Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Le modèle de programmation des fonctions de données utilisateur Fabric définit les modèles et concepts de création de fonctions dans Fabric.
Le fabric-user-data-functions SDK implémente ce modèle de programmation, fournissant les fonctionnalités nécessaires pour créer et publier des fonctions exécutables. Le Kit de développement logiciel (SDK) vous permet également d’intégrer en toute transparence d’autres éléments dans l’écosystème Fabric, tels que des sources de données Fabric.
Cette bibliothèque est disponible publiquement dans PyPI et est préinstallée dans vos éléments de fonctions de données utilisateur.
Cet article explique comment utiliser le Kit de développement logiciel (SDK) pour générer des fonctions qui peuvent être appelées à partir du portail Fabric, d’autres éléments Fabric ou d’applications externes à l’aide de l’API REST. Vous découvrez le modèle de programmation et les concepts clés avec des exemples pratiques.
Conseil / Astuce
Pour plus d’informations sur toutes les classes, méthodes et paramètres, consultez la documentation de référence du SDK.
Getting started avec le Kit de développement logiciel (SDK)
Cette section présente les principaux composants du Kit de développement logiciel (SDK) User Data Functions et explique comment structurer vos fonctions. Vous découvrez les importations requises, les décorateurs et les types de données d’entrée et de sortie que vos fonctions peuvent gérer.
Fonctions de données utilisateur SDK
Le fabric-user-data-functions Kit de développement logiciel (SDK) fournit les composants principaux dont vous avez besoin pour créer des fonctions de données utilisateur dans Python.
Importations et initialisation requises
Chaque fichier de fonctions de données utilisateur doit importer le fabric.functions module et initialiser le contexte d’exécution :
import datetime
import fabric.functions as fn
import logging
udf = fn.UserDataFunctions()
Décorateur @udf.function()
Les fonctions marquées avec le @udf.function() décorateur peuvent être appelées à partir du portail Fabric, d’un autre élément Fabric ou d’une application externe. Les fonctions utilisant ce décorateur doivent définir un type de retour.
Exemple :
@udf.function()
def hello_fabric(name: str) -> str:
logging.info('Python UDF trigger function processed a request.')
logging.info('Executing hello fabric function.')
return f"Welcome to Fabric Functions, {name}, at {datetime.datetime.now()}!"
Fonctions d’assistance
Les méthodes Python sans décorateur @udf.function() ne peuvent pas être appelées directement. Ils ne peuvent être appelés qu’à partir de fonctions décorées et servir de fonctions d’assistance.
Exemple :
def uppercase_name(name: str) -> str:
return name.upper()
Types d’entrée pris en charge
Vous pouvez définir des paramètres d'entrée pour la fonction, tels que des types de données primitives comme str, int, float, etc. Les types de données d'entrée pris en charge sont les suivants :
| Type JSON | Type de données Python |
|---|---|
| Chaîne | Str |
| Chaîne Date/Heure | date et heure |
| Booléen | Bool |
| Nombres | int (entier), float (flottant) |
| Tableau | list[], exemple de liste[int] |
| Objet | dictionnaire |
| Objet | DataFrame pandas |
| Objet ou tableau d’objets | Pandas Series |
Remarque
Pour utiliser les types DataFrame et Série pandas, accédez au portail Fabric, recherchez votre espace de travail et ouvrez votre élément de fonctions de données utilisateur. Sélectionnez gestion de la bibliothèque, recherchez le fabric-user-data-functions package et mettez-le à jour vers la version 1.0.0 ou ultérieure.
Exemple de corps de requête pour les types d’entrée pris en charge :
{
"name": "Alice", // String (str)
"signup_date": "2025-11-08T13:44:40Z", // Datetime string (datetime)
"is_active": true, // Boolean (bool)
"age": 30, // Number (int)
"height": 5.6, // Number (float)
"favorite_numbers": [3, 7, 42], // Array (list[int])
"profile": { // Object (dict)
"email": "alice@example.com",
"location": "Sammamish"
},
"sales_data": { // Object (pandas DataFrame)
"2025-11-01": {"product": "A", "units": 10},
"2025-11-02": {"product": "B", "units": 15}
},
"weekly_scores": [ // Object or Array of Objects (pandas Series)
{"week": 1, "score": 88},
{"week": 2, "score": 92},
{"week": 3, "score": 85}
]
}
Types de sortie pris en charge
Les types de données de sortie pris en charge sont les suivants :
| Type de données Python |
|---|
| Str |
| date et heure |
| Bool |
| int (entier), float (flottant) |
| list[type de données], par exemple list[int] |
| dictionnaire |
| Aucun |
| Pandas Series |
| DataFrame pandas |
Écriture de fonctions
Exigences et limitations de syntaxe
Lorsque vous écrivez des fonctions de données utilisateur, vous devez suivre des règles de syntaxe spécifiques pour vous assurer que vos fonctions fonctionnent correctement.
Nommage des paramètres
-
Utiliser camelCase : les noms de paramètres doivent utiliser la convention d’affectation de noms camelCase et ne peuvent pas contenir de traits de soulignement. Par exemple, utilisez
productNameau lieu deproduct_name. -
Mots clés réservés : vous ne pouvez pas utiliser de mots clés Python réservés ou les mots clés spécifiques à l’infrastructure suivants en tant que noms de paramètres ou noms de fonction :
req,contextetreqInvocationId.
Exigences des paramètres
Annotations de type requises : tous les paramètres doivent inclure des annotations de type (par exemple).
name: strValeurs par défaut : les valeurs de paramètre par défaut sont prises en charge. Vous pouvez définir des arguments par défaut dans les fonctions de données utilisateur Fabric pour faciliter l’appel et la maintenance de votre code. Les paramètres avec des valeurs par défaut sont facultatifs au moment de l’appel ; les paramètres sans valeur par défaut sont obligatoires. Les types suivants sont pris en charge comme valeurs par défaut :
Type par défaut Notes String Toute chaîne json sérialisable. Chaîne de date-heure Spécifiez-le comme une chaîne dans la signature de la fonction. Le runtime analyse la chaîne au datetimemoment de l’appel. Utilisez le format ISO 8601 (par exemple2025-12-31T23:59:59Z) pour l’analyse cohérente et non ambiguë.Booléenne TrueouFalse.Integer Toute valeur entière. Flottant Toute valeur à virgule flottante. Liste Doit être JSON sérialisable. Préfèrez Nonedans la signature et attribuez la véritable valeur par défaut à l'intérieur de la fonction afin d'éviter des valeurs par défaut partagées et mutables.Dictionnaire Doit être JSON sérialisable. Préférez Nonedans la signature et attribuez la valeur par défaut réelle à l'intérieur de la fonction.DataFrame pandas Fourni en tant qu’objet JSON que le SDK convertit en type pandas. Nécessite fabric-user-data-functionsla version 1.0.0 ou ultérieure.Pandas Series Fourni sous la forme d’un tableau JSON d’objets que le SDK convertit en type pandas. Nécessite fabric-user-data-functionsla version 1.0.0 ou ultérieure.Syntaxe
@udf.function() def function_name( requiredParam: str, optionalStr: str = "hello", optionalDate: datetime.datetime = "2025-01-01T00:00:00Z", # specify as a string; the runtime parses it to datetime at invocation time optionalBool: bool = True, optionalInt: int = 10, optionalFloat: float = 1.5, optionalList: list | None = None, # assign real default inside the function optionalDict: dict | None = None, # assign real default inside the function ) -> dict: optionalList = optionalList or [1, 2, 3] optionalDict = optionalDict or {"key": "value"} return {"param": requiredParam}Les valeurs par défaut doivent être sérialisables JSON (les ensembles et les tuples ne sont pas pris en charge). Pour les valeurs par défaut de liste ou de dictionnaire, utilisez-la
Nonedans la signature et attribuez la valeur par défaut réelle à l’intérieur de la fonction pour éviter les valeurs par défaut mutables partagées. Utilisez le format ISO 8601 (par exemple2025-12-31T23:59:59Z) pour les valeurs par défaut datetime. L’utilisation de pandas DataFrame ou Series comme valeur par défaut nécessite la versionfabric-user-data-functions1.0.0 ou ultérieure.
Exigences en matière de fonction
-
Type de retour obligatoire : les fonctions avec le
@udf.function()décorateur doivent spécifier une annotation de type de retour (par exemple).-> str -
Importations requises : l’instruction
import fabric.functions as fnetudf = fn.UserDataFunctions()l’initialisation sont requises pour que vos fonctions fonctionnent.
Exemple de syntaxe correcte
@udf.function()
def process_order(orderNumber: int, customerName: str, orderDate: str) -> dict:
return {
"order_id": orderNumber,
"customer": customerName,
"date": orderDate,
"status": "processed"
}
Comment écrire une fonction asynchrone
Ajoutez un décorateur asynchrone avec votre définition de fonction dans votre code. Avec une async fonction, vous pouvez améliorer la réactivité et l’efficacité de votre application en gérant plusieurs tâches à la fois. Elles sont idéales pour gérer des volumes élevés d’opérations liées aux E/S. Cet exemple de fonction lit un fichier CSV à partir d’un entrepôt de données en utilisant pandas. La fonction prend le nom de fichier comme paramètre d’entrée.
import pandas as pd
# Replace the alias "<My Lakehouse alias>" with your connection alias.
@udf.connection(argName="myLakehouse", alias="<My Lakehouse alias>")
@udf.function()
async def read_csv_from_lakehouse(myLakehouse: fn.FabricLakehouseClient, csvFileName: str) -> str:
# Connect to the Lakehouse
connection = myLakehouse.connectToFilesAsync()
# Download the CSV file from the Lakehouse
csvFile = connection.get_file_client(csvFileName)
downloadFile = await csvFile.download_file()
csvData = await downloadFile.readall()
# Read the CSV data into a pandas DataFrame
from io import StringIO
df = pd.read_csv(StringIO(csvData.decode('utf-8')))
# Display the DataFrame
result=""
for index, row in df.iterrows():
result=result + "["+ (",".join([str(item) for item in row]))+"]"
# Close the connection
csvFile.close()
connection.close()
return f"CSV file read successfully.{result}"
Utilisation des données
Connexions de données aux sources de données Fabric
Le Kit de développement logiciel (SDK) vous permet de référencer des connexions de données sans avoir besoin d’écrire des chaînes de connexion dans votre code. La bibliothèque fabric.functions fournit deux façons de gérer les connexions de données :
- fabric.functions.FabricSqlConnection : vous permet d’utiliser des bases de données SQL dans Fabric, notamment des points de terminaison SQL Analytics et des entrepôts Fabric.
- fabric.functions.FabricLakehouseClient : vous permet d’utiliser Lakehouses, avec un moyen de se connecter aux tables Lakehouse et aux fichiers Lakehouse.
Pour référencer une connexion à une source de données, vous devez utiliser le décorateur @udf.connection. Vous pouvez l'appliquer dans l'un des formats suivants :
@udf.connection(alias="<alias for data connection>", argName="sqlDB")@udf.connection("<alias for data connection>", "<argName>")@udf.connection("<alias for data connection>")
Les arguments pour @udf.connection sont :
-
argName, nom de la variable utilisée par la connexion dans votre fonction. -
alias, alias de la connexion que vous avez ajoutée avec le menu Gérer les connexions. - Si
argNameetaliasont la même valeur, vous pouvez utiliser@udf.connection("<alias and argName for the data connection>").
Exemple :
# Where demosqldatabase is the argument name and the alias for my data connection used for this function
@udf.connection("demosqldatabase")
@udf.function()
def read_from_sql_db(demosqldatabase: fn.FabricSqlConnection)-> list:
# Connect to the SQL database
connection = demosqldatabase.connect()
cursor = connection.cursor()
# Replace with the query you want to run
query = "SELECT * FROM (VALUES ('John Smith', 31), ('Kayla Jones', 33)) AS Employee(EmpName, DepID);"
# Execute the query
cursor.execute(query)
# Fetch all results
results = cursor.fetchall()
# Close the cursor and connection
cursor.close()
connection.close()
return results
Connexions génériques pour les éléments Fabric ou les ressources Azure
Le Kit de développement logiciel (SDK) prend en charge les connexions génériques qui vous permettent de créer des connexions à des éléments Fabric ou à des ressources Azure à l’aide de votre identité de propriétaire d’élément User Data Functions. Cette fonctionnalité génère un jeton Microsoft Entra ID avec l'identité du propriétaire de l'élément et un type d'audience fourni. Ce jeton est utilisé pour s’authentifier auprès d’éléments Fabric ou de ressources Azure qui prennent en charge ce type d’audience. Cette approche offre une expérience de programmation similaire à l’utilisation d’objets de connexions managées à partir de la fonctionnalité Gérer les connexions , mais uniquement pour le type d’audience fourni dans la connexion.
Cette fonctionnalité utilise le @udf.generic_connection() décorateur avec les paramètres suivants :
| Paramètre | Descriptif | Valeur |
|---|---|---|
argName |
Nom de la variable transmise à la fonction. L’utilisateur doit spécifier cette variable dans les arguments de sa fonction et utiliser le type de celui-ci fn.FabricItem |
Par exemple, si argName=CosmosDb, alors la fonction doit contenir l'argument cosmosDb: fn.FabricItem |
audienceType |
Type d’audience pour lequel la connexion est créée. Ce paramètre est associé au type d’élément Fabric ou Azure service et détermine le client utilisé pour la connexion. | Les valeurs autorisées pour ce paramètre sont CosmosDb ou KeyVault. |
Se connecter au conteneur Fabric Cosmos DB à l’aide d’une connexion générique
Les connexions génériques prennent en charge les éléments Fabric Cosmos DB natifs en utilisant le type d'audience CosmosDB. Le Kit de développement logiciel (SDK) User Data Functions inclus fournit une méthode d’assistance appelée get_cosmos_client qui extrait un client Singleton Cosmos DB pour chaque appel.
Vous pouvez vous connecter à un élément Fabric Cosmos DB à l’aide d’une connexion générique en procédant comme suit :
Accédez au portail Fabric, recherchez votre espace de travail et ouvrez votre élément de fonctions de données utilisateur. Sélectionnez Gestion de bibliothèque, recherchez la bibliothèque
azure-cosmoset installez-la. Pour plus d’informations, consultez Gérer les bibliothèques.Accédez aux paramètres de votre élément Fabric Cosmos DB.
Récupérez votre URL de point de terminaison Fabric Cosmos DB.
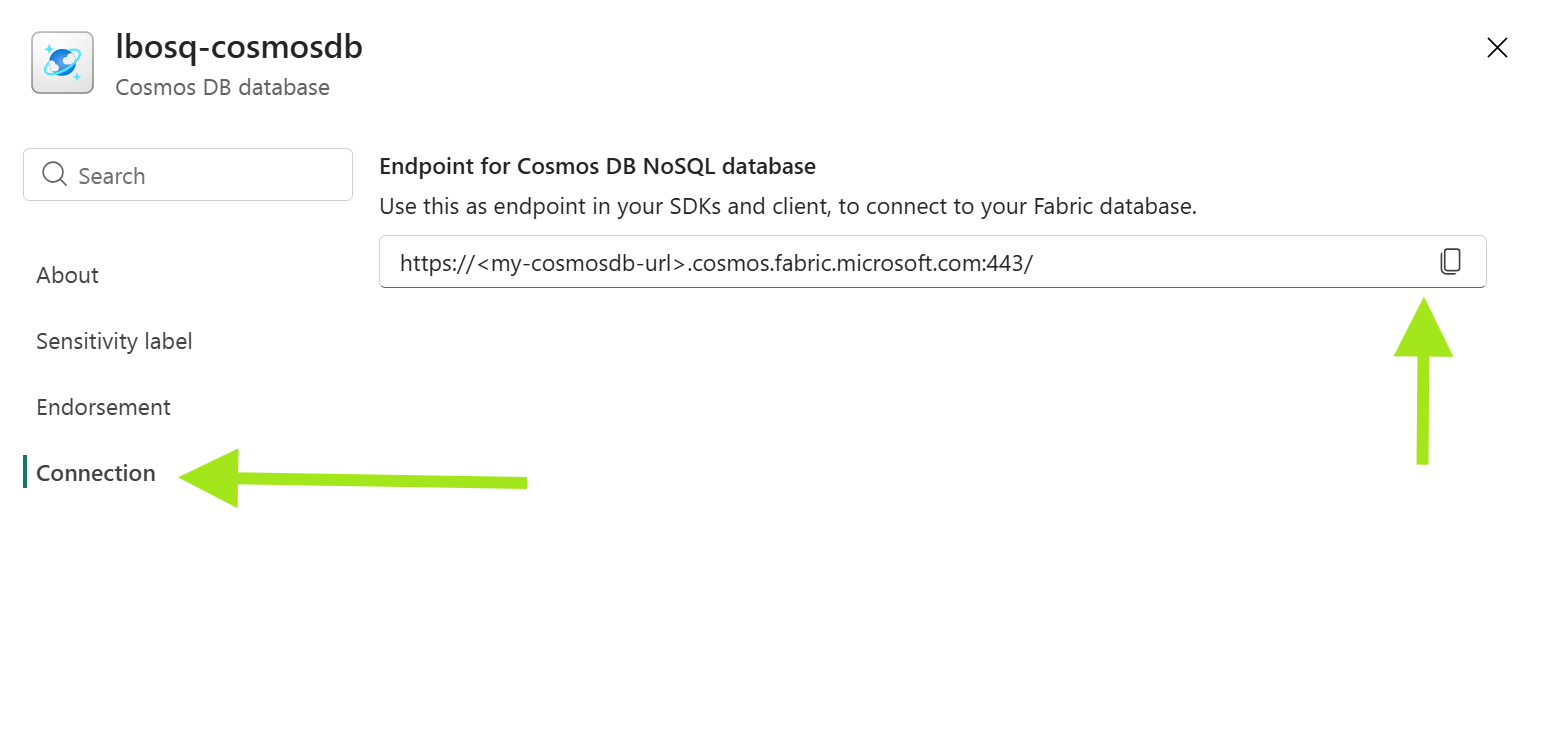
Accédez à votre élément Fonctions de données utilisateur. Utilisez l’exemple de code suivant pour vous connecter à votre conteneur Fabric Cosmos DB et exécuter une requête de lecture à l’aide de l’exemple de jeu de données Cosmos DB. Remplacez les valeurs des variables suivantes :
-
COSMOS_DB_URIavec le point de terminaison de votre Fabric Cosmos DB. -
DB_NAMEavec le nom de votre objet Fabric Cosmos DB.
from fabric.functions.cosmosdb import get_cosmos_client import json @udf.generic_connection(argName="cosmosDb", audienceType="CosmosDB") @udf.function() def get_product_by_category(cosmosDb: fn.FabricItem, category: str) -> list: COSMOS_DB_URI = "YOUR_COSMOS_DB_URL" DB_NAME = "YOUR_COSMOS_DB_NAME" # Note: This is the Fabric item name CONTAINER_NAME = "SampleData" # Note: This is your container name. In this example, we are using the SampleData container. cosmosClient = get_cosmos_client(cosmosDb, COSMOS_DB_URI) # Get the database and container database = cosmosClient.get_database_client(DB_NAME) container = database.get_container_client(CONTAINER_NAME) query = 'select * from c WHERE c.category=@category' #"select * from c where c.category=@category" parameters = [ { "name": "@category", "value": category } ] results = container.query_items(query=query, parameters=parameters) items = [item for item in results] logging.info(f"Found {len(items)} products in {category}") return json.dumps(items)-
Testez ou exécutez cette fonction en fournissant un nom de catégorie, par
Accessoryexemple dans les paramètres d’appel.


Remarque
Vous pouvez également utiliser ces étapes pour vous connecter à une base de données Azure Cosmos DB à l’aide de l’URL du compte et des noms de base de données. Le compte propriétaire des fonctions de données utilisateur aurait besoin d'autorisations d'accès pour ce compte Azure Cosmos DB.
Se connecter à Azure Key Vault à l’aide d’une connexion générique
Les connexions génériques permettent de se connecter à un Azure Key Vault en utilisant le type d'audience KeyVault. Ce type de connexion nécessite que le propriétaire fabric User Data Functions dispose des autorisations nécessaires pour se connecter au Azure Key Vault. Vous pouvez utiliser cette connexion pour récupérer des clés, des secrets ou des certificats par nom.
Vous pouvez vous connecter à Azure Key Vault pour récupérer une clé secrète client pour appeler une API à l’aide d’une connexion générique en procédant comme suit :
Accédez au portail Fabric, recherchez votre espace de travail et ouvrez votre élément de fonctions de données utilisateur. Sélectionnez la gestion Library, puis recherchez et installez les bibliothèques
requestsetazure-keyvault-secrets. Pour plus d’informations, consultez Gérer les bibliothèques.Accédez à votre ressource Azure Key Vault dans la Azure portal et récupérez la
Vault URIet le nom de votre clé, secret ou certificat.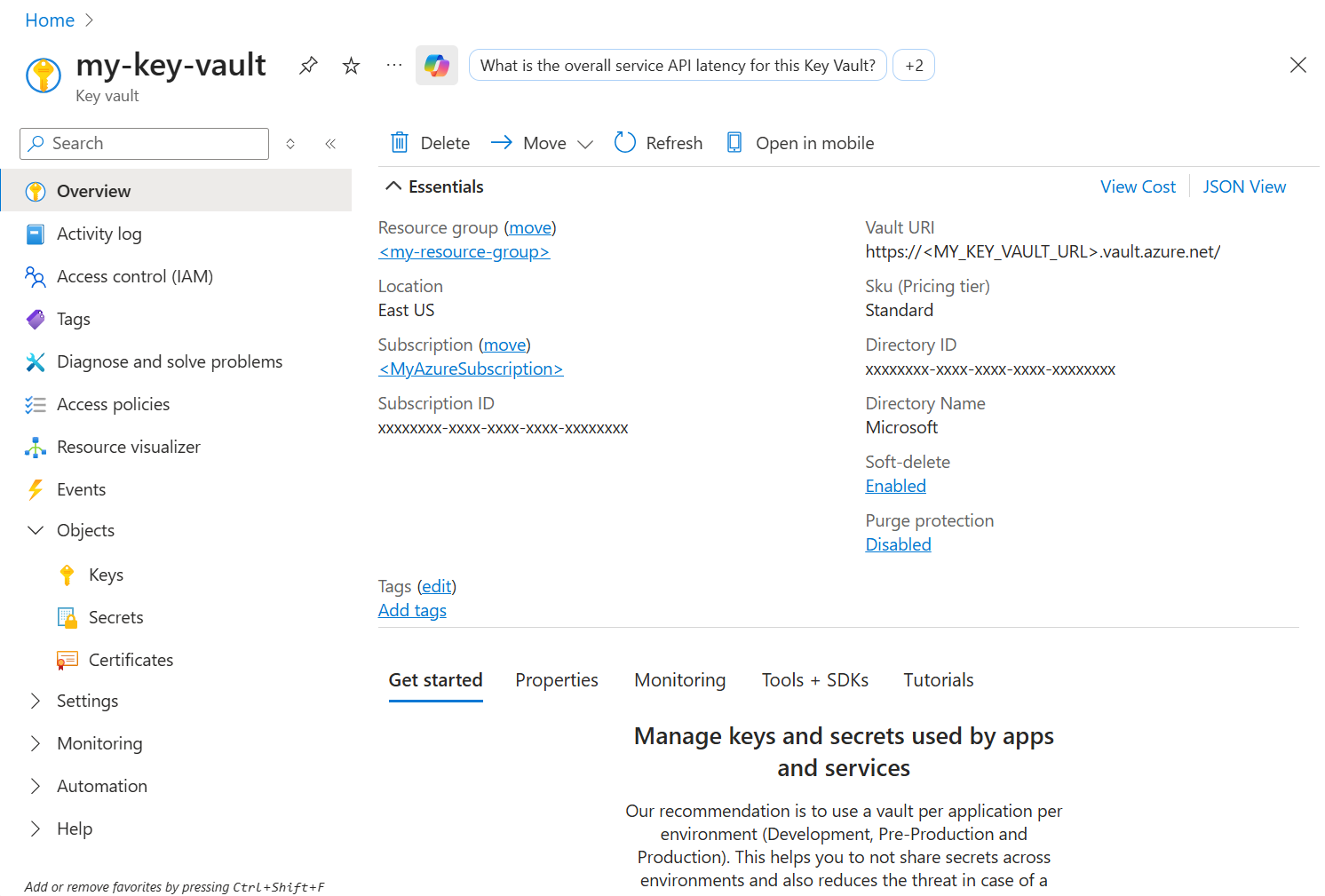
Retournez à votre élément Fabric User Data Functions et utilisez cet exemple. Dans cet exemple, nous récupérons un secret de Azure Key Vault pour nous connecter à une API publique. Remplacez la valeur des variables suivantes :
-
KEY_VAULT_URLavec leVault URIrécupéré à l’étape précédente. -
KEY_VAULT_SECRET_NAMEavec le nom de votre secret. -
API_URLvariable avec l’URL de l’API à laquelle vous souhaitez vous connecter. Cet exemple part du principe que vous vous connectez à une API publique qui accepte les requêtes GET et accepte les paramètresapi-keysuivants etrequest-body.
from azure.keyvault.secrets import SecretClient from azure.identity import DefaultAzureCredential import requests @udf.generic_connection(argName="keyVaultClient", audienceType="KeyVault") @udf.function() def retrieveNews(keyVaultClient: fn.FabricItem, requestBody:str) -> str: KEY_VAULT_URL = 'YOUR_KEY_VAULT_URL' KEY_VAULT_SECRET_NAME= 'YOUR_SECRET' API_URL = 'YOUR_API_URL' credential = keyVaultClient.get_access_token() client = SecretClient(vault_url=KEY_VAULT_URL, credential=credential) api_key = client.get_secret(KEY_VAULT_SECRET_NAME).value api_url = API_URL params = { "api-key": api_key, "request-body": requestBody } response = requests.get(api_url, params=params) data = "" if response.status_code == 200: data = response.json() else: print(f"Error {response.status_code}: {response.text}") return f"Response: {data}"-
Testez ou exécutez cette fonction en fournissant un corps de requête dans votre code.

Fonctionnalités avancées
Le modèle de programmation définit des modèles avancés qui vous donnent un meilleur contrôle sur vos fonctions. Le Kit de développement logiciel (SDK) implémente ces modèles par le biais de classes et de méthodes qui vous permettent de :
- Accédez aux métadonnées d’appel concernant qui a appelé votre fonction et de quelle manière.
- Gérer des scénarios d’erreur personnalisés avec des réponses structurées aux erreurs
- Intégrer avec les bibliothèques de variables Fabric pour la gestion centralisée de la configuration
Remarque
User Data Functions a des limites de service pour la taille de la demande, le délai d’exécution et la taille de réponse. Pour plus d’informations sur ces limites et sur la façon dont elles sont appliquées, consultez les détails et limitations du service.
Obtenir les propriétés d'invocation en utilisant UserDataFunctionContext
Le Kit de développement logiciel (SDK) inclut l’objet UserDataFunctionContext . Cet objet contient les métadonnées d’appel de fonction et peut être utilisé pour créer une logique d’application spécifique pour différents mécanismes d’appel (tels que l’appel du portail et l’appel d’API REST).
Le tableau suivant présente les propriétés de l'objet UserDataFunctionContext :
| Nom de la propriété | Type de données | Descriptif |
|---|---|---|
| invocation_id | ficelle | GUID unique lié à l’appel de l’élément de fonctions de données utilisateur. |
| utilisateur_exécutant | objet | Métadonnées des informations de l’utilisateur utilisées pour autoriser l’appel. |
L’objet executing_user contient les information suivantes :
| Nom de la propriété | Type de données | Descriptif |
|---|---|---|
| Oid | Chaîne (GUID) | ID d’objet de l’utilisateur, qui est un identificateur immuable pour le demandeur. Il s’agit de l’identité vérifiée de l’utilisateur(-trice) ou du principal de service utilisé pour appeler cette fonction entre les applications. |
| ID de locataire | Chaîne (GUID) | ID du locataire auquel l’utilisateur(-trice) est connecté(e). |
| NomD'utilisateurPréféré | ficelle | Nom d’utilisateur préféré de l’utilisateur(-trice) appelant, tel que défini par l’utilisateur(-trice). Cette valeur est mutable. |
Pour access le paramètre UserDataFunctionContext, vous devez utiliser le décorateur suivant en haut de la définition de fonction : @udf.context(argName="<parameter name>")
Exemple
@udf.context(argName="myContext")
@udf.function()
def getContext(myContext: fabric.functions.UserDataFunctionContext)-> str:
logging.info('Python UDF trigger function processed a request.')
return f"Hello oid = {myContext.executing_user['Oid']}, TenantId = {myContext.executing_user['TenantId']}, PreferredUsername = {myContext.executing_user['PreferredUsername']}, InvocationId = {myContext.invocation_id}"
Lever une erreur gérée avec UserThrownError
Lors du développement de votre fonction, vous pouvez lever une réponse d'erreur attendue en utilisant la classe UserThrownError disponible dans le Kit de développement logiciel (SDK). L’une des utilisations de cette classe consiste à gérer les cas où les entrées fournies par l’utilisateur ne réussissent pas les règles de validation métier.
Exemple
import datetime
@udf.function()
def raise_userthrownerror(age: int)-> str:
if age < 18:
raise fn.UserThrownError("You must be 18 years or older to use this service.", {"age": age})
return f"Welcome to Fabric Functions at {datetime.datetime.now()}!"
Le UserThrownError constructeur de classe prend deux paramètres :
-
Message: cette chaîne est retournée en tant que message d’erreur à l’application qui appelle cette fonction. - Un dictionnaire de propriétés est retourné à l’application qui appelle cette fonction.
Obtenir des variables à partir de bibliothèques de variables Fabric
Une bibliothèque de variables Fabric dans Microsoft Fabric est un référentiel centralisé permettant de gérer des variables qui peuvent être utilisées sur différents éléments au sein d’un espace de travail. Il permet aux développeurs de personnaliser et de partager efficacement les configurations d’éléments. Si vous n’avez pas encore de bibliothèque de variables, consultez Créer et gérer des bibliothèques de variables.
Pour utiliser une bibliothèque de variables dans vos fonctions, vous ajoutez une connexion à celle-ci à partir de votre élément de fonctions de données utilisateur. Les bibliothèques de variables apparaissent dans le catalogue OneLake avec des sources de données telles que des bases de données SQL et des lakehouses.
Procédez comme suit pour utiliser des bibliothèques de variables dans vos fonctions :
- Dans votre élément de fonctions de données utilisateur, ajoutez une connexion à votre bibliothèque de variables. Dans le catalogue OneLake, recherchez et sélectionnez votre bibliothèque de variables, puis sélectionnez Se connecter. Notez l’alias généré par Fabric pour la connexion.
- Ajoutez un décorateur de connexion pour l’élément de bibliothèque de variables. Par exemple,
@udf.connection(argName="varLib", alias="<My Variable Library Alias>")et remplacez l’alias par la connexion nouvellement ajoutée pour l’élément de bibliothèque de variables. - Dans la définition de fonction, incluez un argument de type
fn.FabricVariablesClient. Ce client fournit des méthodes dont vous avez besoin pour travailler avec l’élément de bibliothèque de variables. - Utilisez
getVariables()la méthode pour obtenir toutes les variables de la bibliothèque de variables. - Pour lire les valeurs des variables utilisées, soit
["variable-name"].get("variable-name").
Exemple :
Dans cet exemple, nous simulons un scénario de configuration pour une production et un environnement de développement. Cette fonction définit un chemin d’accès storage en fonction de l’environnement sélectionné à l’aide d’une valeur récupérée à partir de la bibliothèque de variables. La bibliothèque de variables contient une variable appelée ENV où les utilisateurs peuvent définir une valeur de dev ou prod.
@udf.connection(argName="varLib", alias="<My Variable Library Alias>")
@udf.function()
def get_storage_path(dataset: str, varLib: fn.FabricVariablesClient) -> str:
"""
Description: Determine storage path for a dataset based on environment configuration from Variable Library.
Args:
dataset_name (str): Name of the dataset to store.
varLib (fn.FabricVariablesClient): Fabric Variable Library connection.
Returns:
str: Full storage path for the dataset.
"""
# Retrieve variables from Variable Library
variables = varLib.getVariables()
# Get environment and base paths
env = variables.get("ENV")
dev_path = variables.get("DEV_FILE_PATH")
prod_path = variables.get("PROD_FILE_PATH")
# Apply environment-specific logic
if env.lower() == "dev":
return f"{dev_path}{dataset}/"
elif env.lower() == "prod":
return f"{prod_path}{dataset}/"
else:
return f"incorrect settings define for ENV variable"