Supprimez les doublons dans chaque table pour l’unification des données
L’étape d’unification Règles de déduplication recherche et supprime les enregistrements en double d’un client d’une table source afin que chaque client soit représenté par une seule ligne dans chaque table. Chaque table est dédupliquée séparément à l’aide de règles permettant d’identifier les enregistrements d’un client donné.
Les règles sont traitées dans l’ordre. Une fois que toutes les règles ont été exécutées sur tous les enregistrements d’une table, les groupes de correspondance partageant une ligne commune sont combinés en un seul groupe de correspondance.
Définir des règles de déduplication
Une bonne règle identifie un client unique. Considérez vos données. Il peut être suffisant d’identifier les clients en fonction d’un champ tel que l’e-mail. Cependant, si vous souhaitez différencier les clients qui partagent un e-mail, vous pouvez choisir d’avoir une règle à deux conditions, correspondant à E-mail + Prénom. Pour plus d’informations, consultez Concepts et scénarios de déduplication.
Sur la page Règles de déduplication, sélectionnez une table et sélectionnez Ajouter une règle pour définir les règles de déduplication.
Astuce
Si vous avez enrichi des tables au niveau source de données pour améliorer vos résultats d’unification, sélectionnez les Utiliser les tables enrichies en haut de la page. Pour plus d’informations, voir Enrichissement des sources de données.
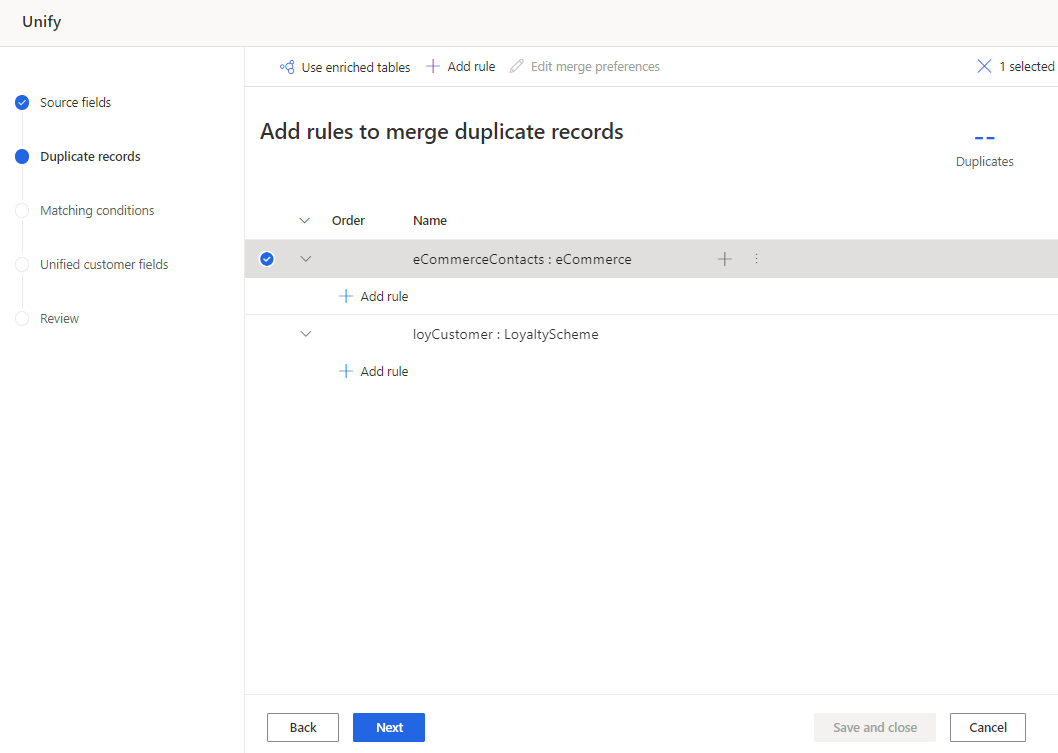
Entrez les informations suivantes dans le volet Ajouter une règle :
- Sélectionner un champ : Choisissez la table dont vous souhaitez vérifier les doublons dans la liste des champs disponibles. Choisissez des champs susceptibles d’être uniques pour chaque client. Par exemple, une adresse e-mail ou la combinaison du nom, de la ville et du numéro de téléphone.
- Normaliser : sélectionnez les options de normalisation pour la colonne. La normalisation n’impacte que l’étape de correspondance et ne modifie pas les données.
- Chiffres : convertit de nombreux symboles Unicode qui représentent des nombres en nombres simples.
- Symboles : supprime de nombreux symboles courants tels que !"#$%’()*+,-./:;<=>?@[]^_`{|}~. Par exemple, Head&Shoulder devient HeadShoulder.
- Texte en minuscules : Convertit tous les caractères en minuscules. « TOUTES LES MAJUSCULES et le titre » devient « toutes les majuscules et le titre ».
- Type (Téléphone, Nom, Adresse, Organisation) : Normalise les noms, les fonctions, les numéros de téléphone, les adresses, etc.
- Unicode en ASCII : convertit les caractères Unicode en caractères ASCII. Par exemple, le ề accentué est converti en caractère e.
- Espace blanc : supprime tous les espaces. Hello World devient HelloWorld.
- Précision : définie sur Précision de la devise La précision est utilisée avec la correspondance approximative et détermine à quel point deux chaînes doivent être proches pour être considérées comme une correspondance.
- De base : Choisissez parmi : Faible (30 %), Moyen (60 %), Élevé (80 %) et Exact (100 %). Sélectionnez Exact pour faire correspondre uniquement les enregistrements qui correspondent à 100 %.
- Personnalisé : Définissez un pourcentage auquel les enregistrements doivent correspondre. Le système ne correspond que les enregistrements dépassant ce seuil.
- Nom : Le nom de la règle.

Vous pouvez, si vous le souhaitez, sélectionner Ajouter>Ajouter une condition pour ajouter plus de conditions à la règle. Les conditions sont connectées avec un opérateur ET logique et ne sont donc exécutées que si toutes les conditions sont remplies.
Vous pouvez, si vous le souhaitez, sélectionner Ajouter>Ajouter une exception pour ajouter des exceptions à la règle. Les exceptions sont utilisées pour traiter les rares cas de faux positifs et de faux négatifs.
Sélectionnez Terminé pour créer la règle.
Vous pouvez également ajouter d’autres règles.
Sélectionnez une table, puis Modifier les préférences de fusion.
Dans le volet Préférences de fusion :
Choisissez l’une des trois options pour déterminer quel enregistrement conserver si un doublon est détecté :
- Le plus rempli : identifie l’enregistrement avec les colonnes les plus remplies comme enregistrement gagnant. C’est l’option de fusion par défaut.
- Le plus récent : identifie l’enregistrement gagnant en fonction du plus récent. Nécessite une date ou un champ numérique pour définir l’ancienneté.
- Le moins récent : identifie l’enregistrement gagnant en fonction du moins récent. Nécessite une date ou un champ numérique pour définir l’ancienneté.
En cas d’égalité, l’enregistrement gagnant est celui avec le MAX(PK) ou la plus grande valeur de clé primaire.
Vous pouvez aussi définir des préférences de fusion sur des colonnes individuelles d’une table en sélectionnant Avancé en bas du volet. Par exemple, vous pouvez choisir de conserver l’e-mail le plus récent ET l’adresse la plus complète de différents enregistrements. Développez la table pour voir toutes ses colonnes et définissez l’option à utiliser pour les colonnes individuelles. Si vous choisissez une option basée sur la récence, vous devez également spécifier un champ de date/heure qui définit la récence.

Sélectionnez Terminé pour appliquer vos préférences de fusion.
Après avoir défini les règles de déduplication et les préférences de fusion, sélectionnez Suivant.
