Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Microsoft Fabric vous permet d’opérationnaliser machine learning modèles à l’aide de la fonction PREDICT évolutive. Cette fonction prend en charge le scoring par lots dans n’importe quel moteur de calcul. Vous pouvez générer des prédictions par lots directement à partir d’un bloc-notes Microsoft Fabric ou à partir de la page d’élément d’un modèle ML donné.
Dans cet article, vous allez apprendre à appliquer PREDICT en écrivant du code vous-même, ou en utilisant une expérience d’interface utilisateur guidée qui gère le scoring par lots pour vous.
Prérequis
Obtenez un abonnement Microsoft Fabric. Vous pouvez également vous inscrire à un essai gratuit Microsoft Fabric.
Connectez-vous à Microsoft Fabric.
Basculez vers Fabric à l’aide du sélecteur d’expérience situé en bas à gauche de votre page d’accueil.

Limites
- La fonction PREDICT prend actuellement en charge uniquement les versions de modèle ML suivantes :
- CatBoost
- Keras
- LightGBM
- ONNX
- Prophète
- PyTorch
- SKLearn
- Spark
- Statsmodels
- TensorFlow
- XGBoost
- PREDICT exige que vous enregistrez des modèles ML au format MLflow, avec leurs signatures remplies.
- PREDICT ne prend pas en charge les modèles ML avec des entrées ou des sorties multitensoriels.
Appeler PREDICT à partir d’un notebook
PREDICT prend en charge les modèles empaquetés MLflow dans le registre Microsoft Fabric. S’il existe déjà un modèle ML entraîné et inscrit dans votre espace de travail, vous pouvez passer à l’étape 2. Si ce n’est pas le cas, l’étape 1 fournit un exemple de code pour vous guider dans l’apprentissage d’un exemple de modèle de régression logistique. Utilisez ce modèle pour générer des prédictions par lots à la fin de la procédure.
Effectuer l'apprentissage d’un modèle Machine Learning et l’inscrire auprès de MLflow. L’exemple de code suivant utilise l’API MLflow pour créer une expérience de machine learning, puis démarre une exécution MLflow pour un modèle de régression logistique scikit-learn. La version du modèle est ensuite stockée et inscrite dans le registre Microsoft Fabric. Pour plus d’informations sur les modèles d’entraînement et le suivi de vos propres expériences, consultez comment entraîner des modèles ML avec scikit-learn.
import mlflow import numpy as np from sklearn.linear_model import LogisticRegression from sklearn.datasets import load_diabetes from mlflow.models.signature import infer_signature mlflow.set_experiment("diabetes-demo") with mlflow.start_run() as run: lr = LogisticRegression() data = load_diabetes(as_frame=True) lr.fit(data.data, data.target) signature = infer_signature(data.data, data.target) mlflow.sklearn.log_model( lr, "diabetes-model", signature=signature, registered_model_name="diabetes-model" )Charger des données de test sous forme de DataFrame Spark. Pour générer des prédictions par lots avec le modèle Machine Learning entraîné à l’étape précédente, vous avez besoin de données de test sous la forme d’un DataFrame Spark. Dans le code suivant, remplacez la valeur variable
testpar vos propres données.# You can substitute "test" below with your own data test = spark.createDataFrame(data.frame.drop(['target'], axis=1))Créez un objet
MLFlowTransformerpour charger le modèle Machine Learning pour l’inférence. Pour créer unMLFlowTransformerobjet pour générer des prédictions par lots, effectuez les actions suivantes :- Spécifiez les
testcolonnes DataFrame dont vous avez besoin en tant qu’entrées de modèle (dans ce cas, toutes ces colonnes). - Choisissez un nom pour la nouvelle colonne de sortie (dans ce cas,
predictions). - Fournissez le nom de modèle et la version de modèle appropriés pour la génération de ces prédictions.
Si vous utilisez votre propre modèle ML, remplacez les valeurs des colonnes d’entrée, du nom de la colonne de sortie, du nom du modèle et de la version du modèle.
from synapse.ml.predict import MLFlowTransformer # You can substitute values below for your own input columns, # output column name, model name, and model version model = MLFlowTransformer( inputCols=test.columns, outputCol='predictions', modelName='diabetes-model', modelVersion=1 )- Spécifiez les
Générez des prédictions à l’aide de la fonction PREDICT. Pour appeler la fonction PREDICT, utilisez l’API Transformer, l’API Spark SQL ou une fonction définie par l’utilisateur (User-Defined Function/UDF) PySpark. Les sections suivantes montrent comment générer des prédictions par lots avec les données de test et le modèle ML définis dans les étapes précédentes, en utilisant les différentes méthodes d’appel de la fonction PREDICT.
PREDICT avec l’API Transformer
Ce code appelle la fonction PREDICT avec l’API Transformer. Si vous utilisez votre propre modèle ML, remplacez les valeurs du modèle et des données de test.
# You can substitute "model" and "test" below with values
# for your own model and test data
model.transform(test).show()
PREDICT avec l’API SPARK SQL
Ce code appelle la fonction PREDICT à l’aide de l’API SQL Spark. Si vous utilisez votre propre modèle ML, remplacez les valeurs pour model_name, model_versionet features par le nom de votre modèle, la version du modèle et les colonnes de fonctionnalités.
Remarque
Lorsque vous utilisez l’API SPARK SQL pour générer des prédictions, vous devez toujours créer un MLFlowTransformer objet, comme indiqué à l’étape 3.
from pyspark.ml.feature import SQLTransformer
# You can substitute "model_name," "model_version," and "features"
# with values for your own model name, model version, and feature columns
model_name = 'diabetes-model'
model_version = 1
features = test.columns
sqlt = SQLTransformer().setStatement(
f"SELECT PREDICT('{model_name}/{model_version}', {','.join(features)}) as predictions FROM __THIS__")
# You can substitute "test" below with your own test data
sqlt.transform(test).show()
PREDICT avec une fonction définie par l’utilisateur
Ce code appelle la fonction PREDICT à l’aide d’une fonction UDF PySpark. Si vous utilisez votre propre modèle ML, remplacez les valeurs du modèle et des fonctionnalités.
from pyspark.sql.functions import col, pandas_udf, udf, lit
# You can substitute "model" and "features" below with your own values
my_udf = model.to_udf()
features = test.columns
test.withColumn("PREDICT", my_udf(*[col(f) for f in features])).show()
Générer du code PREDICT à partir de la page d’élément d’un modèle Machine Learning
Dans la page d’élément de n’importe quel modèle ML, vous pouvez choisir l’une de ces options pour démarrer la génération de prédiction par lots pour une version spécifique d’un modèle, à l’aide de la fonction PREDICT :
- Copiez un modèle de code dans un bloc-notes et personnalisez les paramètres vous-même.
- Utilisez une expérience d’interface utilisateur guidée pour générer du code PREDICT.
Utiliser une expérience d’interface utilisateur guidée
L’expérience guidée de l’interface utilisateur vous guide tout au long de ces étapes :
- Sélectionnez les données sources pour l'évaluation.
- Mappez correctement les données à vos entrées de modèle ML.
- Spécifiez la destination de vos sorties de modèle.
- Créez un notebook qui utilise PREDICT pour générer et stocker les résultats de prédiction.
Pour utiliser l’expérience guidée,
Accéder à la page d’élément d’une version de modèle ML donnée.
Dans la liste déroulante Appliquer cette version, sélectionnez Appliquer ce modèle dans l’Assistant.
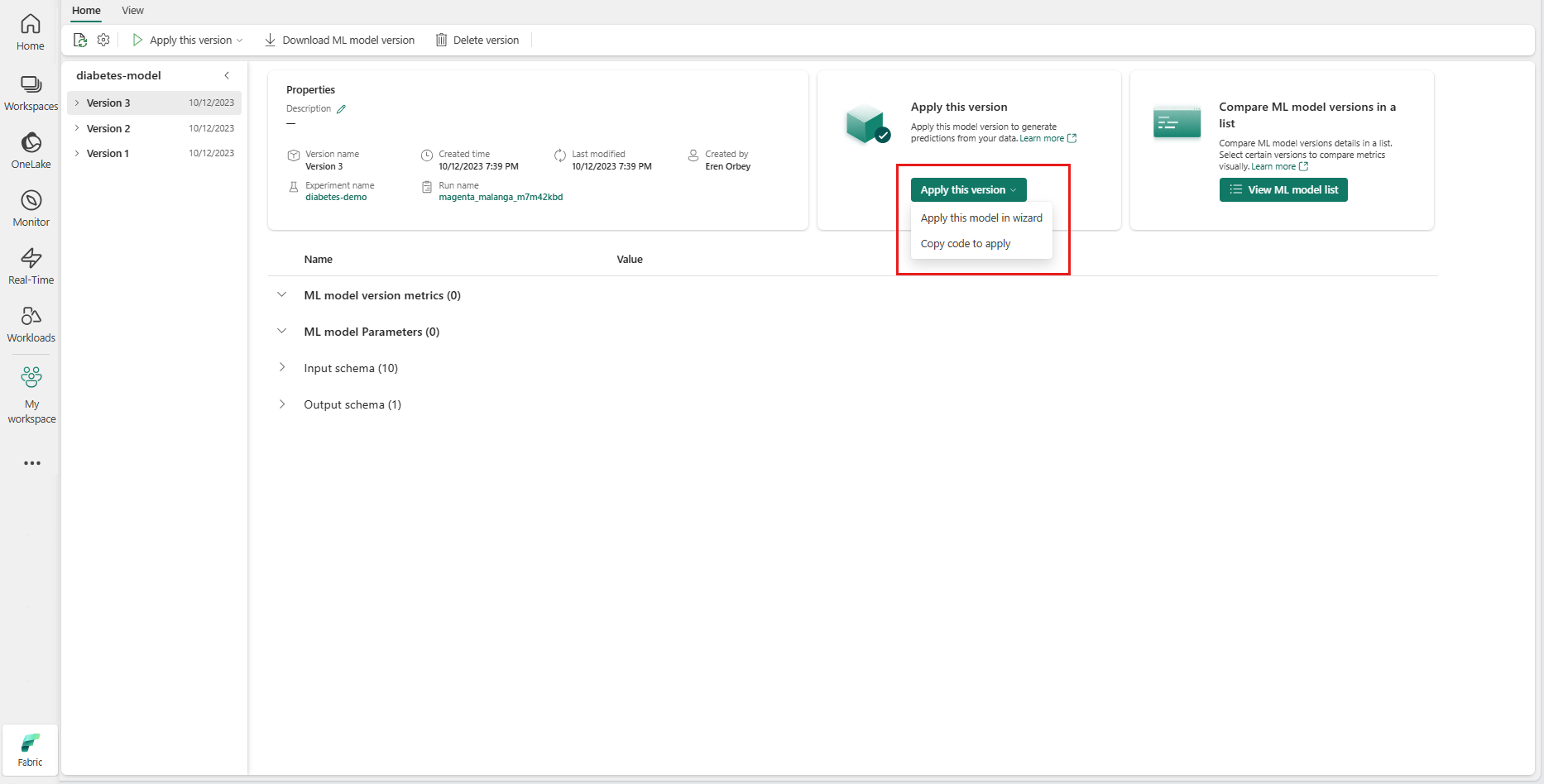
À l’étape « Sélectionner une table d’entrée », la fenêtre « Appliquer les prédictions du modèle ML » s’ouvre.
Sélectionnez une table d'entrée depuis un "lakehouse" de votre espace de travail actuel.
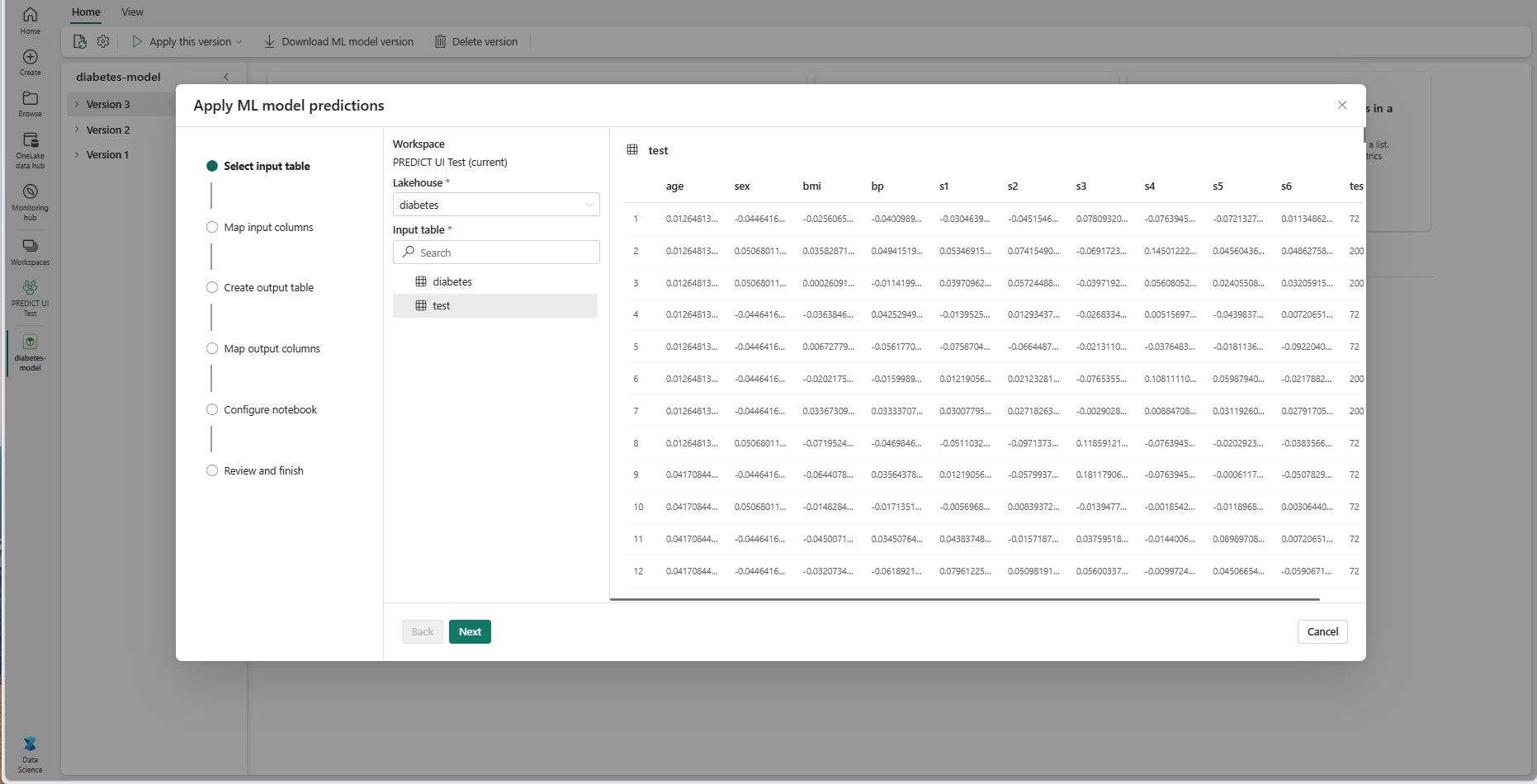
Sélectionnez Suivant pour accéder à l’étape « Colonnes d’entrée de carte ».
Mappez les noms de colonnes de la table source aux champs d’entrée du modèle ML, qui sont extraits de la signature du modèle. Vous devez fournir une colonne d’entrée pour tous les champs obligatoires du modèle. En outre, les types de données de colonne source doivent correspondre aux types de données attendus du modèle.
Conseil
L’Assistant préremplit ce mappage si les noms des colonnes de la table d’entrée correspondent aux noms de colonnes enregistrés dans la signature du modèle ML.
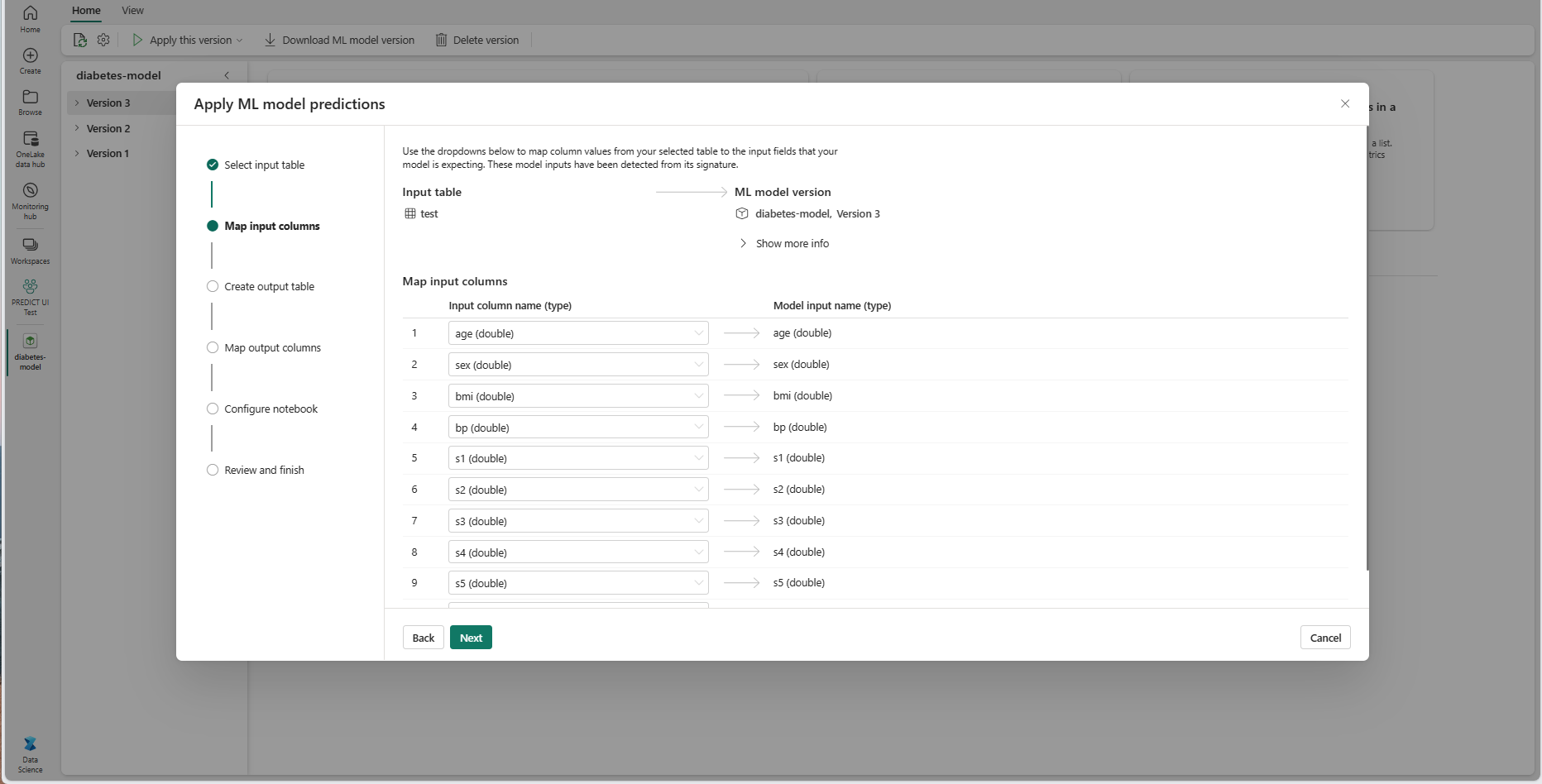
Sélectionnez Suivant pour passer à l’étape « Créer une table de sortie ».
Fournissez un nom pour une nouvelle table dans le lakehouse sélectionné de votre espace de travail actuel. Cette table de sortie stocke les valeurs d’entrée de votre modèle ML et ajoute les valeurs de prédiction à cette table. Par défaut, la table de sortie est créée dans le même lakehouse que la table d’entrée. Vous pouvez modifier le lakehouse de destination.
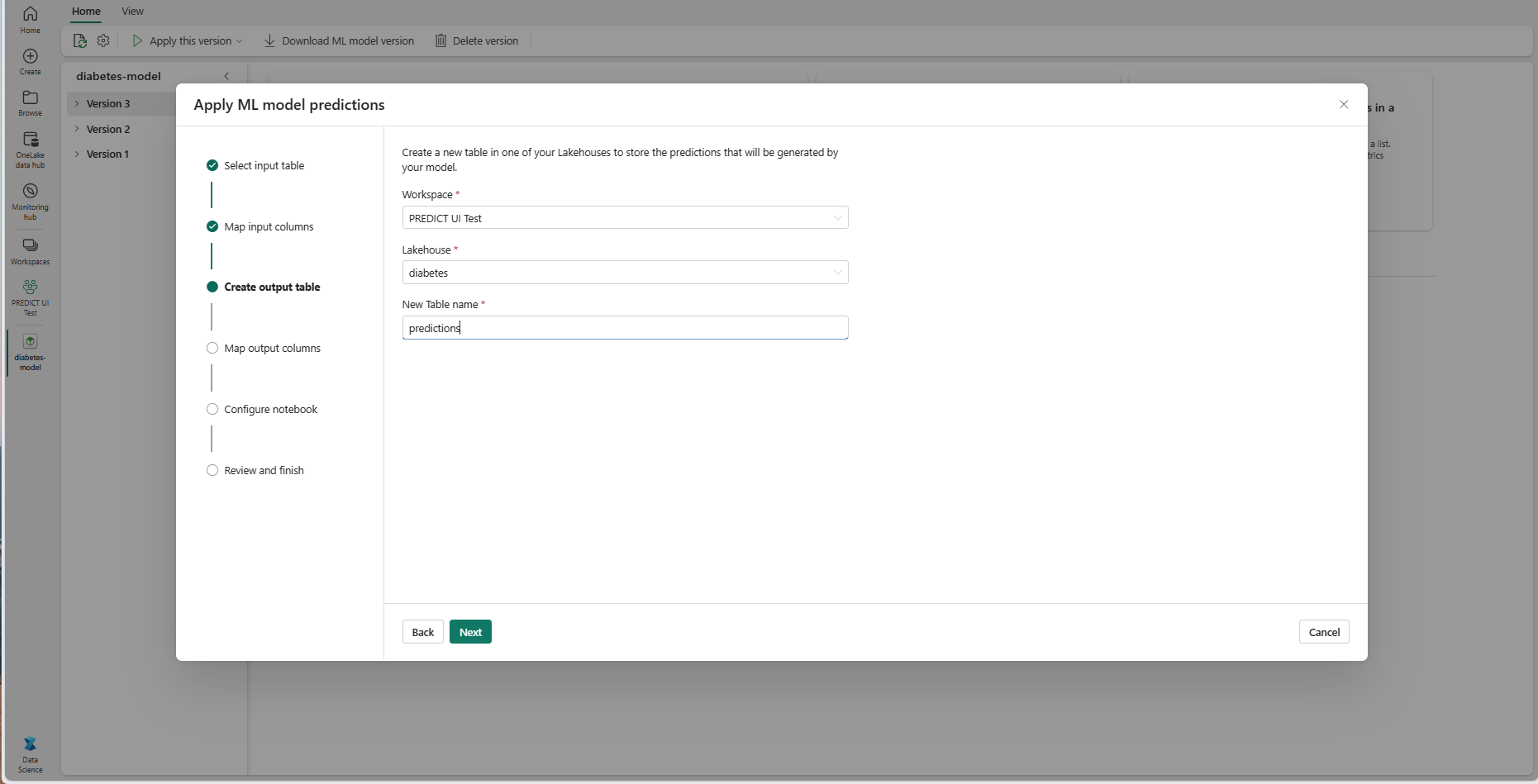
Sélectionnez Suivant pour accéder à l’étape « Colonnes d’entrée de carte ».
Utilisez les champs de texte fournis pour nommer les colonnes de la table de sortie qui stockent les prédictions du modèle ML.
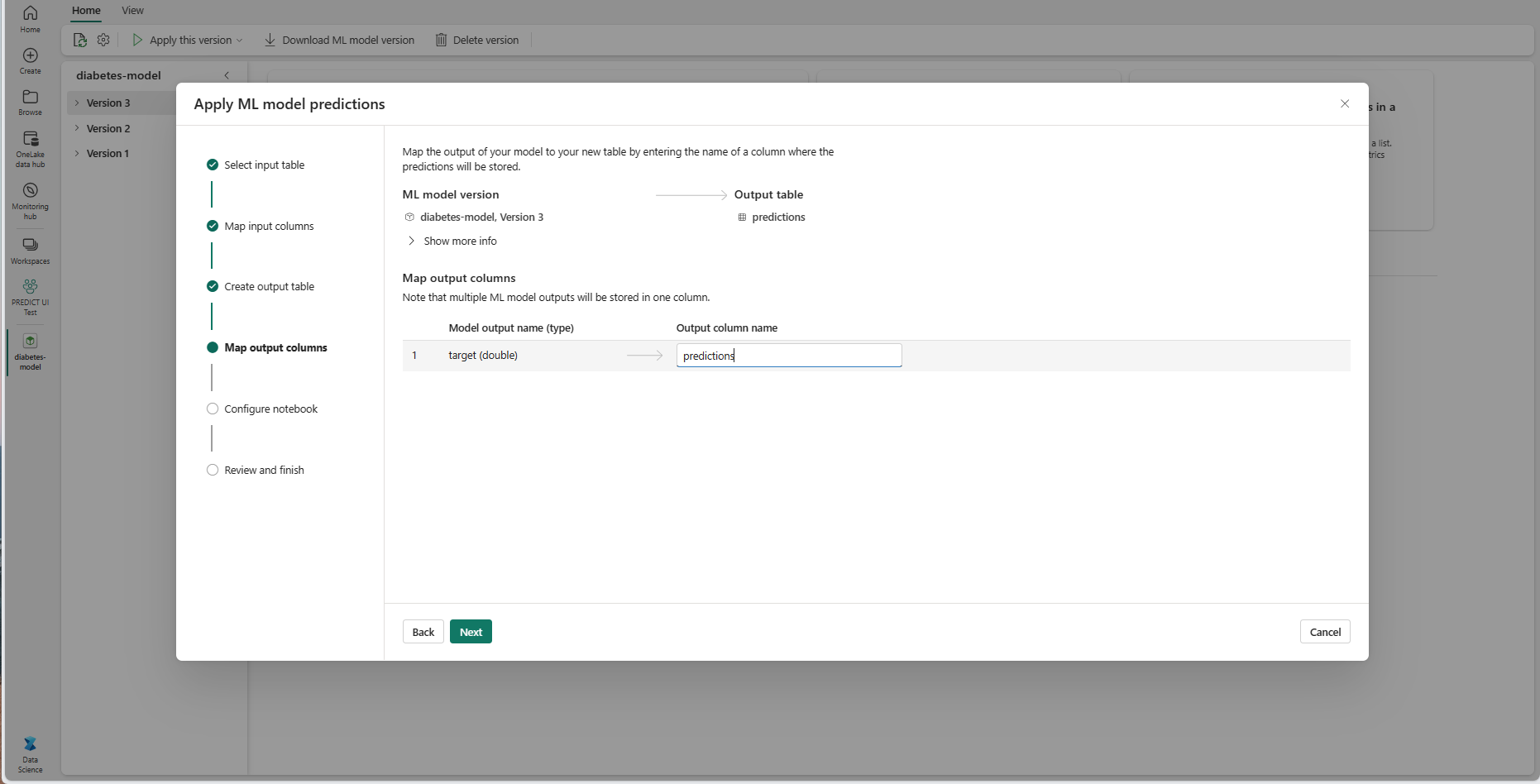
Sélectionnez Suivant pour accéder à l’étape « Configurer le notebook ».
Fournissez un nom pour un nouveau notebook qui exécute le code PREDICT généré. L’Assistant affiche un aperçu du code généré à cette étape. Si vous le souhaitez, vous pouvez copier le code dans votre presse-papiers et le coller dans un notebook existant.
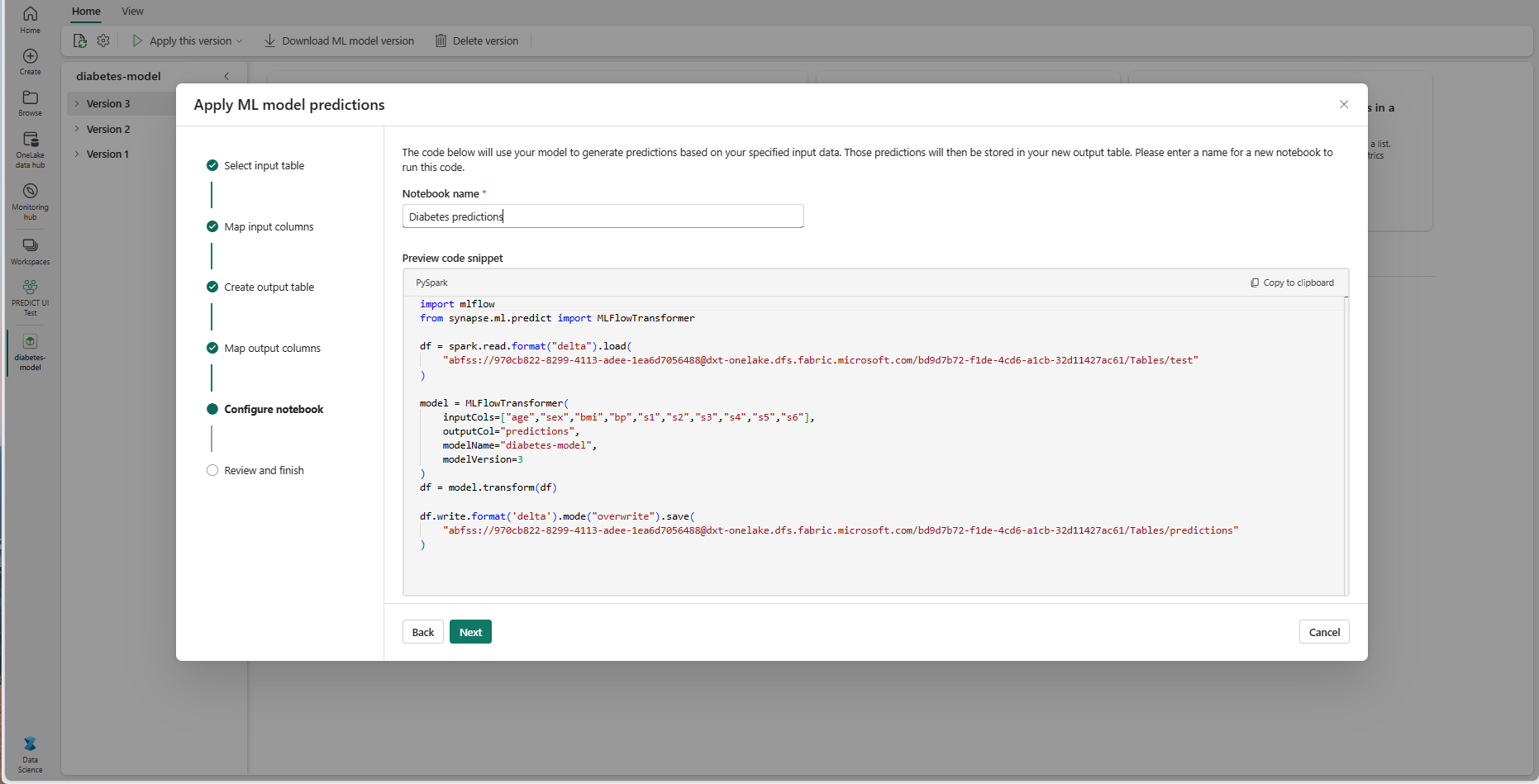
Sélectionnez Suivant pour passer à l’étape « Vérifier et terminer ».
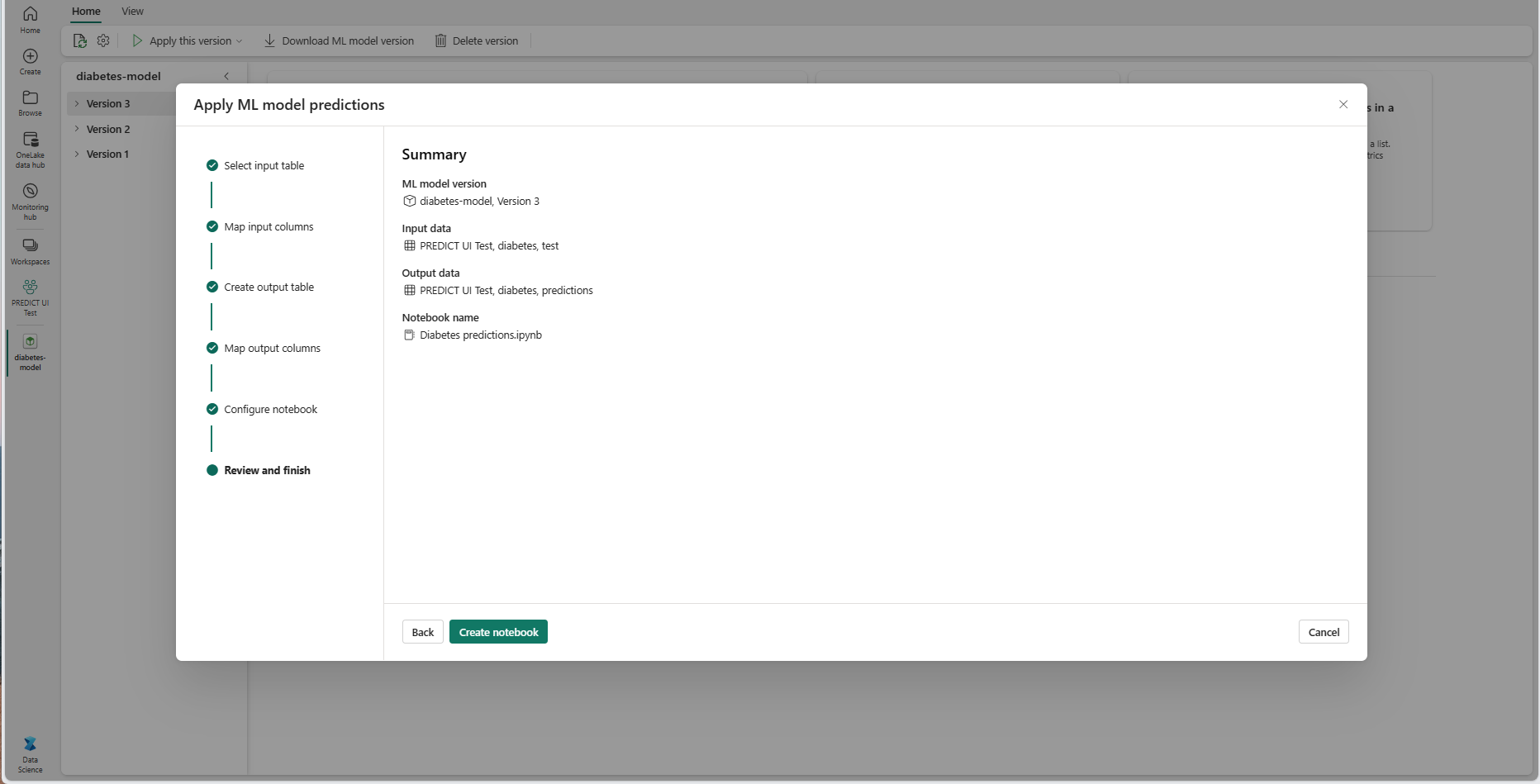
Passez en revue les détails de la page récapitulative et sélectionnez Créer un notebook pour ajouter le nouveau notebook avec son code généré à votre espace de travail. Vous êtes dirigé directement vers ce notebook, où vous pouvez exécuter le code pour générer et stocker des prédictions.







Utiliser un modèle de code personnalisable
Pour utiliser un modèle de code pour générer des prédictions par lots :
- Accédez à la page d’élément d’une version de modèle Machine Learning donnée.
- Sélectionnez Copier le code à appliquer dans la liste déroulante Appliquer cette version. La sélection copie un modèle de code personnalisable.
Vous pouvez coller ce modèle de code dans un notebook pour générer des prédictions par lots avec votre modèle Machine Learning. Pour exécuter correctement le modèle de code, remplacez manuellement les valeurs suivantes :
-
<INPUT_TABLE>: chemin d’accès au fichier de la table qui fournit des entrées au modèle ML. -
<INPUT_COLS>: tableau de noms de colonnes de la table d’entrée à alimenter vers le modèle ML. -
<OUTPUT_COLS>: nom d’une nouvelle colonne dans la table de sortie qui stocke les prédictions. -
<MODEL_NAME>: nom du modèle ML à utiliser pour générer des prédictions. -
<MODEL_VERSION>: version du modèle ML à utiliser pour générer des prédictions. -
<OUTPUT_TABLE>: chemin d’accès au fichier de la table qui stocke les prédictions.

import mlflow
from synapse.ml.predict import MLFlowTransformer
df = spark.read.format("delta").load(
<INPUT_TABLE> # Your input table filepath here
)
model = MLFlowTransformer(
inputCols=<INPUT_COLS>, # Your input columns here
outputCol=<OUTPUT_COLS>, # Your new column name here
modelName=<MODEL_NAME>, # Your ML model name here
modelVersion=<MODEL_VERSION> # Your ML model version here
)
df = model.transform(df)
df.write.format('delta').mode("overwrite").save(
<OUTPUT_TABLE> # Your output table filepath here
)