Notes
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Cet article fournit une vue d’ensemble des types qui aident à lire les données qui s’exécutent sur plusieurs mémoires tampons. Ils sont principalement utilisés pour prendre en charge des objets PipeReader.
IBufferWriter<T>
System.Buffers.IBufferWriter<T> est un contrat pour l’écriture en mémoire tampon synchrone. Au niveau le plus bas, l’interface :
- Est de base et n’est pas difficile à utiliser.
- Permet l’accès à un Memory<T> ou un .Span<T> Le
Memory<T>ou leSpan<T>est accessible en écriture et vous pouvez déterminer le nombre d’élémentsTqui y ont été écrits.
void WriteHello(IBufferWriter<byte> writer)
{
// Request at least 5 bytes.
Span<byte> span = writer.GetSpan(5);
ReadOnlySpan<char> helloSpan = "Hello".AsSpan();
int written = Encoding.ASCII.GetBytes(helloSpan, span);
// Tell the writer how many bytes were written.
writer.Advance(written);
}
La méthode précédente :
- Demande un buffer d’au moins 5 octets de
IBufferWriter<byte>en utilisantGetSpan(5). - Écrit des octets pour la chaîne ASCII « Hello » dans le
Span<byte>retourné. - Appels IBufferWriter<T> pour indiquer le nombre d’octets écrits dans la mémoire tampon.
Cette méthode d’écriture utilise la Memory<T>/Span<T> mémoire tampon fournie par le IBufferWriter<T>. Vous pouvez également utiliser la Write méthode d’extension pour copier une mémoire tampon existante dans le IBufferWriter<T>.
Write effectue le travail d’appeler GetSpan/Advance de manière appropriée, donc il n’est pas nécessaire d’appeler Advance après avoir écrit.
void WriteHello(IBufferWriter<byte> writer)
{
byte[] helloBytes = Encoding.ASCII.GetBytes("Hello");
// Write helloBytes to the writer. There's no need to call Advance here
// since Write calls Advance.
writer.Write(helloBytes);
}
ArrayBufferWriter<T>est une implémentation de IBufferWriter<T> dont le magasin de sauvegarde est un tableau contigu unique.
Problèmes courants liés à IBufferWriter
-
GetSpanetGetMemoryrenvoyer une mémoire tampon avec au moins la quantité de mémoire demandée. Ne supposez pas exactement les tailles de mémoire tampon. - Il n’existe aucune garantie que les appels successifs retournent la même mémoire tampon ou une mémoire tampon de même taille.
- Une nouvelle mémoire tampon doit être demandée après l’appel
Advancepour continuer à écrire plus de données. Une mémoire tampon précédemment acquise ne peut pas être écrite aprèsAdvanceavoir été appelée.
ReadOnlySequence<T>
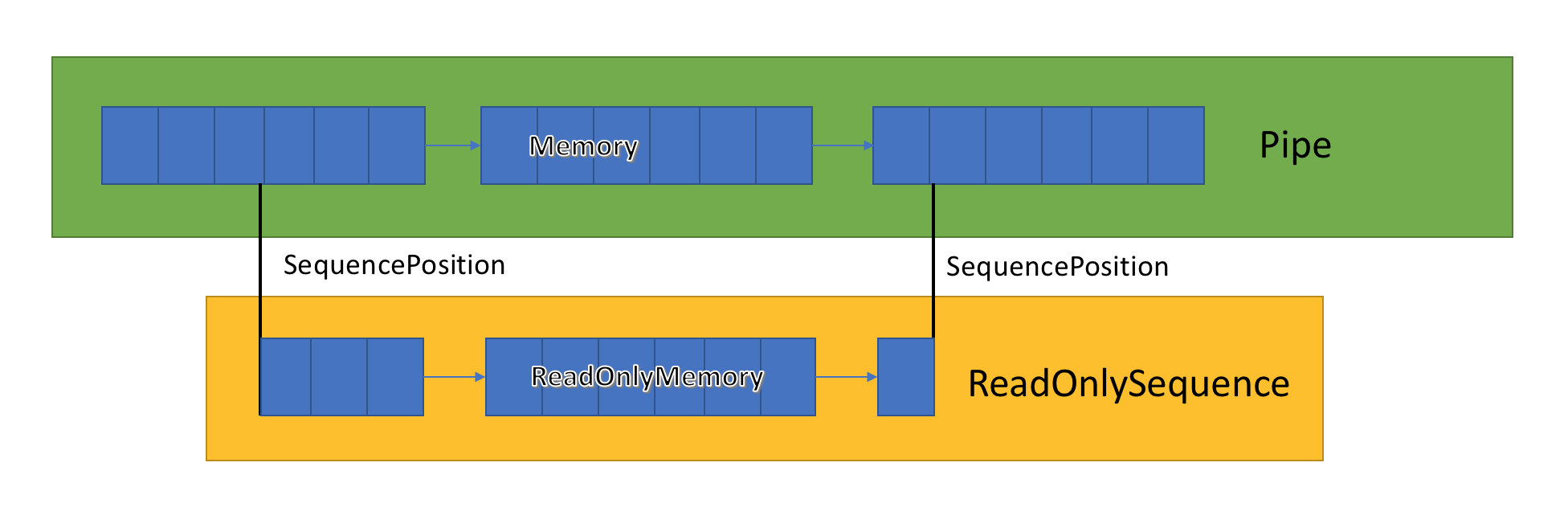
ReadOnlySequence<T> est un struct qui peut représenter une séquence contiguë ou non contiguë de T. Il peut être construit à partir des points suivants :
- Un
T[] - Un
ReadOnlyMemory<T> - Une paire de nœuds de liste liée ReadOnlySequenceSegment<T> et un index pour représenter la position de début et de fin de la séquence.
La troisième représentation est la plus intéressante, car elle a des implications sur les performances sur diverses opérations sur les ReadOnlySequence<T>:
| Représentation | Opération | Complexité |
|---|---|---|
T[]/ReadOnlyMemory<T> |
Length |
O(1) |
T[]/ReadOnlyMemory<T> |
GetPosition(long) |
O(1) |
T[]/ReadOnlyMemory<T> |
Slice(int, int) |
O(1) |
T[]/ReadOnlyMemory<T> |
Slice(SequencePosition, SequencePosition) |
O(1) |
ReadOnlySequenceSegment<T> |
Length |
O(1) |
ReadOnlySequenceSegment<T> |
GetPosition(long) |
O(number of segments) |
ReadOnlySequenceSegment<T> |
Slice(int, int) |
O(number of segments) |
ReadOnlySequenceSegment<T> |
Slice(SequencePosition, SequencePosition) |
O(1) |
En raison de cette représentation mixte, les ReadOnlySequence<T> présentent les index sous la forme de SequencePosition au lieu d’un entier. Une SequencePosition :
- Valeur opaque qui représente un index dans le
ReadOnlySequence<T>d'où il provient. - Se compose de deux parties, d’un entier et d’un objet. Ce que ces deux valeurs représentent sont liées à l’implémentation de
ReadOnlySequence<T>.
Accéder aux données
Les données de ReadOnlySequence<T> sont exposées comme un énumérable de ReadOnlyMemory<T>. L’énumération de chacun des segments peut être effectuée en utilisant une instruction foreach de base :
long FindIndexOf(in ReadOnlySequence<byte> buffer, byte data)
{
long position = 0;
foreach (ReadOnlyMemory<byte> segment in buffer)
{
ReadOnlySpan<byte> span = segment.Span;
var index = span.IndexOf(data);
if (index != -1)
{
return position + index;
}
position += span.Length;
}
return -1;
}
La méthode précédante recherche chaque segment pour un octet spécifique. Si vous devez effectuer le suivi de chaque segment SequencePosition, il est plus approprié d'utiliser ReadOnlySequence<T>.TryGet. L’exemple suivant modifie le code précédent pour retourner un SequencePosition entier au lieu d’un entier. Retourner une SequencePosition a l’avantage de permettre à l’appelant d’éviter de devoir parcourir une deuxième fois la séquence pour obtenir les données à un index spécifique.
SequencePosition? FindIndexOf(in ReadOnlySequence<byte> buffer, byte data)
{
SequencePosition position = buffer.Start;
SequencePosition result = position;
while (buffer.TryGet(ref position, out ReadOnlyMemory<byte> segment))
{
ReadOnlySpan<byte> span = segment.Span;
var index = span.IndexOf(data);
if (index != -1)
{
return buffer.GetPosition(index, result);
}
result = position;
}
return null;
}
La combinaison de SequencePosition et TryGet agit comme un énumérateur. Le champ de position est modifié au début de chaque itération afin de se placer au début de chaque segment dans le ReadOnlySequence<T>.
La méthode précédente existe en tant que méthode d’extension sur ReadOnlySequence<T>.
PositionOf peut être utilisé pour simplifier le code précédent :
SequencePosition? FindIndexOf(in ReadOnlySequence<byte> buffer, byte data) => buffer.PositionOf(data);
Traiter une ReadOnlySequence<T>
Le traitement d’un élément ReadOnlySequence<T> peut être difficile, car les données peuvent être fractionnées sur plusieurs segments dans la séquence. Pour obtenir les meilleures performances, fractionnez le code en deux chemins :
- Un chemin rapide qui traite le cas d’un seul segment.
- Chemin lent qui traite de la répartition des données entre les segments.
Il existe quelques approches qui peuvent être utilisées pour traiter les données dans des séquences multi segmentées :
- Utilisez le
SequenceReader<T>. - Analysez les données segment par segment, en gardant une trace de
SequencePositionet de l'index à l'intérieur du segment analysé. Cela évite les allocations inutiles, mais peut être inefficace, en particulier pour les petites mémoires tampons. - Copier la
ReadOnlySequence<T>dans un tableau contigu et le traiter comme une même mémoire tampon :- Si la taille du fichier
ReadOnlySequence<T>est petite, il peut être raisonnable de copier les données dans une mémoire tampon allouée par pile à l’aide de l’opérateur stackalloc . - Copiez le
ReadOnlySequence<T>dans un tableau mis en pool à l'aide de ArrayPool<T>.Shared. - Utilisez
ReadOnlySequence<T>.ToArray(). Ceci n’est pas recommandé dans les chemins très sollicités, car cela alloue un nouveauT[]sur le tas.
- Si la taille du fichier
Les exemples suivants illustrent certains cas courants de traitement ReadOnlySequence<byte>:
Traiter les données binaires
L’exemple suivant analyse la longueur d’un entier Big Endian sur 4 octets à partir du début de la ReadOnlySequence<byte>.
bool TryParseHeaderLength(ref ReadOnlySequence<byte> buffer, out int length)
{
// If there's not enough space, the length can't be obtained.
if (buffer.Length < 4)
{
length = 0;
return false;
}
// Grab the first 4 bytes of the buffer.
var lengthSlice = buffer.Slice(buffer.Start, 4);
if (lengthSlice.IsSingleSegment)
{
// Fast path since it's a single segment.
length = BinaryPrimitives.ReadInt32BigEndian(lengthSlice.First.Span);
}
else
{
// There are 4 bytes split across multiple segments. Since it's so small, it
// can be copied to a stack allocated buffer. This avoids a heap allocation.
Span<byte> stackBuffer = stackalloc byte[4];
lengthSlice.CopyTo(stackBuffer);
length = BinaryPrimitives.ReadInt32BigEndian(stackBuffer);
}
// Move the buffer 4 bytes ahead.
buffer = buffer.Slice(lengthSlice.End);
return true;
}
Traiter les données de texte
L’exemple suivant :
- Recherche le premier saut de ligne (
\r\n) dans laReadOnlySequence<byte>et le retourne via le paramètre de sortie « line ». - Supprime cette ligne, en excluant le
\r\nde la mémoire tampon d’entrée.
static bool TryParseLine(ref ReadOnlySequence<byte> buffer, out ReadOnlySequence<byte> line)
{
SequencePosition position = buffer.Start;
SequencePosition previous = position;
var index = -1;
line = default;
while (buffer.TryGet(ref position, out ReadOnlyMemory<byte> segment))
{
ReadOnlySpan<byte> span = segment.Span;
// Look for \r in the current segment.
index = span.IndexOf((byte)'\r');
if (index != -1)
{
// Check next segment for \n.
if (index + 1 >= span.Length)
{
var next = position;
if (!buffer.TryGet(ref next, out ReadOnlyMemory<byte> nextSegment))
{
// You're at the end of the sequence.
return false;
}
else if (nextSegment.Span[0] == (byte)'\n')
{
// A match was found.
break;
}
}
// Check the current segment of \n.
else if (span[index + 1] == (byte)'\n')
{
// It was found.
break;
}
}
previous = position;
}
if (index != -1)
{
// Get the position just before the \r\n.
var delimeter = buffer.GetPosition(index, previous);
// Slice the line (excluding \r\n).
line = buffer.Slice(buffer.Start, delimeter);
// Slice the buffer to get the remaining data after the line.
buffer = buffer.Slice(buffer.GetPosition(2, delimeter));
return true;
}
return false;
}
Segments vides
Il est valide de stocker des segments vides à l’intérieur d’un ReadOnlySequence<T>. Des segments vides peuvent se produire lors de l’énumération explicite des segments :
static void EmptySegments()
{
// This logic creates a ReadOnlySequence<byte> with 4 segments,
// two of which are empty.
var first = new BufferSegment(new byte[0]);
var last = first.Append(new byte[] { 97 })
.Append(new byte[0]).Append(new byte[] { 98 });
// Construct the ReadOnlySequence<byte> from the linked list segments.
var data = new ReadOnlySequence<byte>(first, 0, last, 1);
// Slice using numbers.
var sequence1 = data.Slice(0, 2);
// Slice using SequencePosition pointing at the empty segment.
var sequence2 = data.Slice(data.Start, 2);
Console.WriteLine($"sequence1.Length={sequence1.Length}"); // sequence1.Length=2
Console.WriteLine($"sequence2.Length={sequence2.Length}"); // sequence2.Length=2
// sequence1.FirstSpan.Length=1
Console.WriteLine($"sequence1.FirstSpan.Length={sequence1.FirstSpan.Length}");
// Slicing using SequencePosition will Slice the ReadOnlySequence<byte> directly
// on the empty segment!
// sequence2.FirstSpan.Length=0
Console.WriteLine($"sequence2.FirstSpan.Length={sequence2.FirstSpan.Length}");
// The following code prints 0, 1, 0, 1.
SequencePosition position = data.Start;
while (data.TryGet(ref position, out ReadOnlyMemory<byte> memory))
{
Console.WriteLine(memory.Length);
}
}
class BufferSegment : ReadOnlySequenceSegment<byte>
{
public BufferSegment(Memory<byte> memory)
{
Memory = memory;
}
public BufferSegment Append(Memory<byte> memory)
{
var segment = new BufferSegment(memory)
{
RunningIndex = RunningIndex + Memory.Length
};
Next = segment;
return segment;
}
}
Le code précédent crée un ReadOnlySequence<byte> segment avec des segments vides et montre comment ces segments vides affectent les différentes API :
-
ReadOnlySequence<T>.Sliceavec unSequencePositionpointant vers un segment vide préserve ce segment. -
ReadOnlySequence<T>.Sliceavec un entier ignore les segments vides. - L'énumération de
ReadOnlySequence<T>énumère les segments vides.
Problèmes potentiels avec ReadOnlySequence<T> et SequencePosition
Il existe plusieurs résultats inhabituels lors de la gestion d’un ReadOnlySequence<T>/SequencePosition par rapport à un ReadOnlySpan<T>/ReadOnlyMemory<T>/T[]/int normal :
-
SequencePositionest un marqueur de position pour une position spécifiqueReadOnlySequence<T>, et non une position absolue. Étant donné qu’il est relatif à un élément spécifiqueReadOnlySequence<T>, il n’a pas de signification s’il est utilisé en dehors de l’endroitReadOnlySequence<T>où il provient. - Vous ne pouvez pas effectuer des opérations arithmétiques sur
SequencePositionsans laReadOnlySequence<T>. Cela signifie que faire des opérations de base commeposition++doit être écrit comme ceci :position = ReadOnlySequence<T>.GetPosition(1, position). -
GetPosition(long)ne prend pas en charge les index négatifs. Cela signifie qu’il est impossible d’obtenir l’avant-dernier caractère sans parcourir tous les segments. - Deux
SequencePositionne peuvent pas être comparés, ce qui rend difficile à :- Sachez si une position est supérieure ou inférieure à une autre position.
- Écrivez des algorithmes d’analyse.
-
ReadOnlySequence<T>est plus grand qu’une référence d’objet et, dans la mesure du possible, doit être passée par in ou ref. Passer parReadOnlySequence<T>,inourefpermet de réduire le nombre de copies du struct. - Segments vides :
- Sont valides dans une
ReadOnlySequence<T>. - Peuvent apparaître lors de l’itération en utilisant la méthode
ReadOnlySequence<T>.TryGet. - Peuvent fractionner la séquence en utilisant la méthode
ReadOnlySequence<T>.Slice()avec des objetsSequencePosition.
- Sont valides dans une
SequenceReader<T>
- Nouveau type introduit dans .NET Core 3.0 pour simplifier le traitement d’un
ReadOnlySequence<T>. - Unifie les différences entre un segment
ReadOnlySequence<T>unique et plusieurs segmentsReadOnlySequence<T>. - Fournit des assistances pour lire des données binaires et textuelles (
byteetchar) qui peuvent ou ne pas être fractionnées entre les segments.
Il existe des méthodes intégrées pour traiter les données binaires et délimitées. La section suivante montre à quoi ressemblent ces mêmes méthodes avec le SequenceReader<T>.
Accéder aux données
SequenceReader<T> a des méthodes pour énumérer des données directement à l’intérieur de ReadOnlySequence<T>. Le code suivant est un exemple de traitement d’un ReadOnlySequence<byte>byte à la fois :
while (reader.TryRead(out byte b))
{
Process(b);
}
L'CurrentSpan expose le Span du segment actuel, ce qui est similaire à ce qui était fait manuellement dans la méthode.
Utiliser une position
Le code suivant est un exemple d’implémentation utilisant FindIndexOf et SequenceReader<T>.
SequencePosition? FindIndexOf(in ReadOnlySequence<byte> buffer, byte data)
{
var reader = new SequenceReader<byte>(buffer);
while (!reader.End)
{
// Search for the byte in the current span.
var index = reader.CurrentSpan.IndexOf(data);
if (index != -1)
{
// It was found, so advance to the position.
reader.Advance(index);
return reader.Position;
}
// Skip the current segment since there's nothing in it.
reader.Advance(reader.CurrentSpan.Length);
}
return null;
}
Traiter les données binaires
L’exemple suivant analyse la longueur d’un entier Big Endian sur 4 octets à partir du début de la ReadOnlySequence<byte>.
bool TryParseHeaderLength(ref ReadOnlySequence<byte> buffer, out int length)
{
var reader = new SequenceReader<byte>(buffer);
return reader.TryReadBigEndian(out length);
}
Traiter les données de texte
static ReadOnlySpan<byte> NewLine => new byte[] { (byte)'\r', (byte)'\n' };
static bool TryParseLine(ref ReadOnlySequence<byte> buffer,
out ReadOnlySequence<byte> line)
{
var reader = new SequenceReader<byte>(buffer);
if (reader.TryReadTo(out line, NewLine))
{
buffer = buffer.Slice(reader.Position);
return true;
}
line = default;
return false;
}
Problèmes courants liés à SequenceReader<T>
- Étant donné qu’il
SequenceReader<T>s’agit d’un struct mutable, il doit toujours être passé par référence. -
SequenceReader<T>est un struct ref afin qu’il ne puisse être utilisé que dans les méthodes synchrones et ne peut pas être stocké dans des champs. Pour plus d’informations, consultez Éviter les allocations. -
SequenceReader<T>est optimisé pour une utilisation en tant que lecteur vers l’avant uniquement.Rewindest destiné aux petites sauvegardes qui ne peuvent pas être traitées à l’aide des APIRead,PeeketIsNext.
Collaborer avec nous sur GitHub
La source de ce contenu se trouve sur GitHub, où vous pouvez également créer et examiner les problèmes et les demandes de tirage. Pour plus d’informations, consultez notre guide du contributeur.