Intégrer OneLake à Azure HDInsight
Azure HDInsight est un service géré basé sur le cloud pour l’analytique données volumineuses qui aide les organisations à traiter de grandes quantités de données. Ce didacticiel montre comment se connecter à OneLake avec un notebook Jupyter à partir d'un cluster Azure HDInsight.
Utilisation d'Azure HDInsight
Pour vous connecter à OneLake avec un notebook Jupyter à partir d'un cluster HDInsight :
Créez un cluster Apache Spark HDInsight (HDI). Suivez ces instructions : Configurez des clusters dans HDInsight.
En fournissant des informations sur le cluster, souvenez-vous de votre nom d’utilisateur et de votre mot de passe de connexion au cluster, car vous en aurez besoin plus tard pour y accéder.
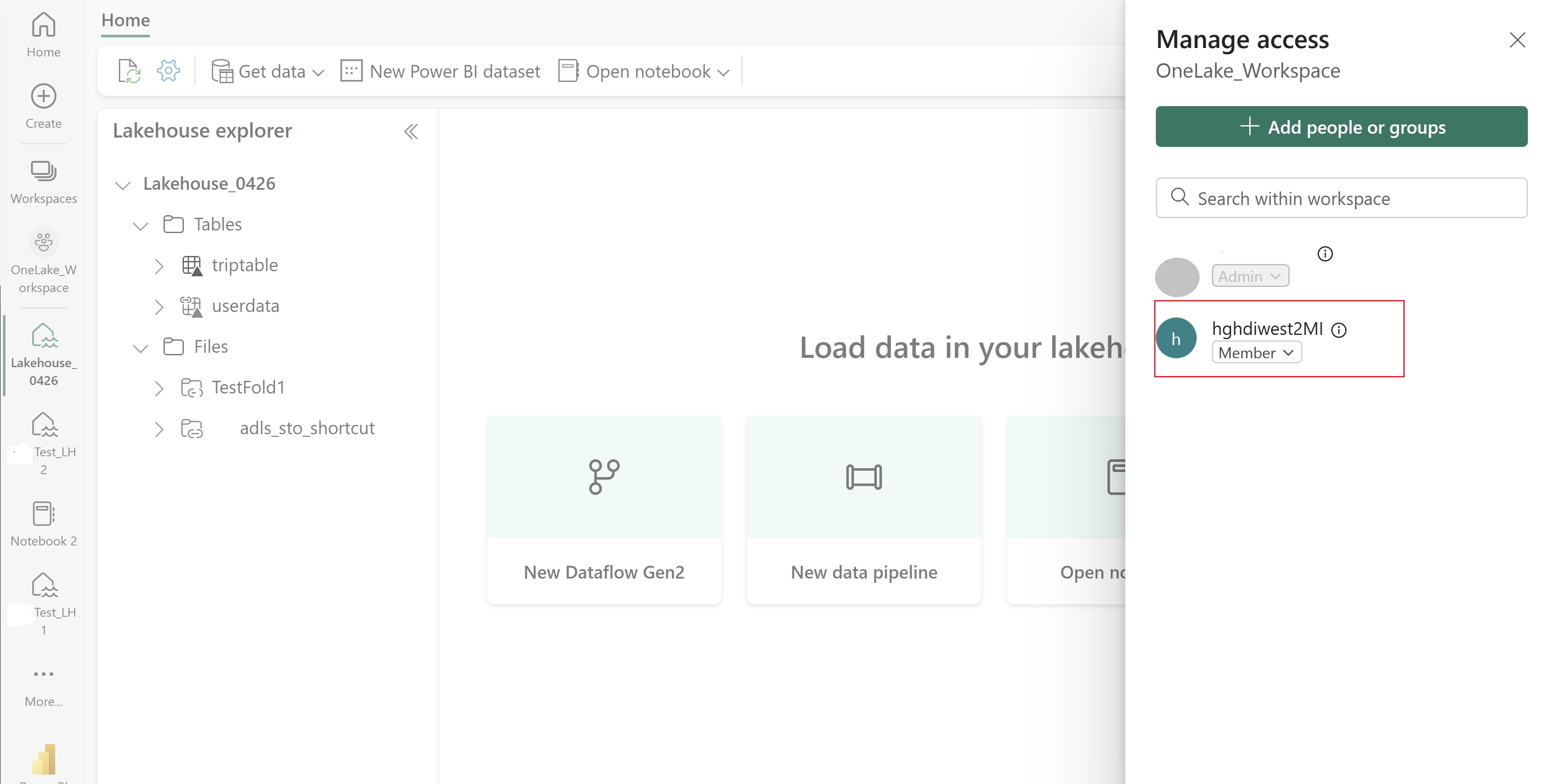
Créez une identité managée attribuée à l'utilisateur (UAMI) : Créez pour Azure HDInsight – UAMI et choisissez-la comme identité dans l'écran Stockage.

Accordez à cet UAMI l'accès à l'espace de travail Fabric qui contient vos éléments. Pour déterminer le rôle qui convient le mieux, consultez Rôles d’espaces de travail.
Accédez à votre lakehouse et trouvez-en le nom et celui de votre espace de travail. Vous pouvez les trouver dans l’URL de votre lakehouse ou dans le volet Propriétés d’un fichier.
Dans le Portail Microsoft Azure, recherchez votre cluster et sélectionnez le bloc-notes.

Entrez les informations d'identification que vous avez fournies lors de la création du cluster.

Créez un notebook Apache Spark.
Copiez les noms de l’espace de travail et du lakehouse dans votre notebook et créez l’URL OneLake pour votre lakehouse. Vous pouvez maintenant lire n'importe quel fichier à partir de ce chemin de fichier.
fp = 'abfss://' + 'Workspace Name' + '@onelake.dfs.fabric.microsoft.com/' + 'Lakehouse Name' + '/Files/' df = spark.read.format("csv").option("header", "true").load(fp + "test1.csv") df.show()Essayez d’écrire des données dans le lakehouse.
writecsvdf = df.write.format("csv").save(fp + "out.csv")Testez que vos données ont été écrites avec succès en vérifiant votre lakehouse ou en lisant votre fichier nouvellement chargé.




Vous pouvez désormais lire et écrire des données dans OneLake à l'aide de votre notebook Jupyter dans un cluster HDI Spark.