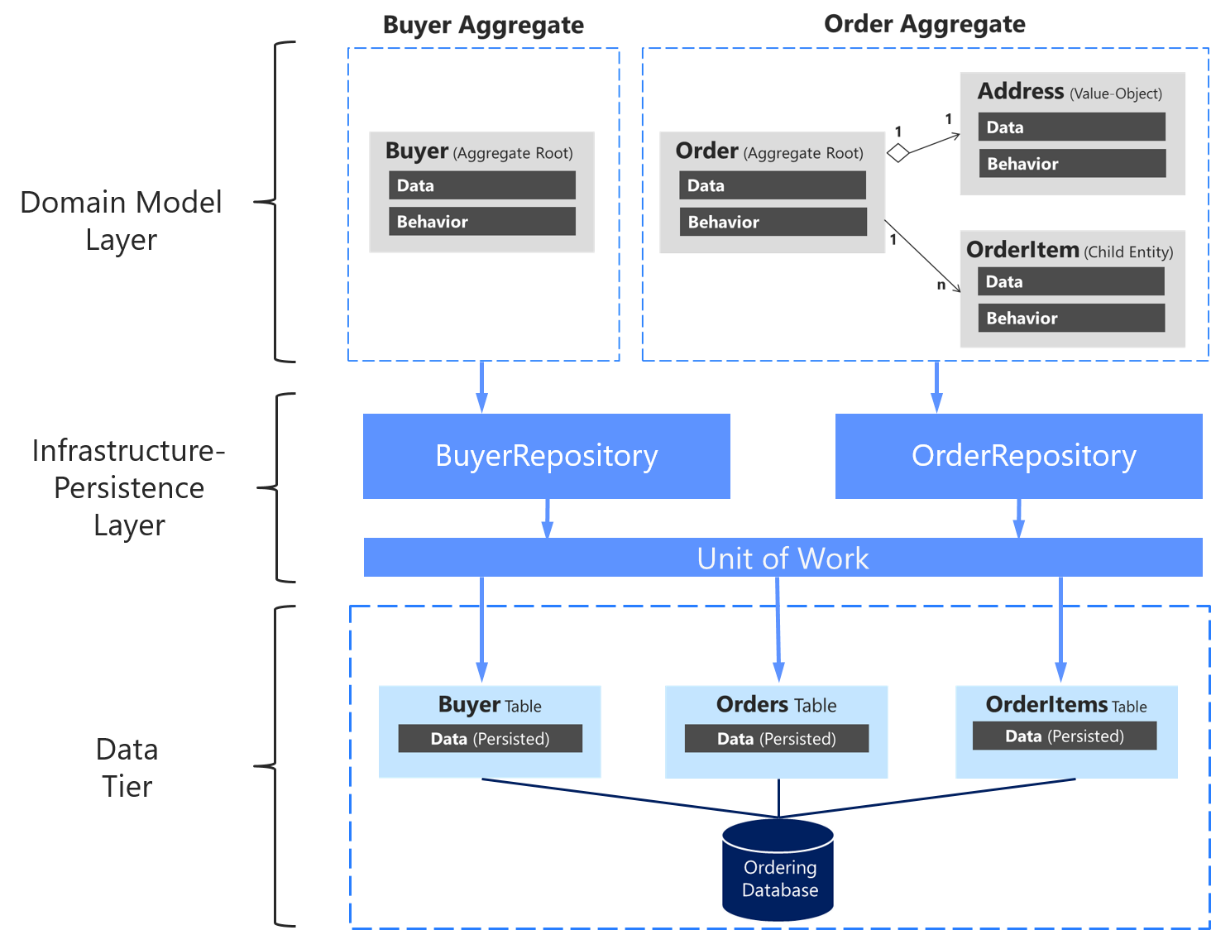
Figure 7-17. Relation entre les dépôts, les agrégats et les tables de base de données
Le diagramme ci-dessus montre les relations entre les couches Infrastructure et Domaine : l’agrégat Buyer dépend de IBuyerRepository et l’agrégat Order dépend des interfaces IOrderRepository ; ces interfaces sont implémentées dans la couche Infrastructure par les référentiels correspondants qui dépendent de UnitOfWork également implémentée ici, qui accède aux tables dans la couche Données.
Appliquer une seule racine d’agrégat par référentiel
Il peut s’avérer très utile d’implémenter votre conception de dépôt de sorte à faire respecter la règle stipulant que seules les racines d’agrégat doivent avoir des dépôts. Vous pouvez créer un type de dépôt générique ou élémentaire qui limite le type des entités utilisées pour veiller à ce qu’elles aient l’interface de marqueur IAggregateRoot.
Ainsi, chaque classe de dépôt implémentée au niveau de la couche d’infrastructure implémente son propre contrat ou sa propre interface, comme le montre le code suivant :
namespace Microsoft.eShopOnContainers.Services.Ordering.Infrastructure.Repositories
{
public class OrderRepository : IOrderRepository
{
// ...
}
}
Chaque interface de dépôt spécifique implémente l’interface IRepository générique :
public interface IOrderRepository : IRepository<Order>
{
Order Add(Order order);
// ...
}
Toutefois, un meilleur moyen d’obliger le code à appliquer la convention selon laquelle chaque dépôt doit être lié à un seul agrégat consiste à implémenter un type de dépôt générique. De cette façon, il est explicite que vous utilisez un dépôt pour cibler un agrégat spécifique. Vous pouvez le faire facilement en implémentant une interface de base IRepository générique, comme dans le code suivant :
public interface IRepository<T> where T : IAggregateRoot
{
//....
}
Le modèle Dépôt facilite le test de votre logique d’application
Le modèle Dépôt vous permet de tester facilement votre application avec des tests unitaires. N’oubliez pas que les tests unitaires testent uniquement votre code, pas l’infrastructure, si bien que les abstractions de dépôt facilitent la réalisation de cet objectif.
Comme indiqué dans une section précédente, il est recommandé de définir et placer les interfaces de dépôt dans la couche du modèle de domaine pour que la couche Application telle que votre microservice d’API web, ne dépende pas directement de la couche d’infrastructure, dans laquelle vous avez implémenté les classes de dépôt réelles. Ce faisant et à l’aide de l’injection de dépendances dans les contrôleurs de votre API web, vous pouvez implémenter des dépôts fictifs qui retournent de fausses données au lieu des données de la base de données. Cette approche découplée vous permet de créer et d’exécuter des tests unitaires centrés sur la logique de votre application sans nécessiter de connectivité à la base de données.
Les connexions aux bases de données peuvent échouer et, ce qui est plus important, l’exécution de centaines de tests sur une base de données est mauvaise pour deux raisons. Tout d’abord, elle peut s’avérer très chronophage en raison du grand nombre de tests. Ensuite, les enregistrements de base de données peuvent changer et affecter les résultats de vos tests, en particulier s’ils s’exécutent en parallèle, et ils risquent ainsi de ne pas être cohérents. Les tests unitaires peuvent généralement s’exécuter en parallèle ; les tests d’intégration peuvent ne pas prendre en charge l’exécution parallèle, en fonction de leur implémentation. Un test sur la base de données n’est pas un test unitaire, mais un test d’intégration. Vous devez effectuer de nombreux tests unitaires qui s’exécutent rapidement, mais un nombre moindre de tests d’intégration sur les bases de données.
En termes de séparation des responsabilités pour les tests unitaires, votre logique s’exécute sur des entités de domaine dans la mémoire. Elle suppose que la classe de dépôt les a remises. Une fois que votre logique modifie les entités de domaine, elle suppose que la classe de dépôt les stocke correctement. Il est important de créer des tests unitaires sur votre modèle de domaine et sa logique de domaine. Les racines d’agrégat correspondent aux limites de cohérence principales dans la conception DDD.
Les référentiels implémentés dans eShopOnContainers s’appuient sur l’implémentation de DbContext d’EF Core des modèles de référentiel et d’unité de travail en utilisant son suivi des modifications, afin qu’ils ne dupliquent pas cette fonctionnalité.
La différence entre le modèle Dépôt et le modèle de la classe d’accès aux données héritée (classe DAL)
Un objet DAL classique effectue directement des opérations d’accès aux données et de persistance sur le stockage, souvent au niveau d’une seule table et d’une seule ligne. Les opérations CRUD simples implémentées avec un ensemble de classes DAL ne prennent souvent pas en charge les transactions (mais il arrive toutefois qu’elles les prennent en charge). La plupart des approches de classe DAL utilisent très peu les abstractions, ce qui entraîne un couplage étroit entre les classes de couche logique métier (BLL, Business Logic Layer) ou d’application qui appellent les objets DAL.
Lors de l’utilisation du référentiel, les détails d’implémentation de la persistance sont encapsulés en dehors du modèle de domaine. L’utilisation d’une abstraction permet d’étendre facilement le comportement par le biais de modèles tels que les décorateurs ou les proxys. Par exemple, les problèmes transversaux tels que la mise en cache, la journalisation et la gestion des erreurs peuvent tous être appliqués à l’aide de ces modèles plutôt que codés en dur dans le code d’accès aux données lui-même. Il est également trivial de prendre en charge plusieurs adaptateurs de référentiel qui peuvent être utilisés dans différents environnements, du développement local aux environnements intermédiaires partagés, en passant par la production.
Implémentation de l’unité de travail
Une unité de travail fait référence à une transaction unique qui implique plusieurs opérations d’insertion, de mise à jour ou de suppression. En termes simples, cela signifie que, pour une action utilisateur spécifique, comme une inscription sur un site web, toutes les opérations d’insertion, de mise à jour et de suppression sont gérées dans une même transaction. Ceci est plus efficace que de gérer plusieurs opérations de base de données d’une manière plus bavarde.
Ces multiples opérations de persistance sont effectuées ultérieurement en une seule action quand votre code de la couche Application la commande. La décision d’appliquer les modifications en mémoire au stockage réel de la base de données se base généralement sur le modèle Unité de travail. Dans EF, le modèle Unité de travail est implémenté par un DbContext et est exécuté lorsqu’un appel est effectué à SaveChanges.
Dans de nombreux cas, ce modèle ou cette façon d’appliquer des opérations dans le stockage peut augmenter les performances de l’application et réduire le risque d’incohérences. Cela réduit également le blocage des transactions dans les tables de base de données, car toutes les opérations prévues sont validées dans le cadre d’une seule transaction. Ce modèle est plus efficace que l’exécution de nombreuses opérations isolées sur la base de données. Par conséquent, le mappage relationnel objet (ORM) sélectionné peut optimiser l’exécution sur la base de données en regroupant plusieurs actions de mise à jour au sein de la même transaction, au lieu d’exécuter de nombreuses transactions distinctes de petite taille.
Le modèle Unité de travail peut être implémenté avec ou sans le modèle Référentiel.
Les dépôts ne doivent pas être obligatoires
Les dépôts personnalisés sont utiles pour les raisons citées précédemment. C’est l’approche utilisée pour le microservice de passation de commandes dans eShopOnContainers. Toutefois, il ne s’agit pas d’un modèle essentiel à implémenter dans une conception DDD ni même dans le cadre d’un développement .NET général.
Par exemple, Jimmy Bogard, en commentant directement le présent guide, a tenu les propos suivants :
Ces commentaires seront probablement mes plus longs. Je ne suis vraiment pas fan des référentiels, principalement parce qu’ils cachent les détails importants du mécanisme de persistance sous-jacent. C’est pour cela que je préfère MediatR pour les commandes, aussi. Je peux utiliser toute la puissance de la couche de persistance et transmettre tout ce comportement de domaine à mes racines d’agrégat. En général, je ne veux pas simuler mes référentiels. J’ai quand même besoin de confronter ce test d’intégration avec la réalité. L’adoption de CQRS signifie que nous n’avons plus vraiment besoin des référentiels.
Les référentiels peuvent être utiles, mais ils ne sont pas essentiels pour votre conception basée sur le domaine, contrairement au modèle Agrégat et au modèle de domaine riche. Par conséquent, utilisez le modèle Dépôt ou ne l’utilisez pas, en fonction de vos besoins.
Ressources supplémentaires
Modèle de référentiel
Edward Hieatt et Rob Mee. Modèle de référentiel.
https://martinfowler.com/eaaCatalog/repository.htmlLe modèle Dépôt
https://learn.microsoft.com/previous-versions/msp-n-p/ff649690(v=pandp.10)Eric Evans. Domain-Driven Design: Tackling Complexity in the Heart of Software. (Book; includes a discussion of the Repository pattern)
https://www.amazon.com/Domain-Driven-Design-Tackling-Complexity-Software/dp/0321125215/
Modèle Unité de travail
Martin Fowler. Modèle d’unité de travail.
https://martinfowler.com/eaaCatalog/unitOfWork.htmlImplementing the Repository and Unit of Work Patterns in an ASP.NET MVC Application
https://learn.microsoft.com/aspnet/mvc/overview/older-versions/getting-started-with-ef-5-using-mvc-4/implementing-the-repository-and-unit-of-work-patterns-in-an-asp-net-mvc-application
Commentaires
Bientôt disponible : Tout au long de 2024, nous allons supprimer progressivement GitHub Issues comme mécanisme de commentaires pour le contenu et le remplacer par un nouveau système de commentaires. Pour plus d’informations, consultez https://aka.ms/ContentUserFeedback.
Envoyer et afficher des commentaires pour