Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Cet article décrit un modèle d’intégration Microsoft Graph courant pour un scénario métier qui nécessite une analyse complexe des données de collaboration d’entreprise pour améliorer les processus métier et la productivité.
Ce scénario s’appuie sur une grande quantité de données Microsoft 365 extraites et a les exigences suivantes :
- Type d’intégration de données.
- Flux de données sortants des limites Microsoft 365 vers l’application.
- Volume élevé de données couvrant plusieurs mois.
- Latence des données relativement élevée ; l’extraction de données initiale peut inclure des messages datant jusqu’à un an.
La meilleure option pour ce scénario consiste à utiliser Microsoft Graph Data Connect. Le client doit configurer un stockage de données haute capacité tel qu’Azure Data Lake ou Azure Synapse, activer un abonnement Azure et configurer un pipeline Azure Data Factory ou Azure Synapse.
Le diagramme suivant illustre l’architecture de cette solution.
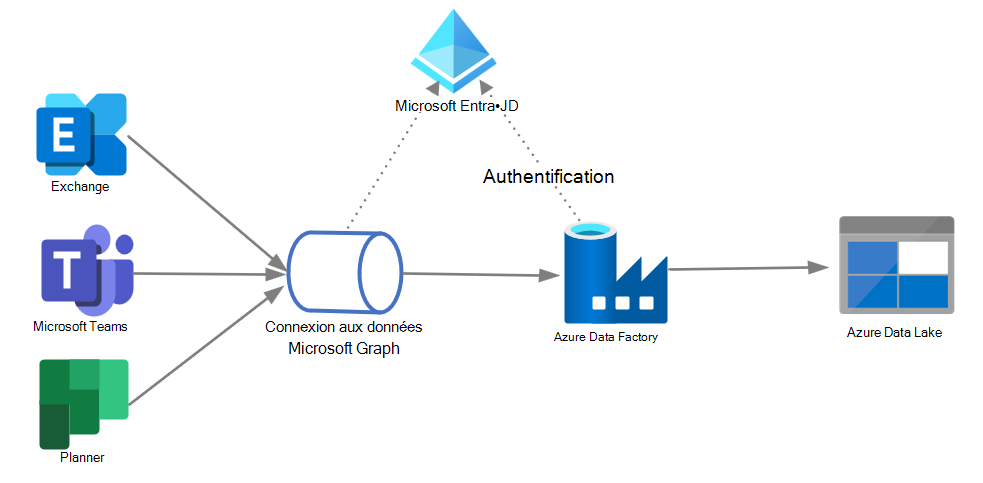
Composants de la solution
L’architecture de la solution comprend les composants suivants :
- Microsoft Graph Data Connect, qui permet l’extraction de données Microsoft 365 à grande échelle avec un consentement granulaire des données, et prend en charge toutes les fonctionnalités de service natives Azure telles que le chiffrement, la géo-isolation, l’audit et l’application de stratégies.
- Azure Data Factory (ADF), qui permet de construire facilement les processus ETL (extraire, transformer et charger) et ELT (extraire, charger et transformer) sans code dans un environnement intuitif, ou d’écrire votre code.
- Azure Data Lake, qui vous permet de conserver de grandes quantités de données structurées et non structurées dans différents formats.
- Microsoft Entra ID, qui est nécessaire pour gérer l’authentification pour les API Microsoft Graph et prend en charge les autorisations déléguées et d’application pour activer le flux OAuth.
Considérations
Les considérations suivantes prennent en charge l’utilisation de ce modèle d’intégration :
Disponibilité : L’ADF client peut extraire des données en bloc selon leur planification ou sur une base ad hoc.
Latence : dans ce scénario, la latence des données peut varier en fonction de l’extraction des données historiques ou de la livraison de données plus récentes au stockage Microsoft Graph Data Connect par des processus asynchrones effectués en tant que tâches planifiées. Les performances de l’extraction de données volumineuses ADF sont plus rapides que les API HTTP granulaires, car ADF utilise le traitement par lot et le transfert de fichiers.
Scalabilité : cette architecture vous permet de développer des pipelines qui optimisent le débit de déplacement des données pour votre environnement. Ces pipelines peuvent utiliser entièrement les ressources suivantes :
- Bande passante réseau entre les magasins de données source et de destination.
- Opérations d’entrée/sortie de magasin de données source ou de destination par seconde (IOPS) et bande passante.
Complexité de la solution : cette solution de sortie de données est d’une faible complexité du point de vue de l’intégration, car elle ne nécessite pas de code personnalisé, a peu de composants et est tolérante à la latence des données.