Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Ce guide de démarrage rapide explique comment créer une définition de tâche Spark qui contient du code Python avec le flux structuré Spark pour atterrir les données dans un lakehouse, puis les diffuser via un point de terminaison d’analytique SQL. Après avoir terminé ce démarrage rapide, vous disposez d'une définition de tâche Spark qui s'exécute en continu et le point de terminaison d’analytique SQL peut afficher les données entrantes.
Créer un script Python
Utilisez le script Python suivant pour créer une table Delta en continu dans un lakehouse à l’aide d’Apache Spark. Le script lit un flux de données générées (une ligne par seconde) et l’écrit en mode Ajout dans une table Delta nommée streamingtable. Il stocke les données et les informations de point de contrôle dans le lakehouse spécifié.
Utilisez le code Python suivant qui utilise le streaming structuré Spark pour obtenir des données dans une table Lakehouse.
from pyspark.sql import SparkSession if __name__ == "__main__": # Start Spark session spark = SparkSession.builder \ .appName("RateStreamToDelta") \ .getOrCreate() # Table name used for logging tableName = "streamingtable" # Define Delta Lake storage path deltaTablePath = f"Tables/{tableName}" # Create a streaming DataFrame using the rate source df = spark.readStream \ .format("rate") \ .option("rowsPerSecond", 1) \ .load() # Write the streaming data to Delta query = df.writeStream \ .format("delta") \ .outputMode("append") \ .option("path", deltaTablePath) \ .option("checkpointLocation", f"{deltaTablePath}/_checkpoint") \ .start() # Keep the stream running query.awaitTermination()Enregistrez votre script en tant que fichier Python (.py) sur votre ordinateur local.
Créer un lakehouse.
Utilisez les étapes suivantes pour créer une maison du lac :
Accédez à l'espace de travail souhaité ou créez-en un nouveau si nécessaire.
Pour créer un lakehouse, sélectionnez Nouvel élément à partir de l’espace de travail, puis sélectionnez Lakehouse dans le panneau qui s’ouvre.
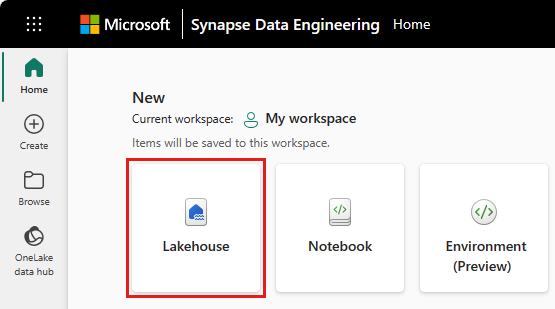
Entrez le nom de votre Lakehouse et sélectionnez Créer.

Créer une définition de tâche Spark
Utilisez les étapes suivantes pour créer une définition de tâche Spark :
Dans le même espace de travail que celui où vous avez créé un lakehouse, sélectionnez Nouvel élément.
Dans le panneau qui s’ouvre, sous Obtenir des données, sélectionnez Définition de tâche Spark.
Entrez le nom de votre définition de travail Spark, puis sélectionnez Créer.
Sélectionnez Télécharger et sélectionnez le fichier Python que vous avez créé à l'étape précédente.
Sous Lakehouse Reference, choisissez le Lakehouse que vous avez créé.
Définir la stratégie de nouvelle tentative pour la définition de tâche Spark
Utilisez les étapes suivantes pour définir la stratégie de nouvelle tentative pour votre définition de tâche Spark :
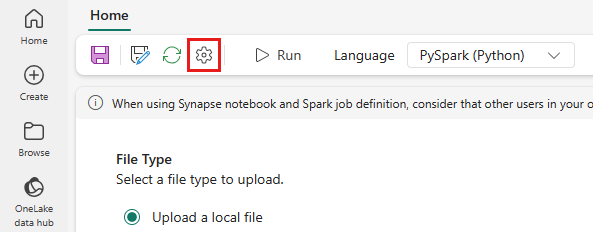
Dans le menu supérieur, sélectionnez l'icône Paramètres.
Ouvrez l’onglet Optimisation et définissez le déclencheur Stratégie de nouvelle tentativeActivé.
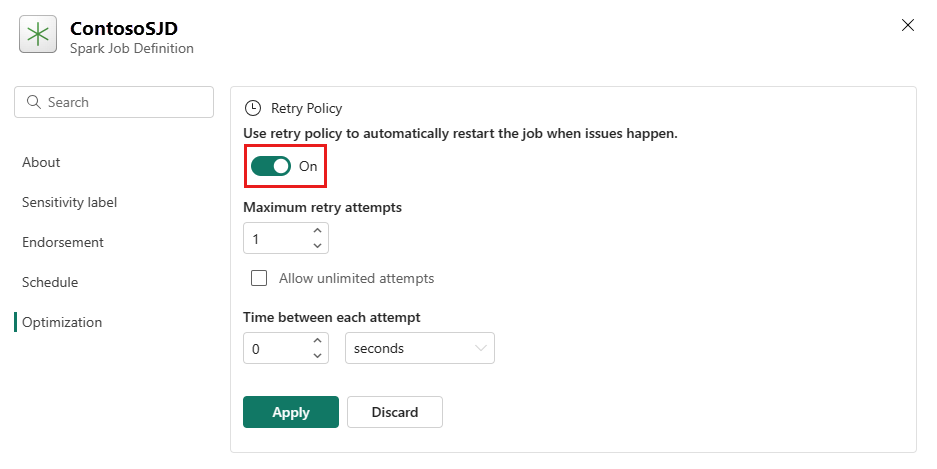
Définissez le nombre maximal de tentatives ou cochez Autoriser les tentatives illimitées.
Spécifiez le délai entre chaque nouvelle tentative et sélectionnez Appliquer.


Remarque
Il existe une limite de durée de vie de 90 jours pour la configuration de la stratégie de nouvelles tentatives. Une fois la stratégie de nouvelles tentatives activée, la tâche sera redémarré en fonction de la stratégie dans les 90 jours. Après cette période, la stratégie de nouvelles tentatives cesse automatiquement de fonctionner et la tâche est terminée. Les utilisateurs devront ensuite redémarrer manuellement la tâche, ce qui réactivera à son tour la stratégie de nouvelles tentatives.
Exécuter et surveiller la définition de tâche Spark
Dans le menu du haut, sélectionnez l'icône Exécuter.
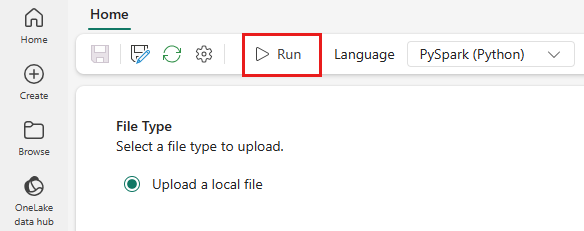
Vérifiez si la définition de la tâche Spark a été soumise avec succès et en cours d'exécution.

Afficher les données à l'aide d'un point de terminaison d’analytique SQL
Une fois le script exécuté, une table nommée streamingtable avec timestamp et des colonnes de valeur est créée dans le lakehouse. Vous pouvez consulter les données à l’aide du point de terminaison d'analytique SQL.
Depuis l’espace de travail, ouvrez votre Lakehouse.
Basculez vers le point de terminaison d'analyse SQL à partir du coin supérieur droit.
Dans le volet de navigation gauche, développez Schémas > dbo >Tables, sélectionnez streamingtable pour afficher un aperçu des données.