Notes
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Dans ce tutoriel, vous allez apprendre à charger de manière incrémentielle des données de Data Warehouse vers Lakehouse.
Vue d’ensemble
Voici le diagramme de solution de haut niveau :

Voici les étapes importantes à suivre pour créer cette solution :
Sélectionner la colonne de limite. Sélectionnez une colonne dans le tableau de données sources, qui peut servir à découper les enregistrements nouveaux ou mis à jour pour chaque exécution. Normalement, les données contenues dans cette colonne sélectionnée (par exemple, last_modify_time ou ID) continuent de croître à mesure que des lignes sont créées ou mises à jour. La valeur maximale de cette colonne est utilisée comme limite.
Préparez une table pour stocker la dernière valeur de filigrane dans votre Data Warehouse.
Créer un pipeline avec le flux de travail suivant :
Le pipeline de cette solution compte les activités suivantes :
- Créez deux activités de recherche. Servez-vous de la première activité de recherche pour récupérer la dernière valeur de limite. Servez-vous de la deuxième activité de recherche pour récupérer la nouvelle valeur de limite. Ces valeurs de limite sont passées à l’activité de copie.
- Créez une activité de copie qui copie les lignes du tableau de données source dont la valeur de la colonne de filigrane est supérieure à l’ancienne valeur de filigrane et inférieure à la nouvelle. Ensuite, il copie les données du Data Warehouse dans Lakehouse en tant que nouveau fichier.
- Créez une activité de procédure stockée qui met à jour la dernière valeur de limite pour la prochaine exécution de pipeline.
Prérequis
- Data Warehouse. Vous utilisez le Data Warehouse comme magasin de données source. Si vous ne l'avez pas, consultez la section Créer un Data Warehouse pour connaître la marche à suivre pour en créer un.
- Lakehouse. Vous utilisez Lakehouse comme magasin de données de destination. Si vous ne l’avez pas, consultez Créer un Lakehouse pour connaître les étapes à suivre pour en créer un. Créez un dossier nommé IncrementalCopy pour stocker les données copiées.
Préparation de votre source
Voici quelques tables et procédures stockées que vous devez préparer dans votre Data Warehouse source avant de configurer le pipeline de copie incrémentielle.
1. Créer une table de source de données dans votre Data Warehouse
Exécutez la commande SQL suivante dans votre Data Warehouse pour créer une table nommée data_source_table en tant que table source de données. Dans ce tutoriel, vous l’utilisez comme données d'exemple pour réaliser une copie incrémentielle.
create table data_source_table
(
PersonID int,
Name varchar(255),
LastModifytime DATETIME2(6)
);
INSERT INTO data_source_table
(PersonID, Name, LastModifytime)
VALUES
(1, 'aaaa','9/1/2017 12:56:00 AM'),
(2, 'bbbb','9/2/2017 5:23:00 AM'),
(3, 'cccc','9/3/2017 2:36:00 AM'),
(4, 'dddd','9/4/2017 3:21:00 AM'),
(5, 'eeee','9/5/2017 8:06:00 AM');
Les données du tableau de la source de données sont présentées ci-dessous :
PersonID | Name | LastModifytime
-------- | ---- | --------------
1 | aaaa | 2017-09-01 00:56:00.000
2 | bbbb | 2017-09-02 05:23:00.000
3 | cccc | 2017-09-03 02:36:00.000
4 | dddd | 2017-09-04 03:21:00.000
5 | eeee | 2017-09-05 08:06:00.000
Dans ce didacticiel, vous allez utiliser LastModifytime comme colonne de filigrane.
2. Créez une autre table dans votre Data Warehouse pour stocker la dernière valeur du filigrane
Exécutez la commande SQL suivante dans votre Data Warehouse pour créer une table nommée table filigrane afin de stocker la dernière valeur du filigrane :
create table watermarktable ( TableName varchar(255), WatermarkValue DATETIME2(6), );Définir la valeur par défaut du dernier filigrane avec le nom du tableau de données source. Dans ce didacticiel, le nom de la table est data_source_table et la valeur par défaut est
1/1/2010 12:00:00 AM.INSERT INTO watermarktable VALUES ('data_source_table','1/1/2010 12:00:00 AM')Passez en revue les données de la table en filigrane.
Select * from watermarktableSortie :
TableName | WatermarkValue ---------- | -------------- data_source_table | 2010-01-01 00:00:00.000
3. Créez une procédure stockée dans votre Data Warehouse
Exécutez la commande suivante pour créer une procédure stockée dans votre Data Warehouse. Cette procédure stockée permet de mettre à jour la dernière valeur de filigrane après la dernière exécution du pipeline.
CREATE PROCEDURE usp_write_watermark @LastModifiedtime datetime, @TableName varchar(50)
AS
BEGIN
UPDATE watermarktable
SET [WatermarkValue] = @LastModifiedtime
WHERE [TableName] = @TableName
END
Configurer un pipeline pour la copie incrémentielle
Étape 1 : Créer un pipeline
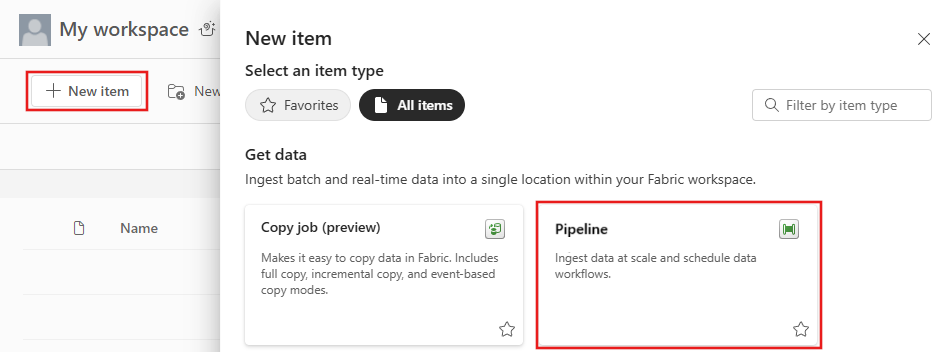
Accédez à Power BI.
Sélectionnez l’icône Power BI en bas à gauche de l’écran, puis Data Factory pour ouvrir la page d’accueil de Data Factory.
Accédez à votre espace de travail Microsoft Fabric.
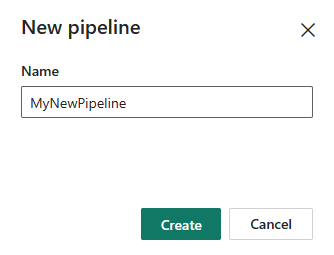
Sélectionnez Pipeline de données, puis entrez un nom de pipeline pour créer un pipeline.
Étape 2 : Ajouter une activité de recherche pour le dernier filigrane
Dans cette étape, vous créez une activité de recherche pour obtenir la dernière valeur de filigrane. La valeur par défaut 1/1/2010 12:00:00 AM définie précédemment est obtenue.
Sélectionnez Ajouter une activité de pipeline et sélectionnez Recherche dans la liste déroulante.
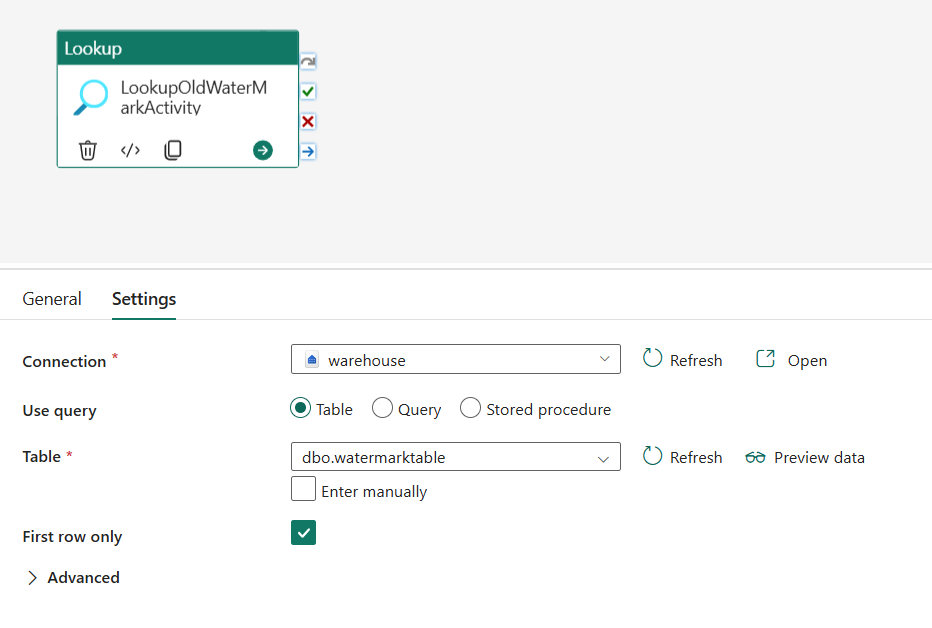
Sous l’onglet Général , renommez cette activité LookupOldWaterMarkActivity.
Sous l’onglet Paramètres, effectuez la configuration suivante :
- Type de magasin de données : Sélectionnez Espace de travail.
- Type de magasin de données d’espace de travail : sélectionnez Data Warehouse.
- Data Warehouse : sélectionnez votre Data Warehouse.
- Utiliser la requête : choisissez Table.
- Table : choisissez dbo.watermarktable.
- Première ligne uniquement : sélectionnée.
Étape 3 : Ajouter une activité de recherche pour le premier filigrane
Dans cette étape, vous créez une activité de recherche pour obtenir la nouvelle valeur de filigrane. Vous utilisez une requête pour obtenir le nouveau filigrane à partir de votre table de données source. La valeur maximale dans la colonne LastModifytime dans data_source_table est obtenue.
Dans la barre supérieure, sélectionnez Recherche sous l’onglet Activités pour ajouter la deuxième activité de recherche.
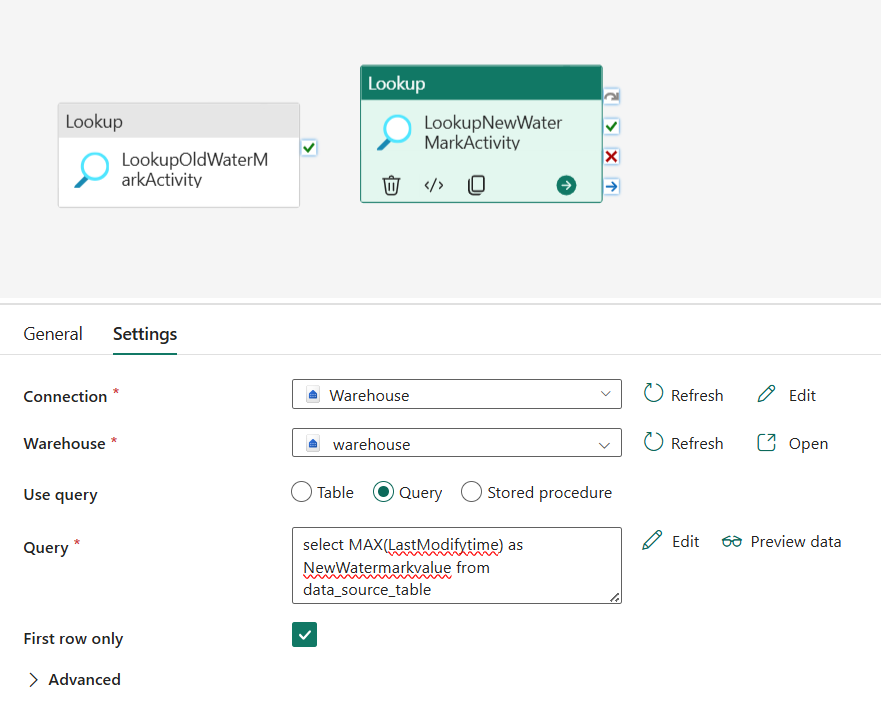
Sous l’onglet Général , renommez cette activité LookupNewWaterMarkActivity.
Sous l’onglet Paramètres, effectuez la configuration suivante :
Type de magasin de données : Sélectionnez Espace de travail.
Type de magasin de données d’espace de travail : sélectionnez Data Warehouse.
Data Warehouse : sélectionnez votre Data Warehouse.
Utiliser la requête : choisissez Requête.
Requête : entrez la requête suivante pour choisir l’heure maximale de la dernière modification comme nouveau filigrane :
select MAX(LastModifytime) as NewWatermarkvalue from data_source_tablePremière ligne uniquement : sélectionnée.
Étape 4 : Ajouter l’activité de copie pour copier des données incrémentielles
Dans cette étape, vous ajoutez une activité de copie pour copier les données incrémentielles entre le dernier filigrane et le nouveau filigrane de Data Warehouse vers Lakehouse.
Sélectionnez Activités dans la barre supérieure, puis Copier des données ->Ajouter au canevas pour obtenir l’activité de copie.
Sous l’onglet Général, renommez cette activité IncrementalCopyActivity.
Reliez les deux activités de recherche à l'activité de copie en faisant glisser le bouton vert (En cas de succès) attaché aux activités de recherche vers l'activité de copie. Relâchez le bouton de la souris lorsque la couleur de bordure de l’activité de copie passe en vert.

Sous l’onglet Source, effectuez la configuration suivante :
Type de magasin de données : Sélectionnez Espace de travail.
Type de magasin de données d’espace de travail : sélectionnez Data Warehouse.
Data Warehouse : sélectionnez votre Data Warehouse.
Utiliser la requête : choisissez Requête.
Requête : entrez la requête suivante pour copier des données incrémentielles entre le dernier filigrane et le nouveau filigrane.
select * from data_source_table where LastModifytime > '@{activity('LookupOldWaterMarkActivity').output.firstRow.WatermarkValue}' and LastModifytime <= '@{activity('LookupNewWaterMarkActivity').output.firstRow.NewWatermarkvalue}'
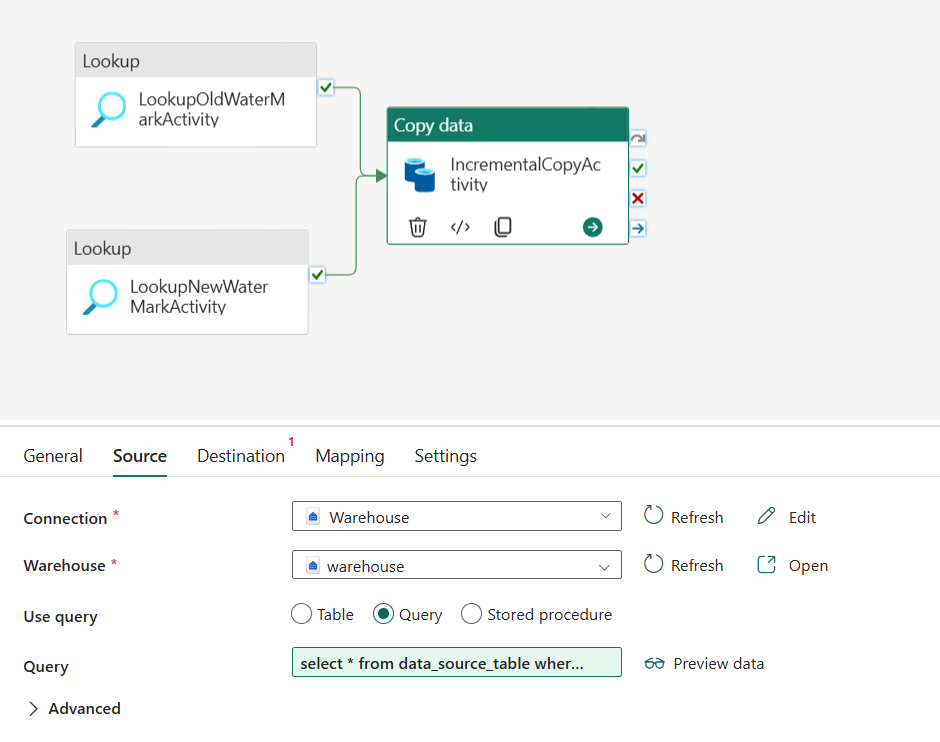
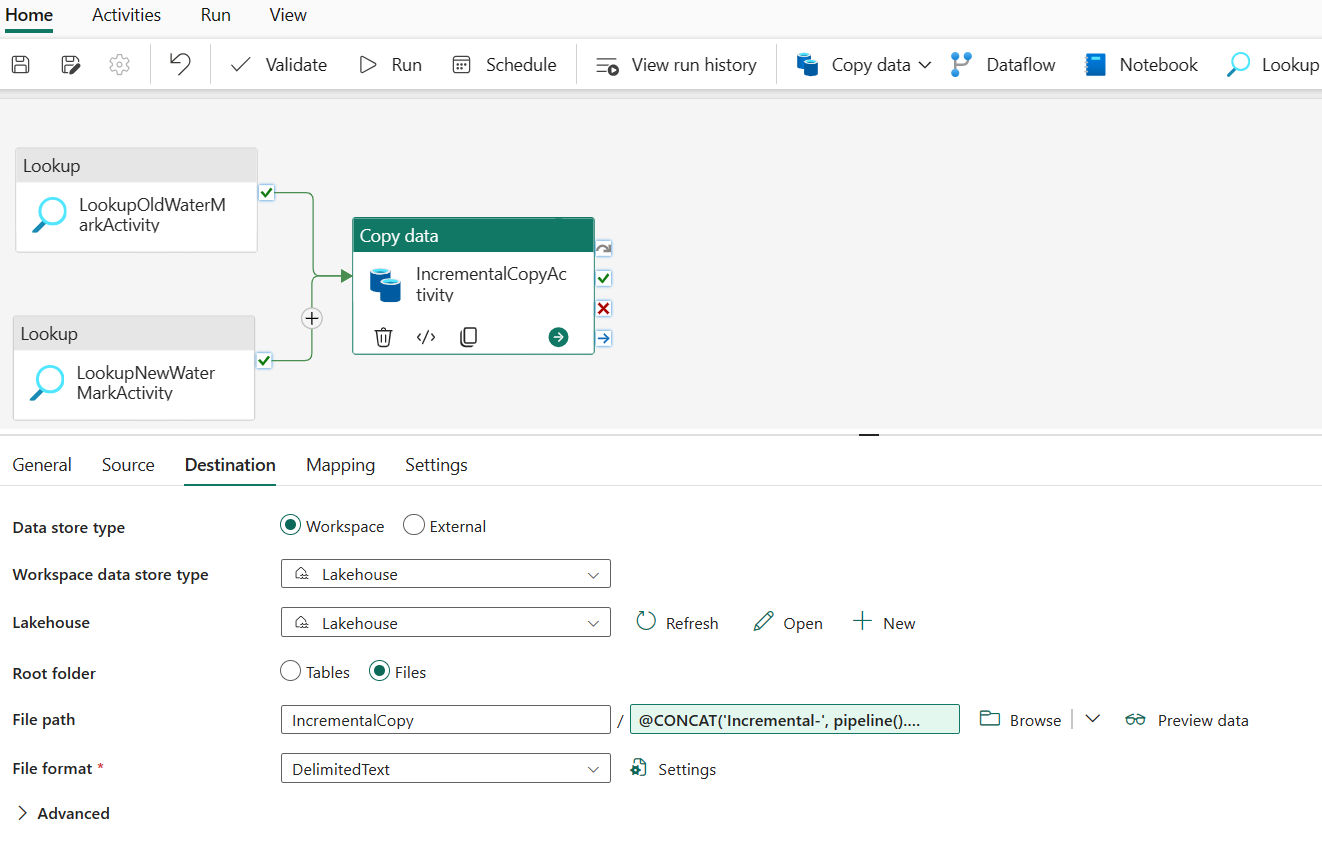
Sous l’onglet Destination, effectuez la configuration suivante :
- Type de magasin de données : Sélectionnez Espace de travail.
- Type de magasin de données de l’espace de travail : sélectionnez Lakehouse.
- Lakehouse: sélectionnez votre Lakehouse.
- Dossier racine : choisissez Fichiers.
- Chemin du fichier : spécifiez le dossier dans lequel vous souhaitez stocker vos données copiées. Sélectionnez Parcourir pour sélectionner votre dossier. Pour le nom du fichier, ouvrez Ajouter du contenu dynamique et entrez
@CONCAT('Incremental-', pipeline().RunId, '.txt')dans la fenêtre ouverte pour créer des noms de fichiers pour votre fichier de données copié dans Lakehouse. - Format de fichier : sélectionnez le type de format de vos données.
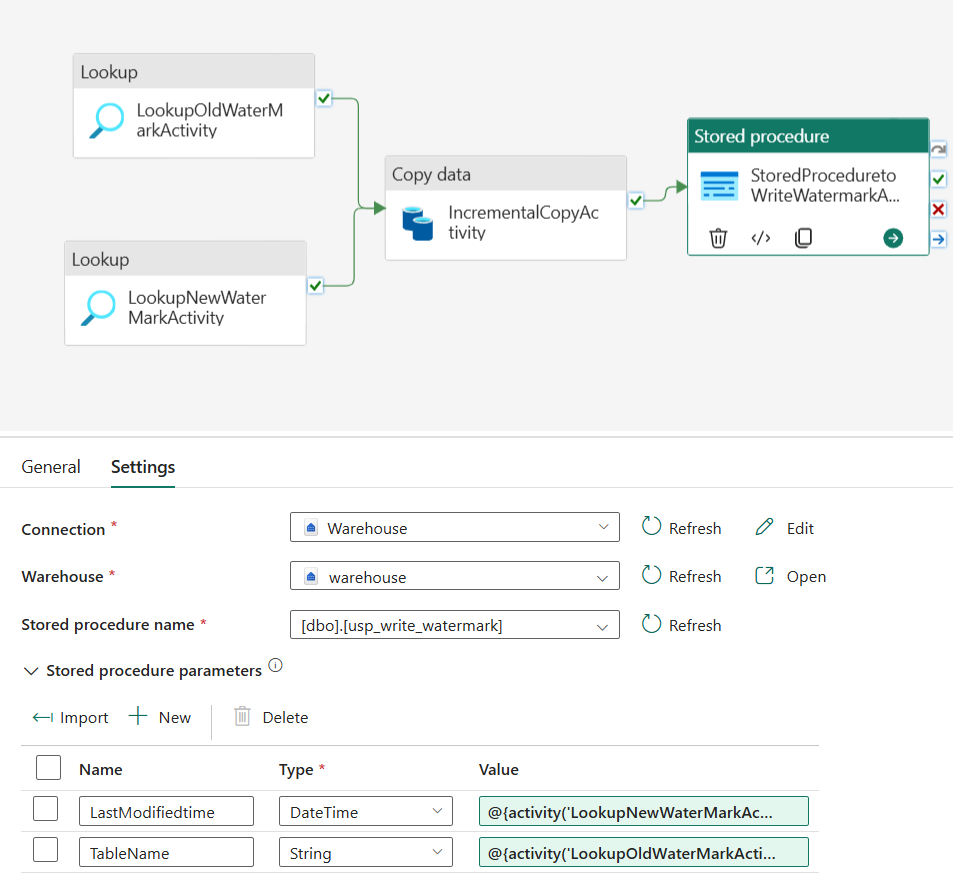
Étape 5 : Ajouter une activité de procédure stockée
Dans cette étape, vous ajoutez une activité de procédure stockée pour mettre à jour la dernière valeur de filigrane de la prochaine exécution du pipeline.
Sélectionnez Activités dans la barre supérieure, puis Procédure stockée pour ajouter une activité de procédure stockée.
Sous l’onglet Général , renommez cette activité StoredProceduretoWriteWatermarkActivity.
Connectez la sortie verte (En cas de réussite) de l’activité de copie à l’activité de procédure stockée.
Sous l’onglet Paramètres, effectuez la configuration suivante :
Type de magasin de données : Sélectionnez Espace de travail.
Data Warehouse : sélectionnez votre Data Warehouse.
Nom de la procédure stockée : spécifiez la procédure stockée que vous avez créée dans votre Data Warehouse : [dbo].[ usp_write_watermark].
Développer Paramètres de procédure stockée. Pour spécifier les valeurs des paramètres de la procédure stockée, sélectionnez Importer, puis saisissez les valeurs suivantes pour les paramètres :
Nom Type Valeur LastModifiedtime DateTime @{activity('LookupNewWaterMarkActivity').output.firstRow.NewWatermarkvalue} TableName String @{activity('LookupOldWaterMarkActivity').output.firstRow.TableName}
Étape 6 : Exécuter le pipeline et surveiller le résultat
Dans la barre supérieure, sélectionnez Exécuter sous l’onglet Accueil. Sélectionnez ensuite Enregistrer et exécuter. Le pipeline commence à s’exécuter et vous pouvez surveiller le pipeline sous l’onglet Sortie.
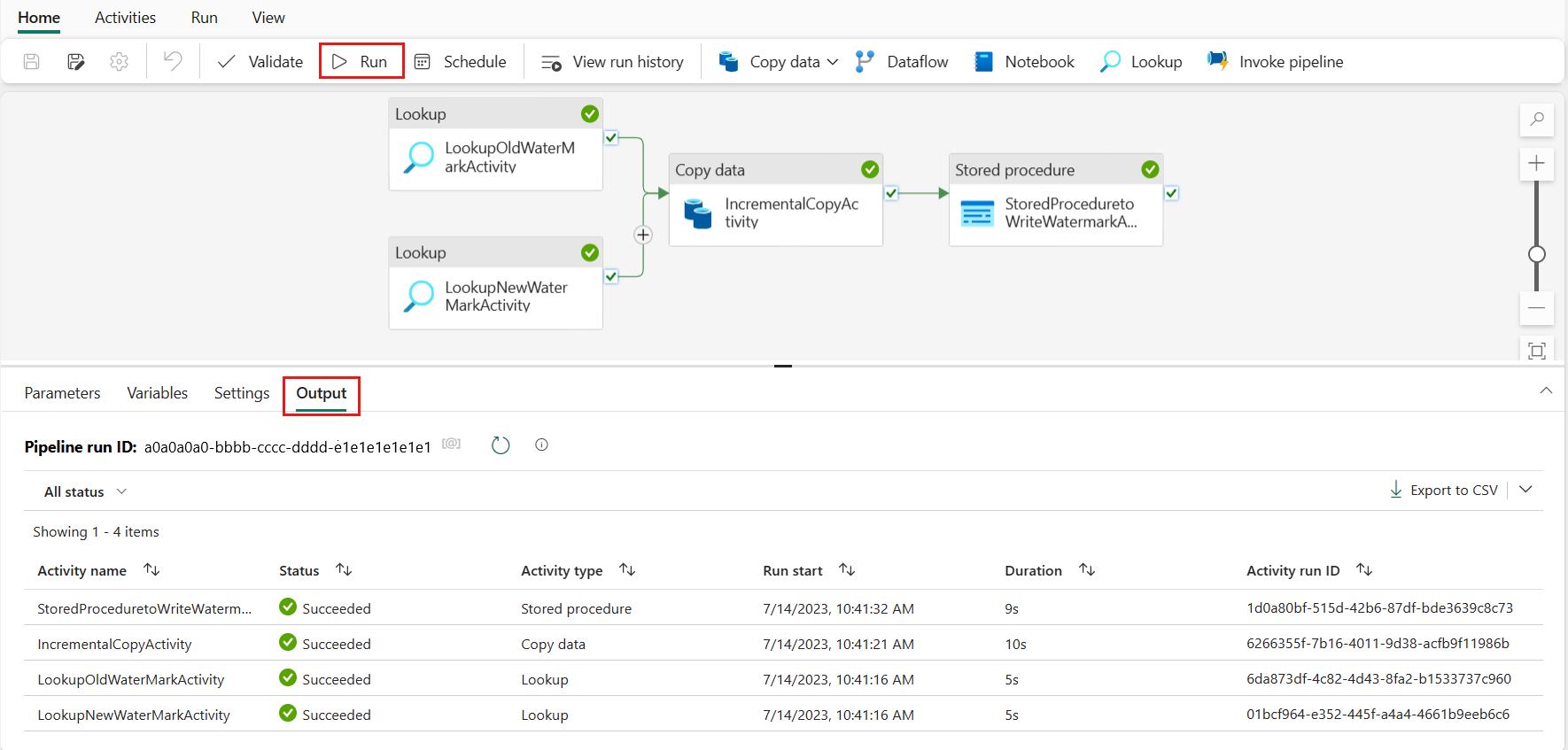
Accédez à votre Lakehouse, vous trouvez que le fichier de données se trouve sous le dossier que vous avez spécifié et vous pouvez sélectionner le fichier pour afficher un aperçu des données copiées.
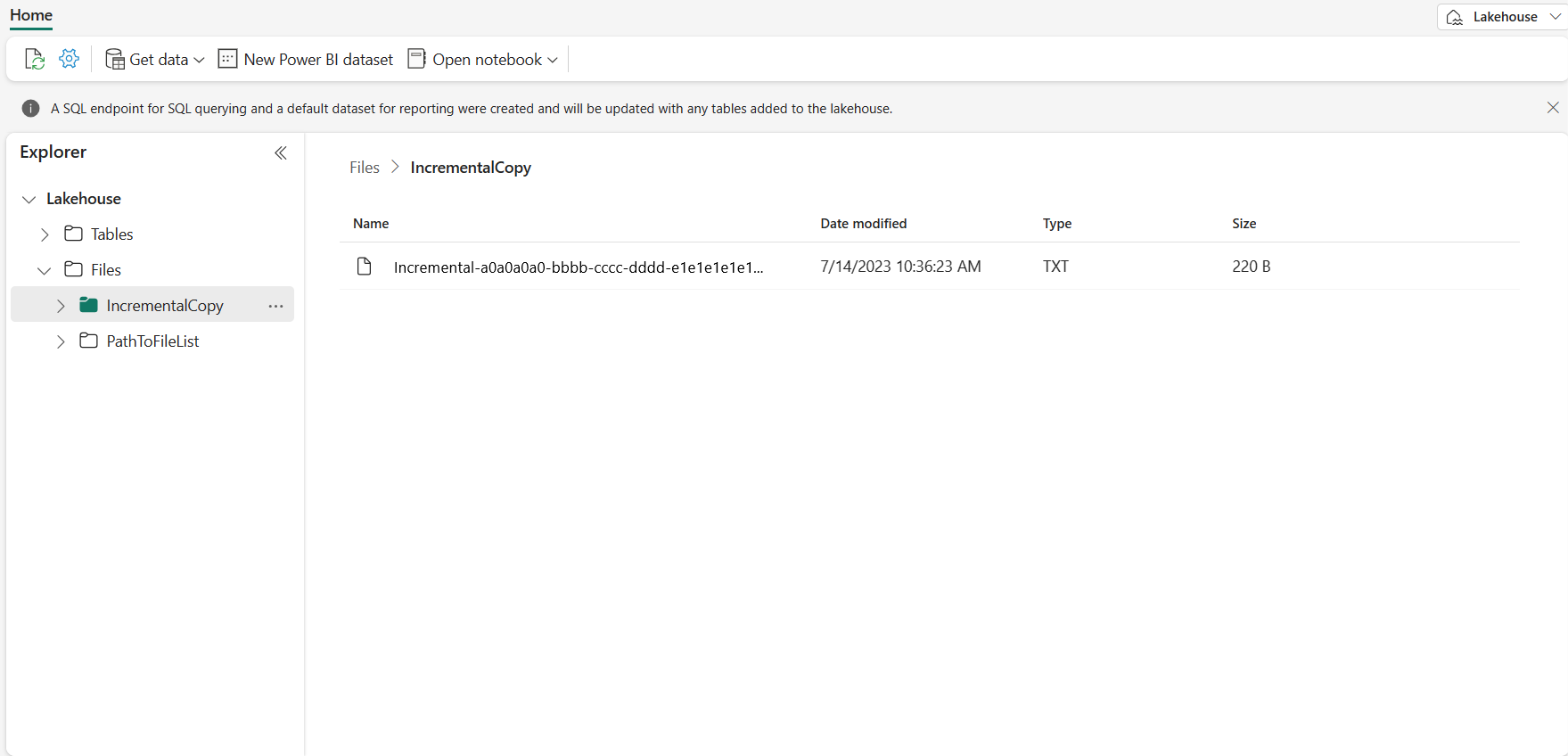
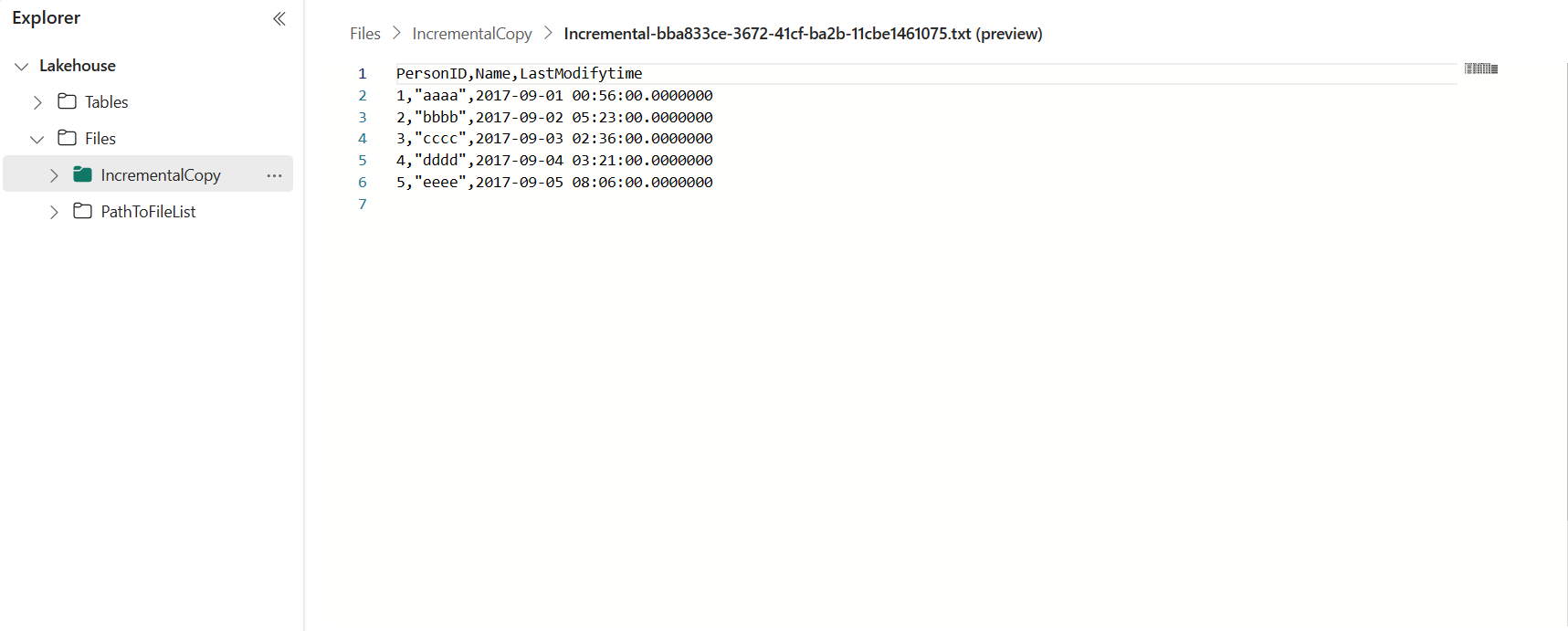
Ajouter des données pour afficher les résultats de la copie incrémentielle
Une fois la première exécution du pipeline terminée, essayons d’ajouter des données supplémentaires à votre table source Data Warehouse pour voir si ce pipeline peut copier vos données incrémentielles.
Étape 1 : Ajouter des données supplémentaires à la source
Insérez de nouvelles données dans votre Data Warehouse en exécutant la requête suivante :
INSERT INTO data_source_table
VALUES (6, 'newdata','9/6/2017 2:23:00 AM')
INSERT INTO data_source_table
VALUES (7, 'newdata','9/7/2017 9:01:00 AM')
Les données mises à jour pour data_source_table sont les suivantes :
PersonID | Name | LastModifytime
-------- | ---- | --------------
1 | aaaa | 2017-09-01 00:56:00.000
2 | bbbb | 2017-09-02 05:23:00.000
3 | cccc | 2017-09-03 02:36:00.000
4 | dddd | 2017-09-04 03:21:00.000
5 | eeee | 2017-09-05 08:06:00.000
6 | newdata | 2017-09-06 02:23:00.000
7 | newdata | 2017-09-07 09:01:00.000
Étape 2 : Déclencher une autre exécution de pipeline et surveiller le résultat
Retour à la page de votre pipeline. Dans la barre supérieure, sélectionnez à nouveau Exécuter sous l’onglet Accueil . Le pipeline commence à s’exécuter et vous pouvez surveiller le pipeline sous Sortie.
Accédez à votre Lakehouse, vous trouverez le nouveau fichier de données copié sous le dossier que vous avez spécifié, et vous pouvez sélectionner le fichier pour afficher un aperçu des données copiées. Vos données incrémentielles s’affichent dans ce fichier.
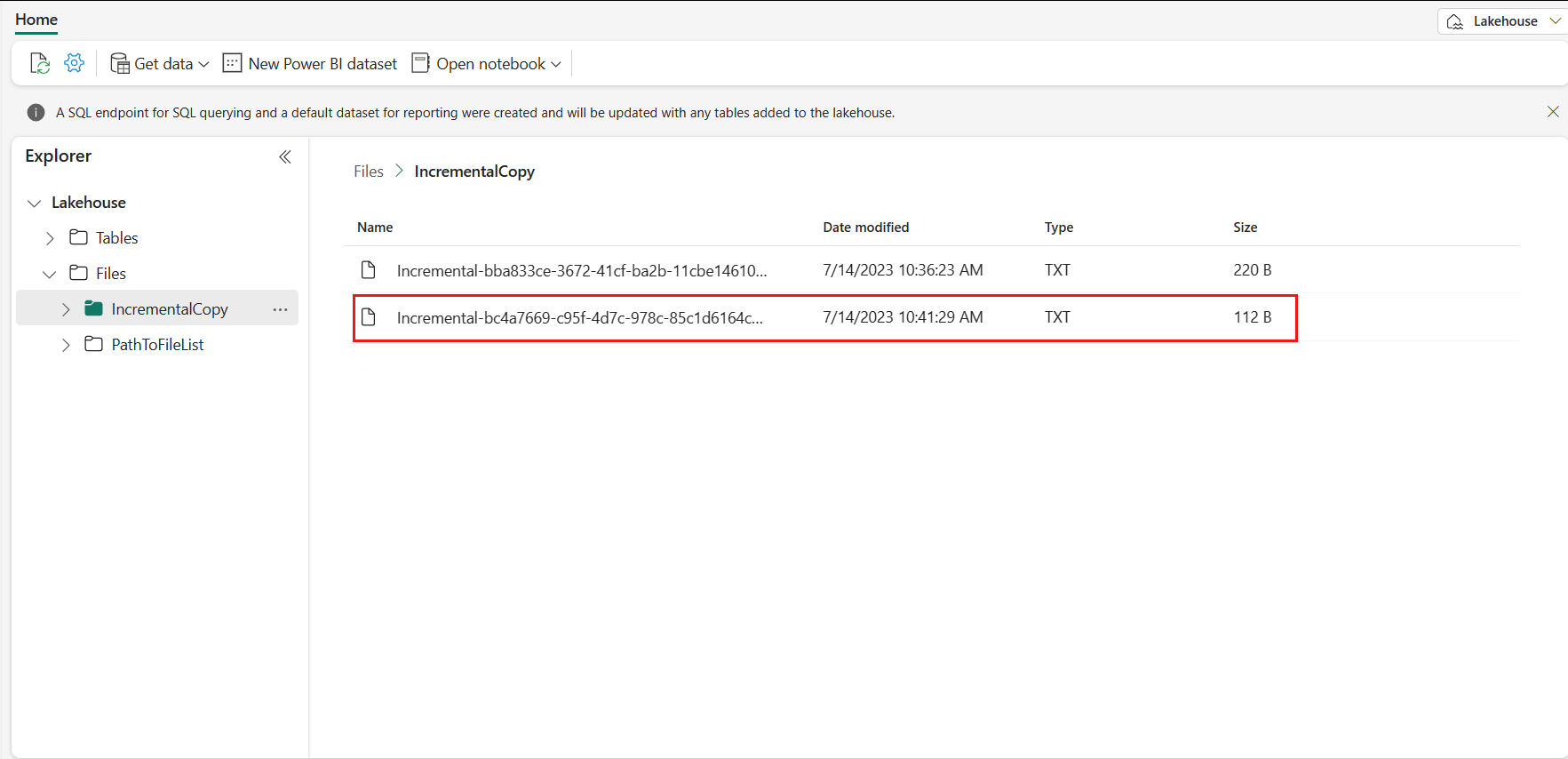
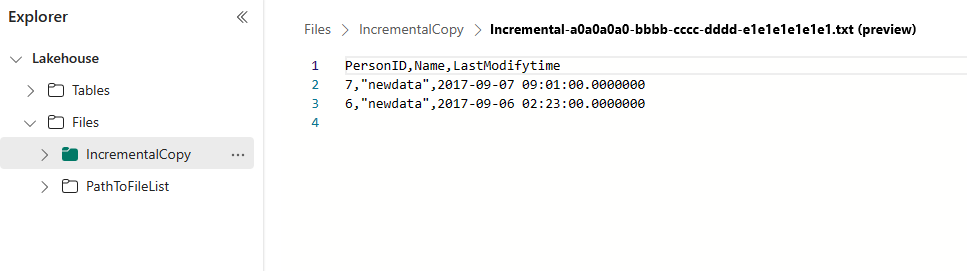
Contenu connexe
Ensuite, avancez pour en savoir plus sur la copie de Stockage Blob Azure vers Lakehouse.