Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Important
Cette fonctionnalité est en version préliminaire.
Fabric Runtime offre une intégration transparente au sein de l’écosystème Microsoft Fabric, offrant un environnement robuste pour l’ingénierie des données et les projets de science des données optimisés par Apache Spark.
Cet article présente la préversion publique de Fabric Runtime 2.0, le dernier runtime conçu pour les calculs Big Data dans Microsoft Fabric. Il met en évidence les principales fonctionnalités et composants qui font de cette version une étape importante pour l’analytique évolutive et les charges de travail avancées.
Fabric Runtime 2.0 intègre les composants et mises à niveau suivants conçus pour améliorer vos fonctionnalités de traitement des données :
- Apache Spark 4.1
- Système d’exploitation : Azure Linux 3.0 (Mariner 3.0)
- Java : 21
- Scala : 2.13
- Python : 3.13
- Delta Lake : 4,2
- R : 4.5.2
Important
L’équipe Microsoft Fabric déploie une mise à jour de Microsoft Fabric Runtime 2.0. Dans le cadre de cette mise à jour, la mise à jour Python introduit un changement radical pour les clients utilisant des artefacts d’environnement avec python et des bibliothèques de roues. Les clients voient l’un des deux messages d’erreur lors de l’exécution de la définition de la tâche Notebook ou Spark (SJD) :
- Erreur : avertissement : 1 avertissement d’obsolescence (depuis la version 2.13.0) ; pour plus de détails, activez
:setting -deprecationou:replay -deprecationSource : SparkCoreService. - « LibraryManagementError » : « Une mise à jour de l’environnement Spark Python de base a été détectée. Veuillez republier l’environnement.|UserError"
Actions requises
Republiez votre environnement (y compris les bibliothèques). Pour ce faire, supprimez toutes les bibliothèques, publiez l’Environnement, réajoutez toutes les bibliothèques, puis publiez à nouveau. Ce processus recrée l’environnement en utilisant l’exécution Python mise à jour et résout le problème.
Conseil / Astuce
Fabric Runtime 2.0 inclut la prise en charge du moteur d’exécution natif, ce qui peut améliorer considérablement les performances sans plus de coûts. Vous pouvez activer le moteur d’exécution natif au niveau de l’environnement afin que tous les travaux et notebooks héritent automatiquement des fonctionnalités de performances améliorées.
Activer Runtime 2.0
Vous pouvez activer Runtime 2.0 au niveau de l’espace de travail ou au niveau de l’élément d’environnement. Utilisez le paramètre d’espace de travail pour appliquer Runtime 2.0 comme valeur par défaut pour toutes les charges de travail Spark de votre espace de travail. Vous pouvez également créer un élément d’environnement fonctionnant sur Runtime 2.0, conçu pour être utilisé avec des notebooks spécifiques ou des définitions de travaux Spark, ce qui permet de remplacer le paramètre par défaut de l’espace de travail.
Activer Runtime 2.0 dans les paramètres de l’espace de travail
Pour définir Runtime 2.0 comme valeur par défaut pour l’ensemble de votre espace de travail :
Accédez à la page paramètres de l’espace de travail dans votre espace de travail Fabric.
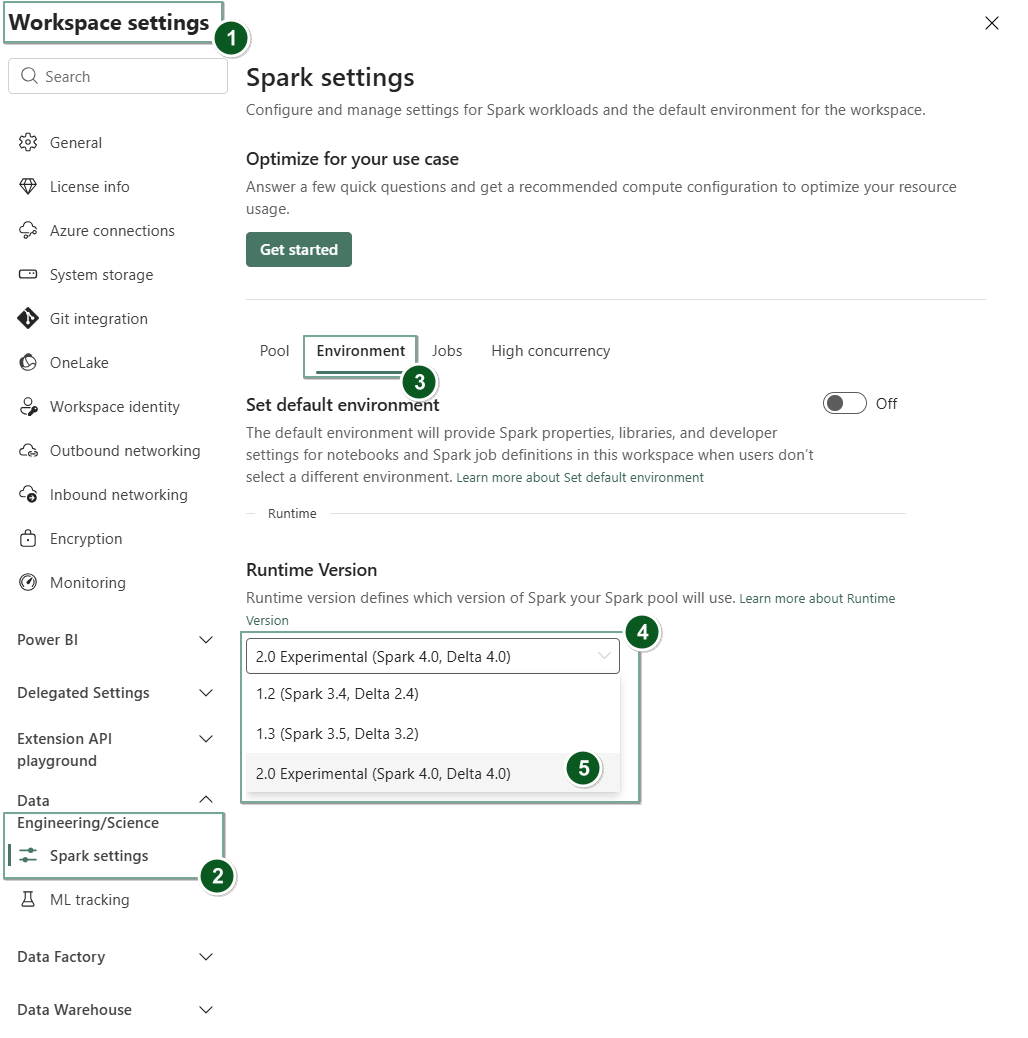
Sélectionnez l’onglet Ingénierie/Science des données , puis sélectionnez Paramètres Spark.
Sélectionnez l’onglet Environnement.
Dans le menu déroulant de la version Runtime , sélectionnez Aperçu public 2.0 (Spark 4.1, Delta 4.2) et enregistrez vos modifications.
Le runtime 2.0 est défini comme runtime par défaut pour votre espace de travail.

Activer Runtime 2.0 dans un élément d’environnement
Pour utiliser Runtime 2.0 avec des notebooks spécifiques ou des définitions de tâches Spark :
Créez un élément d’environnement ou ouvrez-en un existant.
Dans le menu déroulant Runtime , sélectionnez Aperçu public 2.0 (Spark 4.1, Delta 4.2),Enregistrer et Publier vos modifications.
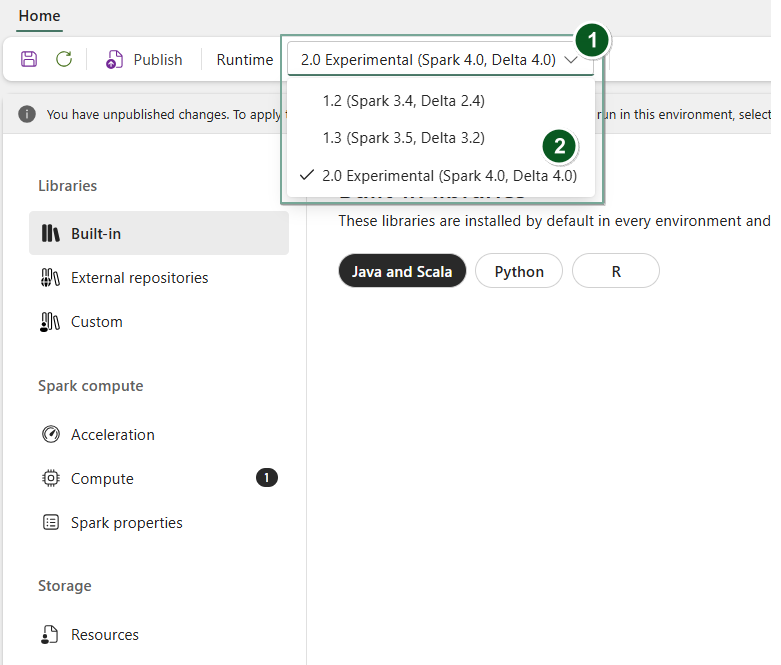
Ensuite, vous pouvez utiliser cet élément Environnement avec votre Notebook ou votre définition de tâche Spark.

Vous pouvez maintenant commencer à expérimenter les dernières améliorations et fonctionnalités introduites dans Fabric Runtime 2.0 (Spark 4.1 et Delta Lake 4.2).
Aperçu public
La phase d’aperçu public de Fabric Runtime 2.0 vous donne accès à de nouvelles fonctionnalités et APIs issues de Spark 4.1 et Delta Lake 4.2. La préversion vous permet d’utiliser immédiatement les dernières améliorations basées sur Spark et Delta, et assure une préparation et une transition fluides pour des optimisations telles que les versions plus récentes de Java, Scala et Python.
Conseil / Astuce
Pour obtenir des informations à jour, une liste détaillée des modifications et des notes de publication spécifiques pour les Fabric runtimes, consultez et abonnez-vous aux versions et mises à jour de Spark Runtimes.
Points clés
Améliorations du moteur de performances et d’exécution
Fabric Runtime 2.0 inclut le moteur d’exécution natif, qui offre des améliorations significatives des performances sur Spark open source. Le moteur utilise le traitement vectorisé pour accélérer les requêtes Spark sur l’infrastructure lakehouse sans nécessiter de modifications de code.
Principales fonctionnalités de performances dans Runtime 2.0 :
- Jusqu’à six fois plus rapide : les benchmarks s’affichent jusqu’à six fois plus rapides que les performances open source spark sur les charges de travail TPC-DS.
- Analyse csv vectorisée : le moteur d’exécution natif inclut un analyseur CSV vectorisé qui accélère l’ingestion et les charges de travail de requête CSV. L’analyse JSON vectorisée et la prise en charge de Spark Structured Streaming sont prévues pour les futures mises à jour.
Pour activer le moteur d’exécution natif, consultez le moteur d’exécution natif pour l’ingénierie des données Fabric.
Apache Spark 4.1
Apache Spark 4.0 a marqué une étape importante comme la version inaugurale de la série 4.x, incarnant l’effort collectif de la communauté open source dynamique. Fabric Runtime 2.0 s’exécute désormais sur Apache Spark 4.1, qui s’appuie sur cette base avec des améliorations supplémentaires.
Dans cette version, Spark SQL est considérablement enrichi avec de puissantes nouvelles fonctionnalités conçues pour améliorer l’expressivité et la polyvalence des charges de travail SQL, telles que la prise en charge des types de données VARIANT, les fonctions définies par l’utilisateur SQL, les variables de session, la syntaxe de canal et le classement de chaîne. PySpark voit un dévouement continu tant à l'égard de son étendue fonctionnelle qu'à l'expérience globale des développeurs, en apportant une API de traçage, une nouvelle API de source de données Python, une prise en charge des fonctions définies par l'utilisateur (UDTF) Python et un profilage unifié pour les fonctions définies par l'utilisateur (UDF) PySpark, ainsi que de nombreuses autres améliorations. Structured Streaming évolue avec des ajouts clés qui offrent un meilleur contrôle et une facilité de débogage, notamment l’introduction de l’API d’état arbitraire v2 pour une gestion d’état plus flexible et la source de données d’état pour faciliter le débogage.
Vous pouvez consulter la liste complète et les modifications détaillées ici :
Note
Dans Spark 4.x, SparkR est déconseillé et peut être supprimé dans une version ultérieure.
Delta Lake 4.2
Delta Lake 4.2 s’appuie sur les précédentes versions de Delta Lake, poursuivant son engagement à rendre Delta Lake interopérable entre différents formats, plus facile à utiliser et plus performant. Il comprend de nouvelles fonctionnalités puissantes, des optimisations des performances et des améliorations fondamentales pour l’avenir des data lakehouses ouverts.
Pour la liste complète et les modifications détaillées introduites avec Delta Lake 3.3, 4.0, 4.1 et 4.2, voir :
Disposition et optimisation des données
Runtime 2.0 prend en charge les fonctionnalités de disposition et d’optimisation des données pour les tables Delta :
- Classement Z : organisez les données dans les fichiers de table Delta en fonction de colonnes spécifiées pour améliorer les performances des requêtes filtrées.
- Clustering liquide : approche de clustering flexible qui optimise automatiquement la disposition des données sans maintenance manuelle.
- Chargement d'instantanés Delta en parallèle : le moteur d'exécution natif charge les instantanés de table Delta en parallèle, réduisant ainsi le temps de démarrage des requêtes pour les tables volumineuses.
Important
Les fonctionnalités spécifiques à Delta Lake 4.2 sont expérimentales et ne fonctionnent que sur les expériences Spark, telles que les carnets et les définitions de postes Spark. Si vous devez utiliser les mêmes tables Delta Lake sur plusieurs charges de travail Microsoft Fabric, n’activez pas ces fonctionnalités. Pour en savoir plus sur les versions et fonctionnalités de protocoles compatibles avec toutes les expériences Microsoft Fabric, voir Interopérabilité des formats de table Delta Lake.
Gestion du calcul dans Runtime 2.0
Runtime 2.0 prend en charge les fonctionnalités de gestion de calcul suivantes :
- Profils de ressources : configurez des allocations de ressources prédéfinies pour les sessions Spark afin de répondre aux exigences de charge de travail et de contrôler les coûts.
- Pools dynamiques personnalisés (préversion) : créez des pools Spark dédiés et préchauffés qui réduisent le temps de démarrage de session. Les pools dynamiques personnalisés sont disponibles en préversion pour les charges de travail Runtime 2.0.
Limitations et notes
- Les fonctionnalités spécifiques à Delta Lake 4.x sont expérimentales et fonctionnent uniquement sur les expériences Spark, telles que les notebooks et les définitions de travaux Spark. Si vous devez utiliser les mêmes tables Delta Lake sur plusieurs charges de travail Fabric, n’activez pas ces fonctionnalités. Pour plus d’informations, consultez l’interopérabilité du format de table Delta Lake.
- Runtime 2.0 est en préversion publique. Certaines fonctionnalités et API peuvent changer avant la disponibilité générale.
- L’extension VS Code pour Fabric Spark prend en charge le Runtime 2.0 pour le développement de définitions de travaux Spark et de cahiers.
Contenu connexe
- Runtimes Apache Spark dans Fabric - Vue d’ensemble, gestion des versions et prise en charge de plusieurs runtimes
- Guide de migration de Spark Core
- Guide de migration de SQL, des jeux de données et du DataFrame
- Guide de migration de la diffusion en continu structurée
- Guide de migration de l’apprentissage automatique (MLlib)
- Guide de migration du PySpark (Python sur Spark)
- Guide de migration SparkR (R sur Spark)