Développement de packages de règles d’informations sensibles dans Exchange 2013
S’applique à : Exchange Server 2013
Le schéma XML et les instructions contenues dans cette rubrique vous permettront de vous familiariser avec vos propres fichiers XML de protection contre la perte de données (DLP) de base qui définissent vos propres types d'informations confidentielles dans un package de règles de classification. Une fois que vous avez créé un fichier XML bien formé, vous pouvez l’importer à l’aide du Centre d’administration Exchange ou de l’interpréteur de commandes de gestion Exchange afin de créer une solution DLP Microsoft Exchange Server 2013. Un fichier XML qui est un modèle de stratégie DLP personnalisé peut contenir le code XML qui constitue votre package de règles de classification. Pour obtenir une vue d’ensemble de la définition de vos propres modèles DLP en tant que fichiers XML, consultez Définir vos propres modèles DLP et types d’informations.
Présentation du processus de création de règle
La processus de création de règle se compose des étapes générales suivantes.
Préparer une série de documents de test représentatifs de leur environnement cible. Les principales caractéristiques à prendre en compte pour l’ensemble de documents de test sont les suivantes : Un sous-ensemble des documents contient l’entité ou l’affinité pour laquelle la règle est créée, et un sous-ensemble des documents ne contient pas l’entité ou l’affinité pour laquelle la règle est créée.
Identifier les règles qui répondent aux exigences d'acceptation (précision et rappel) pour identifier le contenu éligible. Cet effort d’identification peut nécessiter le développement de plusieurs conditions au sein d’une règle, liées à une logique booléenne, qui répondent ensemble aux exigences de correspondance minimale pour identifier les documents cibles.
Définir le niveau de confiance recommandé pour les règles basées sur les exigences d'acceptation (précision et rappel). L'élément de confiance recommandé peut être considéré comme le niveau de confiance par défaut pour la règle.
Valider les règles en instanciant une stratégie à leur propos et en surveillant l'exemple de contenu de test. En fonction des résultats, ajustez les règles ou le niveau de confiance pour maximiser le contenu détecté tout en minimisant les faux positifs et négatifs. Poursuivez le cycle de validation et d'ajustement des règles tant qu'un niveau satisfaisant de détection de contenu n'est pas atteint pour les échantillons positifs et négatifs.
Pour plus d’informations sur la définition de schéma XML pour les fichiers de modèle de stratégie, consultez Développement de fichiers de modèle de stratégie DLP.
Description de la règle
Deux grands types de règles peuvent être créés pour le moteur de détection des informations confidentielles DLP : Entité et affinité. Le type de règle choisi est basé sur le type de logique de traitement qui doit être appliquée au traitement du contenu comme décrit dans les sections précédentes. Les définitions de règle sont configurées dans un document XML au format décrit par le XSD des règles standardisées. Les règles décrivent à la fois le type de contenu à faire correspondre et le niveau de confiance avec lequel la correspondance décrite représente le contenu cible. Le niveau de confiance spécifie la probabilité pour l'entité d'être présente si un modèle est détecté dans le contenu ou la probabilité pour l'affinité d'être présente si une preuve est détectée dans le contenu.
Structure de la règle de base
La définition de la règle est construite à partir de trois éléments principaux :
L’entité définit la logique de correspondance et de comptage pour cette règle
L’affinité définit la logique de correspondance pour la règle
Localisation des chaînes localisées pour les noms de règles et leurs descriptions
Trois autres éléments de prise en charge sont utilisés qui définissent les détails du traitement et référencés dans les composants main : Keyword, Regex et Function. En utilisant des références, une définition unique des éléments de prise en charge, comme un numéro de sécurité sociale, peut être utilisée dans plusieurs règles d'entité ou d'affinité. La structure de la règle de base au format XML peut être vue comme suit.
<?xml version="1.0" encoding="utf-8"?>
<RulePackage xmlns="http://schemas.microsoft.com/office/2011/mce">
<RulePack id="DAD86A92-AB18-43BB-AB35-96F7C594ADAA">
<Version major="1" minor="0" build="0" revision="0"/>
<Publisher id="619DD8C3-7B80-4998-A312-4DF0402BAC04"/>
<Details defaultLangCode="en-us">
<LocalizedDetails langcode="en-us">
<PublisherName>DLP by EPG</PublisherName>
<Name>CSO Custom Rule Pack</Name>
<Description>This is a rule package for a EPG demo.</Description>
</LocalizedDetails>
</Details>
</RulePack>
<Rules>
<!-- Employee ID -->
<Entity id="E1CC861E-3FE9-4A58-82DF-4BD259EAB378" patternsProximity="300" recommendedConfidence="75">
<Pattern confidenceLevel="75">
<IdMatch idRef="Regex_employee_id" />
<Match idRef="Keyword_employee" />
</Pattern>
</Entity>
<Regex id="Regex_employee_id">(\s)(\d{9})(\s)</Regex>
<Keyword id="Keyword_employee">
<Group matchStyle="word">
<Term>Identification</Term>
<Term>Contoso Employee</Term>
</Group>
</Keyword>
<LocalizedStrings>
<Resource idRef="E1CC861E-3FE9-4A58-82DF-4BD259EAB378">
<Name default="true" langcode="en-us">
Employee ID
</Name>
<Description default="true" langcode="en-us">
A custom classification for detecting Employee ID's
</Description>
</Resource>
</LocalizedStrings>
</Rules>
</RulePackage>
Règles d'entité
Les règles d’entité sont destinées à des identificateurs bien définis, tels que le numéro de sécurité sociale, et sont représentées par une collection de modèles d’identification d’identité. Les règles d'entité renvoient un nombre et le niveau de confiance d'une correspondance, où le nombre correspond au nombre total d'instances de l'entité qui ont été détectées et où le niveau de confiance est la probabilité que l'entité donnée existe dans le document en question. L’entité contient l’attribut « Id » comme identificateur unique. L'identificateur est utilisé pour la localisation, la gestion des versions et l'exécution de requêtes. L’ID d’entité doit être un GUID. L’ID d’entité ne doit pas être dupliqué dans d’autres entités ou affinités. Il est référencé dans la section chaînes localisées.
Les règles d’entité contiennent l’attribut facultatif patternsProximity (par défaut = 300) qui est utilisé lors de l’application d’une logique booléenne pour spécifier l’adjacence de plusieurs modèles requis pour satisfaire la condition de correspondance. L’élément Entity contient un ou plusieurs éléments de modèle enfants, où chaque modèle est une représentation distincte de l’entité comme l’entité de carte de crédit ou l’entité de permis de conduire. L’élément Pattern a un attribut obligatoire de confidenceLevel qui représente la précision du modèle en fonction de l’exemple de jeu de données. L'élément Pattern peut avoir trois éléments enfants :
IdMatch : cet élément est obligatoire.
Match
N’importe lequel
Si l’un des éléments Pattern retourne « true », le modèle est satisfait. Le nombre pour l'élément Entity équivaut à la somme de tous les nombres de modèles détectés.
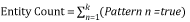
où k est le nombre d'éléments Pattern pour l'entité.
Un élément Pattern doit avoir un élément IdMatch unique. IdMatch représente l'identificateur avec lequel le modèle doit correspondre, par exemple un numéro de carte de crédit ou un numéro ITIN. Le nombre pour un modèle est le nombre d'IdMatches correspondant à l'élément Pattern. L'élément IdMatch ancre la fenêtre de proximité pour les éléments de correspondance.
Un autre sous-élément facultatif de l’élément Pattern est l’élément Match qui représente la preuve corroborative qui doit être mise en correspondance pour prendre en charge la recherche de l’élément IdMatch. Par exemple, la règle de confiance plus élevée peut exiger qu’en plus de trouver un numéro de carte de crédit, des artefacts supplémentaires existent dans le document, dans une fenêtre de proximité du carte de crédit, comme l’adresse et le nom. Ces artefacts supplémentaires sont représentés par l’élément Match ou l’élément Any (décrit en détail dans la section Méthodes et techniques de correspondance). Plusieurs éléments Match peuvent être inclus dans une définition Pattern, qui peut être incluse directement dans l’élément Pattern ou combinée à l’aide de l’élément Any pour définir la sémantique correspondante. Elle renvoie la valeur « true » si une correspondance est détectée dans la fenêtre de proximité ancrée autour du contenu IdMatch.
Les éléments IdMatch et Match ne définissent pas les détails du contenu qui doit être mis en correspondance, mais le référencent via l’attribut idRef. Ce référencement favorise la réutilisation des définitions dans plusieurs constructions de modèle.
<Entity id="..." patternsProximity="300" >
<Pattern confidenceLevel="85">
<IdMatch idRef="FormattedSSN" />
<Any minMatches="1">
<Match idRef="SSNKeyword" />
<Match idRef="USDate" />
<Match idRef="USAddress" />
<Match idRef="Name" />
</Any>
</Pattern>
<Pattern confidenceLevel="65">
<IdMatch idRef="UnformattedSSN" />
<Match idRef="SSNKeyword" />
<Any minMatches="1">
<Match idRef="USDate" />
<Match idRef="USAddress" />
<Match idRef="Name" />
</Any>
</Pattern>
</Entity>
L’élément Entity Id, représenté dans le code XML précédent par « ... » doit être un GUID et il est référencé dans la section Chaînes localisées.
Fenêtre de proximité d'un modèle d'entité
L’entité contient la valeur facultative de l’attribut patternsProximity (integer, default = 300) utilisée pour rechercher les modèles. Pour chaque modèle, la valeur d’attribut définit la distance (en caractères Unicode) à partir de l’emplacement IdMatch pour toutes les autres correspondances spécifiées pour ce modèle. La fenêtre de proximité est ancrée par l’emplacement IdMatch, la fenêtre s’étendant à gauche et à droite de l’IdMatch.
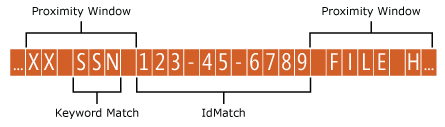
L’exemple ci-dessous illustre la façon dont la fenêtre de proximité affecte l’algorithme de correspondance où l’élément SSN IdMatch nécessite au moins l’une des correspondances d’adresse, de nom ou de date corroborant. Seuls SSN1 et SSN4 correspondent, car pour SSN2 et SSN3, seule une preuve probante partielle – voire aucune preuve probante – a été détectée au sein de la fenêtre de proximité.
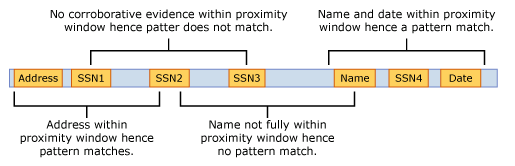
Le corps du message et chaque pièce jointe sont traités comme des éléments indépendants. Cette condition signifie que la fenêtre de proximité ne s’étend pas au-delà de la fin de chacun de ces éléments. Pour chaque élément (pièce jointe ou corps), la preuve idMatch et la preuve corroborative doivent résider dans chacun d’eux.
Niveau de confiance de l'entité
Le niveau de confiance de l'élément Entity correspond à l'association de l'ensemble des niveaux de confiance satisfaits pour le modèle. Ils sont combinés à l’aide de l’équation suivante :
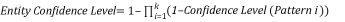
où k est le nombre d’éléments Pattern pour l’entité et un modèle qui ne correspond pas retourne un niveau de confiance de 0.
En se référant à l'exemple de code de structure de l'élément de l'entité de l'exemple, si les deux modèles sont mis en correspondance, le niveau de confiance de l'entité dépend à 94,75 % du calcul suivant :
Entité CL = 1-[(1-CL Pattern1) x (1-CLPattern1)]
= 1-[(1-0.85) x (1-0.65)]
= 1-(0.15 x 0.35)
= 94,75 %
De même, si seul le deuxième modèle établit une correspondance, le niveau de confiance de l'entité dépend à 65 % du calcul suivant :
Entité CL = 1 - [(1 - Modèle CL1) X (1 -Modèle CL1)]
= 1 - [(1 - 0) X (1 - 0,65)]
= 1 - (1 X 0,35)
= 65 %
Ces valeurs de confiance sont attribuées dans les règles concernant les modèles individuels à partir de l'ensemble de documents de test validés dans le cadre du processus de création de règle.
Règles d'affinité
Les règles d’affinité sont ciblées vers du contenu sans identificateur bien défini, par exemple Sarbanes-Oxley ou du contenu financier d’entreprise. Pour ce contenu, aucun identificateur cohérent unique ne peut être trouvé et à la place l’analyse nécessite de déterminer si une collection de preuves est présente. Les règles d’affinité ne retournent pas de nombre, mais elles retournent si elles sont trouvées et le niveau de confiance associé. Le contenu d’affinité est représenté sous la forme d’une collection de preuves indépendantes. La preuve est une agrégation de correspondances requises dans une certaine proximité. Pour la règle d’affinité, la proximité est définie par l’attribut evidencesProximity (la valeur par défaut est 600) et le niveau de confiance minimal par l’attribut thresholdConfidenceLevel.
Les règles d’affinité contiennent l’attribut Id de son identificateur unique utilisé pour la localisation, le contrôle de version et l’interrogation. Contrairement aux règles d’entité, étant donné que les règles d’affinité ne reposent pas sur des identificateurs bien définis, elles ne contiennent pas l’élément IdMatch.
Chaque règle d’affinité contient un ou plusieurs éléments de preuve enfants qui définissent la preuve à trouver et le niveau de confiance qui contribue à la règle d’affinité. L’affinité n’est pas considérée comme trouvée si le niveau de confiance résultant est inférieur au niveau de seuil. Chaque preuve représente logiquement une preuve corroborative pour ce « type » de document et l’attribut confidenceLevel est la précision de cette preuve sur le jeu de données de test.
Les éléments Evidence ont un ou plusieurs éléments enfants Match ou Any. Si tous les éléments Match et Any enfants correspondent, la preuve est trouvée et le niveau de confiance est affecté au calcul du niveau de confiance des règles. La même description s'applique aux éléments Match ou Any des règles d'affinité pour les règles d'entité.
<Affinity id="..."
evidencesProximity="1000"
thresholdConfidenceLevel="65">
<Evidence confidenceLevel="40">
<Any>
<Match idRef="AssetsTerms" />
<Match idRef="BalanceSheetTerms" />
<Match idRef="ProfitAndLossTerms" />
</Any>
</Evidence>
<Evidence confidenceLevel="40">
<Any minMatches="2">
<Match idRef="TaxTerms" />
<Match idRef="DollarAmountTerms" />
<Match idRef="SECTerms" />
<Match idRef="SECFilingFormTerms" />
<Match idRef="DollarTotalRegex" />
</Any>
</Evidence>
</Affinity>
Fenêtre de proximité d'affinité
La fenêtre de proximité pour l'affinité est calculée de façon différente que pour les modèles d'entité. La proximité d'affinité suit un modèle de fenêtre coulissante. L'algorithme de proximité de l'affinité tente de rechercher le nombre maximal de preuves correspondantes dans la fenêtre donnée. Les preuves de la fenêtre de proximité doivent présenter un niveau de confiance supérieure au seuil défini pour la règle d'affinité à trouver.

Niveau de confiance d'affinité
Le niveau de confiance de l'affinité équivaut à l'association des preuves détectées au sein de la fenêtre de proximité pour la règle de proximité. Bien que similaire au niveau de confiance de la règle de l'entité, la principale différence est l'application de la fenêtre de proximité. Similaire aux règles d'entité, le niveau de confiance de l'élément Affinity est la combinaison de l'ensemble des niveaux de confiance de preuves remplis, mais pour la règle d'affinité, il représente uniquement la combinaison la plus élevée des éléments Evidence détectés au sein de la fenêtre de proximité. Les niveaux de confiance des preuves sont combinés à l'aide de l'équation suivante :
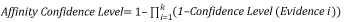
où k est le nombre d'éléments Evidence pour l'affinité associé au sein de la fenêtre de proximité.
En se référant à la structure de la règle d'affinité de l'exemple de la Figure 4, si les trois preuves sont mises en correspondance au sein de la fenêtre coulissante de proximité, le niveau de confiance de l'affinité dépend à 85,6 % du calcul suivant. Cette valeur dépasse le seuil de la règle d’affinité de 65, ce qui entraîne la correspondance de la règle.
Affinité CL = 1 - [(1 - Preuve CL 1) X (1 -Preuve CL 2) X (1 - Preuve CL2)]
= 1 - [(1 - 0,6) X (1 - 0,4) X (1 - 0,4)]
= 1 - (0,4 x 0,6 x 0,6)
= 85,6 %
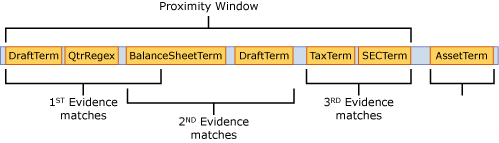
En utilisant le même exemple de définition de règle, si seule la première preuve correspond, car la deuxième preuve est en dehors de la fenêtre de proximité, le niveau de confiance d’affinité le plus élevé est de 60 % selon le calcul ci-dessous et la règle d’affinité ne correspond pas, car le seuil de 65 n’a pas été atteint.
Affinité CL = 1 - [(1 - Preuve CL 1) X (1 -Preuve CL 2) X (1 - Preuve CL2)]
= 1 - [(1 - 0.6) X (1 - 0) X (1 - 0) ]
= 1 - (0,4 x 1 x 1)
= 60 %
Réglage des niveaux de confiance
L'un des principaux aspects du processus de création de règle est le réglage des niveaux de confiance pour les règles d'entité et d'affinité. Après la création des définitions de la règle, exécutez la règle sur le contenu représentatif et recueillez les données de précision. Comparez les résultats renvoyés pour chaque modèle ou preuve par rapport aux résultats prévus pour les documents de test.
Si les règles répondent aux exigences d’acceptation, c’est-à-dire que le modèle ou la preuve a un taux de confiance supérieur à un seuil établi (par exemple, 75 %), l’expression de correspondance est terminée et elle peut être déplacée à l’étape suivante.
Si le modèle ou la preuve ne répond pas au niveau de confiance, réautorisez-le (par exemple, ajoutez des preuves plus corroboratives, supprimez ou ajoutez des modèles/preuves supplémentaires, etc.) et répétez cette étape.
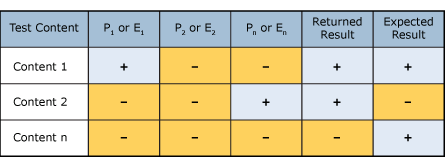
Ensuite, ajustez le niveau de confiance de chaque modèle ou preuve dans vos règles à partir des résultats de l'étape précédente. Pour chaque modèle ou preuve, agrègez le nombre de vrais positifs (TP), sous-ensemble des documents qui contiennent l’entité ou l’affinité pour laquelle la règle est créée et qui ont abouti à une correspondance et le nombre de faux positifs (FP), un sous-ensemble de documents qui ne contiennent pas l’entité ou l’affinité pour lesquelles la règle est créée et qui ont également retourné une correspondance. Définissez le niveau de confiance pour chaque modèle et preuve à l'aide du calcul suivant :
Niveau de confiance = vrais positifs / (vrais positifs + faux positifs)
| Modèle ou preuve | Vrais positifs | Faux positifs | Niveau de confiance |
|---|---|---|---|
| P1ou E1 | 4 | 1 | 80 % |
| P2ou E2 | 2 | 2 | 50% |
| Pnou En | 9 | 10 | 47% |
Utilisation des langues locales dans votre fichier XML
Le schéma de règle prend en charge le stockage de nom et de description localisés pour chaque élément Entity et Affinity. Chaque élément Entity et Affinity doit avoir un élément correspondant dans la section LocalizedStrings. Pour localiser chaque élément, incluez un élément Resource en tant qu'enfant de l'élément LocalizedStrings pour stocker le nom et les descriptions de plusieurs paramètres régionaux de chaque élément. L’élément Resource inclut un attribut idRef requis qui correspond à l’attribut idRef correspondant pour chaque élément en cours de localisation. Les éléments enfants Locale de l’élément Resource contiennent le nom localisé et les descriptions de chaque paramètre régional spécifié.
<LocalizedStrings>
<Resource idRef="guid">
<Locale langcode="en-US" default="true">
<Name>affinity name en-us</Name>
<Description>
affinity description en-us
</Description>
</Locale>
<Locale langcode="de">
<Name>affinity name de</Name>
<Description>
affinity description de
</Description>
</Locale>
</Resource>
</LocalizedStrings>
Définition de schéma XML du pack de règle de classification
<?xml version="1.0" encoding="utf-8"?>
<xs:schema xmlns:mce="http://schemas.microsoft.com/office/2011/mce"
targetNamespace="http://schemas.microsoft.com/office/2011/mce"
xmlns:xs="http://www.w3.org/2001/XMLSchema"
elementFormDefault="qualified"
attributeFormDefault="unqualified"
id="RulePackageSchema">
<xs:simpleType name="LangType">
<xs:union memberTypes="xs:language">
<xs:simpleType>
<xs:restriction base="xs:string">
<xs:enumeration value=""/>
</xs:restriction>
</xs:simpleType>
</xs:union>
</xs:simpleType>
<xs:simpleType name="GuidType" final="#all">
<xs:restriction base="xs:token">
<xs:pattern value="[0-9a-fA-F]{8}\-([0-9a-fA-F]{4}\-){3}[0-9a-fA-F]{12}"/>
</xs:restriction>
</xs:simpleType>
<xs:complexType name="RulePackageType">
<xs:sequence>
<xs:element name="RulePack" type="mce:RulePackType"/>
<xs:element name="Rules" type="mce:RulesType">
<xs:key name="UniqueRuleId">
<xs:selector xpath="mce:Entity|mce:Affinity"/>
<xs:field xpath="@id"/>
</xs:key>
<xs:key name="UniqueProcessorId">
<xs:selector xpath="mce:Regex|mce:Keyword"></xs:selector>
<xs:field xpath="@id"/>
</xs:key>
<xs:key name="UniqueResourceIdRef">
<xs:selector xpath="mce:LocalizedStrings/mce:Resource"/>
<xs:field xpath="@idRef"/>
</xs:key>
<xs:keyref name="ReferencedRuleMustExist" refer="mce:UniqueRuleId">
<xs:selector xpath="mce:LocalizedStrings/mce:Resource"/>
<xs:field xpath="@idRef"/>
</xs:keyref>
<xs:keyref name="RuleMustHaveResource" refer="mce:UniqueResourceIdRef">
<xs:selector xpath="mce:Entity|mce:Affinity"/>
<xs:field xpath="@id"/>
</xs:keyref>
</xs:element>
</xs:sequence>
</xs:complexType>
<xs:complexType name="RulePackType">
<xs:sequence>
<xs:element name="Version" type="mce:VersionType"/>
<xs:element name="Publisher" type="mce:PublisherType"/>
<xs:element name="Details" type="mce:DetailsType">
<xs:key name="UniqueLangCodeInLocalizedDetails">
<xs:selector xpath="mce:LocalizedDetails"/>
<xs:field xpath="@langcode"/>
</xs:key>
<xs:keyref name="DefaultLangCodeMustExist" refer="mce:UniqueLangCodeInLocalizedDetails">
<xs:selector xpath="."/>
<xs:field xpath="@defaultLangCode"/>
</xs:keyref>
</xs:element>
<xs:element name="Encryption" type="mce:EncryptionType" minOccurs="0" maxOccurs="1"/>
</xs:sequence>
<xs:attribute name="id" type="mce:GuidType" use="required"/>
</xs:complexType>
<xs:complexType name="VersionType">
<xs:attribute name="major" type="xs:unsignedShort" use="required"/>
<xs:attribute name="minor" type="xs:unsignedShort" use="required"/>
<xs:attribute name="build" type="xs:unsignedShort" use="required"/>
<xs:attribute name="revision" type="xs:unsignedShort" use="required"/>
</xs:complexType>
<xs:complexType name="PublisherType">
<xs:attribute name="id" type="mce:GuidType" use="required"/>
</xs:complexType>
<xs:complexType name="LocalizedDetailsType">
<xs:sequence>
<xs:element name="PublisherName" type="mce:NameType"/>
<xs:element name="Name" type="mce:RulePackNameType"/>
<xs:element name="Description" type="mce:OptionalNameType"/>
</xs:sequence>
<xs:attribute name="langcode" type="mce:LangType" use="required"/>
</xs:complexType>
<xs:complexType name="DetailsType">
<xs:sequence>
<xs:element name="LocalizedDetails" type="mce:LocalizedDetailsType" maxOccurs="unbounded"/>
</xs:sequence>
<xs:attribute name="defaultLangCode" type="mce:LangType" use="required"/>
</xs:complexType>
<xs:complexType name="EncryptionType">
<xs:sequence>
<xs:element name="Key" type="xs:normalizedString"/>
<xs:element name="IV" type="xs:normalizedString"/>
</xs:sequence>
</xs:complexType>
<xs:simpleType name="RulePackNameType">
<xs:restriction base="xs:token">
<xs:minLength value="1"/>
<xs:maxLength value="64"/>
</xs:restriction>
</xs:simpleType>
<xs:simpleType name="NameType">
<xs:restriction base="xs:normalizedString">
<xs:minLength value="1"/>
<xs:maxLength value="256"/>
</xs:restriction>
</xs:simpleType>
<xs:simpleType name="OptionalNameType">
<xs:restriction base="xs:normalizedString">
<xs:minLength value="0"/>
<xs:maxLength value="256"/>
</xs:restriction>
</xs:simpleType>
<xs:simpleType name="RestrictedTermType">
<xs:restriction base="xs:string">
<xs:minLength value="1"/>
<xs:maxLength value="512"/>
</xs:restriction>
</xs:simpleType>
<xs:complexType name="RulesType">
<xs:sequence>
<xs:choice maxOccurs="unbounded">
<xs:element name="Entity" type="mce:EntityType"/>
<xs:element name="Affinity" type="mce:AffinityType"/>
</xs:choice>
<xs:choice minOccurs="0" maxOccurs="unbounded">
<xs:element name="Regex" type="mce:RegexType"/>
<xs:element name="Keyword" type="mce:KeywordType"/>
</xs:choice>
<xs:element name="LocalizedStrings" type="mce:LocalizedStringsType"/>
</xs:sequence>
</xs:complexType>
<xs:complexType name="EntityType">
<xs:sequence>
<xs:element name="Pattern" type="mce:PatternType" maxOccurs="unbounded"/>
</xs:sequence>
<xs:attribute name="id" type="mce:GuidType" use="required"/>
<xs:attribute name="patternsProximity" type="mce:ProximityType" use="required"/>
<xs:attribute name="recommendedConfidence" type="mce:ProbabilityType"/>
<xs:attribute name="workload" type="mce:WorkloadType"/>
</xs:complexType>
<xs:complexType name="PatternType">
<xs:sequence>
<xs:element name="IdMatch" type="mce:IdMatchType"/>
<xs:choice minOccurs="0" maxOccurs="unbounded">
<xs:element name="Match" type="mce:MatchType"/>
<xs:element name="Any" type="mce:AnyType"/>
</xs:choice>
</xs:sequence>
<xs:attribute name="confidenceLevel" type="mce:ProbabilityType" use="required"/>
</xs:complexType>
<xs:complexType name="AffinityType">
<xs:sequence>
<xs:element name="Evidence" type="mce:EvidenceType" maxOccurs="unbounded"/>
</xs:sequence>
<xs:attribute name="id" type="mce:GuidType" use="required"/>
<xs:attribute name="evidencesProximity" type="mce:ProximityType" use="required"/>
<xs:attribute name="thresholdConfidenceLevel" type="mce:ProbabilityType" use="required"/>
<xs:attribute name="workload" type="mce:WorkloadType"/>
</xs:complexType>
<xs:complexType name="EvidenceType">
<xs:sequence>
<xs:choice maxOccurs="unbounded">
<xs:element name="Match" type="mce:MatchType"/>
<xs:element name="Any" type="mce:AnyType"/>
</xs:choice>
</xs:sequence>
<xs:attribute name="confidenceLevel" type="mce:ProbabilityType" use="required"/>
</xs:complexType>
<xs:complexType name="IdMatchType">
<xs:attribute name="idRef" type="xs:string" use="required"/>
</xs:complexType>
<xs:complexType name="MatchType">
<xs:attribute name="idRef" type="xs:string" use="required"/>
</xs:complexType>
<xs:complexType name="AnyType">
<xs:sequence>
<xs:choice maxOccurs="unbounded">
<xs:element name="Match" type="mce:MatchType"/>
<xs:element name="Any" type="mce:AnyType"/>
</xs:choice>
</xs:sequence>
<xs:attribute name="minMatches" type="xs:nonNegativeInteger" default="1"/>
<xs:attribute name="maxMatches" type="xs:nonNegativeInteger" use="optional"/>
</xs:complexType>
<xs:simpleType name="ProximityType">
<xs:restriction base="xs:positiveInteger">
<xs:minInclusive value="1"/>
</xs:restriction>
</xs:simpleType>
<xs:simpleType name="ProbabilityType">
<xs:restriction base="xs:integer">
<xs:minInclusive value="1"/>
<xs:maxInclusive value="100"/>
</xs:restriction>
</xs:simpleType>
<xs:simpleType name="WorkloadType">
<xs:restriction base="xs:string">
<xs:enumeration value="Exchange"/>
<xs:enumeration value="Outlook"/>
</xs:restriction>
</xs:simpleType>
<xs:complexType name="RegexType">
<xs:simpleContent>
<xs:extension base="xs:string">
<xs:attribute name="id" type="xs:token" use="required"/>
</xs:extension>
</xs:simpleContent>
</xs:complexType>
<xs:complexType name="KeywordType">
<xs:sequence>
<xs:element name="Group" type="mce:GroupType" maxOccurs="unbounded"/>
</xs:sequence>
<xs:attribute name="id" type="xs:token" use="required"/>
</xs:complexType>
<xs:complexType name="GroupType">
<xs:sequence>
<xs:choice>
<xs:element name="Term" type="mce:TermType" maxOccurs="unbounded"/>
</xs:choice>
</xs:sequence>
<xs:attribute name="matchStyle" default="word">
<xs:simpleType>
<xs:restriction base="xs:NMTOKEN">
<xs:enumeration value="word"/>
<xs:enumeration value="string"/>
</xs:restriction>
</xs:simpleType>
</xs:attribute>
</xs:complexType>
<xs:complexType name="TermType">
<xs:simpleContent>
<xs:extension base="mce:RestrictedTermType">
<xs:attribute name="caseSensitive" type="xs:boolean" default="false"/>
</xs:extension>
</xs:simpleContent>
</xs:complexType>
<xs:complexType name="LocalizedStringsType">
<xs:sequence>
<xs:element name="Resource" type="mce:ResourceType" maxOccurs="unbounded">
<xs:key name="UniqueLangCodeUsedInNamePerResource">
<xs:selector xpath="mce:Name"/>
<xs:field xpath="@langcode"/>
</xs:key>
<xs:key name="UniqueLangCodeUsedInDescriptionPerResource">
<xs:selector xpath="mce:Description"/>
<xs:field xpath="@langcode"/>
</xs:key>
</xs:element>
</xs:sequence>
</xs:complexType>
<xs:complexType name="ResourceType">
<xs:sequence>
<xs:element name="Name" type="mce:ResourceNameType" maxOccurs="unbounded"/>
<xs:element name="Description" type="mce:DescriptionType" minOccurs="0" maxOccurs="unbounded"/>
</xs:sequence>
<xs:attribute name="idRef" type="mce:GuidType" use="required"/>
</xs:complexType>
<xs:complexType name="ResourceNameType">
<xs:simpleContent>
<xs:extension base="xs:string">
<xs:attribute name="default" type="xs:boolean" default="false"/>
<xs:attribute name="langcode" type="mce:LangType" use="required"/>
</xs:extension>
</xs:simpleContent>
</xs:complexType>
<xs:complexType name="DescriptionType">
<xs:simpleContent>
<xs:extension base="xs:string">
<xs:attribute name="default" type="xs:boolean" default="false"/>
<xs:attribute name="langcode" type="mce:LangType" use="required"/>
</xs:extension>
</xs:simpleContent>
</xs:complexType>
</xs:schema>