Créer un lakehouse pour Direct Lake
Cet article explique comment créer un lakehouse, créer une table Delta dans le lakehouse, puis créer un modèle sémantique de base pour le lakehouse dans un espace de travail Microsoft Fabric.
Avant de bien démarrer la création d’un lakehouse pour Direct Lake, veillez à lire la vue d’ensemble de Direct Lake.
Créer un lakehouse
Dans votre espace de travail Microsoft Fabric, sélectionnez Nouveau>Plus d’options, puis, dans Engineering données, choisissez la vignette Lakehouse.
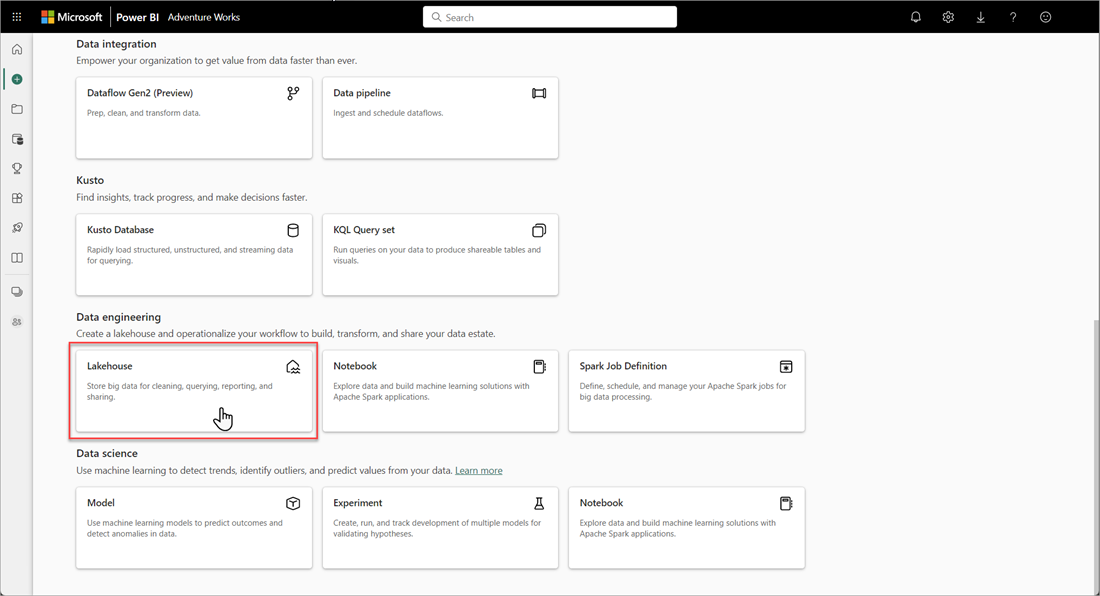
Dans la zone de dialogue Nouveau Lakehouse, saisissez un nom, puis sélectionnez Créer. Le nom ne peut contenir que des caractères alphanumériques et des traits de soulignement.
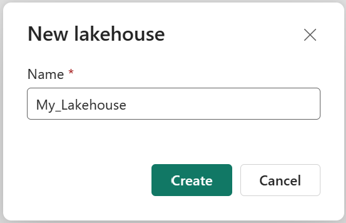
Assurez-vous que le nouveau lakehouse a été créé et s’ouvre correctement.
Créer une table Delta dans le lakehouse
Après avoir créé un lakehouse, vous devez créer au moins une table Delta pour que Direct Lake puisse accéder à certaines données. Direct Lake peut lire des fichiers au format parquet, mais, pour des performances optimales, il est préférable de compresser les données à l’aide de la méthode de compression VORDER. VORDER compresse les données au moyen d’un algorithme de compression natif du moteur Power BI. Le moteur peut ainsi charger les données en mémoire aussi rapidement que possible.
Il existe plusieurs options pour charger des données dans un lakehouse, notamment des pipelines de données et des scripts. Les étapes suivantes utilisent PySpark pour ajouter une table Delta à un lakehouse grâce à un jeu de données Azure Open Dataset :
Dans le lakehouse nouvellement créé, sélectionnez Ouvrir le notebook, puis Nouveau notebook.
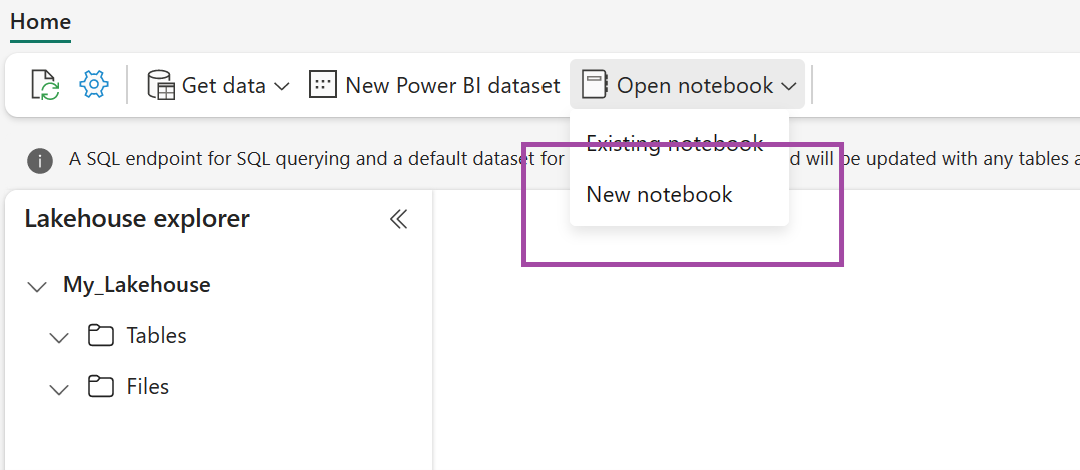
Copiez et collez l’extrait de code suivant dans la première cellule de code pour permettre à SPARK d’accéder au modèle ouvert, puis appuyez sur Maj + Entrée pour exécuter le code.
# Azure storage access info blob_account_name = "azureopendatastorage" blob_container_name = "holidaydatacontainer" blob_relative_path = "Processed" blob_sas_token = r"" # Allow SPARK to read from Blob remotely wasbs_path = 'wasbs://%s@%s.blob.core.windows.net/%s' % (blob_container_name, blob_account_name, blob_relative_path) spark.conf.set( 'fs.azure.sas.%s.%s.blob.core.windows.net' % (blob_container_name, blob_account_name), blob_sas_token) print('Remote blob path: ' + wasbs_path)Assurez-vous que le code génère correctement un chemin distant d’objet blob.
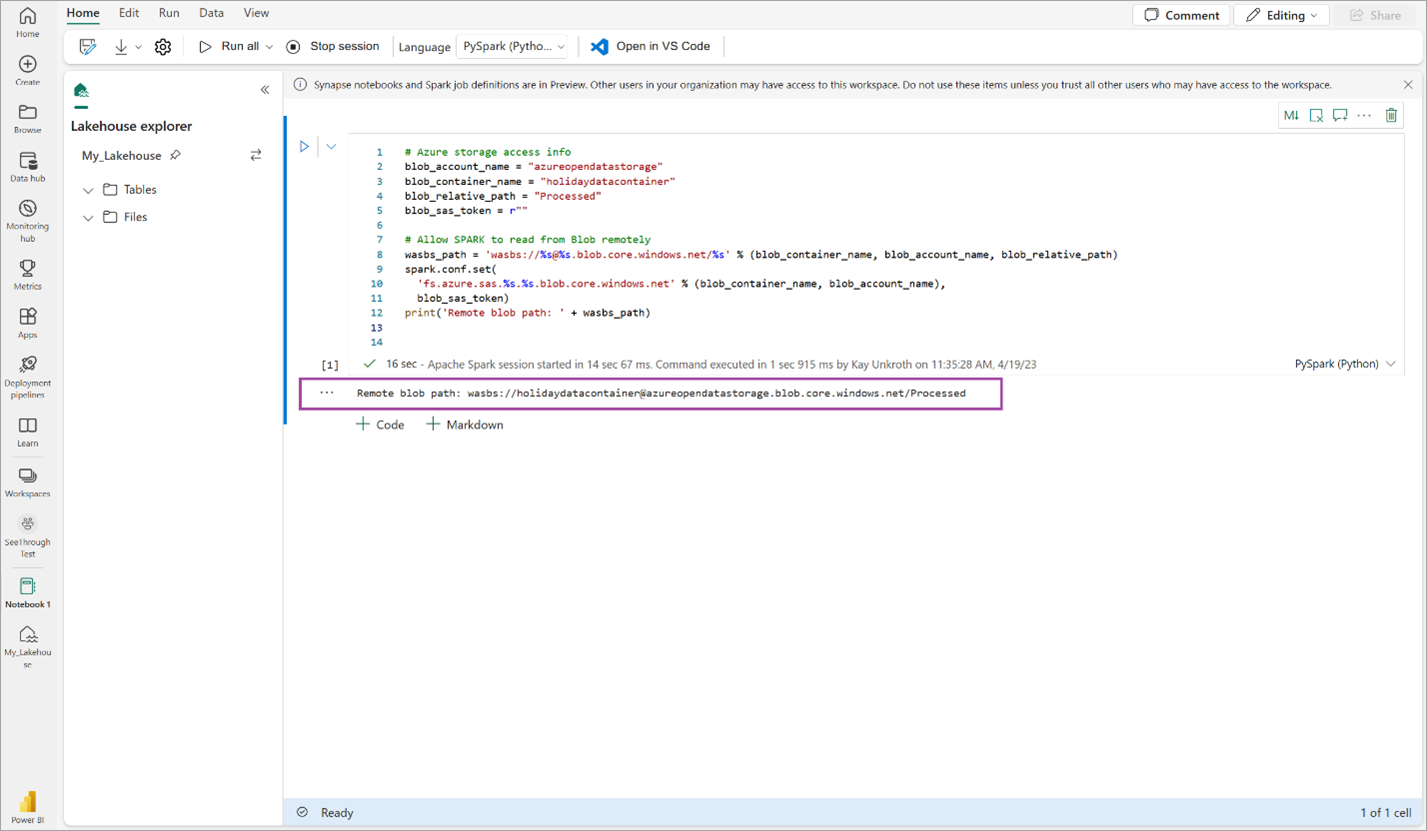
Copiez et collez le code suivant dans la cellule suivante, appuyez ensuite sur Maj + Entrée.
# Read Parquet file into a DataFrame. df = spark.read.parquet(wasbs_path) print(df.printSchema())Assurez-vous que le code génère correctement le schéma DataFrame.
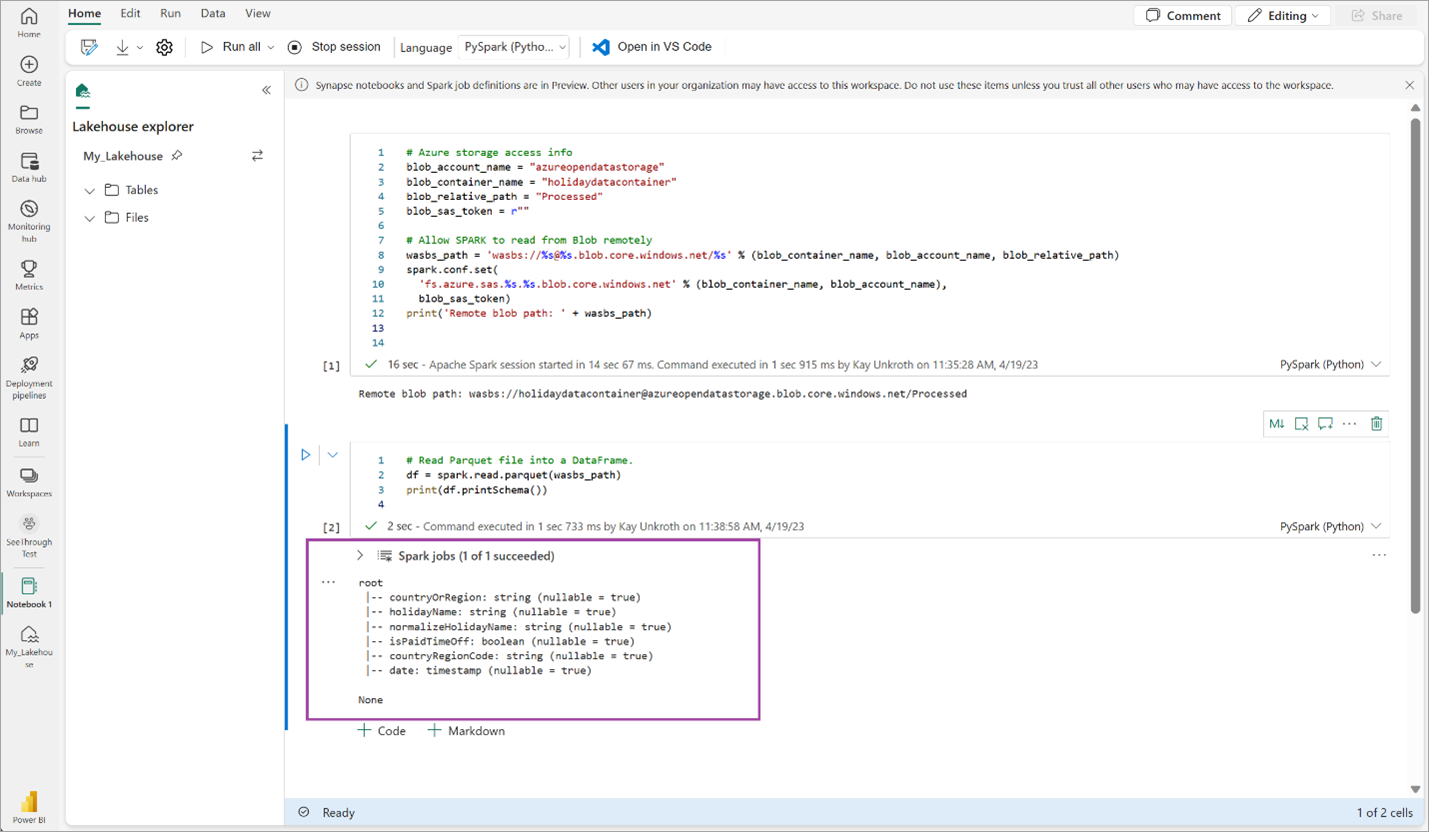
Copiez et collez les lignes suivantes dans la cellule suivante, puis appuyez sur Maj + Entrée. La première instruction active la méthode de compression VORDER, tandis que la suivante enregistre le DataFrame en tant que table Delta dans le lakehouse.
# Save as delta table spark.conf.set("spark.sql.parquet.vorder.enabled", "true") df.write.format("delta").saveAsTable("holidays")Assurez-vous du bon achèvement de tous les travaux SPARK. Développez la liste des travaux SPARK pour afficher des détails supplémentaires.
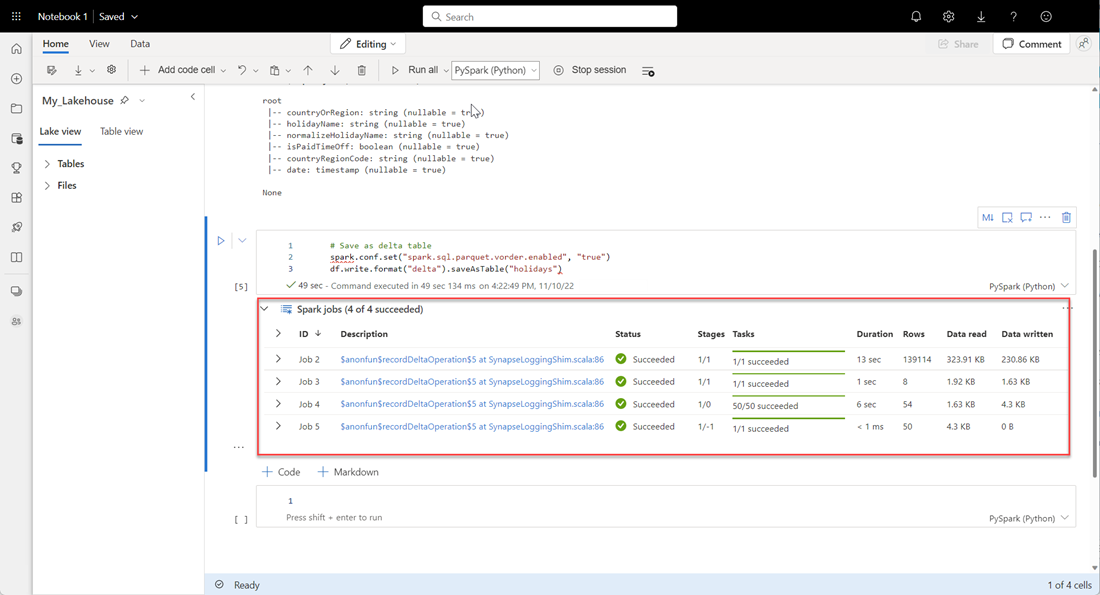
Pour vérifier qu’une table a bien été créée, dans la zone supérieure gauche, après Tables, sélectionnez les points de suspension (...), ensuite Actualiser et développez le nœud Tables.
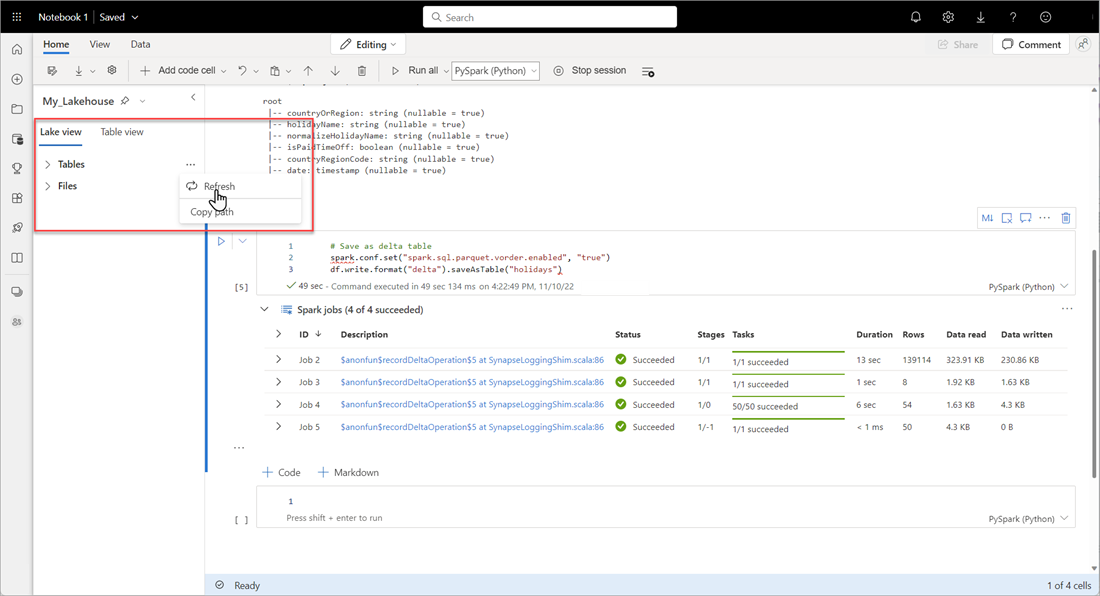
Au moyen de la méthode employée ci-dessus ou d’autres méthodes prises en charge, ajoutez d’autres tables Delta aux données que vous souhaitez analyser.
Créer un modèle Direct Lake de base pour votre lakehouse
Dans votre lakehouse, sélectionnez Nouveau modèle sémantique, puis dans la boîte de dialogue, sélectionnez les tables à inclure.
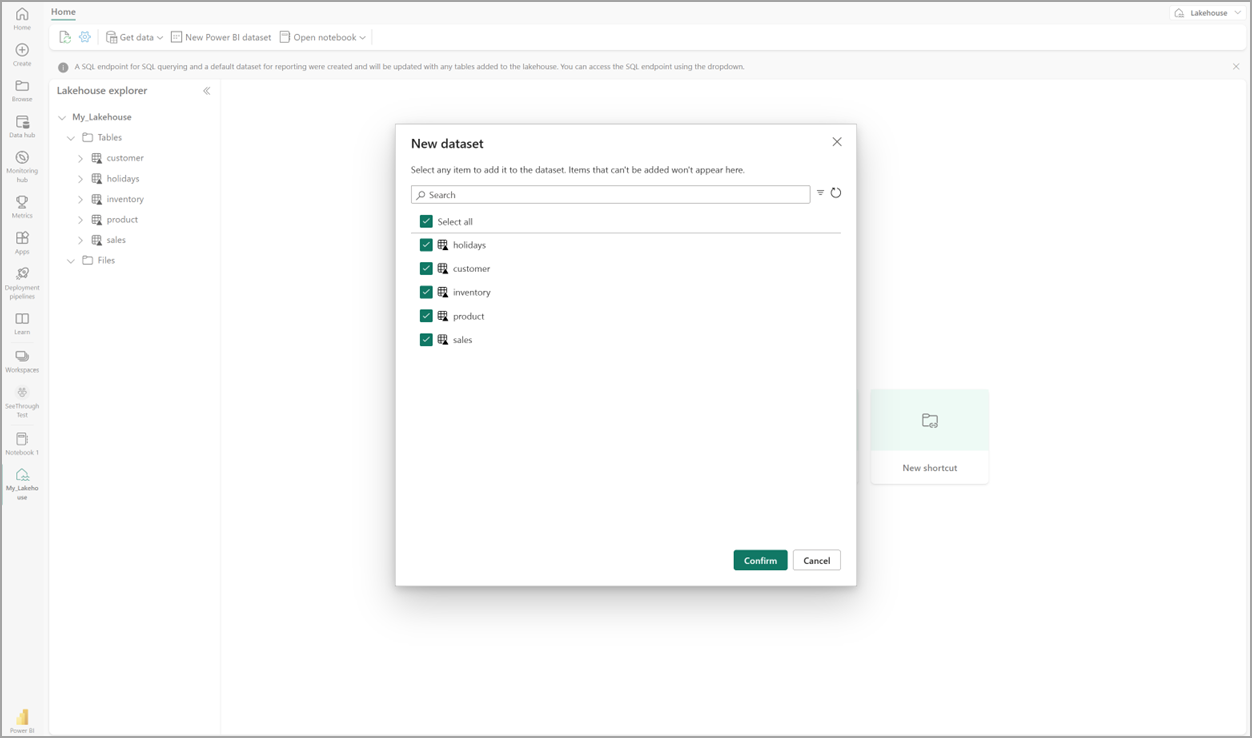
Sélectionnez Confirmer pour générer le modèle Direct Lake. Le modèle est automatiquement enregistré dans l’espace de travail, en fonction du nom de votre lakehouse, puis ouvre le modèle.
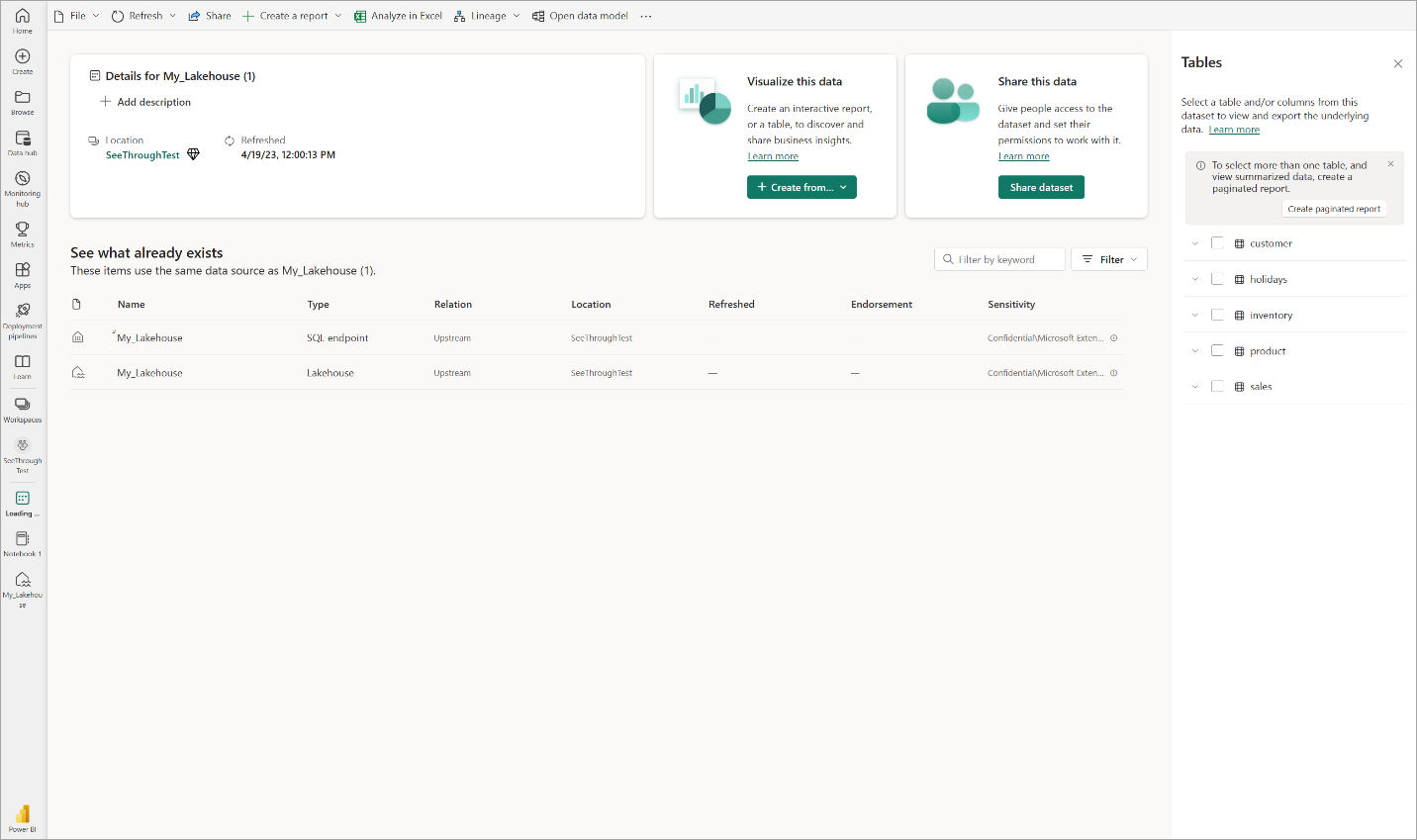
Sélectionnez Ouvrir le modèle de données pour ouvrir l’expérience de modélisation Web dans laquelle vous pouvez ajouter des relations de table et des mesures DAX.
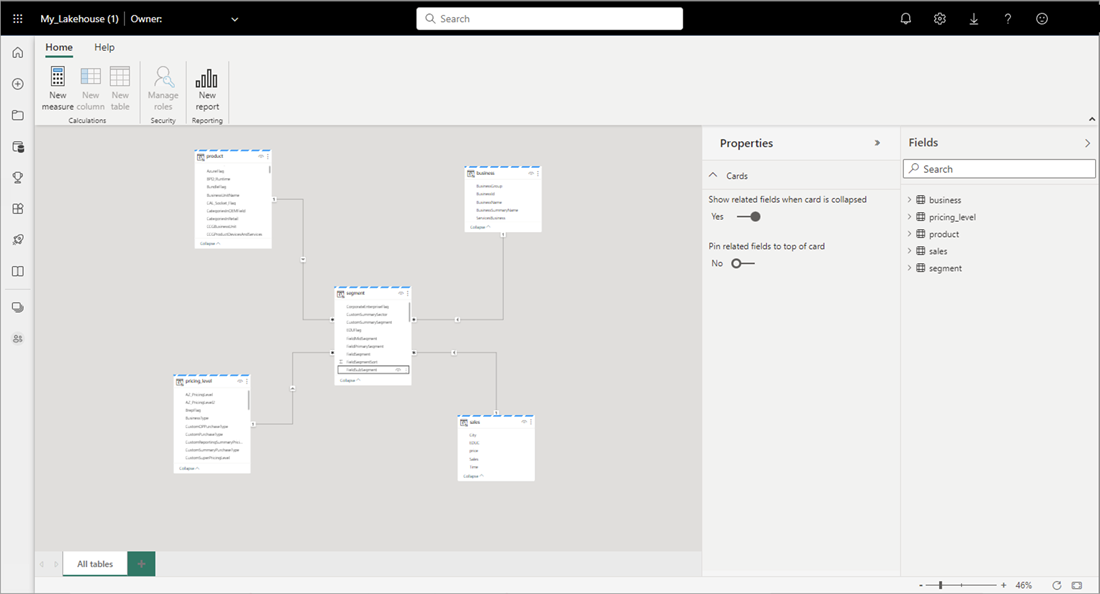
Une fois l’ajout des relations et des mesures DAX terminé, vous pouvez créer des rapports, créer un modèle composite et interroger le modèle par des points de terminaison XMLA de la même manière que n’importe quel autre modèle.
Contenu connexe
Commentaires
Bientôt disponible : Tout au long de 2024, nous allons supprimer progressivement GitHub Issues comme mécanisme de commentaires pour le contenu et le remplacer par un nouveau système de commentaires. Pour plus d’informations, consultez https://aka.ms/ContentUserFeedback.
Envoyer et afficher des commentaires pour