Migrations Code First dans les environnements d’équipe
Remarque
Cet article part du principe que vous savez comment utiliser les Migrations Code First dans des scénarios de base. Si ce n’est pas le cas, vous devez lire Migrations Code First avant de continuer.
Prenez un café, vous devez lire cet article entier
Les problèmes rencontrés dans les environnements d’équipe sont principalement liés à la fusion des migrations lorsque deux développeurs ont généré des migrations dans leur base de code locale. Bien que les étapes à suivre pour résoudre ces problèmes soient assez simples, elles vous obligent à avoir une bonne compréhension du fonctionnement des migrations. N’oubliez pas simplement de passer à la fin - prenez le temps de lire l’ensemble de l’article pour vous assurer que vous avez réussi.
Quelques instructions générales
Avant de savoir comment gérer la fusion des migrations générées par plusieurs développeurs, voici quelques instructions générales pour vous configurer pour réussir.
Chaque membre de l’équipe doit avoir une base de données de développement locale
Les migrations utilisent la table __MigrationsHistory pour stocker les migrations qui ont été appliquées à la base de données. Si vous avez plusieurs développeurs générant différentes migrations tout en essayant de cibler la même base de données (et ainsi partager une table __MigrationsHistory ) les migrations vont être très confus.
Bien sûr, si vous avez des membres de l’équipe qui ne génèrent pas de migrations, il n’y a aucun problème pour qu’ils partagent une base de données de développement centralisée.
Éviter les migrations automatiques
La ligne de base est que les migrations automatiques semblent initialement bonnes dans les environnements d’équipe, mais en réalité, elles ne fonctionnent pas. Si vous souhaitez savoir pourquoi, continuez à lire – si ce n’est pas le cas, vous pouvez passer à la section suivante.
Les migrations automatiques vous permettent de mettre à jour votre schéma de base de données pour qu’il corresponde au modèle actuel sans avoir besoin de générer des fichiers de code (migrations basées sur du code). Les migrations automatiques fonctionnent très bien dans un environnement d’équipe si vous ne les avez jamais utilisées et n’ont jamais généré de migrations basées sur du code. Le problème est que les migrations automatiques sont limitées et ne gèrent pas un certain nombre de renommages de propriété/colonne d’opérations, déplacement de données vers une autre table, etc. Pour gérer ces scénarios, vous générez des migrations basées sur du code (et modifiez le code généré automatiquement) qui sont mélangées entre les modifications gérées par des migrations automatiques. Cela rend presque impossible la fusion des modifications lorsque deux développeurs vérifient les migrations.
Présentation du fonctionnement des migrations
La clé de l’utilisation des migrations dans un environnement d’équipe est une compréhension de base de la façon dont les migrations effectuent le suivi et utilisent des informations sur le modèle pour détecter les modifications de modèle.
La première migration
Lorsque vous ajoutez la première migration à votre projet, vous exécutez quelque chose comme Add-Migration First dans la console du gestionnaire de paquets. Les étapes générales effectuées par cette commande sont décrites ci-dessous.
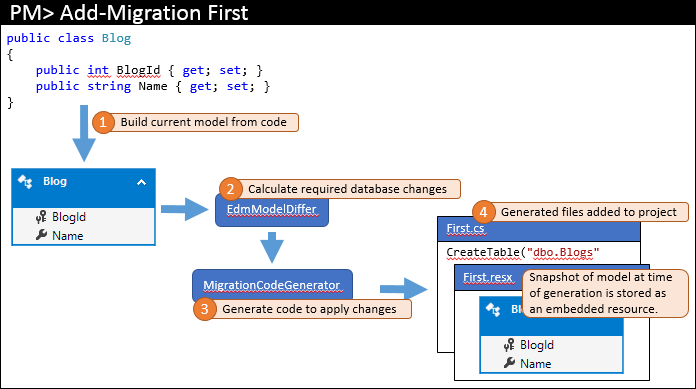
Le modèle actuel est calculé à partir de votre code (1). Les objets de base de données requis sont ensuite calculés par le modèle (2), car il s’agit de la première migration que le modèle diffère simplement utilise un modèle vide pour la comparaison. Les modifications requises sont transmises au générateur de code pour générer le code de migration requis (3) qui est ensuite ajouté à votre solution Visual Studio (4).
Outre le code de migration réel stocké dans le fichier de code principal, les migrations génèrent également des fichiers code-behind supplémentaires. Ces fichiers sont des métadonnées utilisées par les migrations et ne sont pas quelque chose que vous devez modifier. L’un de ces fichiers est un fichier de ressources (.resx) qui contient un instantané du modèle au moment de la génération de la migration. Vous verrez comment cela est utilisé à l’étape suivante.
À ce stade, vous allez probablement exécuter Update-Database pour appliquer vos modifications à la base de données, puis implémenter d’autres domaines de votre application.
Migrations suivantes
Plus tard, vous revenez et apportez quelques modifications à votre modèle – dans notre exemple, nous allons ajouter une propriété URL à Blog. Vous devez ensuite émettre une commande telle que Add-Migration AddUrl pour générer une génération automatique d’une migration pour appliquer les modifications de base de données correspondantes. Les étapes générales effectuées par cette commande sont décrites ci-dessous.
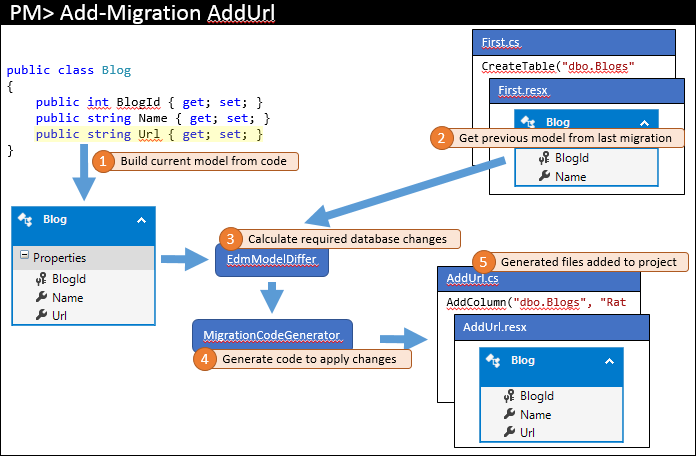
Tout comme la dernière fois, le modèle actuel est calculé à partir du code (1). Toutefois, cette fois,il existe des migrations existantes afin que le modèle précédent soit récupéré à partir de la dernière migration (2). Ces deux modèles sont différents pour rechercher les modifications de base de données requises (3), puis le processus se termine comme avant.
Ce même processus est utilisé pour toutes les migrations supplémentaires que vous ajoutez au projet.
Pourquoi déranger avec l’instantané du modèle ?
Vous vous demandez peut-être pourquoi EF dérange avec l’instantané de modèle, pourquoi ne pas simplement regarder la base de données. Si c’est le cas, lisez-le. Si vous n’êtes pas intéressé, vous pouvez ignorer cette section.
Il existe plusieurs raisons pour lesquelles EF conserve l’instantané de modèle autour :
- Elle permet à votre base de données de dériver du modèle EF. Ces modifications peuvent être apportées directement dans la base de données, ou vous pouvez modifier le code généré automatiquement dans vos migrations pour apporter les modifications. Voici quelques exemples de ceci dans la pratique :
- Vous souhaitez ajouter une colonne insérée et mise à jour à une ou plusieurs de vos tables, mais vous ne souhaitez pas inclure ces colonnes dans le modèle EF. Si les migrations examinaient la base de données, il tenterait continuellement de supprimer ces colonnes chaque fois que vous avez généré une migration. À l’aide de l’instantané de modèle, EF ne détecte jamais les modifications légitimes apportées au modèle.
- Vous souhaitez modifier le corps d’une procédure stockée utilisée pour les mises à jour afin d’inclure une journalisation. Si les migrations examinaient cette procédure stockée à partir de la base de données, elle tenterait continuellement de revenir à la définition attendue par EF. À l’aide de l’instantané de modèle, EF ne crée jamais de code de structure pour modifier la procédure stockée lorsque vous modifiez la forme de la procédure dans le modèle EF.
- Ces mêmes principes s’appliquent à l’ajout d’index supplémentaires, notamment des tables supplémentaires dans votre base de données, le mappage d’EF à une vue de base de données qui se trouve sur une table, etc.
- Le modèle EF contient plus que la forme de la base de données. Le fait de disposer de l’ensemble du modèle permet aux migrations d’examiner les informations sur les propriétés et les classes de votre modèle et leur mappage aux colonnes et tables. Ces informations permettent aux migrations d’être plus intelligentes dans le code qu’elles structurent. Par exemple, si vous modifiez le nom de la colonne qu’une propriété mappe aux migrations peut détecter le renommage en voyant qu’il s’agit de la même propriété – que celle qui ne peut pas être effectuée si vous avez uniquement le schéma de base de données.
Ce qui provoque des problèmes dans les environnements d’équipe
Le flux de travail abordé dans la section précédente fonctionne parfaitement lorsque vous êtes un développeur unique travaillant sur une application. Il fonctionne également bien dans un environnement d’équipe si vous êtes la seule personne qui apporte des modifications au modèle. Dans ce scénario, vous pouvez apporter des modifications de modèle, générer des migrations et les soumettre à votre contrôle de code source. D’autres développeurs peuvent synchroniser vos modifications et exécuter update-Database pour appliquer les modifications de schéma.
Les problèmes commencent à survenir lorsque plusieurs développeurs ont apporté des modifications au modèle EF et que vous soumettez au contrôle de code source en même temps. Ce qu’EF manque est un moyen de première classe de fusionner vos migrations locales avec des migrations envoyées par un autre développeur au contrôle de code source depuis la dernière synchronisation.
Exemple de conflit de fusion
Tout d’abord, examinons un exemple concret de ce conflit de fusion. Nous allons continuer avec l’exemple que nous avons examiné précédemment. Comme point de départ, supposons que les modifications de la section précédente ont été vérifiées par le développeur d’origine. Nous allons suivre deux développeurs au fur et à mesure qu’ils apporteront des modifications à la base de code.
Nous allons suivre le modèle EF et les migrations par le biais d’un certain nombre de modifications. Pour un point de départ, les deux développeurs ont synchronisé avec le référentiel de contrôle de code source, comme illustré dans le graphique suivant.
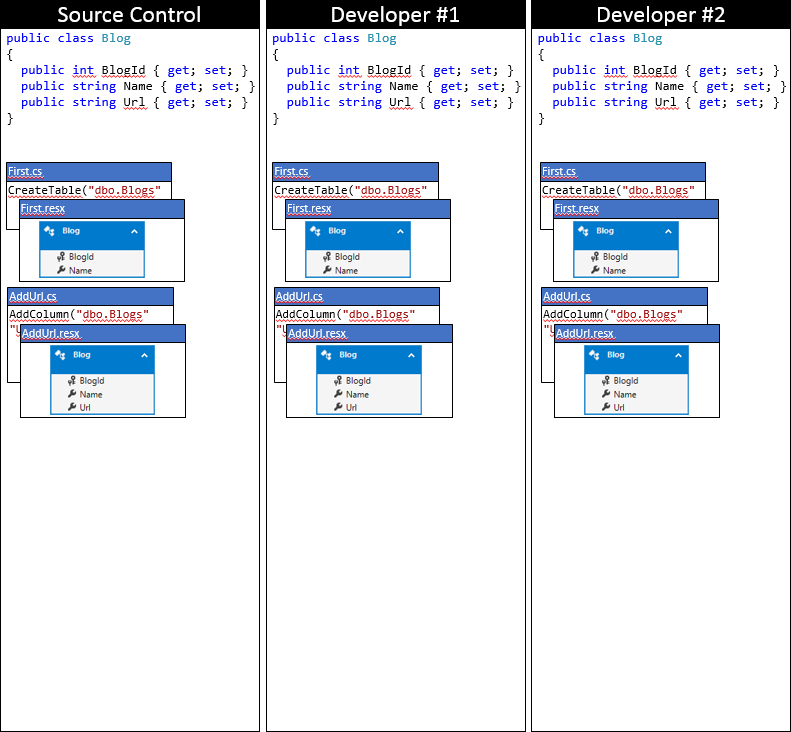
Developer #1 et developer #2 apporte désormais des modifications au modèle EF dans leur base de code locale. Le développeur #1 ajoute une propriété Rating à Blog et génère une migration AddRating pour appliquer les modifications à la base de données. Le développeur #2 ajoute une propriété Reader à blog et génère la migration AddReaders correspondante. Les deux développeurs exécutent Update-Database, pour appliquer les modifications à leurs bases de données locales, puis continuer à développer l’application.
Remarque
Les migrations sont précédées d’un horodatage. Notre graphique représente donc que la migration des AddReaders à partir du développeur #2 vient après la migration AddRating à partir du développeur #1. Que le développeur #1 ou #2 ait généré la migration en premier ne fait aucune différence avec les problèmes de travail dans une équipe, ou le processus de fusion de ceux-ci que nous examinerons dans la section suivante.
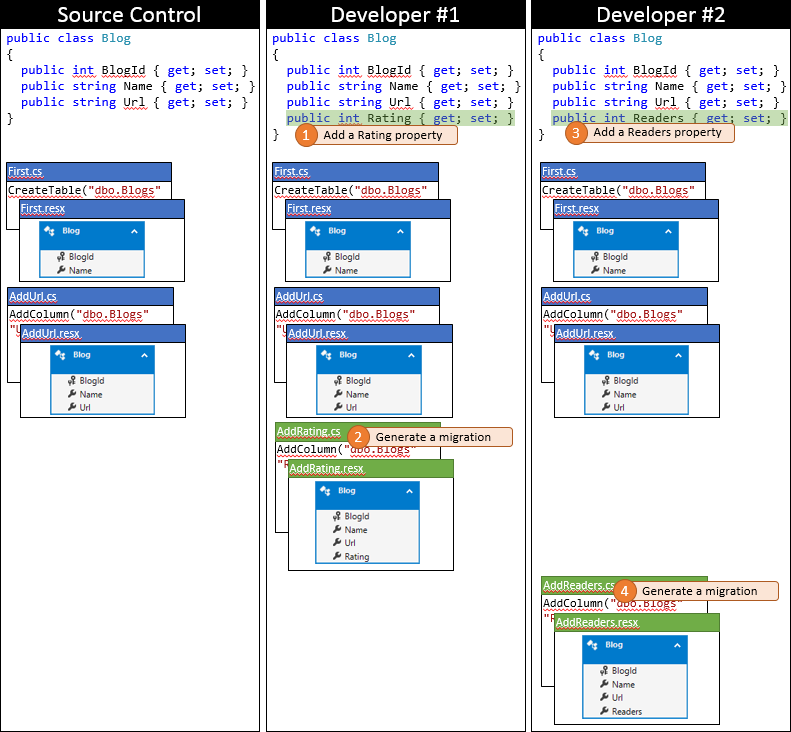
C’est un jour de chance pour le développeur #1, car ils arrivent à soumettre leurs modifications en premier. Comme personne d’autre n’a archivé depuis qu’ils ont synchronisé leur référentiel, ils peuvent simplement soumettre leurs modifications sans effectuer de fusion.
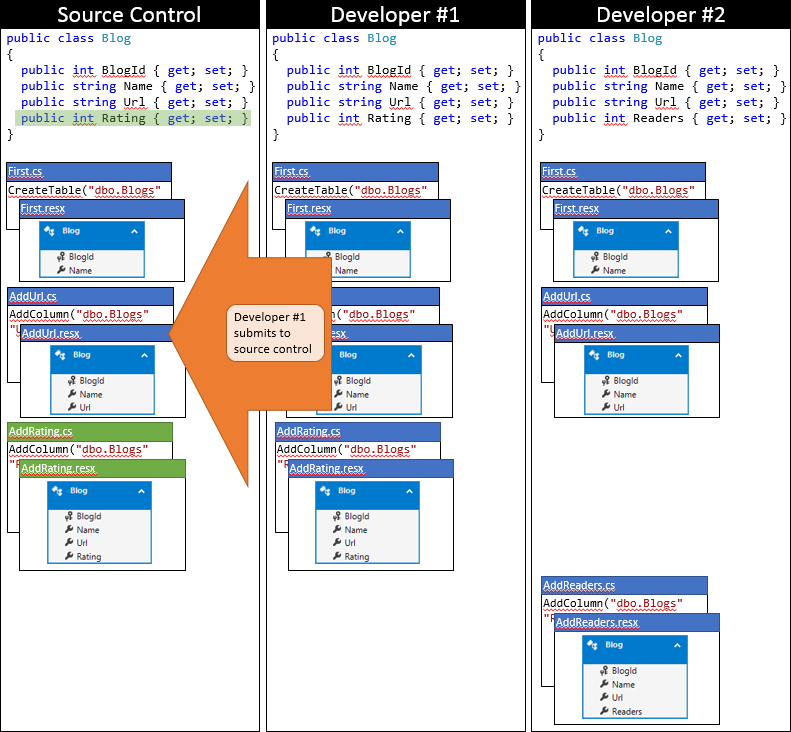
Maintenant, il est temps pour le développeur #2 de soumettre. Ils ne sont pas si chanceux. Étant donné que quelqu’un d’autre a envoyé des modifications depuis leur synchronisation, ils devront extraire les modifications et fusionner. Le système de contrôle de code source sera probablement en mesure de fusionner automatiquement les modifications au niveau du code, car elles sont très simples. L’état du référentiel local du développeur #2 après la synchronisation est représenté dans le graphique suivant.
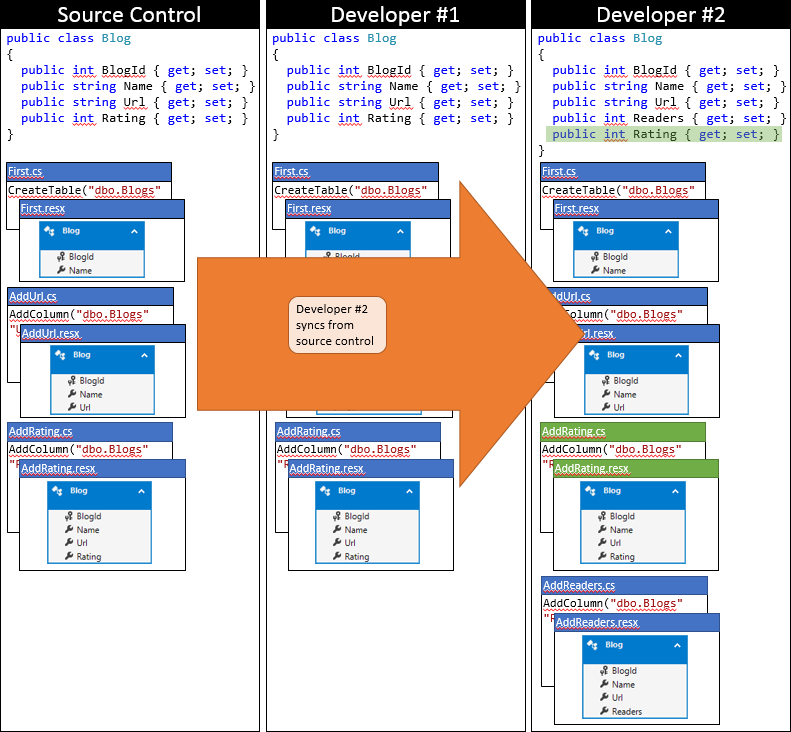
À ce stade, le développeur #2 peut exécuter Update-Database qui détectera la nouvelle migration AddRating (qui n’a pas été appliquée à la base de données du développeur #2) et l’appliquer. À présent, la colonne Rating est ajoutée à la table Blogs et la base de données est synchronisée avec le modèle.
Il y a quelques problèmes cependant :
- Bien que update-database applique le AddRating migration, il génère également un avertissement : Impossible de mettre à jour la base de données pour qu’elle corresponde au modèle actuel, car il existe des modifications en attente et la migration automatique est désactivée… Le problème est que l’instantané de modèle stocké dans la dernière migration (AddReader) manque la propriété Évaluation sur Blog (car elle ne faisait pas partie du modèle lorsque la migration a été générée). Code First détecte que le modèle dans la dernière migration ne correspond pas au modèle actuel et déclenche l’avertissement.
- L’exécution de l’application entraîne une exception InvalidOperationException indiquant que «le modèle qui sauvegarde le contexte « BlogsContext » a changé depuis la création de la base de données. Envisagez d’utiliser code First Migrations pour mettre à jour la base de données…» à nouveau, le problème est que l’instantané de modèle stocké dans la dernière migration ne correspond pas au modèle actuel.
- Enfin, nous nous attendons à ce que l’exécution add-migration génère désormais une migration vide (puisqu’il n’existe aucune modification à appliquer à la base de données). Toutefois, étant donné que les migrations comparent le modèle actuel à celui de la dernière migration (qui ne contient pas la propriété Rating ), il génère en fait une structure d’un autre appel de AddColumn pour ajouter dans la colonne Rating. Bien sûr, cette migration échoue pendant Update-Database, car la colonne Rating existe déjà.
Résolution du conflit de fusion
La bonne nouvelle est qu’il n’est pas trop difficile de gérer la fusion manuellement, à condition que vous compreniez le fonctionnement des migrations. Par conséquent, si vous avez ignoré cette section… Désolé, vous devez revenir en arrière et lire le reste de l’article en premier !
Il existe deux options: la plus simple consiste à générer une migration vide qui a le modèle actuel approprié en tant qu’instantané. La deuxième option consiste à mettre à jour l’instantané dans la dernière migration pour avoir l’instantané de modèle approprié. La deuxième option est un peu plus difficile et ne peut pas être utilisée dans chaque scénario, mais elle est également plus propre, car elle n’implique pas l’ajout d’une migration supplémentaire.
Option 1 : Ajouter une migration de « fusion » vide
Dans cette option, nous générons une migration vide uniquement pour vous assurer que la dernière migration dispose de l’instantané de modèle approprié stocké dans celui-ci.
Cette option peut être utilisée quel que soit l’utilisateur qui a généré la dernière migration. Dans l’exemple, nous avons suivi le développeur #2 pour prendre soin de la fusion et ils se sont produits pour générer la dernière migration. Toutefois, ces mêmes étapes peuvent être utilisées si le développeur #1 a généré la dernière migration. Les étapes s’appliquent également s’il existe plusieurs migrations impliquées, nous venons d’en regarder deux afin de la simplifier.
Le processus suivant peut être utilisé pour cette approche, à partir du moment où vous réalisez que vous avez des modifications qui doivent être synchronisées à partir du contrôle de code source.
- Vérifiez que les modifications de modèle en attente dans votre base de code locale ont été écrites dans une migration. Cette étape vous permet de ne pas manquer de modifications légitimes quand il est temps de générer la migration vide.
- Synchroniser avec le contrôle de code source.
- Exécutez Update-Database pour appliquer les nouvelles migrations que d’autres développeurs ont vérifiées. Remarque : si vous ne recevez aucun avertissement de la commande Update-Database, il n’y a pas eu de nouvelles migrations d’autres développeurs et il n’est pas nécessaire d’effectuer d’autres fusions.
- Exécutez Add-Migration <pick_a_name> –IgnoreChanges (par exemple, Add-Migration Merge –IgnoreChanges). Cela génère une migration avec toutes les métadonnées (y compris un instantané du modèle actuel), mais ignore les modifications qu’il détecte lors de la comparaison du modèle actuel à l’instantané dans les dernières migrations (ce qui signifie que vous obtenez une méthodevide et down ).
- Exécutez Update-Database pour réappliquer la dernière migration avec les métadonnées mises à jour.
- Poursuivez le développement ou envoyez-le au contrôle de code source (après avoir exécuté vos tests unitaires bien sûr).
Voici l’état de la base de code local du développeur #2 après avoir utilisé cette approche.
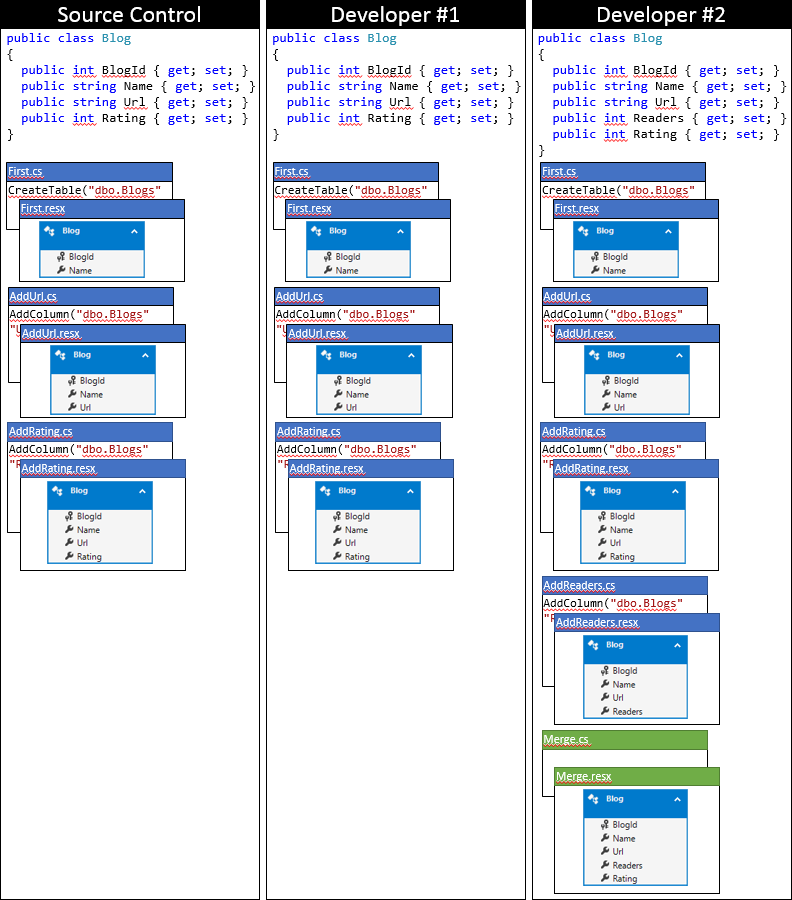
Option 2 : Mettre à jour l’instantané du modèle dans la dernière migration
Cette option est très similaire à l'option 1, mais elle supprime la migration vierge supplémentaire - parce que, soyons honnêtes, qui veut des fichiers de code supplémentaires dans sa solution.
Cette approche n’est possible que si la dernière migration existe uniquement dans votre base de code local et n’a pas encore été soumise au contrôle de code source (par exemple, si la dernière migration a été générée par l’utilisateur effectuant la fusion). La modification des métadonnées des migrations que d'autres développeurs ont déjà appliquées à leur base de données de développement ou, pire encore, à une base de données de production, peut avoir des effets secondaires inattendus. Pendant le processus, nous allons restaurer la dernière migration dans notre base de données locale et l’appliquer à nouveau avec les métadonnées mises à jour.
Même si la dernière migration doit simplement se trouver dans la base de code locale, il n’existe aucune restriction au nombre ou à l’ordre des migrations qui le poursuivent. Il peut y avoir plusieurs migrations provenant de plusieurs développeurs différents et les mêmes étapes s'appliquent - nous n'en avons examiné que deux pour rester simples.
Le processus suivant peut être utilisé pour cette approche, à partir du moment où vous réalisez que vous avez des modifications qui doivent être synchronisées à partir du contrôle de code source.
- Vérifiez que les modifications de modèle en attente dans votre base de code locale ont été écrites dans une migration. Cette étape vous permet de ne pas manquer de modifications légitimes quand il est temps de générer la migration vide.
- Synchroniser avec le contrôle de code source.
- Exécutez Update-Database pour appliquer les nouvelles migrations que d’autres développeurs ont vérifiées. Remarque : si vous ne recevez aucun avertissement de la commande Update-Database, il n’y a pas eu de nouvelles migrations d’autres développeurs et il n’est pas nécessaire d’effectuer d’autres fusions.
- Exécutez Update-Database –TargetMigration <second_last_migration> (dans l’exemple que nous avons suivi, il s’agit Update-Database –TargetMigration AddRating). Cela restaure la base de données à l’état de la deuxième dernière migration –‘sans appliquer’ la dernière migration à partir de la base de données. Remarque : Cette étape est nécessaire pour sécuriser la modification des métadonnées de la migration, car les métadonnées sont également stockées dans la __MigrationsHistoryTable de la base de données. C’est pourquoi vous ne devez utiliser cette option que si la dernière migration se trouve uniquement dans votre base de code locale. Si d’autres bases de données avaient appliqué la dernière migration, vous devrez également les restaurer et réappliquer la dernière migration pour mettre à jour les métadonnées.
- Exécutez Add-Migration <full_name_including_timestamp_of_last_migration>(dans l’exemple que nous avons suivi, il s’agit d’un exemple semblable à Add-Migration 201311062215252_AddReaders). Remarque : Vous devez inclure l’horodatage afin que les migrations sachent que vous souhaitez modifier la migration existante plutôt que d’en échafauder une nouvelle. Cela met à jour les métadonnées de la dernière migration pour qu’elles correspondent au modèle actuel. Vous recevez l’avertissement suivant lorsque la commande est terminée, mais c’est exactement ce que vous voulez. « Seul le code du concepteur pour la migration « 201311062215252_AddReaders » a été généré à nouveau. Pour recréer la structure de la migration entière, utilisez le paramètre -Force. »
- Exécutez Update-Database pour réappliquer la dernière migration avec les métadonnées mises à jour.
- Poursuivez le développement ou envoyez-le au contrôle de code source (après avoir exécuté vos tests unitaires bien sûr).
Voici l’état de la base de code local du développeur #2 après avoir utilisé cette approche.
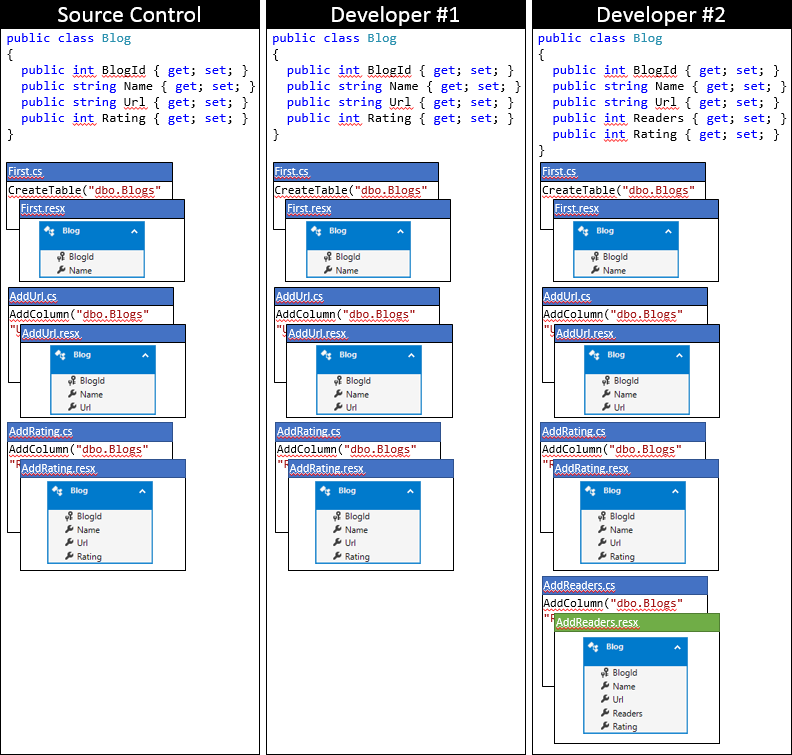
Résumé
Il existe des défis lors de l’utilisation de Code First Migrations dans un environnement d’équipe. Toutefois, une compréhension de base du fonctionnement des migrations et de certaines approches simples pour résoudre les conflits de fusion facilite la résolution de ces défis.
Le problème fondamental est des métadonnées incorrectes stockées dans la dernière migration. Le code Commence par détecter de manière incorrecte que le schéma actuel du modèle et de la base de données ne correspond pas et qu’il génère un code incorrect dans la migration suivante. Cette situation peut être surmontée en générant une migration vide avec le modèle approprié ou en mettant à jour les métadonnées dans la dernière migration.
Commentaires
Bientôt disponible : Tout au long de 2024, nous allons supprimer progressivement GitHub Issues comme mécanisme de commentaires pour le contenu et le remplacer par un nouveau système de commentaires. Pour plus d’informations, consultez https://aka.ms/ContentUserFeedback.
Envoyer et afficher des commentaires pour