Meilleures pratiques en matière d’unification des données
Lorsque vous définissez des règles pour unifier vos données dans un profil client, tenez compte de ces bonnes pratiques :
Équilibrez le temps pour unifier et compléter la correspondance. Tenter de capturer toutes les correspondances possibles conduit à de nombreuses règles et à une unification qui prend beaucoup de temps.
Ajoutez des règles progressivement et suivez les résultats. Supprimez les règles qui n’améliorent pas le résultat du match.
Dédupliquer chaque table afin que chaque client soit représenté sur une seule ligne.
Utilisez la normalisation pour standardiser les variations dans la façon dont les données ont été saisies, telles que Street vs. St. vs. st.
Utilisez la correspondance floue de manière stratégique pour corriger les fautes de frappe et les erreurs telles que bob@contoso.com et bob@contoso.cm. Les correspondances floues prennent plus de temps à s’exécuter que les correspondances exactes. Testez toujours pour voir si le temps supplémentaire consacré à la correspondance floue vaut le taux de correspondance supplémentaire.
Réduisez la portée des correspondances avec une correspondance exacte. Assurez-vous que chaque règle avec des conditions floues possède au moins une condition de correspondance exacte.
Ne faites pas correspondre les colonnes qui contiennent des données très répétées. Assurez-vous que les colonnes à correspondance floue n’ont pas de valeurs répétées fréquemment, comme la valeur par défaut d’un formulaire "Prénom".
Performances d’unification
Chaque règle prend du temps à s’exécuter. Des modèles tels que la comparaison de chaque table avec chaque autre table ou la tentative de capture de chaque correspondance d’enregistrement possible peuvent entraîner de longs délais de traitement d’unification. Il renvoie également peu ou pas de correspondances par rapport à un plan qui compare chaque table à une table de base.
La meilleure approche consiste à commencer par un ensemble de règles de base dont vous savez qu’elles sont nécessaires, comme la comparaison de chaque table à votre table principale. Votre table principale doit être celle contenant les données les plus complètes et les plus précises. Ce tableau doit être classé en haut dans l’unification des règles de correspondance étape.
Ajoutez progressivement plusieurs règles et voyez combien de temps les modifications prennent à s’exécuter et si vos résultats s’améliorent. Accédez à Paramètres>Système>État et Fermer Correspondance pour voir combien de temps la déduplication et la correspondance ont pris pour chaque exécution d’unification.
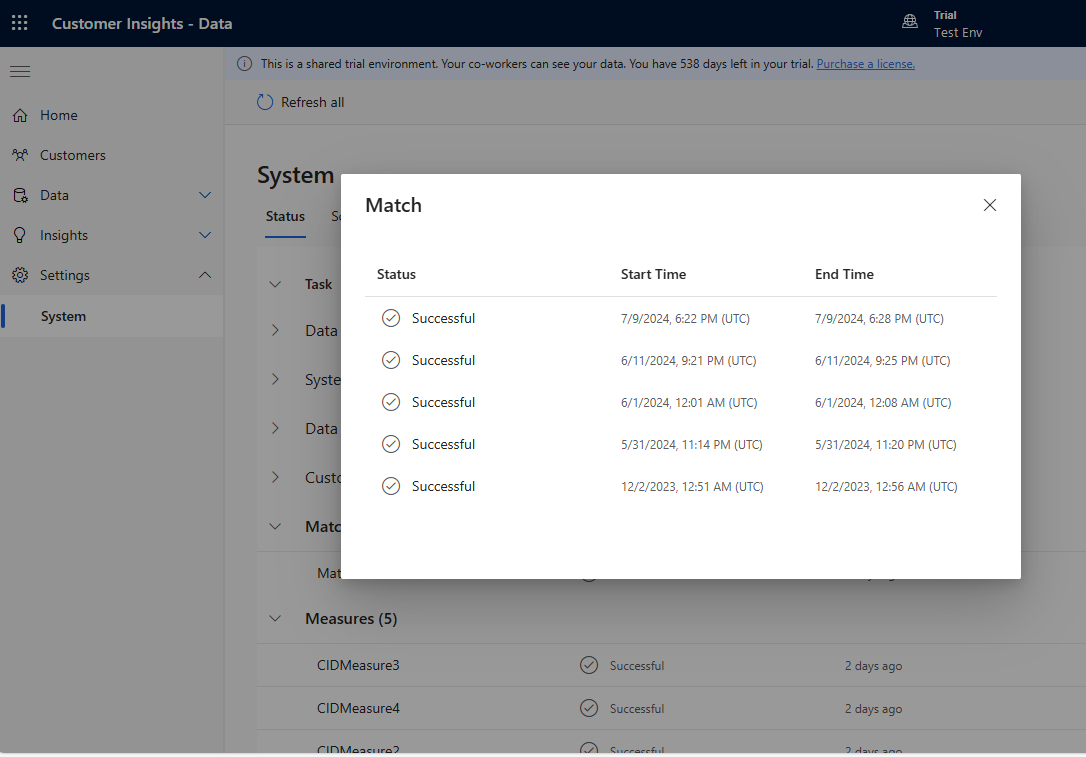
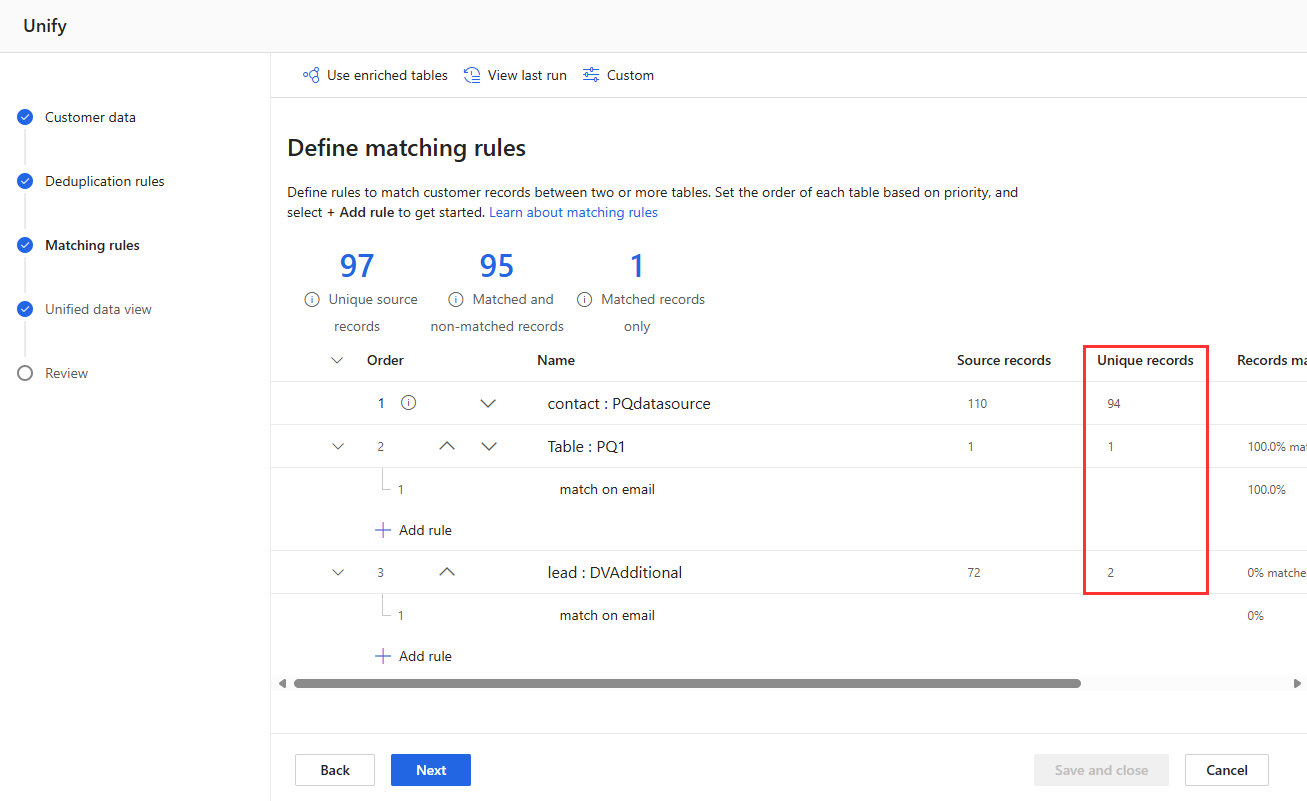
Consultez les statistiques des règles sur les pages Règles de déduplication et Règles de correspondance pour voir si le nombre d’ enregistrements uniques change. Si une nouvelle règle correspond à certains enregistrements et que le nombre d’enregistrements uniques ne change pas, une règle précédente identifie ces correspondances.
Déduplication
Utilisez des règles de déduplication pour supprimer les enregistrements client en double dans une table afin qu’une seule ligne dans chaque table représente chaque client. Une bonne règle identifie un client unique.
Dans cet exemple simple, les enregistrements 1, 2 et 3 Partager sont soit une adresse e-mail, soit un numéro de téléphone et représentent la même personne.
| ID | Nom | votre numéro de | |
|---|---|---|---|
| 1 | Personne 1 | (425) 555-1111 | AAA@A.com |
| 2 | Personne 1 | (425) 555-1111 | BBB@B.com |
| 3 | Personne 1 | (425) 555-2222 | BBB@B.com |
| 4 | Personne 2 | (206) 555-9999 | Person2@contoso.com |
Nous ne voulons pas faire correspondre uniquement le nom, car cela ferait correspondre différentes personnes portant le même nom.
Créez la règle 1 en utilisant le nom et le téléphone, qui correspond aux enregistrements 1 et 2.
Créez la règle 2 en utilisant le nom et l’e-mail, qui correspond aux enregistrements 2 et 3.
La combinaison de la règle 1 et de la règle 2 crée un seul groupe de correspondance car elles partagent l’enregistrement 2.
Vous décidez du nombre de règles et de conditions qui identifient de manière unique vos clients. Les règles exactes dépendent des données dont vous disposez pour la correspondance, de la qualité de vos données et du degré d’exhaustivité que vous souhaitez pour le processus de déduplication.
Gagnant et records alternatifs
Une fois les règles exécutées et les enregistrements en double identifiés, le processus de déduplication sélectionne une "ligne gagnante". Les lignes non gagnantes sont appelées "lignes alternatives". Les lignes alternatives sont utilisées dans l’unification des règles de correspondance étape pour faire correspondre les enregistrements d’autres tables à la ligne gagnante. Les lignes sont comparées aux données des lignes alternatives en plus de la ligne gagnante.
Une fois que vous avez ajouté une règle à une table, vous pouvez configurer la ligne à Sélectionner utiliser comme ligne gagnante via les Préférences de fusion. Les préférences de fusion sont définies par table. Quelle que soit la politique de fusion sélectionnée, s’il y a égalité pour une ligne gagnante, la première ligne dans l’ordre des données est utilisée comme critère de départage.
Normalisation
Utilisez la normalisation pour standardiser les données pour une meilleure correspondance. La normalisation fonctionne bien sur de grands ensembles de données.
Les données normalisées ne sont utilisées qu’à des fins de comparaison afin de correspondre plus efficacement aux enregistrements des clients. Cela ne modifie pas les données dans la sortie finale du profil client unifié.
| Normalisation | Examples |
|---|---|
| Valeurs numériques | Convertit de nombreux symboles Unicode qui représentent des nombres en nombres simples. Exemples : ❽ et Ⅷ sont tous deux normalisés au nombre 8. Remarque : Les symboles doivent être codés au format de point Unicode. |
| Symboles | Supprime tous les symboles et caractères spéciaux. Exemples : !?"#$%&’( )+,.-/:;<=>@^~{}`[ ] |
| Texte en minuscules | Convertit les caractères en majuscules en minuscules. Exemple : "CECI EST UN EXEMPLE" est converti en "Ceci est un exemple" |
| Type – Téléphone | Convertit les téléphones de différents formats en chiffres et prend en compte les variations dans la présentation des codes de pays et des extensions. Exemple : +01 425.555.1212 = 1 (425) 555-1212 |
| Type – Nom | Convertit plus de 500 variantes de noms et titres courants. Exemples : « debby » -> « deborah » « prof » et « professeur » -> « Prof. » |
| Type – Adresse | Convertit les parties communes des adresses Exemples : « street » -> « st » et « northwest » -> « nw » |
| Type – Organisation | Supprime environ 50 "mots parasites" dans les noms d’entreprises, tels que "co", "corp", "corporation" et "ltd". |
| Unicode en ASCII | Convertit les caractères Unicode en caractères ASCII Exemple : Les caractères "à", "á", "â", "À", "Á", "Â", "Ã", "Ä", "Ⓐ" et "A" sont tous convertis en "a". .’ |
| Espace blanc | Supprime tous les espaces blancs |
| Mise en correspondance d’alias | Vous permet de télécharger une liste personnalisée de paires de chaînes qui peuvent ensuite être utilisées pour indiquer les chaînes qui doivent toujours être considérées comme une correspondance exacte. Utilisez le mappage d’alias lorsque vous avez des exemples de données spécifiques qui, selon vous, devraient correspondre et qui ne correspondent pas à l’aide de l’un des autres modèles de normalisation. Exemple : Scott et Scooter, ou MSFT et Microsoft. |
| Contournement personnalisé | Vous permet de télécharger une liste personnalisée de chaînes qui peuvent ensuite être utilisées pour indiquer les chaînes qui ne doivent jamais être considérées comme une correspondance exacte. Le contournement personnalisé est utile lorsque vous avez des données avec des valeurs communes qui doivent être ignorées, comme un numéro de téléphone factice ou une adresse e-mail factice. Exemple : Ne jamais faire correspondre le téléphone 555-1212, ou test@contoso.com |
Correspondance exacte
Utilisez la précision pour déterminer à quel point deux chaînes doivent être considérées comme une correspondance. Le paramètre de précision par défaut nécessite une correspondance exacte. Toute autre valeur permet une correspondance floue pour cette condition.
La précision peut être définie sur faible (correspondance à 30 %), moyenne (correspondance à 60 %) et élevée (correspondance à 80 %). Ou vous pouvez personnaliser et définir la précision par incréments de 1 %.
Conditions de correspondance exactes
Les conditions de correspondance exactes sont exécutées en premier pour obtenir un ensemble de valeurs Sélectionner pour les correspondances floues. Pour être efficaces, les conditions de correspondance exacte doivent avoir un degré raisonnable d’unicité. Par exemple, si tous vos clients vivent dans le même pays/la même région, avoir une correspondance exacte sur le pays/la région n’aiderait pas à réduire la portée.
Les colonnes telles que le nom complet, l’e-mail, le téléphone ou l’adresse ont une bonne unicité et sont d’excellentes colonnes à utiliser comme correspondance exacte.
Assurez-vous que la colonne que vous utilisez pour une condition de correspondance exacte ne contient aucune valeur répétée fréquemment, comme une valeur par défaut de "Prénom" capturée par un formulaire. Les informations client peuvent profiler les colonnes de données pour fournir un aperçu des valeurs les plus récurrentes. Vous pouvez activer le profilage des données sur les connexions Azure Data Lake (à l’aide du format Common Data Model ou Delta) et Synapse. Le profil de données est exécuté lors de la prochaine actualisation de source de données. Pour plus d’informations, rendez-vous sur Profilage des données.
Correspondance floue
Utilisez la correspondance floue pour faire correspondre les chaînes qui sont Fermer mais qui ne sont pas exactes en raison de fautes de frappe ou d’autres petites variations. Utilisez la correspondance floue de manière stratégique, car elle est plus lente que les correspondances exactes. Assurez-vous qu’il existe au moins une condition de correspondance exacte dans toute règle comportant des conditions floues.
La correspondance floue n’est pas destinée à capturer les variations de noms comme Suzzie et Suzanne. Ces variations sont mieux capturées avec le modèle de normalisation Type : Nom ou la Correspondance d’alias personnalisée où les clients peuvent saisir leur liste de variations de nom qu’ils souhaitent considérer comme des correspondances.
Vous pouvez ajouter des conditions à une règle, telles que la correspondance du Prénom et du Téléphone. Les conditions au sein d’une règle donnée sont des conditions "ET". Chaque condition doit correspondre pour que les lignes correspondent. Les règles distinctes sont les conditions "OU". Si la règle 1 ne correspond pas aux lignes, les lignes sont alors comparées à la règle 2.
Note
Seules les colonnes de type de données chaîne peuvent utiliser la correspondance floue. Pour les colonnes contenant d’autres types de données tels que entier, double ou datetime, le champ de précision est en lecture seule et défini sur la correspondance exacte.
Calculs de correspondance floue
Les correspondances floues sont déterminées en calculant le score de distance d’édition entre deux chaînes. Si le score atteint ou dépasse le seuil de précision, les chaînes sont considérées comme une correspondance.
La distance d’édition est le nombre d’éditions nécessaires pour transformer une chaîne en une autre, en ajoutant, en supprimant ou en modifiant un caractère.
Par exemple, les chaînes "Jacqueline" et "Jaclyne" ont une distance d’édition de cinq lorsque nous supprimons les caractères q, u, e, i et e et insérons le caractère y.
Pour calculer le score de distance d’édition, utilisez cette formule : (Longueur de base de la chaîne – Distance d’édition) / Longueur de base de la chaîne.
| Chaîne de base | Chaîne de comparaison | Score |
|---|---|---|
| Jacqueline | Jaclyne | (10-4)/10=0,6 |
| fred@contoso.com | fred@contso.cm | (14-2) / 14 = 0,857 |
| franklin | frank | (8-3) / 8 = 0,625 |