Notes
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Dans ce tutoriel, découvrez comment créer une définition de tâche Spark dans Microsoft Fabric.
Prérequis
Avant de commencer, vous avez besoin des éléments suivants :
- Un compte de locataire Fabric avec un abonnement actif. Créez un compte gratuitement.
Conseil
Pour exécuter l'élément de définition de tâche Spark, vous devez disposer d'un fichier de définition principal et d'un contexte Lakehouse par défaut. Si vous n’avez pas de lakehouse, vous pouvez en créer un en suivant les étapes décrites dans Créer un lakehouse.
Créer une définition de travail Spark
Le processus de création de définition de tâche Spark est rapide et simple ; il existe plusieurs façons de commencer.
Options permettant de créer une définition de tâche Spark
Il existe deux façons de commencer avec le processus de création :
Vue de l’espace de travail : vous pouvez facilement créer une définition de tâche Spark via l’espace de travail Fabric en sélectionnant Nouvel élément>Définition de tâche Spark.
Accueil Fabric : un autre point d’entrée pour créer une définition de tâche Spark est la vignette Analytique données via SQL… sur la page d’accueil Fabric. Vous pouvez trouver cette même option en sélectionnant la vignette Général.

Vous devez donner un nom à votre définition de tâche Spark lorsque vous la créez. Ce nom doit être unique dans l’espace de travail actuel. La nouvelle définition de tâche Spark est créée dans votre espace de travail actuel.
Créer une définition de tâche Apache Spark pour PySpark (Python)
Pour créer une définition de tâche Spark pour PySpark :
Téléchargez l'exemple de fichier Parquet yellow_tripdata_2022-01.parquet et téléchargez-le dans la section des fichiers du lakehouse.
Créez une définition de tâche Spark.
Sélectionnez PySpark (Python) dans la liste déroulante Langage.
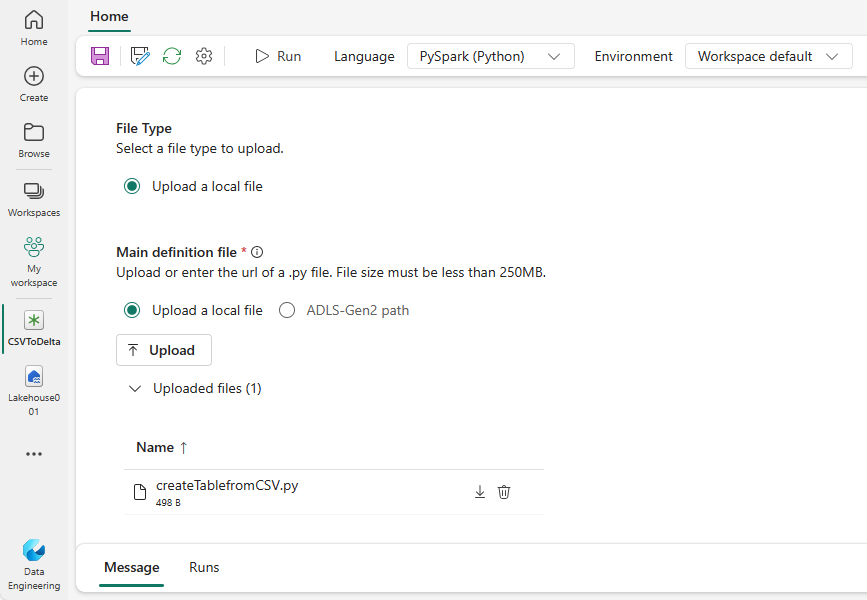
Téléchargez l'exemple createTablefromParquet.py et chargez-le en tant que fichier de définition principal. Le fichier de définition principal (job.Main) est le fichier qui contient la logique de l'application et est obligatoire pour exécuter une tâche Spark. Pour chaque définition de tâche Spark, vous ne pouvez télécharger qu'un seul fichier de définition principal.
Vous pouvez télécharger le fichier de définition principal à partir de votre bureau local ou à partir d’un Azure Data Lake Storage (ADLS) Gen2 existant en fournissant le chemin ABFSS complet du fichier. Par exemple :
abfss://your-storage-account-name.dfs.core.windows.net/your-file-path.Téléchargez les fichiers de référence sous forme de fichiers .py. Les fichiers de référence sont les modules Python importés par le fichier de définition principal. Tout comme le fichier de définition principal, vous pouvez le télécharger depuis votre bureau ou depuis un ADLS Gen2 existant. Plusieurs fichiers de référence sont pris en charge.
Conseil
Si vous utilisez un chemin ADLS Gen2, pour vous assurer que le fichier est accessible, vous devez accorder au compte utilisateur qui exécute la tâche l'autorisation appropriée sur le compte de stockage. Nous vous proposons deux manières différentes de procéder :
- Attribuez au compte utilisateur un rôle de contributeur pour le compte de stockage.
- Accordez l’autorisation de lecture et d’exécution au compte utilisateur pour le fichier via la liste de contrôle d’accès (ACL) ADLS Gen2.
Pour une exécution manuelle, le compte de l'utilisateur actuellement connecté est utilisé pour exécuter la tâche.
Fournissez des arguments de ligne de commande pour le travail, si nécessaire. Utilisez un espace comme séparateur pour séparer les arguments.
Ajoutez la référence lakehouse au travail. Vous devez avoir au moins une référence lakehouse ajoutée au travail. Ce lakehouse est le contexte lakehouse par défaut pour le travail.
Plusieurs références lakehouse sont prises en charge. Recherchez le nom du Lakehouse (autre que celui par défaut) et l'URL complète de OneLake sur la page Paramètres Spark.
Créer une définition de tâche Spark pour Scala/Java
Pour créer une définition de travail Spark pour Scala/Java :
Créez une définition de tâche Spark.
Sélectionnez Spark(Scala/Java) dans la liste déroulante Langage.
Téléchargez le fichier de définition principal en tant que fichier .jar. Le fichier de définition principal est le fichier qui contient la logique d'application de ce travail et est obligatoire pour exécuter un travail Spark. Pour chaque définition de tâche Spark, vous ne pouvez télécharger qu'un seul fichier de définition principal. Fournissez le nom de la classe Main.
Téléchargez les fichiers de référence sous forme de fichiers .jar. Les fichiers de référence sont les fichiers référencés/importés par le fichier de définition principal.
Fournissez des arguments de ligne de commande pour le travail, si nécessaire.
Ajoutez la référence lakehouse au travail. Vous devez avoir au moins une référence lakehouse ajoutée au travail. Ce lakehouse est le contexte lakehouse par défaut pour le travail.
Créer une définition de tâche Spark pour R
Pour créer une définition de tâche Spark pour SparkR(R) :
Créez une définition de tâche Spark.
Sélectionnez SparkR(R) dans la liste déroulante Langage.
Téléchargez le fichier de définition principal en tant que fichier .R. Le fichier de définition principal est le fichier qui contient la logique d'application de ce travail et est obligatoire pour exécuter un travail Spark. Pour chaque définition de tâche Spark, vous ne pouvez télécharger qu'un seul fichier de définition principal.
Téléchargez les fichiers de référence sous forme de fichiers .R. Les fichiers de référence sont les fichiers référencés/importés par le fichier de définition principal.
Fournissez des arguments de ligne de commande pour le travail, si nécessaire.
Ajoutez la référence lakehouse au travail. Vous devez avoir au moins une référence lakehouse ajoutée au travail. Ce lakehouse est le contexte lakehouse par défaut pour le travail.
Remarque
La définition de tâche Spark sera créée dans votre espace de travail actuel.
Options pour personnaliser les définitions de tâches Spark
Il existe quelques options pour personnaliser davantage l'exécution des définitions de tâches Spark.
- Calcul Spark : sous l’onglet Calcul Spark, vous pouvez voir la Version du runtime qui est la version de Spark utilisée pour exécuter le travail. Vous pouvez également voir les paramètres de configuration Spark qui seront utilisés pour exécuter le travail. Vous pouvez personnaliser les paramètres de configuration Spark en cliquant sur le bouton Ajouter.
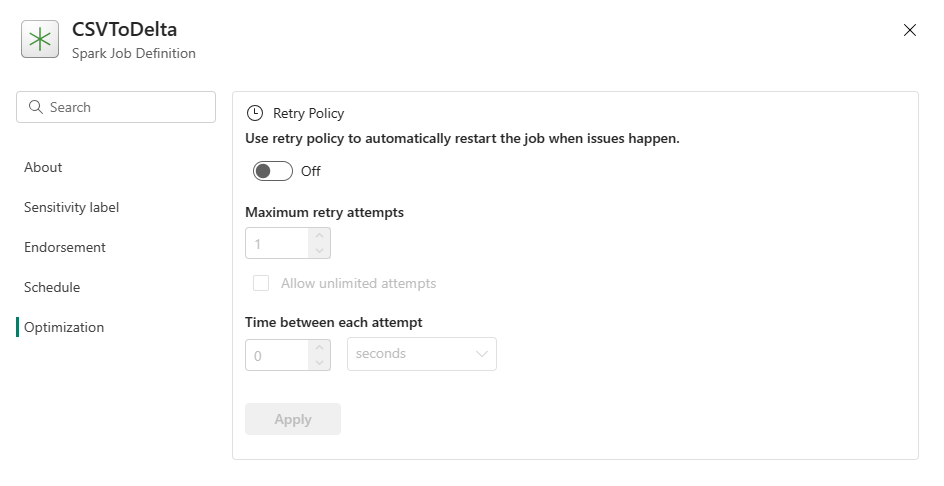
Optimisation : dans l'onglet Optimisation, vous pouvez activer et configurer la stratégie de nouvelle tentative pour le travail. Lorsqu'elle est activée, la tâche est réessayée en cas d'échec. Vous pouvez également définir le nombre maximal de nouvelles tentatives et l’intervalle entre les nouvelles tentatives. À chaque nouvelle tentative, le travail est redémarré. Assurez-vous que le travail est idempotent.