Note
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier les répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de changer de répertoire.
Conseil / Astuce
Ce contenu est un extrait du livre électronique, architecte d’applications web modernes avec ASP.NET Core et Azure, disponible sur .NET Docs ou en tant que PDF téléchargeable gratuitement qui peut être lu hors connexion.

Il n’est pas important d’avoir raison la première fois. Il est essentiel de réussir la dernière fois. - Andrew Hunt et David Thomas
ASP.NET Core est une infrastructure open source multiplateforme permettant de créer des applications web modernes optimisées pour le cloud. ASP.NET Applications Core sont légères et modulaires, avec prise en charge intégrée de l’injection de dépendances, ce qui permet une meilleure testabilité et une facilité de maintenance accrues. Combiné à MVC, qui prend en charge la création d’API web modernes en plus des applications basées sur l’affichage, ASP.NET Core est un framework puissant avec lequel créer des applications web d’entreprise.
MVC et pages Razor
ASP.NET Core MVC offre de nombreuses fonctionnalités utiles pour la création d’API et d’applications web. Le terme MVC signifie « Model-View-Controller », un modèle d’interface utilisateur qui divise les responsabilités de réponse aux demandes utilisateur en plusieurs parties. En plus de suivre ce modèle, vous pouvez également implémenter des fonctionnalités dans vos applications ASP.NET Core en tant que pages Razor.
Les pages Razor sont intégrées à ASP.NET Core MVC et utilisent les mêmes fonctionnalités pour le routage, la liaison de modèle, les filtres, l’autorisation, etc. Toutefois, au lieu d’avoir des dossiers et des fichiers distincts pour les contrôleurs, les modèles, les vues, etc. et l’utilisation d’un routage basé sur des attributs, Razor Pages sont placés dans un dossier unique (« /Pages »), route en fonction de leur emplacement relatif dans ce dossier et gèrent les requêtes avec des gestionnaires au lieu d’actions du contrôleur. Par conséquent, lorsque vous utilisez Razor Pages, les fichiers et les classes dont vous avez besoin sont généralement regroupés ensemble, et ne sont pas dispersés dans le projet web.
Découvrez comment MVC, Razor Pages et les modèles associés sont appliqués dans l’exemple d’application eShopOnWeb.
Lorsque vous créez une application ASP.NET Core, vous devez avoir un plan à l’esprit pour le type d’application que vous souhaitez créer. Lors de la création d’un projet, dans votre IDE ou à l’aide de la dotnet new commande CLI, vous choisissez parmi plusieurs modèles. Les modèles de projet les plus courants sont Empty, Web API, Web App et Web App (Model-View-Controller). Bien que vous ne puissiez prendre cette décision que lorsque vous créez un projet pour la première fois, il ne s’agit pas d’une décision irréversible. Le projet d’API web utilise des contrôleurs de modèle standardView-Controller; il manque simplement de vues par défaut. De même, le modèle d’application web par défaut utilise Razor Pages et n’a donc pas de dossier Views. Vous pouvez ajouter un dossier Views à ces projets ultérieurement pour prendre en charge le comportement basé sur l’affichage. Les projets d’API web et de modèle-View-Controller n’incluent pas de dossier Pages par défaut, mais vous pouvez en ajouter un ultérieurement pour prendre en charge le comportement basé sur Razor Pages. Vous pouvez considérer ces trois modèles comme prenant en charge trois types d’interaction utilisateur par défaut : les données (API web), les pages et les vues. Toutefois, vous pouvez combiner et faire correspondre l’un ou l’autre de ces modèles au sein d’un seul projet si vous le souhaitez.
Pourquoi Razor Pages ?
Razor Pages est l’approche par défaut pour les nouvelles applications web dans Visual Studio. Razor Pages offre un moyen plus simple de créer des fonctionnalités d’application basées sur des pages, telles que des formulaires non SPA. À l’aide de contrôleurs et de vues, il était courant pour les applications d’avoir des contrôleurs très volumineux qui utilisaient de nombreuses dépendances et modèles d’affichage différents et renvoyaient de nombreuses vues différentes. Cela a entraîné une plus grande complexité et a souvent entraîné des contrôleurs qui ne respectaient pas efficacement le principe de responsabilité unique ou les principes ouverts/fermés. Razor Pages résout ce problème encapsulant la logique côté serveur pour une « page » logique donnée dans une application web avec son balisage Razor. Une page Razor qui n’a aucune logique côté serveur ne peut se composer que d’un fichier Razor (par exemple, « Index.cshtml »). Toutefois, la plupart des pages Razor non triviales auront une classe de modèle de page associée, qui, par convention, porte le même nom que le fichier Razor avec une extension « .cs » (par exemple, « Index.cshtml.cs »).
Le modèle de page d'une Razor Page combine les responsabilités d'un contrôleur MVC et d'un modèle de vue. Au lieu de gérer les demandes avec des méthodes d’action du contrôleur, les gestionnaires de modèles de page tels que « OnGet() » sont exécutés, rendant leur page associée par défaut. Razor Pages simplifie le processus de création de pages individuelles dans une application ASP.NET Core, tout en fournissant toutes les fonctionnalités architecturales de ASP.NET Core MVC. Il s’agit d’un bon choix par défaut pour les nouvelles fonctionnalités basées sur les pages.
Quand utiliser MVC
Si vous créez des API web, le modèle MVC est plus judicieux que d’essayer d’utiliser Razor Pages. Si votre projet expose uniquement des points de terminaison d’API web, vous devez idéalement commencer à partir du modèle de projet d’API web. Sinon, il est facile d’ajouter des contrôleurs et des points de terminaison d’API associés à n’importe quelle application ASP.NET Core. Utilisez l’approche MVC basée sur la vue si vous migrez une application existante de ASP.NET MVC 5 ou antérieure vers ASP.NET Core MVC et que vous souhaitez le faire avec le moins d’efforts. Une fois que vous avez effectué la migration initiale, vous pouvez évaluer s’il est judicieux d’adopter Razor Pages pour de nouvelles fonctionnalités ou même en tant que migration en gros. Pour plus d’informations sur le portage d’applications .NET 4.x vers .NET 8, consultez Portage d’applications ASP.NET existantes vers ASP.NET Core eBook.
Que vous choisissiez de créer votre application web à l’aide de vues Razor Pages ou MVC, votre application aura des performances similaires et inclura la prise en charge de l’injection de dépendances, des filtres, de la liaison de modèle, de la validation, et ainsi de suite.
Mappage des requêtes aux réponses
À la base, les applications ASP.NET Core mappent les requêtes entrantes à des réponses sortantes. À un bas niveau, ce mappage est effectué avec les intergiciels, et les applications et microservices core ASP.NET simples peuvent être composés uniquement d’intergiciels personnalisés. Lorsque vous utilisez ASP.NET Core MVC, vous pouvez travailler à un niveau un peu plus élevé, en pensant en termes d’itinéraires, de contrôleurs et d’actions. Chaque requête entrante est comparée à la table de routage de l’application et, si une route correspondante est trouvée, la méthode d’action associée (appartenant à un contrôleur) est appelée pour gérer la requête. Si aucune route correspondante n’est trouvée, un gestionnaire d’erreurs (dans ce cas, le retour d’un résultat NotFound) est appelé.
ASP.NET applications Core MVC peuvent utiliser des itinéraires classiques, des itinéraires d’attribut ou les deux. Les itinéraires conventionnels sont définis dans le code, en spécifiant des conventions de routage à l’aide de la syntaxe comme dans l’exemple ci-dessous :
app.UseEndpoints(endpoints =>
{
endpoints.MapControllerRoute(name: "default", pattern: "{controller=Home}/{action=Index}/{id?}");
});
Dans cet exemple, un itinéraire nommé « default » a été ajouté à la table de routage. Il définit un modèle d’itinéraire avec des espaces réservés pour controller, actionet id. Les espaces réservés controller et action ont la valeur par défaut spécifiée (Home etIndex respectivement) et l’espace réservé id est facultatif (en vertu d’un « ? » qui lui est appliqué). La convention définie ici indique que la première partie d’une demande doit correspondre au nom du contrôleur, la deuxième partie à l’action, puis, si nécessaire, une troisième partie représente un paramètre d’ID. Les itinéraires conventionnels sont généralement définis à un seul endroit pour l’application, par exemple dans Program.cs où le pipeline d’intergiciel de requête est configuré.
Les itinéraires d’attribut sont appliqués directement aux contrôleurs et aux actions, plutôt que spécifiés globalement. Cette approche présente l’avantage de les rendre beaucoup plus détectables lorsque vous examinez une méthode particulière, mais cela signifie que les informations de routage ne sont pas conservées dans un seul endroit dans l’application. Avec les itinéraires d’attribut, vous pouvez facilement spécifier plusieurs itinéraires pour une action donnée, ainsi que combiner des itinéraires entre les contrôleurs et les actions. Par exemple:
[Route("Home")]
public class HomeController : Controller
{
[Route("")] // Combines to define the route template "Home"
[Route("Index")] // Combines to define route template "Home/Index"
[Route("/")] // Does not combine, defines the route template ""
public IActionResult Index() {}
}
Les itinéraires peuvent être spécifiés sur [HttpGet] et des attributs similaires, ce qui évite d’avoir à ajouter des attributs [Route] distincts. Les itinéraires d’attribut peuvent également utiliser des jetons pour réduire la nécessité de répéter les noms de contrôleur ou d’action, comme indiqué ci-dessous :
[Route("[controller]")]
public class ProductsController : Controller
{
[Route("")] // Matches 'Products'
[Route("Index")] // Matches 'Products/Index'
public IActionResult Index() {}
}
Les pages Razor n’utilisent pas le routage des attributs. Vous pouvez spécifier des informations de modèle de route supplémentaires pour une page Razor dans le cadre de sa directive @page :
@page "{id:int}"
Dans l’exemple précédent, la page en question correspondrait à un itinéraire avec un paramètre entier id . Par exemple, la page Products.cshtml située à la racine d’un /Pages produit répond à des demandes comme celle-ci :
/Products/123
Une fois qu’une demande donnée a été mise en correspondance avec un itinéraire, mais avant l’appel de la méthode d’action, ASP.NET Core MVC effectue la liaison de modèle et la validation du modèle sur la demande. La liaison de modèle est chargée de convertir les données HTTP entrantes en types .NET spécifiés en tant que paramètres de la méthode d’action à appeler. Par exemple, si la méthode d’action attend un int id paramètre, la liaison de modèle tente de fournir ce paramètre à partir d’une valeur fournie dans le cadre de la requête. Pour ce faire, la liaison de données recherche des valeurs dans un formulaire publié, dans la route elle-même et dans la chaîne de requête. En supposant qu’une id valeur est trouvée, elle est convertie en entier avant d’être passée dans la méthode d’action.
Après la liaison du modèle, mais avant d’appeler la méthode d’action, la validation du modèle se produit. La validation de modèle utilise des attributs facultatifs sur le type de modèle et peut vous aider à garantir que l’objet de modèle fourni est conforme à certaines exigences de données. Certaines valeurs peuvent être spécifiées en fonction des besoins, ou limitées à une certaine longueur ou plage numérique, etc. Si les attributs de validation sont spécifiés, mais que le modèle n’est pas conforme à leurs exigences, la propriété ModelState.IsValid est false et l’ensemble de règles de validation défaillantes sera disponible pour envoyer au client effectuant la requête.
Si vous utilisez la validation du modèle, veillez à toujours vérifier que le modèle est valide avant d’exécuter des commandes de modification d’état, pour vous assurer que votre application n’est pas endommagée par des données non valides. Vous pouvez utiliser un filtre pour éviter d’avoir à ajouter du code pour cette validation dans chaque action. ASP.NET filtres MVC de base offrent un moyen d’intercepter des groupes de requêtes, afin que les stratégies courantes et les préoccupations croisées puissent être appliquées sur une base ciblée. Les filtres peuvent être appliqués à des actions individuelles, à des contrôleurs entiers ou globalement pour une application.
Pour les API web, ASP.NET Core MVC prend en charge la négociation de contenu, ce qui permet aux demandes de spécifier la façon dont les réponses doivent être mises en forme. La réponse sera formatée en XML, JSON, ou un autre format pris en charge, en fonction des en-têtes fournis dans la requête par les actions qui retournent des données. Cette fonctionnalité permet à la même API d’être utilisée par plusieurs clients avec différentes exigences en matière de format de données.
Les projets d’API web doivent envisager d’utiliser l’attribut [ApiController] , qui peut être appliqué à des contrôleurs individuels, à une classe de contrôleur de base ou à l’assembly entier. Cet attribut ajoute la vérification automatique de la validation du modèle et toute action avec un modèle non valide retourne une Requête BadRequest avec les détails des erreurs de validation. L’attribut nécessite également que toutes les actions aient un itinéraire d’attribut, plutôt que d’utiliser une route conventionnelle, et retourne des informations ProblemDetails plus détaillées en réponse aux erreurs.
Maintenir les contrôleurs sous contrôle
Pour les applications basées sur des pages, Razor Pages font un excellent travail pour empêcher les contrôleurs de devenir trop encombrants. Chaque page individuelle reçoit ses propres fichiers et classes dédiés uniquement à ses gestionnaires. Avant l’introduction de Razor Pages, de nombreuses applications centrées sur l’affichage auraient des classes de contrôleur volumineuses responsables de nombreuses actions et vues différentes. Ces classes se développeraient naturellement pour avoir de nombreuses responsabilités et dépendances, ce qui les rend plus difficiles à maintenir. Si vous trouvez que vos contrôleurs basés sur l’affichage sont trop volumineux, envisagez de les refactoriser pour utiliser Razor Pages ou d’introduire un modèle comme un médiateur.
Le modèle de conception du médiateur est utilisé pour réduire le couplage entre les classes tout en autorisant la communication entre eux. Dans ASP.NET applications MVC core, ce modèle est fréquemment utilisé pour décomposer les contrôleurs en morceaux plus petits à l’aide de gestionnaires pour effectuer le travail des méthodes d’action. Le package NuGet MediatR populaire est souvent utilisé pour y parvenir. En règle générale, les contrôleurs incluent de nombreuses méthodes d’action différentes, chacune pouvant nécessiter certaines dépendances. L’ensemble de toutes les dépendances requises par n’importe quelle action doit être transmis au constructeur du contrôleur. Lorsque vous utilisez MediatR, la seule dépendance qu’un contrôleur aura généralement est une instance du médiateur. Chaque action utilise ensuite l’instance médiateur pour envoyer un message, qui est traité par un gestionnaire. Le gestionnaire est spécifique à une seule action et nécessite donc uniquement les dépendances requises par cette action. Voici un exemple de contrôleur utilisant MediatR :
public class OrderController : Controller
{
private readonly IMediator _mediator;
public OrderController(IMediator mediator)
{
_mediator = mediator;
}
[HttpGet]
public async Task<IActionResult> MyOrders()
{
var viewModel = await _mediator.Send(new GetMyOrders(User.Identity.Name));
return View(viewModel);
}
// other actions implemented similarly
}
Dans l’action MyOrders , l’appel à Send un GetMyOrders message est géré par cette classe :
public class GetMyOrdersHandler : IRequestHandler<GetMyOrders, IEnumerable<OrderViewModel>>
{
private readonly IOrderRepository _orderRepository;
public GetMyOrdersHandler(IOrderRepository orderRepository)
{
_orderRepository = orderRepository;
}
public async Task<IEnumerable<OrderViewModel>> Handle(GetMyOrders request, CancellationToken cancellationToken)
{
var specification = new CustomerOrdersWithItemsSpecification(request.UserName);
var orders = await _orderRepository.ListAsync(specification);
return orders.Select(o => new OrderViewModel
{
OrderDate = o.OrderDate,
OrderItems = o.OrderItems?.Select(oi => new OrderItemViewModel()
{
PictureUrl = oi.ItemOrdered.PictureUri,
ProductId = oi.ItemOrdered.CatalogItemId,
ProductName = oi.ItemOrdered.ProductName,
UnitPrice = oi.UnitPrice,
Units = oi.Units
}).ToList(),
OrderNumber = o.Id,
ShippingAddress = o.ShipToAddress,
Total = o.Total()
});
}
}
Le résultat final de cette approche est que les contrôleurs soient beaucoup plus petits et concentrés principalement sur le routage et la liaison de modèle, tandis que les gestionnaires individuels sont responsables des tâches spécifiques nécessaires par un point de terminaison donné. Cette approche peut également être obtenue sans MediatR à l’aide du package NuGet ApiEndpoints, qui tente d’apporter aux contrôleurs d’API les mêmes avantages que les pages Razor apporte aux contrôleurs basés sur l’affichage.
Références – Mappage des requêtes aux réponses
- Routage vers les actions du contrôleur
https://learn.microsoft.com/aspnet/core/mvc/controllers/routing- Liaison de modèles
https://learn.microsoft.com/aspnet/core/mvc/models/model-binding- Validation du modèle
https://learn.microsoft.com/aspnet/core/mvc/models/validation- Filtres
https://learn.microsoft.com/aspnet/core/mvc/controllers/filters- Attribut ApiController
https://learn.microsoft.com/aspnet/core/web-api/
Travailler avec les dépendances
ASP.NET Core prend en charge et utilise en interne une technique appelée injection de dépendances. L’injection de dépendances est une technique qui autorise un couplage faible entre les différentes parties d’une application. Le couplage plus souple est souhaitable, car il permet d’isoler plus facilement les parties de l’application, ce qui permet de tester ou de remplacer. Elle rend également moins probable qu’une modification dans une partie de l’application aura un impact inattendu ailleurs dans l’application. L'injection de dépendance repose sur le principe d'inversion de dépendance et joue souvent un rôle clé pour respecter le principe ouvert/fermé. Quand vous évaluez le fonctionnement de votre application avec ses dépendances, prenez garde au « code smell » Static Cling (adhésion statique), et n’oubliez pas l’aphorisme « New is Glue » (couplage du code résultant de l’utilisation du mot clé new).
L’accroche statique se produit lorsque vos classes effectuent des appels à des méthodes statiques ou accèdent à des propriétés statiques, qui ont des effets secondaires ou des dépendances sur l’infrastructure. Par exemple, si vous avez une méthode qui appelle une méthode statique, qui à son tour écrit dans une base de données, votre méthode est étroitement couplée à la base de données. Tout ce qui interrompt cet appel de base de données interrompt votre méthode. Le test de ces méthodes est notoirement difficile, car ces tests nécessitent des bibliothèques de simulation commerciales pour simuler les appels statiques, ou ne peuvent être testées qu’avec une base de données de test en place. Les appels statiques qui n’ont aucune dépendance vis-à-vis de l’infrastructure, en particulier ceux qui sont complètement sans état, sont parfaits pour appeler et n’ont aucun impact sur le couplage ou la testabilité (au-delà du code de couplage vers l’appel statique lui-même).
De nombreux développeurs sont conscients des risques liés à l’attachement statique et à l’état global, mais continuent de coupler étroitement leur code à des implémentations spécifiques par l’instanciation directe. « New is glue » vise à rappeler ce couplage, et non une condamnation générale de l’utilisation du mot clé new. Tout comme avec les appels de méthode statique, les nouvelles instances de types qui n’ont pas de dépendances externes ne couplent généralement pas étroitement le code aux détails de l’implémentation ou rendent les tests plus difficiles. Toutefois, chaque fois qu’une classe est instanciée, prenez un bref instant pour déterminer s’il est judicieux de coder en dur cette instance spécifique dans cet emplacement particulier, ou s’il s’agit d’une meilleure conception pour demander cette instance en tant que dépendance.
Déclarer vos dépendances
ASP.NET Core repose sur la création de méthodes et de classes pour déclarer leurs dépendances, en les demandant en tant qu’arguments. ASP.NET applications sont généralement configurées dans Program.cs ou dans une Startup classe.
Remarque
La configuration complète des applications dans Program.cs est l’approche par défaut pour les applications .NET 6 (et versions ultérieures) et Visual Studio 2022 (et versions ultérieures). Les modèles de projet ont été mis à jour pour vous aider à bien démarrer avec cette nouvelle approche. ASP.NET projets Core peuvent toujours utiliser une Startup classe, si vous le souhaitez.
Configurer des services dans Program.cs
Pour les applications très simples, vous pouvez connecter des dépendances directement dans Program.cs fichier à l’aide d’un WebApplicationBuilder. Une fois que tous les services nécessaires ont été ajoutés, le générateur est utilisé pour créer l’application.
var builder = WebApplication.CreateBuilder(args);
// Add services to the container.
builder.Services.AddRazorPages();
var app = builder.Build();
Configurer des services dans Startup.cs
La Startup.cs est elle-même configurée pour prendre en charge l’injection de dépendances à plusieurs points. Si vous utilisez une Startup classe, vous pouvez lui donner un constructeur et lui demander des dépendances, comme suit :
public class Startup
{
public Startup(IHostingEnvironment env)
{
var builder = new ConfigurationBuilder()
.SetBasePath(env.ContentRootPath)
.AddJsonFile("appsettings.json", optional: false, reloadOnChange: true)
.AddJsonFile($"appsettings.{env.EnvironmentName}.json", optional: true);
}
}
La Startup classe est intéressante dans le fait qu’il n’y a pas de conditions de type explicites pour elle. Il n’hérite pas d’une classe de base spéciale Startup , ni n’implémente une interface particulière. Vous pouvez lui donner un constructeur, ou non, et vous pouvez spécifier autant de paramètres sur le constructeur que vous le souhaitez. Lorsque l’hôte web que vous avez configuré pour votre application démarre, il appelle la Startup classe (si vous l’avez dit d’utiliser une) et utilise l’injection de dépendances pour remplir toutes les dépendances dont la Startup classe a besoin. Bien sûr, si vous demandez des paramètres qui ne sont pas configurés dans le conteneur de services utilisé par ASP.NET Core, vous obtiendrez une exception, mais tant que vous restez fidèle aux dépendances que le conteneur connaît, vous pouvez demander tout ce que vous voulez.
L’injection de dépendances est intégrée à vos applications ASP.NET Core dès le début, lorsque vous créez l’instance de démarrage. Mais la classe Startup va plus loin. Vous pouvez également demander des dépendances dans la Configure méthode :
public void Configure(IApplicationBuilder app,
IHostingEnvironment env,
ILoggerFactory loggerFactory)
{
}
La méthode ConfigureServices est l’exception à ce comportement ; il doit prendre un seul paramètre de type IServiceCollection. Il n’a pas vraiment besoin de prendre en charge l’injection de dépendances, car d’une part, il est responsable de l’ajout d’objets au conteneur de services, et d’autre part, il a accès à tous les services actuellement configurés via le IServiceCollection paramètre. Par conséquent, vous pouvez utiliser des dépendances définies dans la collection de services de base ASP.NET dans chaque partie de la Startup classe, soit en demandant le service nécessaire en tant que paramètre, soit en travaillant avec l’élément IServiceCollection in ConfigureServices.
Remarque
Si vous devez vous assurer que certains services sont disponibles pour votre Startup classe, vous pouvez les configurer à l’aide d’un IWebHostBuilder et de sa méthode ConfigureServices lors de l’appel CreateDefaultBuilder.
La classe Startup est un modèle pour la façon dont vous devez structurer d’autres parties de votre application ASP.NET Core, des contrôleurs aux intergiciels aux filtres vers vos propres services. Dans chaque cas, vous devez suivre le principe des dépendances explicites, demander vos dépendances plutôt que les créer directement et tirer parti de l’injection de dépendances dans votre application. Faites attention à l’emplacement et à la façon dont vous instanciez directement les implémentations, en particulier les services et les objets qui fonctionnent avec l’infrastructure ou qui ont des effets secondaires. Préférez utiliser des abstractions définies dans votre cœur d’application et passées en tant qu’arguments pour le codage en dur des références à des types d’implémentation spécifiques.
Structurer l’application
Les applications monolithiques ont généralement un point d’entrée unique. Dans le cas d’une application web ASP.NET Core, le point d’entrée sera le projet web ASP.NET Core. Toutefois, cela ne signifie pas que la solution doit se composer d’un seul projet. Il est utile de diviser l’application en différentes couches afin de suivre la séparation des préoccupations. Une fois divisé en couches, il est utile d’aller au-delà des dossiers pour séparer les projets, ce qui peut aider à améliorer l’encapsulation. La meilleure approche pour atteindre ces objectifs avec une application ASP.NET Core est une variante de l’architecture propre décrite dans le chapitre 5. À l’issue de cette approche, la solution de l’application comprend des bibliothèques distinctes pour l’interface utilisateur, l’infrastructure et ApplicationCore.
En plus de ces projets, des projets de test distincts sont également inclus (le test est abordé dans le chapitre 9).
Le modèle objet et les interfaces de l’application doivent être placés dans le projet ApplicationCore. Ce projet aura le plus peu de dépendances possible (et aucun sur des problèmes d’infrastructure spécifiques), et les autres projets de la solution le référenceront. Les entités métier qui doivent être conservées ainsi que les services qui ne dépendent pas directement de l'infrastructure sont définis dans le projet ApplicationCore.
Les détails de l’implémentation, tels que la façon dont la persistance est effectuée ou la façon dont les notifications peuvent être envoyées à un utilisateur, sont conservées dans le projet d’infrastructure. Ce projet référencera des packages spécifiques à l’implémentation tels que Entity Framework Core, mais ne doit pas exposer de détails sur ces implémentations en dehors du projet. Les services et référentiels d’infrastructure doivent implémenter des interfaces définies dans le projet ApplicationCore, et ses implémentations de persistance sont responsables de la récupération et du stockage d’entités définies dans ApplicationCore.
Le projet d’interface utilisateur principal ASP.NET est responsable des problèmes au niveau de l’interface utilisateur, mais ne doit pas inclure de détails sur la logique métier ou l’infrastructure. En fait, dans l’idéal, il ne devrait même pas avoir de dépendance sur le projet d’infrastructure, ce qui permettra de garantir qu’aucune dépendance entre les deux projets n’est introduite accidentellement. Cela peut être réalisé à l’aide d’un conteneur d’di tiers comme Autofac, qui vous permet de définir des règles d’di dans les classes de module dans chaque projet.
Une autre approche pour découpler l'application des détails de l'implémentation consiste à faire en sorte que l'application appelle des microservices, peut-être déployés dans des conteneurs Docker individuels. Cela offre une séparation encore plus nette des préoccupations et un découplage accru que l’utilisation de l'ID entre deux projets, mais introduit une complexité supplémentaire.
Organisation des fonctionnalités
Par défaut, ASP.NET applications principales organisent leur structure de dossiers pour inclure les contrôleurs et les vues, et fréquemment ViewModels. Le code côté client pour prendre en charge ces structures côté serveur est généralement stocké séparément dans le dossier wwwroot. Toutefois, les grandes applications peuvent rencontrer des problèmes avec cette organisation, car l’utilisation d’une fonctionnalité donnée nécessite souvent un saut entre ces dossiers. Cela devient plus difficile à mesure que le nombre de fichiers et de sous-dossiers de chaque dossier augmente, ce qui entraîne un grand nombre de défilements dans l’Explorateur de solutions. Une solution à ce problème consiste à organiser le code d’application par fonctionnalité au lieu d’un type de fichier. Ce style d’organisation est généralement appelé dossiers de caractéristiques ou tranches de caractéristiques (voir aussi : Tranches verticales).
ASP.NET Core MVC prend en charge les zones à cet effet. À l’aide de zones, vous pouvez créer des ensembles distincts de dossiers Contrôleurs et Vues (ainsi que tous les modèles associés) dans chaque dossier Area. La figure 7-1 montre un exemple de structure de dossiers, à l’aide de Zones.
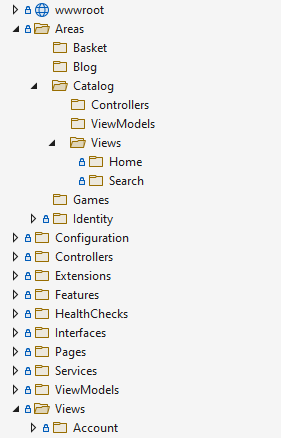
Figure 7-1. Exemple d’organisation de zone
Lorsque vous utilisez Des zones, vous devez utiliser des attributs pour décorer vos contrôleurs avec le nom de la zone à laquelle ils appartiennent :
[Area("Catalog")]
public class HomeController
{}
Vous devez également ajouter la prise en charge des zones à vos routes :
app.UseEndpoints(endpoints =>
{
endpoints.MapControllerRoute(name: "areaRoute", pattern: "{area:exists}/{controller=Home}/{action=Index}/{id?}");
endpoints.MapControllerRoute(name: "default", pattern: "{controller=Home}/{action=Index}/{id?}");
});
Outre la prise en charge intégrée des zones, vous pouvez également utiliser votre propre structure de dossiers et les conventions à la place des attributs et des itinéraires personnalisés. Cela vous permettrait d’avoir des dossiers de fonctionnalités qui n’incluaient pas de dossiers distincts pour les vues, les contrôleurs, etc., en conservant la hiérarchie à plat et en facilitant l’affichage de tous les fichiers associés à un emplacement unique pour chaque fonctionnalité. Pour les API, les dossiers peuvent être utilisés pour remplacer les contrôleurs, et chaque dossier peut contenir tous les points de terminaison d’API et leurs DTO associés.
ASP.NET Core utilise des types de convention intégrés pour contrôler son comportement. Vous pouvez modifier ou remplacer ces conventions. Par exemple, vous pouvez créer une convention qui obtient automatiquement le nom de fonctionnalité d’un contrôleur donné en fonction de son espace de noms (qui correspond généralement au dossier dans lequel se trouve le contrôleur) :
public class FeatureConvention : IControllerModelConvention
{
public void Apply(ControllerModel controller)
{
controller.Properties.Add("feature",
GetFeatureName(controller.ControllerType));
}
private string GetFeatureName(TypeInfo controllerType)
{
string[] tokens = controllerType.FullName.Split('.');
if (!tokens.Any(t => t == "Features")) return "";
string featureName = tokens
.SkipWhile(t => !t.Equals("features", StringComparison.CurrentCultureIgnoreCase))
.Skip(1)
.Take(1)
.FirstOrDefault();
return featureName;
}
}
Vous spécifiez ensuite cette convention comme option lorsque vous ajoutez la prise en charge de MVC à votre application dans ConfigureServices (ou dans Program.cs) :
// ConfigureServices
services.AddMvc(o => o.Conventions.Add(new FeatureConvention()));
// Program.cs
builder.Services.AddMvc(o => o.Conventions.Add(new FeatureConvention()));
ASP.NET Core MVC utilise également une convention pour localiser les vues. Vous pouvez la remplacer par une convention personnalisée afin que les vues se trouvent dans vos dossiers de fonctionnalités (à l’aide du nom de fonctionnalité fourni par FeatureConvention, ci-dessus). Vous pouvez en savoir plus sur cette approche et télécharger un exemple de travail à partir de l’article MSDN Magazine, Segments de fonctionnalités pour ASP.NET Core MVC.
APIs et Blazor applications
Si votre application inclut un ensemble d’API web, qui doivent être sécurisées, ces API doivent idéalement être configurées en tant que projet distinct de votre application View ou Razor Pages. La séparation des API, en particulier les API publiques, de votre application web côté serveur présente un certain nombre d’avantages. Ces applications auront souvent des caractéristiques de déploiement et de charge uniques. Ils sont également très susceptibles d’adopter différents mécanismes de sécurité, avec des applications basées sur des formulaires standard tirant parti de l’authentification basée sur les cookies et des API qui utilisent probablement l’authentification basée sur des jetons.
En outre, Blazor les applications, qu'elles utilisent le serveur Blazor ou BlazorWebAssembly, doivent être construites en tant que projets distincts. Les applications ont des caractéristiques d’exécution différentes ainsi que des modèles de sécurité. Ils sont susceptibles de partager des types communs avec l’application web côté serveur (ou projet API), et ces types doivent être définis dans un projet partagé commun.
L’ajout d’une BlazorWebAssembly interface d’administration à eShopOnWeb exige l’ajout de plusieurs nouveaux projets. Le projet BlazorWebAssembly lui-même, BlazorAdmin. Un nouvel ensemble de points de terminaison d’API publics, utilisés BlazorAdmin et configurés pour utiliser l’authentification basée sur des jetons, est défini dans le PublicApi projet. Et certains types partagés utilisés par ces deux projets sont conservés dans un nouveau BlazorShared projet.
On peut demander pourquoi ajouter un projet distinct BlazorShared lorsqu’il existe déjà un projet commun ApplicationCore qui pourrait être utilisé pour partager tous les types requis par les deux PublicApi et BlazorAdmin? La réponse est que ce projet inclut toute la logique métier de l’application et est donc beaucoup plus volumineux que nécessaire et qu’il doit également être conservé sécurisé sur le serveur. N’oubliez pas que toute bibliothèque référencée par BlazorAdmin sera téléchargée sur les navigateurs des utilisateurs lorsqu’elles chargent l’application Blazor .
Selon que l’on utilise le modèle Backends-For-Frontends (BFF), les API consommées par l’application BlazorWebAssembly peuvent ne pas partager leurs types 100% avec Blazor. En particulier, une API publique destinée à être consommée par de nombreux clients différents peut définir ses propres types de requête et de résultat, plutôt que de les partager dans un projet partagé spécifique au client. Dans l’exemple eShopOnWeb, l’hypothèse est faite que le PublicApi projet est, en fait, l’hébergement d’une API publique, donc pas tous ses types de demande et de réponse proviennent du BlazorShared projet.
Problèmes transversaux
À mesure que les applications augmentent, il devient de plus en plus important de prendre en compte les préoccupations croisées afin d’éliminer la duplication et de maintenir la cohérence. Certains exemples de préoccupations croisées dans ASP.NET applications principales sont l’authentification, les règles de validation de modèle, la mise en cache de sortie et la gestion des erreurs, bien qu’il existe de nombreux autres. ASP.NET filtres MVC core vous permettent d’exécuter du code avant ou après certaines étapes du pipeline de traitement des demandes. Par exemple, un filtre peut s’exécuter avant et après la liaison du modèle, avant et après l'exécution d'une action, ou avant et après le résultat d’une action. Vous pouvez également utiliser un filtre d’autorisation pour contrôler l’accès au reste du pipeline. Les figures 7-2 montrent comment l’exécution des requêtes transite par les filtres, si elle est configurée.
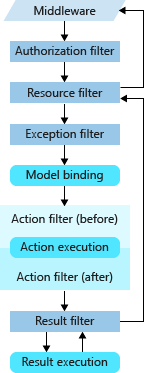
Figure 7-2. Exécution de la demande via des filtres et un pipeline de requête.
Les filtres sont généralement implémentés en tant qu’attributs, ce qui vous permet de les appliquer aux contrôleurs ou aux actions (voire globalement). Lorsqu’ils sont ajoutés de cette façon, les filtres spécifiés au niveau de l’action remplacent ou s’appuient sur des filtres spécifiés au niveau du contrôleur, qui remplacent eux-mêmes les filtres globaux. Par exemple, l’attribut [Route] peut être utilisé pour créer des itinéraires entre les contrôleurs et les actions. De même, l’autorisation peut être configurée au niveau du contrôleur, puis remplacée par des actions individuelles, comme l’illustre l’exemple suivant :
[Authorize]
public class AccountController : Controller
{
[AllowAnonymous] // overrides the Authorize attribute
public async Task<IActionResult> Login() {}
public async Task<IActionResult> ForgotPassword() {}
}
La première méthode, Login, utilise le filtre [AllowAnonymous] (attribut) pour outrepasser le filtre Authorize défini au niveau du contrôleur. L’action ForgotPassword (et toute autre action de la classe qui n’a pas d’attribut AllowAnonymous) nécessite une requête authentifiée.
Les filtres peuvent être utilisés pour éliminer la duplication sous la forme de stratégies courantes de gestion des erreurs pour les API. Par exemple, une stratégie d’API classique consiste à retourner une réponse Introuvable aux demandes référençant les clés qui n’existent pas, et une réponse BadRequest si la validation du modèle échoue. L’exemple suivant illustre ces deux stratégies en action :
[HttpPut("{id}")]
public async Task<IActionResult> Put(int id, [FromBody]Author author)
{
if ((await _authorRepository.ListAsync()).All(a => a.Id != id))
{
return NotFound(id);
}
if (!ModelState.IsValid)
{
return BadRequest(ModelState);
}
author.Id = id;
await _authorRepository.UpdateAsync(author);
return Ok();
}
N’autorisez pas vos méthodes d’action à devenir encombrées avec du code conditionnel comme celui-ci. Au lieu de cela, intégrez les politiques dans des filtres qui peuvent être appliqués en fonction des besoins. Dans cet exemple, la vérification de validation du modèle, qui doit se produire chaque fois qu’une commande est envoyée à l’API, peut être remplacée par l’attribut suivant :
public class ValidateModelAttribute : ActionFilterAttribute
{
public override void OnActionExecuting(ActionExecutingContext context)
{
if (!context.ModelState.IsValid)
{
context.Result = new BadRequestObjectResult(context.ModelState);
}
}
}
Vous pouvez ajouter le ValidateModelAttribute à votre projet en tant que dépendance NuGet en incluant le package Ardalis.ValidateModel. Pour les API, vous pouvez utiliser l’attribut ApiController pour appliquer ce comportement sans avoir besoin d’un filtre distinct ValidateModel .
De même, un filtre peut être utilisé pour vérifier si un enregistrement existe et retourner un 404 avant l’exécution de l’action, ce qui élimine la nécessité d’effectuer ces vérifications dans l’action. Une fois que vous avez extrait des conventions courantes et organisé votre solution pour séparer le code d’infrastructure et la logique métier de votre interface utilisateur, vos méthodes d’action MVC doivent être extrêmement minces :
[HttpPut("{id}")]
[ValidateAuthorExists]
public async Task<IActionResult> Put(int id, [FromBody]Author author)
{
await _authorRepository.UpdateAsync(author);
return Ok();
}
Vous pouvez en savoir plus sur l’implémentation de filtres et télécharger un exemple de travail à partir de l’article MSDN Magazine, Real-World ASP.NET Core MVC Filters.
Si vous constatez que vous avez un certain nombre de réponses courantes provenant d’API basées sur des scénarios courants tels que les erreurs de validation (demande incorrecte), les ressources introuvables et les erreurs de serveur, vous pouvez envisager d’utiliser une abstraction de résultat . L’abstraction de résultat serait retournée par les services consommés par les points de terminaison d’API, et l’action ou le point de terminaison du contrôleur utiliserait un filtre pour les traduire en IActionResults.
Références – Structure des applications
- Zones
https://learn.microsoft.com/aspnet/core/mvc/controllers/areas- MSDN Magazine – Tranches de fonctionnalités pour ASP.NET Core MVC
https://learn.microsoft.com/archive/msdn-magazine/2016/september/asp-net-core-feature-slices-for-asp-net-core-mvc- Filtres
https://learn.microsoft.com/aspnet/core/mvc/controllers/filters- MSDN Magazine – Real World ASP.NET Core MVC Filters
https://learn.microsoft.com/archive/msdn-magazine/2016/august/asp-net-core-real-world-asp-net-core-mvc-filters- Résultat dans eShopOnWeb
https://github.com/dotnet-architecture/eShopOnWeb/wiki/Patterns#result
Sécurité
La sécurisation des applications web est une rubrique importante, avec de nombreuses considérations. Au niveau le plus élémentaire, la sécurité implique de vous assurer que vous savez qui une demande donnée provient, puis de s’assurer que la demande n’a accès qu’aux ressources qu’elle doit. L’authentification est le processus de comparaison des informations d’identification fournies avec une demande à celles d’un magasin de données approuvé, pour voir si la demande doit être traitée comme provenant d’une entité connue. L’autorisation est le processus de restriction de l’accès à certaines ressources en fonction de l’identité de l’utilisateur. Une troisième préoccupation en matière de sécurité consiste à protéger les demandes contre l’écoute par des tiers, pour lesquels vous devez au moins vous assurer que SSL est utilisé par votre application.
Identité
ASP.NET Core Identity est un système d’appartenance que vous pouvez utiliser pour prendre en charge les fonctionnalités de connexion pour votre application. Il prend en charge les comptes d’utilisateurs locaux ainsi que le support des fournisseurs de connexion externes provenant de fournisseurs tels que Compte Microsoft, Twitter, Facebook, Google, etc. En plus de ASP.NET Identité principale, votre application peut utiliser l’authentification Windows ou un fournisseur d’identité tiers comme Identity Server.
ASP.NET Identité principale est incluse dans les nouveaux modèles de projet si l’option Comptes d’utilisateur individuels est sélectionnée. Ce modèle inclut la prise en charge de l’inscription, de la connexion, des connexions externes, des mots de passe oubliés et des fonctionnalités supplémentaires.
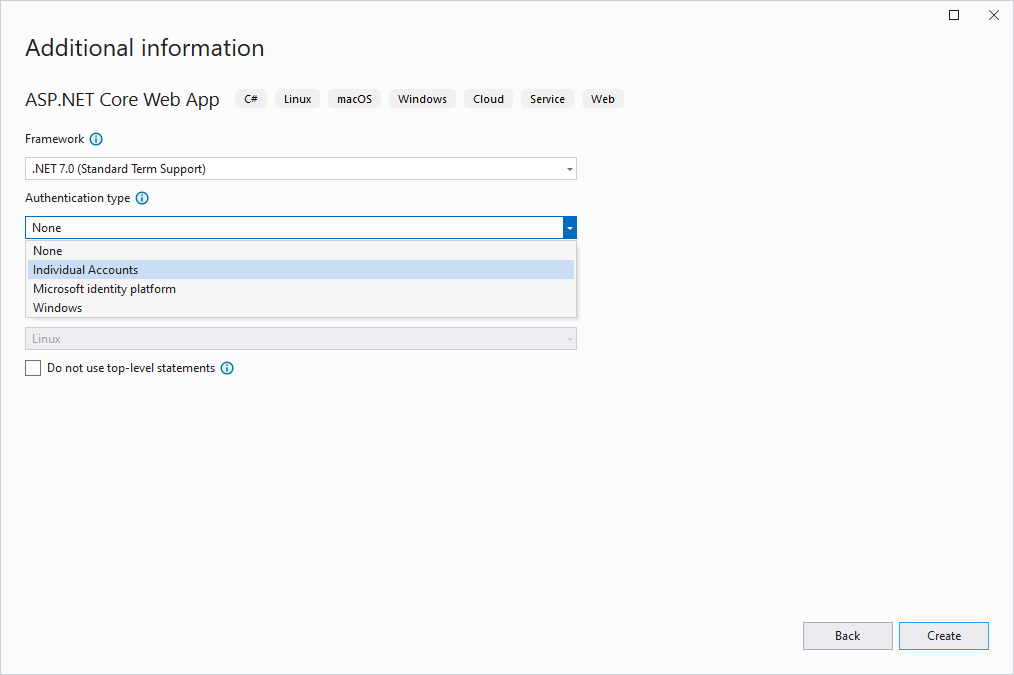
Figure 7-3. Sélectionnez Des comptes d’utilisateur individuels pour que l’identité soit préconfigurée.
La prise en charge des identités est configurée dans Program.cs ou Startup, et inclut la configuration des services et des intergiciels.
Configurer l’identité dans Program.cs
Dans Program.cs, vous configurez les services à partir de l’instance WebHostBuilder , puis une fois l’application créée, vous configurez son intergiciel. Les points clés à noter sont l’appel aux AddDefaultIdentity pour les services requis et les appels UseAuthentication et UseAuthorization qui ajoutent le middleware requis.
var builder = WebApplication.CreateBuilder(args);
// Add services to the container.
var connectionString = builder.Configuration.GetConnectionString("DefaultConnection");
builder.Services.AddDbContext<ApplicationDbContext>(options =>
options.UseSqlServer(connectionString));
builder.Services.AddDatabaseDeveloperPageExceptionFilter();
builder.Services.AddDefaultIdentity<IdentityUser>(options => options.SignIn.RequireConfirmedAccount = true)
.AddEntityFrameworkStores<ApplicationDbContext>();
builder.Services.AddRazorPages();
var app = builder.Build();
// Configure the HTTP request pipeline.
if (app.Environment.IsDevelopment())
{
app.UseMigrationsEndPoint();
}
else
{
app.UseExceptionHandler("/Error");
// The default HSTS value is 30 days. You may want to change this for production scenarios, see https://aka.ms/aspnetcore-hsts.
app.UseHsts();
}
app.UseHttpsRedirection();
app.UseStaticFiles();
app.UseRouting();
app.UseAuthentication();
app.UseAuthorization();
app.MapRazorPages();
app.Run();
Configuration de l’identité au démarrage de l’application
// Add framework services.
builder.Services.AddDbContext<ApplicationDbContext>(options =>
options.UseSqlServer(Configuration.GetConnectionString("DefaultConnection")));
builder.Services.AddIdentity<ApplicationUser, IdentityRole>()
.AddEntityFrameworkStores<ApplicationDbContext>()
.AddDefaultTokenProviders();
builder.Services.AddMvc();
var app = builder.Build();
if (app.Environment.IsDevelopment())
{
app.UseMigrationsEndPoint();
}
else
{
app.UseExceptionHandler("/Error");
app.UseHsts();
}
app.UseHttpsRedirection();
app.UseStaticFiles();
app.UseRouting();
app.UseAuthentication();
app.UseAuthorization();
app.MapRazorPages();
Il est important que UseAuthentication et UseAuthorization apparaissent avant MapRazorPages. Lors de la configuration des services Identity, vous remarquerez un appel à AddDefaultTokenProviders. Cela n’a rien à voir avec les jetons qui peuvent être utilisés pour sécuriser les communications web, mais fait plutôt référence aux fournisseurs qui créent des invites qui peuvent être envoyées aux utilisateurs par SMS ou par e-mail pour confirmer leur identité.
Vous pouvez en savoir plus sur la configuration de l’authentification à deux facteurs et l’activation des fournisseurs de connexion externes à partir de la documentation officielle ASP.NET Core.
Authentification
L’authentification consiste à déterminer qui accède au système. Si vous utilisez ASP.NET Core Identity et les méthodes de configuration indiquées dans la section précédente, il configure automatiquement certaines valeurs par défaut d’authentification dans l’application. Toutefois, vous pouvez également configurer ces valeurs par défaut manuellement ou remplacer celles définies par AddIdentity. Si vous utilisez Identity, il configure l’authentification basée sur les cookies comme schéma par défaut.
Dans l’authentification web, il existe généralement jusqu’à cinq actions qui peuvent être effectuées au cours de l’authentification d’un client d’un système. Ces règles sont les suivantes :
- S’authentifier. Utilisez les informations fournies par le client pour créer une identité à utiliser dans l’application.
- Défi. Cette action est utilisée pour exiger que le client s’identifie lui-même.
- Interdire. Informez le client qu’il n’est pas autorisé à effectuer une action.
- Connectez-vous. Conservez le client existant d’une certaine façon.
- Déconnexion. Retirez le client de l’état de persistance.
Il existe plusieurs techniques courantes pour effectuer l’authentification dans les applications web. Il s’agit de schémas. Un schéma donné définit des actions pour certaines ou toutes les options ci-dessus. Certains schémas prennent uniquement en charge un sous-ensemble d’actions et peuvent nécessiter un schéma distinct pour effectuer ceux qu’il ne prend pas en charge. Par exemple, le schéma OpenId-Connect (OIDC) ne prend pas en charge la connexion ou la déconnexion, mais est généralement configuré pour utiliser l’authentification cookie pour cette persistance.
Dans votre application ASP.NET Core, vous pouvez configurer un DefaultAuthenticateScheme et des schémas spécifiques facultatifs pour chacune des actions décrites ci-dessus. Par exemple : DefaultChallengeScheme et DefaultForbidScheme. L’appel AddIdentity configure un certain nombre d’aspects de l’application et ajoute de nombreux services requis. Il inclut également cet appel pour configurer le schéma d’authentification :
builder.Services.AddAuthentication(options =>
{
options.DefaultAuthenticateScheme = IdentityConstants.ApplicationScheme;
options.DefaultChallengeScheme = IdentityConstants.ApplicationScheme;
options.DefaultSignInScheme = IdentityConstants.ExternalScheme;
});
Ces schémas utilisent des cookies pour la persistance et la redirection vers les pages de connexion pour l’authentification par défaut. Ces schémas sont appropriés pour les applications web qui interagissent avec les utilisateurs via des navigateurs web, mais qui ne sont pas recommandés pour les API. Au lieu de cela, les API utilisent généralement une autre forme d’authentification, comme les jetons du porteur JWT.
Les API web sont consommées par le code, comme HttpClient dans les applications .NET et les types équivalents dans d’autres frameworks. Ces clients attendent une réponse utilisable à partir d’un appel d’API ou un code d’état indiquant le problème qui s’est produit, le cas échéant. Ces clients n’interagissent pas via un navigateur et n’affichent ni n’interagissent avec un code HTML qu’une API peut retourner. Par conséquent, il n’est pas approprié pour les points de terminaison d’API de rediriger leurs clients vers des pages de connexion s’ils ne sont pas authentifiés. Un autre schéma est plus approprié.
Pour configurer l’authentification pour les API, vous pouvez configurer l’authentification comme suit, utilisée par le PublicApi projet dans l’application de référence eShopOnWeb :
builder.Services
.AddAuthentication(config =>
{
config.DefaultScheme = JwtBearerDefaults.AuthenticationScheme;
})
.AddJwtBearer(config =>
{
config.RequireHttpsMetadata = false;
config.SaveToken = true;
config.TokenValidationParameters = new TokenValidationParameters
{
ValidateIssuerSigningKey = true,
IssuerSigningKey = new SymmetricSecurityKey(key),
ValidateIssuer = false,
ValidateAudience = false
};
});
Bien qu’il soit possible de configurer plusieurs schémas d’authentification différents au sein d’un seul projet, il est beaucoup plus simple de configurer un schéma par défaut unique. Pour cette raison, entre autres, l’application de référence eShopOnWeb sépare ses API en créant un projet à part PublicApi, distinct du projet principal Web qui inclut les vues de l’application et les pages Razor.
Authentification dans les Blazor applications
Blazor Les applications serveur peuvent tirer parti des mêmes fonctionnalités d’authentification que toutes les autres applications ASP.NET Core. Blazor WebAssembly les applications ne peuvent pas utiliser les fournisseurs d’identité et d’authentification intégrés, toutefois, car elles s’exécutent dans le navigateur. Blazor WebAssembly les applications peuvent stocker l’état d’authentification utilisateur localement et accéder aux revendications pour déterminer quelles actions les utilisateurs doivent être en mesure d’effectuer. Toutefois, toutes les vérifications d’authentification et d’autorisation doivent être effectuées sur le serveur, quelle que soit la logique implémentée à l’intérieur de l’application BlazorWebAssembly , car les utilisateurs peuvent facilement contourner l’application et interagir directement avec les API.
Références – Authentification
- Actions d’authentification et valeurs par défaut
https://stackoverflow.com/a/52493428- Authentification et autorisation pour les SPA
https://learn.microsoft.com/aspnet/core/security/authentication/identity-api-authorization- ASP.NET Core Blazor l’authentification et l’autorisation
https://learn.microsoft.com/aspnet/core/blazor/security/- Sécurité : Authentification et autorisation dans ASP.NET Web Forms et Blazor
https://learn.microsoft.com/dotnet/architecture/blazor-for-web-forms-developers/security-authentication-authorization
Autorisation
La forme d’autorisation la plus simple implique de restreindre l’accès aux utilisateurs anonymes. Cette fonctionnalité peut être obtenue en appliquant l’attribut [Authorize] à certains contrôleurs ou actions. Si des rôles sont utilisés, l’attribut peut être étendu pour restreindre l’accès aux utilisateurs qui appartiennent à certains rôles, comme indiqué :
[Authorize(Roles = "HRManager,Finance")]
public class SalaryController : Controller
{
}
Dans ce cas, les utilisateurs appartenant aux rôles HRManager ou Finance (ou les deux) auraient accès au contrôleur de salaire. Pour exiger qu’un utilisateur appartienne à plusieurs rôles (pas seulement l’un de plusieurs), vous pouvez appliquer l’attribut plusieurs fois, en spécifiant un rôle obligatoire à chaque fois.
La spécification de certains ensembles de rôles en tant que chaînes dans de nombreux contrôleurs et actions différents peut entraîner une répétition indésirable. Au minimum, définissez des constantes pour ces littéraux de chaîne et utilisez les constantes partout où vous devez spécifier la chaîne. Vous pouvez également configurer des stratégies d’autorisation, qui encapsulent des règles d’autorisation, puis spécifier la stratégie au lieu de rôles individuels lors de l’application de l’attribut [Authorize] :
[Authorize(Policy = "CanViewPrivateReport")]
public IActionResult ExecutiveSalaryReport()
{
return View();
}
À l’aide de politiques de cette manière, vous pouvez séparer les types d’actions qui sont restreintes des rôles ou règles spécifiques qui leur sont applicables. Plus tard, si vous créez un rôle qui doit avoir accès à certaines ressources, vous pouvez simplement mettre à jour une stratégie, plutôt que mettre à jour chaque liste de rôles sur chaque [Authorize] attribut.
Réclamations
Les revendications sont des paires nom/valeur qui représentent les propriétés d’un utilisateur authentifié. Par exemple, vous pouvez stocker le numéro d’employé des utilisateurs en tant que revendication. Les revendications peuvent ensuite être utilisées dans le cadre de stratégies d’autorisation. Vous pouvez créer une stratégie appelée « EmployeeOnly » qui nécessite l’existence d’une revendication appelée "EmployeeNumber", comme illustré dans cet exemple :
public void ConfigureServices(IServiceCollection services)
{
services.AddMvc();
services.AddAuthorization(options =>
{
options.AddPolicy("EmployeeOnly", policy => policy.RequireClaim("EmployeeNumber"));
});
}
Cette stratégie peut ensuite être utilisée avec l’attribut [Authorize] pour protéger n’importe quel contrôleur et/ou action, comme décrit ci-dessus.
Sécurisation des API web
La plupart des API web doivent implémenter un système d’authentification basé sur des jetons. L’authentification par jeton est sans état et conçue pour être évolutive. Dans un système d’authentification basé sur des jetons, le client doit d’abord s’authentifier auprès du fournisseur d’authentification. En cas de réussite, le client reçoit un jeton, qui est simplement une chaîne de caractères cryptographiquement significative. Le format le plus courant pour les jetons est JSON Web Token ou JWT (souvent prononcé « jot »). Lorsque le client doit ensuite émettre une demande à une API, il ajoute ce jeton en tant qu’en-tête à la demande. Le serveur valide ensuite le jeton trouvé dans l’en-tête de demande avant de terminer la demande. La figure 7-4 illustre ce processus.
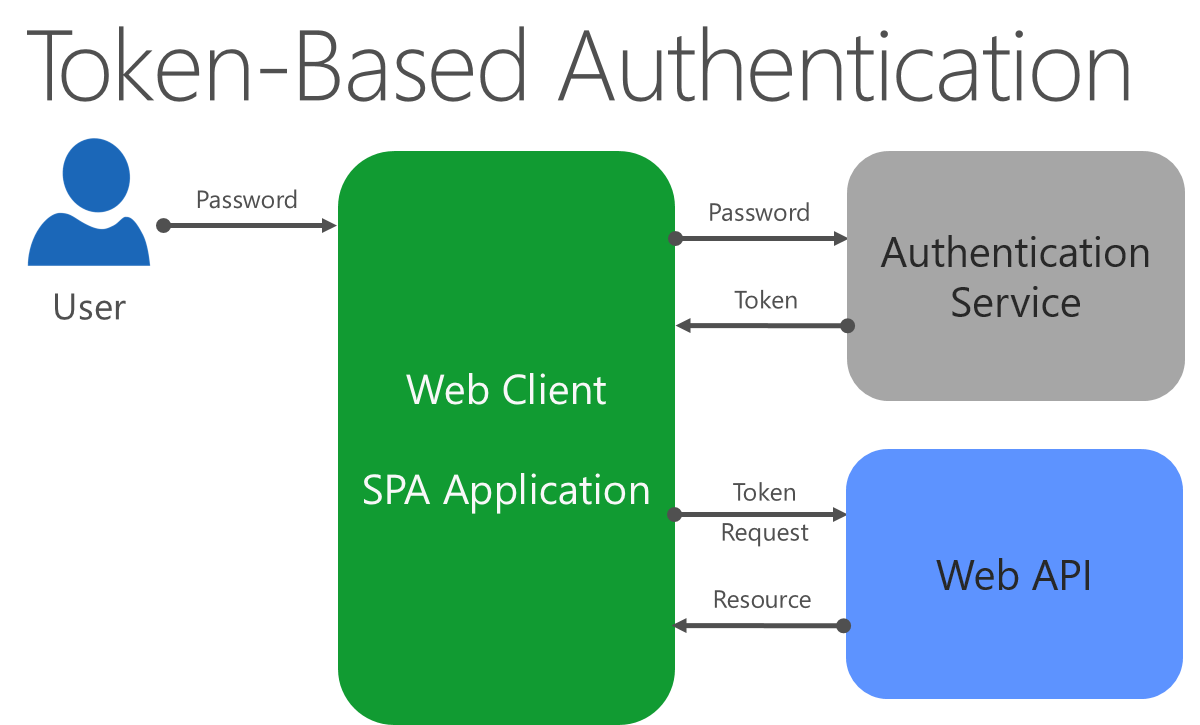
Figure 7-4. Authentification basée sur des jetons pour les API web.
Vous pouvez créer votre propre service d’authentification, l’intégrer à Azure AD et OAuth ou implémenter un service à l’aide d’un outil open source comme IdentityServer.
Les jetons JWT peuvent incorporer des revendications sur l’utilisateur, qui peuvent être lues sur le client ou le serveur. Vous pouvez utiliser un outil comme jwt.io pour afficher le contenu d’un jeton JWT. Ne stockez pas de données sensibles telles que des mots de passe ou des clés dans des jetons JTW, car leur contenu est facilement lu.
Lorsque vous utilisez des jetons JWT avec spa ou BlazorWebAssembly applications, vous devez stocker le jeton quelque part sur le client, puis l’ajouter à chaque appel d’API. Cette activité est généralement effectuée en tant qu’en-tête, comme le montre le code suivant :
// AuthService.cs in BlazorAdmin project of eShopOnWeb
private async Task SetAuthorizationHeader()
{
var token = await GetToken();
_httpClient.DefaultRequestHeaders.Authorization = new AuthenticationHeaderValue("Bearer", token);
}
Après avoir appelé la méthode ci-dessus, les requêtes effectuées avec le _httpClient jeton auront le jeton incorporé dans les en-têtes de la requête, ce qui permet à l’API côté serveur d’authentifier et d’autoriser la requête.
Sécurité personnalisée
Avertissement
En règle générale, évitez d’implémenter vos propres implémentations de sécurité personnalisées.
Soyez particulièrement vigilant quant au « développement de votre propre » implémentation du chiffrement, de l’appartenance de l’utilisateur et du système de génération de jetons. Il existe de nombreuses alternatives commerciales et open source disponibles, ce qui aura presque certainement une meilleure sécurité qu’une implémentation personnalisée.
Références – Sécurité
- Vue d’ensemble de Security Docs
https://learn.microsoft.com/aspnet/core/security/- Application du protocole SSL dans une application ASP.NET Core
https://learn.microsoft.com/aspnet/core/security/enforcing-ssl- Présentation de l’identité
https://learn.microsoft.com/aspnet/core/security/authentication/identity- Présentation de l’autorisation
https://learn.microsoft.com/aspnet/core/security/authorization/introduction- Authentification et autorisation pour API Apps dans Azure App Service
https://learn.microsoft.com/azure/app-service-api/app-service-api-authentication- Serveur d’identité
https://github.com/IdentityServer
Communication du client
En plus de servir des pages et de répondre aux demandes de données via des API web, ASP.NET applications Core peuvent communiquer directement avec les clients connectés. Cette communication sortante peut utiliser une variété de technologies de transport, les plus courantes étant Les WebSockets. ASP.NET Core SignalR est une bibliothèque qui facilite l’ajout de fonctionnalités de communication serveur à client en temps réel à vos applications. SignalR prend en charge une variété de technologies de transport, notamment WebSockets, et extrait la plupart des détails de l’implémentation du développeur.
La communication cliente en temps réel, qu’il s’agisse d’utiliser des WebSockets directement ou d’autres techniques, est utile dans divers scénarios d’application. Voici quelques exemples :
Applications de salle de conversation en direct
Surveillance des applications
Mises à jour de la progression des travaux
Avis
Applications de formulaires interactifs
Lors de la génération de la communication cliente dans vos applications, il existe généralement deux composants :
Gestionnaire de connexions côté serveur (SignalR Hub, WebSocketManager WebSocketHandler)
Bibliothèque côté client
Les clients ne sont pas limités aux navigateurs : les applications mobiles, les applications console et d’autres applications natives peuvent également communiquer à l’aide de SignalR/WebSockets. Le programme simple suivant fait écho à tout le contenu envoyé à une application de conversation à la console, dans le cadre d’un exemple d’application WebSocketManager :
public class Program
{
private static Connection _connection;
public static void Main(string[] args)
{
StartConnectionAsync();
_connection.On("receiveMessage", (arguments) =>
{
Console.WriteLine($"{arguments[0]} said: {arguments[1]}");
});
Console.ReadLine();
StopConnectionAsync();
}
public static async Task StartConnectionAsync()
{
_connection = new Connection();
await _connection.StartConnectionAsync("ws://localhost:65110/chat");
}
public static async Task StopConnectionAsync()
{
await _connection.StopConnectionAsync();
}
}
Envisagez les façons dont vos applications communiquent directement avec les applications clientes et déterminez si la communication en temps réel améliore l’expérience utilisateur de votre application.
Références – Communication du client
- ASP.NET Core SignalR
https://github.com/dotnet/aspnetcore/tree/main/src/SignalR- Gestionnaire WebSocket
https://github.com/radu-matei/websocket-manager
Conception pilotée par le domaine : devez-vous l’appliquer ?
Domain-Driven Design (DDD) est une approche agile de la création de logiciels qui met l’accent sur le domaine métier. Il met l'accent sur la communication et l'interaction avec les experts du domaine professionnel qui peuvent expliquer aux développeurs comment le système fonctionne en réalité. Par exemple, si vous créez un système qui gère les transactions boursières, votre expert de domaine peut être un courtier en actions expérimenté. DDD est conçu pour résoudre les problèmes métier volumineux et complexes et n’est souvent pas approprié pour les applications plus petites, plus simples, car l’investissement dans la compréhension et la modélisation du domaine ne vaut pas la peine.
Lors de la création de logiciels à la suite d’une approche DDD, votre équipe (y compris les parties prenantes et contributeurs non techniques) doit développer un langage omniprésent pour l’espace de problème. Autrement dit, la même terminologie doit être utilisée pour le concept réel modélisé, l’équivalent logiciel et toutes les structures susceptibles d’exister pour conserver le concept (par exemple, les tables de base de données). Ainsi, les concepts décrits dans le langage omniprésent doivent constituer la base de votre modèle de domaine.
Votre modèle de domaine comprend des objets qui interagissent les uns avec les autres pour représenter le comportement du système. Ces objets peuvent se trouver dans les catégories suivantes :
Entités, qui représentent des objets avec un thread d’identité. Les entités sont généralement stockées dans la persistance avec une clé par laquelle elles peuvent être récupérées ultérieurement.
Agrégats, qui représentent des groupes d’objets qui doivent être conservés en tant qu’unité.
Objets valeur, qui représentent des concepts qui peuvent être comparés en fonction de la somme de leurs valeurs de propriété. Par exemple, DateRange se compose d’une date de début et de fin.
Événements de domaine, qui représentent les choses qui se produisent dans le système qui sont intéressants pour d’autres parties du système.
Un modèle de domaine DDD doit encapsuler un comportement complexe au sein du modèle. Les entités, en particulier, ne doivent pas simplement être des collections de propriétés. Lorsque le modèle de domaine n’a pas de comportement et représente simplement l’état du système, il est dit qu’il s’agit d’un modèle anémique, qui n’est pas souhaitable dans DDD.
En plus de ces types de modèles, DDD utilise généralement une variété de modèles :
Référentiel, pour extraire les détails de persistance.
Factory, pour encapsuler la création d’objets complexes.
Services, pour encapsuler des détails d’implémentation complexes et/ou de comportement de l’infrastructure.
Commande, pour découpler les commandes émettrices et l’exécution de la commande elle-même.
Spécification, pour encapsuler les détails de la requête.
DDD recommande également l’utilisation de l’architecture propre décrite précédemment, ce qui permet un couplage libre, l’encapsulation et le code qui peuvent facilement être vérifiés à l’aide de tests unitaires.
Quand recourir à DDD ?
DDD convient parfaitement aux grandes applications avec une complexité métier importante (et pas seulement technique). L’application doit nécessiter la connaissance des experts du domaine. Il doit y avoir un comportement significatif dans le modèle de domaine lui-même, représentant des règles d’entreprise et des interactions au-delà du simple stockage et de la récupération de l’état actuel de différents enregistrements à partir de magasins de données.
Quand ne devez-vous pas appliquer le DDD
DDD implique des investissements dans la modélisation, l’architecture et la communication qui peuvent ne pas être justifiées pour les applications ou applications plus petites qui sont essentiellement simplement CRUD (créer/lire/mettre à jour/supprimer). Si vous choisissez d’approcher votre application après DDD, mais que votre domaine a un modèle anémique sans comportement, vous devrez peut-être repenser votre approche. Votre application n’a peut-être pas besoin de DDD ou vous avez peut-être besoin d’aide pour refactoriser votre application pour encapsuler la logique métier dans le modèle de domaine, plutôt que dans votre base de données ou votre interface utilisateur.
Une approche hybride consisterait uniquement à utiliser DDD pour les zones transactionnelles ou plus complexes de l’application, mais pas pour des parties CRUD ou lecture seule plus simples de l’application. Par exemple, vous n’avez pas besoin des contraintes d’un agrégat si vous interrogez des données pour afficher un rapport ou visualiser des données pour un tableau de bord. Il est parfaitement acceptable d’avoir un modèle de lecture distinct et plus simple pour ces exigences.
Références – DDD
- DDD en anglais brut (Réponse StackOverflow)
https://stackoverflow.com/questions/1222392/can-someone-explain-domain-driven-design-ddd-in-plain-english-please/1222488#1222488
Déploiement
Il existe quelques étapes impliquées dans le processus de déploiement de votre application ASP.NET Core, quel que soit l’emplacement où elle sera hébergée. La première étape consiste à publier l’application, qui peut être effectuée à l’aide de la dotnet publish commande CLI. Cette étape compile l’application et place tous les fichiers nécessaires pour exécuter l’application dans un dossier désigné. Lorsque vous déployez à partir de Visual Studio, cette étape est effectuée automatiquement. Le dossier de publication contient des fichiers .exe et .dll pour l’application et ses dépendances. Une application autonome inclut également une version du runtime .NET. ASP.NET applications principales incluent également des fichiers de configuration, des ressources clientes statiques et des vues MVC.
ASP.NET Applications principales sont des applications console qui doivent être démarrées lors du démarrage du serveur et redémarrées si l’application (ou le serveur) se bloque. Un gestionnaire de processus peut être utilisé pour automatiser ce processus. Les gestionnaires de processus les plus courants pour ASP.NET Core sont Nginx et Apache sur Linux et IIS ou le service Windows sur Windows.
En plus d’un gestionnaire de processus, ASP.NET applications Core peuvent utiliser un serveur proxy inverse. Un serveur proxy inverse reçoit des requêtes HTTP à partir d’Internet et les transfère à Kestrel après une gestion préliminaire. Les serveurs proxy inverses fournissent une couche de sécurité pour l’application. Kestrel ne prend pas également en charge l’hébergement de plusieurs applications sur le même port, de sorte que les techniques telles que les en-têtes d’hôte ne peuvent pas être utilisées avec elle pour permettre l’hébergement de plusieurs applications sur le même port et l’adresse IP.

Figure 7-5. ASP.NET hébergé dans Kestrel derrière un serveur proxy inverse
Un autre scénario dans lequel un proxy inverse peut être utile est de sécuriser plusieurs applications à l’aide de SSL/HTTPS. Dans ce cas, seul le proxy inverse doit avoir configuré SSL. La communication entre le serveur proxy inverse et Kestrel peut se produire sur HTTP, comme illustré dans la figure 7-6.

Figure 7-6. ASP.NET hébergé derrière un serveur proxy inverse sécurisé par HTTPS
Une approche de plus en plus populaire consiste à héberger votre application ASP.NET Core dans un conteneur Docker, qui peut ensuite être hébergée localement ou déployée sur Azure pour l’hébergement cloud. Le conteneur Docker peut contenir votre code d’application, s’exécutant sur Kestrel et être déployé derrière un serveur proxy inverse, comme indiqué ci-dessus.
Si vous hébergez votre application sur Azure, vous pouvez utiliser Microsoft Azure Application Gateway comme appliance virtuelle dédiée pour fournir plusieurs services. En plus d’agir comme proxy inverse pour des applications individuelles, Application Gateway peut également offrir les fonctionnalités suivantes :
Équilibrage de charge HTTP
Déchargement SSL (SSL uniquement à Internet)
SSL de bout en bout
Routage multisite (consolider jusqu’à 20 sites sur une seule application Gateway)
Pare-feu d’application web
Prise en charge de WebSocket
Diagnostic avancé
En savoir plus sur les options de déploiement Azure dans le chapitre 10.
Références – Déploiement
- Vue d’ensemble de l’hébergement et du déploiement
https://learn.microsoft.com/aspnet/core/publishing/- Quand utiliser Kestrel avec un proxy inverse
https://learn.microsoft.com/aspnet/core/fundamentals/servers/kestrel#when-to-use-kestrel-with-a-reverse-proxy- Héberger des applications ASP.NET Core dans Docker
https://learn.microsoft.com/aspnet/core/publishing/docker- Présentation d’Azure Application Gateway
https://learn.microsoft.com/azure/application-gateway/application-gateway-introduction
Collaborez avec nous sur GitHub
La source de ce contenu se trouve sur GitHub, où vous pouvez également créer et examiner des problèmes et des demandes de tirage. Pour plus d’informations, consultez notre guide du contributeur.