Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
S’applique à :✅ Entrepôt dans Microsoft Fabric
Cet article met en évidence les fonctionnalités et innovations de l’architecture de Fabric Data Warehouse qui alimentent ses performances, sa scalabilité et son efficacité économique.
Fabric Data Warehouse s’exécute sur une architecture future dans une plateforme de données convergée. Avec un format de stockage Delta ouvert et une intégration OneLake, vos données dans Fabric Data Warehouse sont prêtes à être analysées.
Architecture de haut niveau

Fabric Data Warehouse est conçu pour l’analytique à grande échelle avec les blocs de construction suivants :
| Bloc de construction | Description |
|---|---|
| Optimiseur de requête unifié | Génère un plan d’exécution optimal pour les environnements cloud distribués, quelle que soit la qualité des requêtes SQL créées par l’utilisateur. |
| Traitement des requêtes distribuées | Prend en charge l’exécution massive de requêtes parallèles avec une infrastructure cloud à mise à l’échelle automatique rapide, fournissant instantanément les ressources de calcul nécessaires pour les requêtes. Les charges de travail SELECT et DML distinctes utilisent des pools distincts pour une exécution efficace et isolée. |
| Moteur d’exécution de requête | Moteur SQL pour l’exécution de requêtes d’analyse sur une grande quantité de données avec des performances rapides et une concurrence élevée. |
| Gestion des métadonnées et des transactions | Les métadonnées résident dans le serveur frontal, le back-end et dans le cache SSD local et le stockage OneLake distant. Prend en charge les transactions simultanées et garantit la conformité ACID. |
| Stockage dans OneLake | Log Structured Tables implémentées à l’aide du format de table Delta ouvert, un modèle lakehouse avec un stockage ouvert sécurisé. |
| Plateforme Fabric | La plateforme Fabric fournit un modèle d’authentification et de sécurité unifié, de surveillance et d’audit. Votre entrepôt de données Fabric est automatiquement disponible pour d’autres services de plateforme Fabric pour répondre aux besoins de l’entreprise, notamment Power BI, les pipelines de données dans Data Factory, Real-Time Intelligence, etc. |
Moteur d’optimiseur de requête unifié
L’optimiseur de requête unifié dans Fabric Data Warehouse est le moteur qui décide du moyen le plus intelligent d’exécuter vos requêtes SQL.
Lorsque vous envoyez une requête, l’optimiseur de requête unifié examine les méthodes possibles pour l’exécuter : comment joindre des tables, où déplacer des données et comment utiliser des ressources telles que l’UC, la mémoire et le réseau. L’optimiseur de requête unifié ne choisit pas simplement la première option, il choisit le plan le plus optimal dans le temps autorisé en évaluant les coûts entre ces facteurs et les métadonnées et statistiques disponibles.
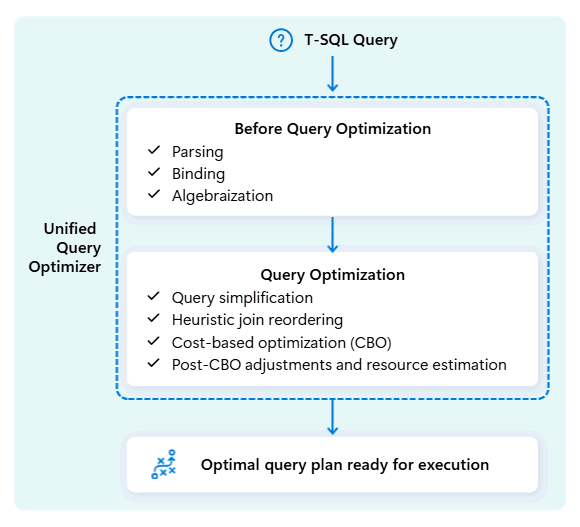
Lors de l’optimisation du plan d’exécution d’une requête, l’optimiseur de requête unifié considère tout en un coup : la forme de votre requête, la distribution des données de vos tables et le coût du déplacement des données par rapport au traitement localement. L’optimiseur de requête unifié peut faire des compromis intelligents, comme décider si la répartition d’une petite table est moins coûteuse que la redistribution d'une grande. Cela signifie moins de shuffles de données inutiles, une meilleure utilisation du calcul et des performances plus rapides, même pour les requêtes T-SQL complexes ou mal écrites.
Les performances cohérentes ne nécessitent pas que les développeurs consacrent du temps au réglage manuel des requêtes T-SQL. Par exemple, vous n’avez pas besoin de déterminer manuellement le meilleur JOIN ordre dans les requêtes. Si votre SQL répertorie d’abord la table volumineuse et une table de données plus petite et très sélective, l’optimiseur peut automatiquement changer de position pour améliorer les performances. Il utilise la table plus petite comme point de départ pour construire les correspondances (côté « build ») et la table plus grande comme celle à explorer (côté « sonde », où l'on recherche les correspondances). Cette approche réduit l’utilisation de la mémoire, réduit le déplacement des données et améliore le parallélisme, tout en fournissant des résultats précis.
L’optimiseur de requête unifié apprend en permanence à partir des exécutions de requêtes passées à mesure que les charges de travail évoluent, en affinant son algorithme d’optimisation pour offrir les meilleures performances possibles. Les utilisateurs bénéficient automatiquement de l’exécution rapide des requêtes, quelle que soit la complexité et sans avoir à intervenir.
Moteur de traitement des requêtes distribuées
Dans Fabric Data Warehouse, le moteur de traitement des requêtes distribué alloue des ressources informatiques aux tâches dans les plans de requête. Le moteur de traitement des requêtes distribué peut planifier des tâches entre les nœuds de calcul afin que chaque nœud exécute une partie d’un plan de requête, ce qui permet l’exécution parallèle pour accélérer les performances. Les rapports complexes sur les jeux de données volumineux peuvent tirer parti du traitement des requêtes distribuées.
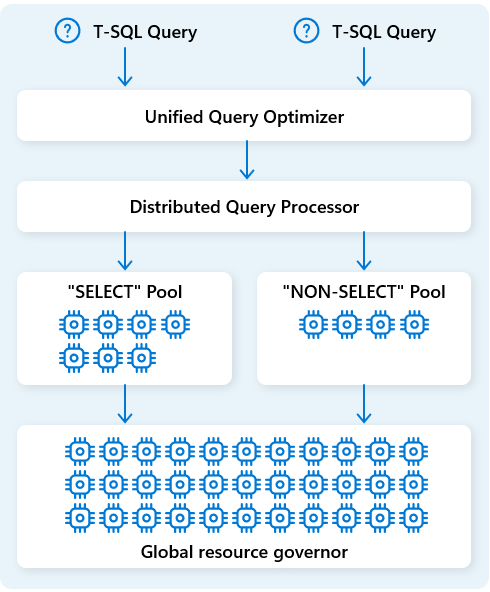
Pour optimiser davantage les ressources, le moteur de traitement de requêtes distribué sépare les ressources de calcul en deux pools : pour les requêtes et pour SELECT les tâches d’ingestion de données (NON-SELECT requêtes). Chaque charge de travail reçoit les ressources dédiées en fonction des besoins. Cela signifie, par exemple, que vos travaux ETL nocturnes ne retardent pas les tableaux de bord matinaux.
Avec l’approvisionnement rapide des nœuds dans le cloud, le moteur de traitement des requêtes distribué met automatiquement à l’échelle les ressources de calcul vers le haut ou vers le bas en réponse aux modifications apportées au volume de requêtes, à la taille des données et à la complexité des requêtes. Fabric Data Warehouse dispose de fonctionnalités de traitement parallèle pour les petits jeux de données ou les données à l’échelle multioctet.
Moteur d’exécution de requête
Le moteur d’exécution de requête est un processus qui exécute des parties du plan d’exécution distribué qui sont affectées aux nœuds de calcul individuels. Le moteur d’exécution de requête est basé sur le même moteur utilisé par SQL Server et Azure SQL Database pour utiliser des formats d’exécution en mode batch et de données en colonnes pour une analytique efficace sur le Big Data à un coût optimal.
Le moteur d’exécution de requête lit les données directement à partir de fichiers Delta Parquet stockés dans Fabric OneLake et tire parti de plusieurs couches de mise en cache (mémoire et SSD) pour accélérer les performances des requêtes et garantir que les requêtes s’exécutent à une vitesse optimale. Le moteur d’exécution de requête traite les données en mémoire et, le cas échéant, récupère des données supplémentaires à partir du cache SSD ou du stockage OneLake.
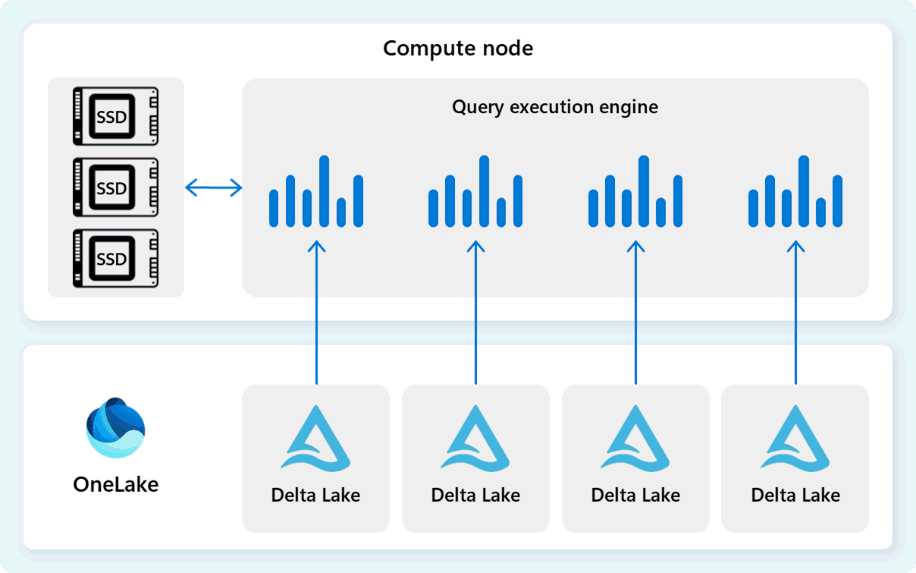
Au fur et à mesure qu’il traite les données, le moteur d’exécution de requête effectue l’élimination des colonnes et des groupes de lignes pour ignorer les segments qui ne sont pas pertinents pour la requête. Cette optimisation réduit la quantité de données analysées à partir des fichiers et du cache de mémoire, ce qui permet de réduire l’utilisation des ressources et d’améliorer le temps d’exécution global.
Le moteur d’exécution de requête excelle au filtrage et à l’agrégation de milliards de lignes, prenant en charge les modèles d’analyse de données génériques utilisés dans les solutions d’entrepôt de données modernes. L’exécution en mode batch tire parti de la capacité de processeur moderne à traiter plusieurs lignes en parallèle, réduisant considérablement la surcharge et rendant les requêtes exécutées jusqu’à des centaines de fois plus rapidement que l’exécution classique de lignes par ligne.
Gestion des métadonnées et des transactions
Le moteur d’entrepôt utilise des métadonnées pour décrire le schéma de table, l’organisation de fichiers, l’historique des versions et les états transactionnels. Ces métadonnées permettent au moteur d’entrepôt de gérer et d’interroger efficacement les données. Fabric Data Warehouse offre une architecture robuste et complète de gestion des métadonnées et des transactions, étendant un gestionnaire de transactions OLTP pour orchestrer des opérations de métadonnées hautement simultanées et garantir la conformité ACID.
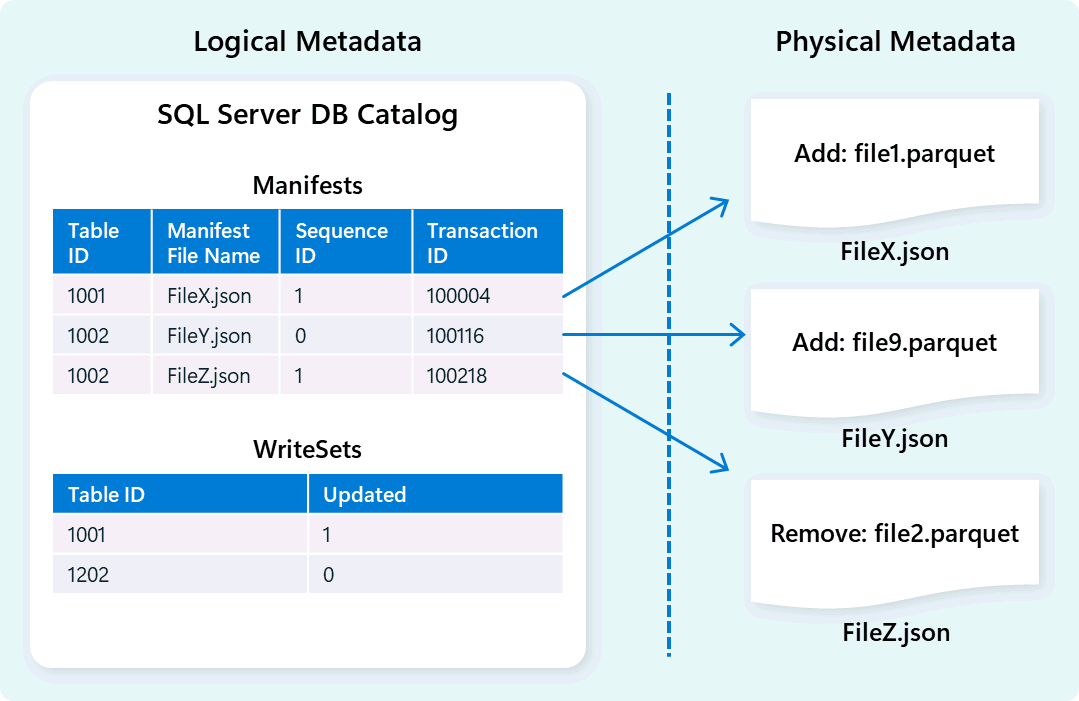
Cette conception permet une navigation rapide et fiable des états transactionnels, prenant en charge les charges de travail avec une concurrence élevée tout en garantissant la cohérence.
Stockage et ingestion de données
Fabric Data Warehouse utilise une architecture lakehouse avec le format Delta open source pour un stockage évolutif, sécurisé et hautes performances. Le format de table Delta prend en charge le contrôle de version des données, ce qui permet l’accès instantané aux instantanés historiques via le voyage dans le temps et le clonage sans copie pour les opérations de test et de restauration sécurisées. Les données utilisateur sont stockées dans OneLake, ce qui permet à tous les moteurs Fabric d’accéder efficacement aux données partagées sans redondance.
En s’appuyant sur cette base, Fabric Data Warehouse est conçu pour offrir des performances optimales d’ingestion des données avec un focus sur la simplicité et la flexibilité. Le moteur gère efficacement le stockage des données de table via le compactage automatique des données, qui consolide les fichiers fragmentés en arrière-plan pour réduire l’analyse inutile des données. Sa méthode de distribution de données intelligente divise et organise les données en cellules micro-partitionnés pour améliorer le traitement parallèle et améliorer les résultats des requêtes. Ces fonctionnalités fonctionnent de manière autonome, sans avoir besoin d’ajustements manuels.