Notes
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
System.IO.Pipelines est une bibliothèque conçue pour faciliter l’exécution d’E/S hautes performances dans .NET. Il s’agit d’une bibliothèque ciblant .NET Standard qui fonctionne sur toutes les implémentations .NET.
La bibliothèque est disponible dans le package Nuget System.IO.Pipelines .
Quel problème System.IO.Pipelines résout-il ?
Les applications qui analysent les données de streaming sont composées de code réutilisable ayant de nombreux flux de code spécialisés et inhabituels. Le code réutilisable et le code de cas spécial sont complexes et difficiles à gérer.
System.IO.Pipelines a été conçu pour :
- Disposer de données de streaming d’analyse hautes performances.
- Réduire la complexité du code.
Le code suivant est typique pour un serveur TCP qui reçoit des messages délimités par une ligne (délimités par '\n') d’un client :
async Task ProcessLinesAsync(NetworkStream stream)
{
var buffer = new byte[1024];
await stream.ReadAsync(buffer, 0, buffer.Length);
// Process a single line from the buffer
ProcessLine(buffer);
}
Le code précédent présente plusieurs problèmes :
- L’intégralité du message (fin de ligne) peut ne pas être reçue dans un seul appel à
ReadAsync. - Il ignore le résultat de
stream.ReadAsync.stream.ReadAsyncretourne la quantité de données lues. - Il ne gère pas le cas où plusieurs lignes sont lues en un seul appel
ReadAsync. - Il alloue un tableau
byteà chaque lecture.
Pour résoudre les problèmes précédents, les modifications suivantes sont nécessaires :
Mettre en mémoire tampon les données entrantes jusqu’à ce qu’une nouvelle ligne soit trouvée.
Analyser toutes les lignes retournées dans la mémoire tampon.
Il est possible que la ligne dépasse 1 Ko (1 024 octets). Le code doit redimensionner la mémoire tampon d’entrée jusqu’à ce que le délimiteur soit trouvé pour ajuster la ligne complète à l’intérieur de la mémoire tampon.
- Si la mémoire tampon est redimensionnée, d’autres copies de mémoire tampon sont effectuées à mesure que des lignes plus longues apparaissent dans l’entrée.
- Pour réduire le gaspillage d’espace, compactez la mémoire tampon utilisée pour la lecture des lignes.
Envisagez d’utiliser le pool de mémoires tampons pour éviter d’allouer de la mémoire à plusieurs reprises.
Le code suivant résout certains de ces problèmes :
async Task ProcessLinesAsync(NetworkStream stream)
{
byte[] buffer = ArrayPool<byte>.Shared.Rent(1024);
var bytesBuffered = 0;
var bytesConsumed = 0;
while (true)
{
// Calculate the amount of bytes remaining in the buffer.
var bytesRemaining = buffer.Length - bytesBuffered;
if (bytesRemaining == 0)
{
// Double the buffer size and copy the previously buffered data into the new buffer.
var newBuffer = ArrayPool<byte>.Shared.Rent(buffer.Length * 2);
Buffer.BlockCopy(buffer, 0, newBuffer, 0, buffer.Length);
// Return the old buffer to the pool.
ArrayPool<byte>.Shared.Return(buffer);
buffer = newBuffer;
bytesRemaining = buffer.Length - bytesBuffered;
}
var bytesRead = await stream.ReadAsync(buffer, bytesBuffered, bytesRemaining);
if (bytesRead == 0)
{
// EOF
break;
}
// Keep track of the amount of buffered bytes.
bytesBuffered += bytesRead;
var linePosition = -1;
do
{
// Look for a EOL in the buffered data.
linePosition = Array.IndexOf(buffer, (byte)'\n', bytesConsumed,
bytesBuffered - bytesConsumed);
if (linePosition >= 0)
{
// Calculate the length of the line based on the offset.
var lineLength = linePosition - bytesConsumed;
// Process the line.
ProcessLine(buffer, bytesConsumed, lineLength);
// Move the bytesConsumed to skip past the line consumed (including \n).
bytesConsumed += lineLength + 1;
}
}
while (linePosition >= 0);
}
}
Le code précédent est complexe et ne répond pas à tous les problèmes identifiés. La mise en réseau hautes performances implique généralement l’écriture de code complexe pour optimiser les performances.
System.IO.Pipelines a été conçu pour faciliter l’écriture de ce type de code.
Tuyau
La classe Pipe peut être utilisée pour créer une paire PipeWriter/PipeReader. Toutes les données écrites dans le PipeWriter sont disponibles dans le PipeReader :
var pipe = new Pipe();
PipeReader reader = pipe.Reader;
PipeWriter writer = pipe.Writer;
Utilisation de base du canal
async Task ProcessLinesAsync(Socket socket)
{
var pipe = new Pipe();
Task writing = FillPipeAsync(socket, pipe.Writer);
Task reading = ReadPipeAsync(pipe.Reader);
await Task.WhenAll(reading, writing);
}
async Task FillPipeAsync(Socket socket, PipeWriter writer)
{
const int minimumBufferSize = 512;
while (true)
{
// Allocate at least 512 bytes from the PipeWriter.
Memory<byte> memory = writer.GetMemory(minimumBufferSize);
try
{
int bytesRead = await socket.ReceiveAsync(memory, SocketFlags.None);
if (bytesRead == 0)
{
break;
}
// Tell the PipeWriter how much was read from the Socket.
writer.Advance(bytesRead);
}
catch (Exception ex)
{
LogError(ex);
break;
}
// Make the data available to the PipeReader.
FlushResult result = await writer.FlushAsync();
if (result.IsCompleted)
{
break;
}
}
// By completing PipeWriter, tell the PipeReader that there's no more data coming.
await writer.CompleteAsync();
}
async Task ReadPipeAsync(PipeReader reader)
{
while (true)
{
ReadResult result = await reader.ReadAsync();
ReadOnlySequence<byte> buffer = result.Buffer;
while (TryReadLine(ref buffer, out ReadOnlySequence<byte> line))
{
// Process the line.
ProcessLine(line);
}
// Tell the PipeReader how much of the buffer has been consumed.
reader.AdvanceTo(buffer.Start, buffer.End);
// Stop reading if there's no more data coming.
if (result.IsCompleted)
{
break;
}
}
// Mark the PipeReader as complete.
await reader.CompleteAsync();
}
bool TryReadLine(ref ReadOnlySequence<byte> buffer, out ReadOnlySequence<byte> line)
{
// Look for a EOL in the buffer.
SequencePosition? position = buffer.PositionOf((byte)'\n');
if (position == null)
{
line = default;
return false;
}
// Skip the line + the \n.
line = buffer.Slice(0, position.Value);
buffer = buffer.Slice(buffer.GetPosition(1, position.Value));
return true;
}
Il existe deux opérations de mappage de boucle :
-
FillPipeAsynclit à partir duSocketet écrit dansPipeWriter. -
ReadPipeAsynclit à partir duPipeReaderet analyse les lignes entrantes.
Aucune mémoire tampon explicite n’est allouée. Toute la gestion des mémoires tampons est déléguée aux implémentations PipeReader et PipeWriter . La délégation de la gestion des tampons facilite la consommation de code pour se concentrer uniquement sur la logique métier.
Dans la première boucle :
- PipeWriter.GetMemory(Int32) est appelé pour obtenir la mémoire de l’enregistreur sous-jacent.
-
PipeWriter.Advance(Int32) est appelé pour indiquer au
PipeWriterla quantité de données écrites dans la mémoire tampon. -
PipeWriter.FlushAsync est appelé pour rendre les données disponibles pour le
PipeReader.
Dans la deuxième boucle, le PipeReader consomme les mémoires tampons écrites par PipeWriter. Les mémoires tampons proviennent du socket. L’appel à PipeReader.ReadAsync :
Retourne un ReadResult qui contient deux informations importantes :
- Les données lues sous la forme de
ReadOnlySequence<byte>. - Une valeur booléenne
IsCompletedqui indique si la fin des données (EOF) a été atteinte.
- Les données lues sous la forme de
Après avoir trouvé le délimiteur de fin de ligne (EOL) et analysé la ligne :
- La logique traite la mémoire tampon pour ignorer ce qui est déjà traité.
-
PipeReader.AdvanceToest appelé pour indiquer auPipeReaderla quantité de données consommées et examinées.
Les boucles lecteur et enregistreur se terminent par l’appel de Complete.
Complete permet au canal sous-jacent de libérer la mémoire allouée.
Contre-pression et contrôle de flux
Dans l’idéal, la lecture et l’analyse vont de pair :
- Le thread de lecture consomme les données du réseau et les place dans des mémoires tampons.
- Le thread d’analyse est responsable de la construction des structures de données appropriées.
En règle générale, l’analyse prend plus de temps que la simple copie de blocs de données à partir du réseau :
- Le thread de lecture devance le thread d’analyse.
- Le thread de lecture doit soit ralentir, soit allouer plus de mémoire pour stocker les données du thread d’analyse.
Pour des performances optimales, il existe un équilibre entre les pauses fréquentes et l’allocation de plus de mémoire.
Pour résoudre le problème précédent, le Pipe a deux paramètres pour contrôler le flux de données :
- PauseWriterThreshold : détermine la quantité de données à mettre en mémoire tampon avant la suspension des appels à FlushAsync.
-
ResumeWriterThreshold : détermine la quantité de données que le lecteur doit observer avant la reprise des appels
PipeWriter.FlushAsync.
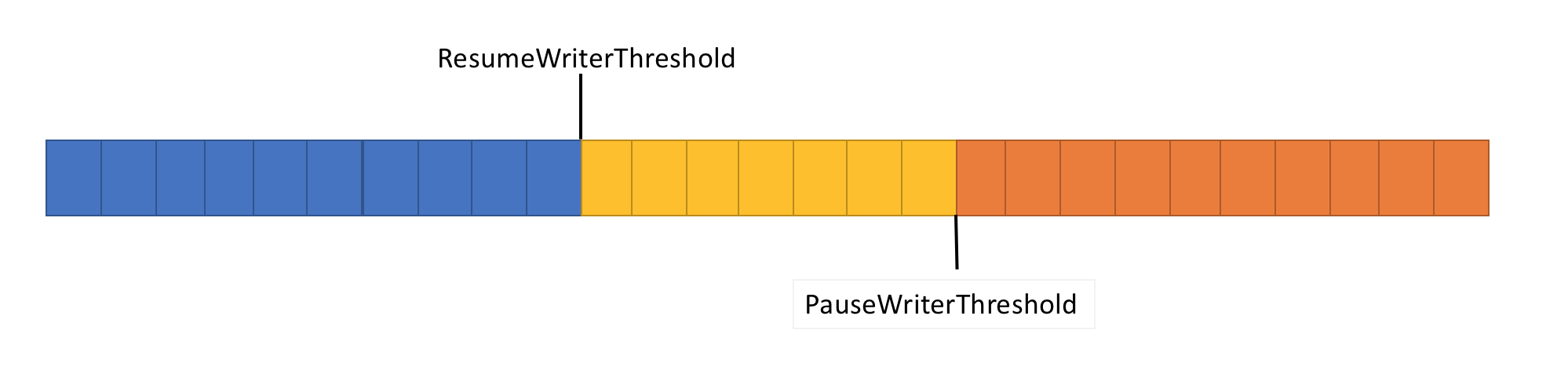
- Retourne un
ValueTask<FlushResult>incomplet lorsque la quantité de données dans lePipecroisePauseWriterThreshold. - Termine
ValueTask<FlushResult>quand il devient inférieur àResumeWriterThreshold.
Deux valeurs sont utilisées pour empêcher le cycle rapide, ce qui peut se produire si une valeur est utilisée.
Exemples
// The Pipe will start returning incomplete tasks from FlushAsync until
// the reader examines at least 5 bytes.
var options = new PipeOptions(pauseWriterThreshold: 10, resumeWriterThreshold: 5);
var pipe = new Pipe(options);
PipeScheduler
En règle générale, lors de l’utilisation de async et await, le code asynchrone reprend sur un TaskScheduler ou le SynchronizationContext actuel.
Lorsque vous effectuez des E/S, il est important d’avoir un contrôle précis sur l’endroit où les E/S sont effectuées. Ce contrôle permet de tirer parti efficacement des caches processeur. Une mise en cache efficace est essentielle pour les applications hautes performances telles que les serveurs web. PipeScheduler permet de contrôler l’endroit où les rappels asynchrones s’exécutent. Par défaut :
- Le SynchronizationContext actuel est utilisé.
- S’il n’y a pas de
SynchronizationContext, il utilise le pool de threads pour exécuter des rappels.
public static void Main(string[] args)
{
var writeScheduler = new SingleThreadPipeScheduler();
var readScheduler = new SingleThreadPipeScheduler();
// Tell the Pipe what schedulers to use and disable the SynchronizationContext.
var options = new PipeOptions(readerScheduler: readScheduler,
writerScheduler: writeScheduler,
useSynchronizationContext: false);
var pipe = new Pipe(options);
}
// This is a sample scheduler that async callbacks on a single dedicated thread.
public class SingleThreadPipeScheduler : PipeScheduler
{
private readonly BlockingCollection<(Action<object> Action, object State)> _queue =
new BlockingCollection<(Action<object> Action, object State)>();
private readonly Thread _thread;
public SingleThreadPipeScheduler()
{
_thread = new Thread(DoWork);
_thread.Start();
}
private void DoWork()
{
foreach (var item in _queue.GetConsumingEnumerable())
{
item.Action(item.State);
}
}
public override void Schedule(Action<object?> action, object? state)
{
if (state is not null)
{
_queue.Add((action, state));
}
// else log the fact that _queue.Add was not called.
}
}
PipeScheduler.ThreadPool est l’implémentation de PipeScheduler qui met en file d’attente les rappels au pool de threads.
PipeScheduler.ThreadPool est la valeur par défaut. C’est généralement le meilleur choix.
PipeScheduler.Inline peut entraîner des conséquences inattendues telles que des interblocages.
Réinitialisation du canal
Il est souvent efficace de réutiliser l’objet Pipe. Pour réinitialiser le canal, appelez PipeReaderReset lorsque PipeReader et PipeWriter sont tous les deux terminés.
PipeReader
PipeReader gère la mémoire au nom de l’appelant. Appelez toujoursPipeReader.AdvanceTo après avoir appelé PipeReader.ReadAsync. Cela permet au PipeReader de savoir quand l’appelant a terminé avec la mémoire afin de démarrer le suivi. Le ReadOnlySequence<byte> retourné à partir de PipeReader.ReadAsync n’est valide que jusqu’à l’appel de PipeReader.AdvanceTo. Il est illégal d’utiliser ReadOnlySequence<byte> après l’appel de PipeReader.AdvanceTo.
PipeReader.AdvanceTo accepte deux arguments SequencePosition :
- Le premier argument détermine la quantité de mémoire consommée.
- Le deuxième argument détermine la quantité de la mémoire tampon observée.
Marquer les données comme consommées signifie que le canal peut retourner la mémoire au pool de mémoires tampons sous-jacent. Le marquage des données comme observées contrôle ce que fait l’appel à PipeReader.ReadAsync suivant. Le marquage de tout comme observé signifie que l’appel à PipeReader.ReadAsync suivant ne reviendra pas tant qu’il n’y aura pas plus de données écrites dans le canal. Toute autre valeur effectuera l’appel à PipeReader.ReadAsync suivant pour retourner immédiatement avec les données observées et non observées, mais pas les données qui ont déjà été consommées.
Lire des scénarios de données de streaming
Il existe quelques modèles typiques qui émergent lorsque vous essayez de lire des données de streaming :
- Dans un flux de données, analysez un seul message.
- Dans un flux de données, analysez tous les messages disponibles.
Les exemples suivants utilisent la méthode TryParseLines pour analyser les messages d’un ReadOnlySequence<byte>.
TryParseLines analyse un seul message et met à jour la mémoire tampon d’entrée pour couper le message analysé de la mémoire tampon.
TryParseLines ne fait pas partie de .NET, il s’agit d’une méthode écrite par l’utilisateur utilisée dans les sections suivantes.
bool TryParseLines(ref ReadOnlySequence<byte> buffer, out Message message);
Lire un message unique
Le code suivant lit un seul message d’un PipeReader et le retourne à l’appelant.
async ValueTask<Message?> ReadSingleMessageAsync(PipeReader reader,
CancellationToken cancellationToken = default)
{
while (true)
{
ReadResult result = await reader.ReadAsync(cancellationToken);
ReadOnlySequence<byte> buffer = result.Buffer;
// In the event that no message is parsed successfully, mark consumed
// as nothing and examined as the entire buffer.
SequencePosition consumed = buffer.Start;
SequencePosition examined = buffer.End;
try
{
if (TryParseLines(ref buffer, out Message message))
{
// A single message was successfully parsed so mark the start of the
// parsed buffer as consumed. TryParseLines trims the buffer to
// point to the data after the message was parsed.
consumed = buffer.Start;
// Examined is marked the same as consumed here, so the next call
// to ReadSingleMessageAsync will process the next message if there's
// one.
examined = consumed;
return message;
}
// There's no more data to be processed.
if (result.IsCompleted)
{
if (buffer.Length > 0)
{
// The message is incomplete and there's no more data to process.
throw new InvalidDataException("Incomplete message.");
}
break;
}
}
finally
{
reader.AdvanceTo(consumed, examined);
}
}
return null;
}
Le code précédent :
- Analyse un message unique.
- Met à jour le
SequencePositionconsommé et leSequencePositionexaminé pour pointer vers le début de la mémoire tampon d’entrée découpée.
Les deux arguments SequencePosition sont mis à jour, car TryParseLines supprime le message analysé de la mémoire tampon d’entrée. En règle générale, lors de l’analyse d’un seul message à partir de la mémoire tampon, la position examinée doit être l’une des suivantes :
- La fin du message.
- La fin de la mémoire tampon reçue si aucun message n’a été trouvé.
Le cas d’un message unique présente le plus de risques d’erreurs. Passer les valeurs incorrectes au statut examinées peut entraîner une exception de mémoire insuffisante ou une boucle infinie. Pour plus d’informations, consultez la section Problèmes courants de PipeReader dans cet article.
Lecture de plusieurs messages
Le code suivant lit tous les messages d’un PipeReader et appelle ProcessMessageAsync sur chacun d’eux.
async Task ProcessMessagesAsync(PipeReader reader, CancellationToken cancellationToken = default)
{
try
{
while (true)
{
ReadResult result = await reader.ReadAsync(cancellationToken);
ReadOnlySequence<byte> buffer = result.Buffer;
try
{
// Process all messages from the buffer, modifying the input buffer on each
// iteration.
while (TryParseLines(ref buffer, out Message message))
{
await ProcessMessageAsync(message);
}
// There's no more data to be processed.
if (result.IsCompleted)
{
if (buffer.Length > 0)
{
// The message is incomplete and there's no more data to process.
throw new InvalidDataException("Incomplete message.");
}
break;
}
}
finally
{
// Since all messages in the buffer are being processed, you can use the
// remaining buffer's Start and End position to determine consumed and examined.
reader.AdvanceTo(buffer.Start, buffer.End);
}
}
}
finally
{
await reader.CompleteAsync();
}
}
Annulation
PipeReader.ReadAsync :
- Prend en charge le passage d’un CancellationToken.
- Lève une OperationCanceledException si le
CancellationTokenest annulé alors qu’une lecture est en attente. - Prend en charge un moyen d’annuler l’opération de lecture actuelle via PipeReader.CancelPendingRead, ce qui évite de déclencher une exception. Appeler
PipeReader.CancelPendingReadfait que l’appel actuel ou suivant àPipeReader.ReadAsyncretourne un ReadResult avecIsCanceleddéfini surtrue. Cela peut être utile pour arrêter la boucle de lecture existante de manière non destructive et non exceptionnelle.
private PipeReader reader;
public MyConnection(PipeReader reader)
{
this.reader = reader;
}
public void Abort()
{
// Cancel the pending read so the process loop ends without an exception.
reader.CancelPendingRead();
}
public async Task ProcessMessagesAsync()
{
try
{
while (true)
{
ReadResult result = await reader.ReadAsync();
ReadOnlySequence<byte> buffer = result.Buffer;
try
{
if (result.IsCanceled)
{
// The read was canceled. You can quit without reading the existing data.
break;
}
// Process all messages from the buffer, modifying the input buffer on each
// iteration.
while (TryParseLines(ref buffer, out Message message))
{
await ProcessMessageAsync(message);
}
// There's no more data to be processed.
if (result.IsCompleted)
{
break;
}
}
finally
{
// Since all messages in the buffer are being processed, you can use the
// remaining buffer's Start and End position to determine consumed and examined.
reader.AdvanceTo(buffer.Start, buffer.End);
}
}
}
finally
{
await reader.CompleteAsync();
}
}
Problèmes courants liés à PipeReader
La transmission de valeurs incorrectes à
consumedouexaminedpeut entraîner la lecture de données déjà lues.Donnez à
buffer.Endle statut examiné peut entraîner les conséquences suivantes :- Données bloquées
- Éventuellement une exception de mémoire insuffisante (OOM) si les données ne sont pas consommées. Par exemple,
PipeReader.AdvanceTo(position, buffer.End)lors du traitement d’un seul message à la fois à partir de la mémoire tampon.
Le passage de valeurs incorrectes à
consumedouexaminedpeut entraîner une boucle infinie. Par exemple,PipeReader.AdvanceTo(buffer.Start)sibuffer.Startn’a pas changé fera que l’appel suivant àPipeReader.ReadAsyncsera retourné immédiatement avant l’arrivée de nouvelles données.La transmission des valeurs incorrectes à
consumedouexaminedpeut entraîner une mise en mémoire tampon infinie (éventuellement une mémoire insuffisante).L’utilisation du
ReadOnlySequence<byte>après l’appel àPipeReader.AdvanceTopeut entraîner une altération de la mémoire (à utiliser une fois libre).L’échec de l’appel à
PipeReader.Complete/CompleteAsyncpeut entraîner une fuite de mémoire.La vérification de ReadResult.IsCompleted et la fermeture de la logique de lecture avant de traiter la mémoire tampon entraînent une perte de données. La condition de sortie de boucle doit être basée sur
ReadResult.Buffer.IsEmptyetReadResult.IsCompleted. Une opération incorrecte peut entraîner une boucle infinie.
Code problématique
❌ Perte de données
Le ReadResult peut retourner le dernier segment de données lorsque IsCompleted est défini sur true. Le fait de ne pas lire ces données avant de quitter la boucle de lecture entraîne une perte de données.
Avertissement
N’utilisez PAS le code suivant. L’utilisation de cet exemple entraîne une perte de données, des blocages, des problèmes de sécurité et ne doit PAS être copié. L’exemple suivant est fourni pour expliquer les problèmes courants de PipeReader.
Environment.FailFast("This code is terrible, don't use it!");
while (true)
{
ReadResult result = await reader.ReadAsync(cancellationToken);
ReadOnlySequence<byte> dataLossBuffer = result.Buffer;
if (result.IsCompleted)
break;
Process(ref dataLossBuffer, out Message message);
reader.AdvanceTo(dataLossBuffer.Start, dataLossBuffer.End);
}
Avertissement
N’utilisez PAS le code précédent. L’utilisation de cet exemple entraîne une perte de données, des blocages, des problèmes de sécurité et ne doit PAS être copié. L’exemple précédent est fourni pour expliquer les problèmes courants de PipeReader.
❌ Boucle infinie
La logique suivante peut entraîner une boucle infinie si le Result.IsCompleted est true mais qu’il n’y a jamais de message complet dans la mémoire tampon.
Avertissement
N’utilisez PAS le code suivant. L’utilisation de cet exemple entraîne une perte de données, des blocages, des problèmes de sécurité et ne doit PAS être copié. L’exemple suivant est fourni pour expliquer les problèmes courants de PipeReader.
Environment.FailFast("This code is terrible, don't use it!");
while (true)
{
ReadResult result = await reader.ReadAsync(cancellationToken);
ReadOnlySequence<byte> infiniteLoopBuffer = result.Buffer;
if (result.IsCompleted && infiniteLoopBuffer.IsEmpty)
break;
Process(ref infiniteLoopBuffer, out Message message);
reader.AdvanceTo(infiniteLoopBuffer.Start, infiniteLoopBuffer.End);
}
Avertissement
N’utilisez PAS le code précédent. L’utilisation de cet exemple entraîne une perte de données, des blocages, des problèmes de sécurité et ne doit PAS être copié. L’exemple précédent est fourni pour expliquer les problèmes courants de PipeReader.
Voici un autre élément de code avec le même problème. Il recherche une mémoire tampon non vide avant de vérifier ReadResult.IsCompleted. Étant donné qu’il se trouve dans un else if, il bouclera indéfiniment s’il n’y a jamais de message complet dans la mémoire tampon.
Avertissement
N’utilisez PAS le code suivant. L’utilisation de cet exemple entraîne une perte de données, des blocages, des problèmes de sécurité et ne doit PAS être copié. L’exemple suivant est fourni pour expliquer les problèmes courants de PipeReader.
Environment.FailFast("This code is terrible, don't use it!");
while (true)
{
ReadResult result = await reader.ReadAsync(cancellationToken);
ReadOnlySequence<byte> infiniteLoopBuffer = result.Buffer;
if (!infiniteLoopBuffer.IsEmpty)
Process(ref infiniteLoopBuffer, out Message message);
else if (result.IsCompleted)
break;
reader.AdvanceTo(infiniteLoopBuffer.Start, infiniteLoopBuffer.End);
}
Avertissement
N’utilisez PAS le code précédent. L’utilisation de cet exemple entraîne une perte de données, des blocages, des problèmes de sécurité et ne doit PAS être copié. L’exemple précédent est fourni pour expliquer les problèmes courants de PipeReader.
❌ Application sans réponse
Appeler PipeReader.AdvanceTo de manière inconditionnelle avec buffer.End dans la position examined peut faire que l’application ne réponde pas lors de l’analyse d’un seul message. L’appel suivant à PipeReader.AdvanceTo ne sera pas retourné tant que :
- Il y a plus de données écrites dans le canal.
- Mes nouvelles données n’ont pas été examinées précédemment.
Avertissement
N’utilisez PAS le code suivant. L’utilisation de cet exemple entraîne une perte de données, des blocages, des problèmes de sécurité et ne doit PAS être copié. L’exemple suivant est fourni pour expliquer les problèmes courants de PipeReader.
Environment.FailFast("This code is terrible, don't use it!");
while (true)
{
ReadResult result = await reader.ReadAsync(cancellationToken);
ReadOnlySequence<byte> hangBuffer = result.Buffer;
Process(ref hangBuffer, out Message message);
if (result.IsCompleted)
break;
reader.AdvanceTo(hangBuffer.Start, hangBuffer.End);
if (message != null)
return message;
}
Avertissement
N’utilisez PAS le code précédent. L’utilisation de cet exemple entraîne une perte de données, des blocages, des problèmes de sécurité et ne doit PAS être copié. L’exemple précédent est fourni pour expliquer les problèmes courants de PipeReader.
❌ Mémoire insuffisante
Dans les conditions suivantes, le code suivant conserve la mise en mémoire tampon jusqu’à ce qu’une OutOfMemoryException se produise :
- Il n’y a pas de taille de message maximale.
- Les données retournées par le
PipeReaderne constituent pas un message complet. Par exemple, il ne crée pas de message complet, car l’autre côté écrit un message volumineux (par exemple, un message de 4 Go).
Avertissement
N’utilisez PAS le code suivant. L’utilisation de cet exemple entraîne une perte de données, des blocages, des problèmes de sécurité et ne doit PAS être copié. L’exemple suivant est fourni pour expliquer les problèmes courants de PipeReader.
Environment.FailFast("This code is terrible, don't use it!");
while (true)
{
ReadResult result = await reader.ReadAsync(cancellationToken);
ReadOnlySequence<byte> thisCouldOutOfMemory = result.Buffer;
Process(ref thisCouldOutOfMemory, out Message message);
if (result.IsCompleted)
break;
reader.AdvanceTo(thisCouldOutOfMemory.Start, thisCouldOutOfMemory.End);
if (message != null)
return message;
}
Avertissement
N’utilisez PAS le code précédent. L’utilisation de cet exemple entraîne une perte de données, des blocages, des problèmes de sécurité et ne doit PAS être copié. L’exemple précédent est fourni pour expliquer les problèmes courants de PipeReader.
❌ Altération de la mémoire
Lors de l’écriture de helpers qui lisent la mémoire tampon, toute charge utile retournée doit être copiée avant d’appeler Advance. L’exemple suivant retourne la mémoire que le Pipe a ignorée et peut la réutiliser pour l’opération suivante (lecture/écriture).
Avertissement
N’utilisez PAS le code suivant. L’utilisation de cet exemple entraîne une perte de données, des blocages, des problèmes de sécurité et ne doit PAS être copié. L’exemple suivant est fourni pour expliquer les problèmes courants de PipeReader.
public class Message
{
public ReadOnlySequence<byte> CorruptedPayload { get; set; }
}
Environment.FailFast("This code is terrible, don't use it!");
Message message = null;
while (true)
{
ReadResult result = await reader.ReadAsync(cancellationToken);
ReadOnlySequence<byte> buffer = result.Buffer;
ReadHeader(ref buffer, out int length);
if (length <= buffer.Length)
{
message = new Message
{
// Slice the payload from the existing buffer
CorruptedPayload = buffer.Slice(0, length)
};
buffer = buffer.Slice(length);
}
if (result.IsCompleted)
break;
reader.AdvanceTo(buffer.Start, buffer.End);
if (message != null)
{
// This code is broken since reader.AdvanceTo() was called with a position *after* the buffer
// was captured.
break;
}
}
return message;
}
Avertissement
N’utilisez PAS le code précédent. L’utilisation de cet exemple entraîne une perte de données, des blocages, des problèmes de sécurité et ne doit PAS être copié. L’exemple précédent est fourni pour expliquer les problèmes courants de PipeReader.
PipeWriter
Le PipeWriter gère les mémoires tampons pour l’écriture au nom de l’appelant. L'objet PipeWriter implémente l'objet IBufferWriter<byte>.
IBufferWriter<byte> permet d’accéder aux mémoires tampons pour effectuer des écritures sans copies de mémoire tampon supplémentaires.
async Task WriteHelloAsync(PipeWriter writer, CancellationToken cancellationToken = default)
{
// Request at least 5 bytes from the PipeWriter.
Memory<byte> memory = writer.GetMemory(5);
// Write directly into the buffer.
int written = Encoding.ASCII.GetBytes("Hello".AsSpan(), memory.Span);
// Tell the writer how many bytes were written.
writer.Advance(written);
await writer.FlushAsync(cancellationToken);
}
Le code précédent :
- Demande une mémoire tampon d’au moins 5 octets auprès du
PipeWriteren utilisant GetMemory. - Écrit des octets pour la chaîne ASCII
"Hello"dans leMemory<byte>retourné. - Appelle Advance pour indiquer le nombre d’octets qui ont été écrits dans la mémoire tampon.
- Vide le
PipeWriter, qui envoie les octets à l’appareil sous-jacent.
La méthode d’écriture précédente utilise la mémoire tampon fournie par le PipeWriter. Il a également pu utiliser PipeWriter.WriteAsync, qui :
- Copie la mémoire tampon existante dans
PipeWriter. - Appelle
GetSpan,Advancele cas échéant, et appelle FlushAsync.
async Task WriteHelloAsync(PipeWriter writer, CancellationToken cancellationToken = default)
{
byte[] helloBytes = Encoding.ASCII.GetBytes("Hello");
// Write helloBytes to the writer, there's no need to call Advance here
// (Write does that).
await writer.WriteAsync(helloBytes, cancellationToken);
}
Annulation
FlushAsync prend en charge le passage d’un CancellationToken. La transmission d’un CancellationToken cause une OperationCanceledException si le jeton est annulé alors qu’un vidage est en attente.
PipeWriter.FlushAsync prend en charge un moyen d’annuler l’opération de vidage en cours via PipeWriter.CancelPendingFlush sans déclencher d’exception. Appeler PipeWriter.CancelPendingFlush fait que l’appel actuel ou suivant à PipeWriter.FlushAsync ou PipeWriter.WriteAsync retourne un FlushResult avec IsCanceled définir sur true. Cela peut être utile pour arrêter le vidage d’interruption de manière non destructive et non exceptionnelle.
Problèmes courants liés à PipeWriter
- GetSpan et GetMemory retournent une mémoire tampon avec au moins la quantité de mémoire demandée. Les tailles des mémoires tampons ne seront pas nécessairement exactes.
- Il n’est pas garanti que des appels successifs vont retourner la même mémoire tampon ou une mémoire tampon de même taille.
- Une nouvelle mémoire tampon doit être demandée après l’appel de Advance pour continuer à écrire d’autres données. La mémoire tampon précédemment acquise ne peut pas y être écrite.
- Il n’est pas prudent d’appeler
GetMemoryouGetSpanalors qu’il y a un appel incomplet àFlushAsync. - Appeler
CompleteouCompleteAsyncalors que des données non vidées peuvent entraîner une altération de la mémoire.
Conseils d’utilisation pour PipeReader et PipeWriter
Les conseils suivants vous aideront à utiliser correctement les classes System.IO.Pipelines :
- Effectuez toujours les commandes PipeReader et PipeWriter, avec une exception le cas échéant.
- Appelez toujours PipeReader.AdvanceTo après avoir appelé PipeReader.ReadAsync.
- Régulièrement
awaitPipeWriter.FlushAsync lors de l’écriture, et vérifiez toujours FlushResult.IsCompleted. Abandonner l’écriture siIsCompletedesttrue, car cela indique que le lecteur est terminé et ne se soucie plus de ce qui est écrit. - Appelez PipeWriter.FlushAsync après avoir écrit quelque chose auquel vous souhaitez que
PipeReadera accès. - N’appelez pas
FlushAsyncsi le lecteur ne peut pas démarrer tant queFlushAsyncn’a pas terminé, car cela peut entraîner un interblocage. - Vérifiez qu’un seul contexte « possède » un
PipeReaderouPipeWriterou y accède. Ces types ne sont pas thread-safe. - N’accédez jamais à un ReadResult.Buffer après avoir appelé
AdvanceToou terminé lePipeReader.
IDuplexPipe
Le IDuplexPipe est un contrat pour les types qui prennent en charge à la fois la lecture et l’écriture. Par exemple, une connexion réseau est représentée par un IDuplexPipe.
Contrairement à Pipe, qui contient un PipeReader et un PipeWriter, IDuplexPipe représente un côté unique d’une connexion duplex complète. Cela signifie que ce qui est écrit dans le PipeWriter ne sera pas lu à partir du PipeReader.
Flux
Lors de la lecture ou de l’écriture de données de flux de données, vous lisez généralement des données à l’aide d’un désérialiseur et vous écrivez des données à l’aide d’un sérialiseur. La plupart de ces API de flux de lecture et d’écriture ont un paramètre Stream. Pour faciliter l’intégration à ces API existantes, PipeReader et PipeWriter exposent une méthode AsStream.
AsStream retourne une implémentation Stream autour du PipeReader ou PipeWriter .
Exemple de flux
Les instances PipeReader et PipeWriter peuvent être créées à l’aide des méthodes statiques Create en fonction d’un objet Stream et des options de création facultatives correspondantes.
Le StreamPipeReaderOptions permet de contrôler la création de l’instance PipeReader avec les paramètres suivants :
-
StreamPipeReaderOptions.BufferSize est la taille de mémoire tampon minimale en octets utilisée lors de la location de mémoire à partir du pool. La valeur par défaut est
4096. - L’indicateur StreamPipeReaderOptions.LeaveOpen détermine si le flux sous-jacent est ou non laissé ouvert une fois l’opération
PipeReaderterminée, et la valeur par défaut estfalse. -
StreamPipeReaderOptions.MinimumReadSize représente le seuil d’octets à conserver dans la mémoire tampon avant l’allocation d’une nouvelle mémoire tampon. La valeur par défaut est
1024. -
StreamPipeReaderOptions.Pool est le
MemoryPool<byte>utilisé lors de l’allocation de mémoire. La valeur par défaut estnull.
Le StreamPipeWriterOptions permet de contrôler la création de l’instance PipeWriter avec les paramètres suivants :
- L’indicateur StreamPipeWriterOptions.LeaveOpen détermine si le flux sous-jacent est ou non laissé ouvert une fois l’opération
PipeWriterterminée, et la valeur par défaut estfalse. -
StreamPipeWriterOptions.MinimumBufferSize représente la taille minimale de mémoire tampon à utiliser pour la location de mémoire à partir du Pool. La valeur par défaut est
4096. -
StreamPipeWriterOptions.Pool est le
MemoryPool<byte>utilisé lors de l’allocation de mémoire. La valeur par défaut estnull.
Important
Lors de la création d’instances PipeReader et PipeWriter à l’aide des méthodes Create, vous devez prendre en compte la durée de vie de l’objet Stream. Si vous avez besoin d’accéder au flux une fois le lecteur ou l’enregistreur terminé, vous devez définir l’indicateur LeaveOpen sur true pour les options de création. Sinon, le flux sera fermé.
Le code suivant illustre la création d’instances PipeReader et PipeWriter à l’aide des méthodes Create d’un flux.
using System.Buffers;
using System.IO.Pipelines;
using System.Text;
class Program
{
static async Task Main()
{
using var stream = File.OpenRead("lorem-ipsum.txt");
var reader = PipeReader.Create(stream);
var writer = PipeWriter.Create(
Console.OpenStandardOutput(),
new StreamPipeWriterOptions(leaveOpen: true));
WriteUserCancellationPrompt();
var processMessagesTask = ProcessMessagesAsync(reader, writer);
var userCanceled = false;
var cancelProcessingTask = Task.Run(() =>
{
while (char.ToUpperInvariant(Console.ReadKey().KeyChar) != 'C')
{
WriteUserCancellationPrompt();
}
userCanceled = true;
// No exceptions thrown
reader.CancelPendingRead();
writer.CancelPendingFlush();
});
await Task.WhenAny(cancelProcessingTask, processMessagesTask);
Console.WriteLine(
$"\n\nProcessing {(userCanceled ? "cancelled" : "completed")}.\n");
}
static void WriteUserCancellationPrompt() =>
Console.WriteLine("Press 'C' to cancel processing...\n");
static async Task ProcessMessagesAsync(
PipeReader reader,
PipeWriter writer)
{
try
{
while (true)
{
ReadResult readResult = await reader.ReadAsync();
ReadOnlySequence<byte> buffer = readResult.Buffer;
try
{
if (readResult.IsCanceled)
{
break;
}
if (TryParseLines(ref buffer, out string message))
{
FlushResult flushResult =
await WriteMessagesAsync(writer, message);
if (flushResult.IsCanceled || flushResult.IsCompleted)
{
break;
}
}
if (readResult.IsCompleted)
{
if (!buffer.IsEmpty)
{
throw new InvalidDataException("Incomplete message.");
}
break;
}
}
finally
{
reader.AdvanceTo(buffer.Start, buffer.End);
}
}
}
catch (Exception ex)
{
Console.Error.WriteLine(ex);
}
finally
{
await reader.CompleteAsync();
await writer.CompleteAsync();
}
}
static bool TryParseLines(
ref ReadOnlySequence<byte> buffer,
out string message)
{
SequencePosition? position;
StringBuilder outputMessage = new();
while(true)
{
position = buffer.PositionOf((byte)'\n');
if (!position.HasValue)
break;
outputMessage.Append(Encoding.ASCII.GetString(buffer.Slice(buffer.Start, position.Value)))
.AppendLine();
buffer = buffer.Slice(buffer.GetPosition(1, position.Value));
};
message = outputMessage.ToString();
return message.Length != 0;
}
static ValueTask<FlushResult> WriteMessagesAsync(
PipeWriter writer,
string message) =>
writer.WriteAsync(Encoding.ASCII.GetBytes(message));
}
L’application utilise un StreamReader pour lire le fichier lorem-ipsum.txt en tant que flux et doit se terminer par une ligne vide. Le FileStream est passé à PipeReader.Create, qui instancie un objet PipeReader. L’application console transmet ensuite son flux de sortie standard à PipeWriter.Create à l’aide de Console.OpenStandardOutput(). L’exemple prend en charge l’annulation.
Collaborer avec nous sur GitHub
La source de ce contenu se trouve sur GitHub, où vous pouvez également créer et examiner les problèmes et les demandes de tirage. Pour plus d’informations, consultez notre guide du contributeur.