Étendre Smart Store Analytics
Les utilisateurs avancés de Smart Store Analytics peuvent accéder aux données et analyses pertinentes à partir de leur propre stockage de lac de données. L’accès peut se faire via tout autre service ou application prenant en charge Microsoft Azure Data Lake Storage et la définition du modèle de données commun, par exemple, Microsoft Azure Synapse Analytics, Microsoft Azure Data Factory ou Microsoft Power BI.
Important
Vous devez utiliser Microsoft Azure Data Lake Storage Gen2 puisque Microsoft Azure Data Lake Storage Gen1 sera incompatible.
Le modèle de données Smart Store Analytics est conforme aux modèles de base de données Azure Synapse pour la vente au détail, est amélioré avec les spécificités de Smart Store Analytics et simplifie la connexion d’autres applications aux données du lac.
Structure du lac de données Smart Store Analytics
Le lac de données Smart Store Analytics suit la définition Common Data Model (métadonnées de Common Data Model).
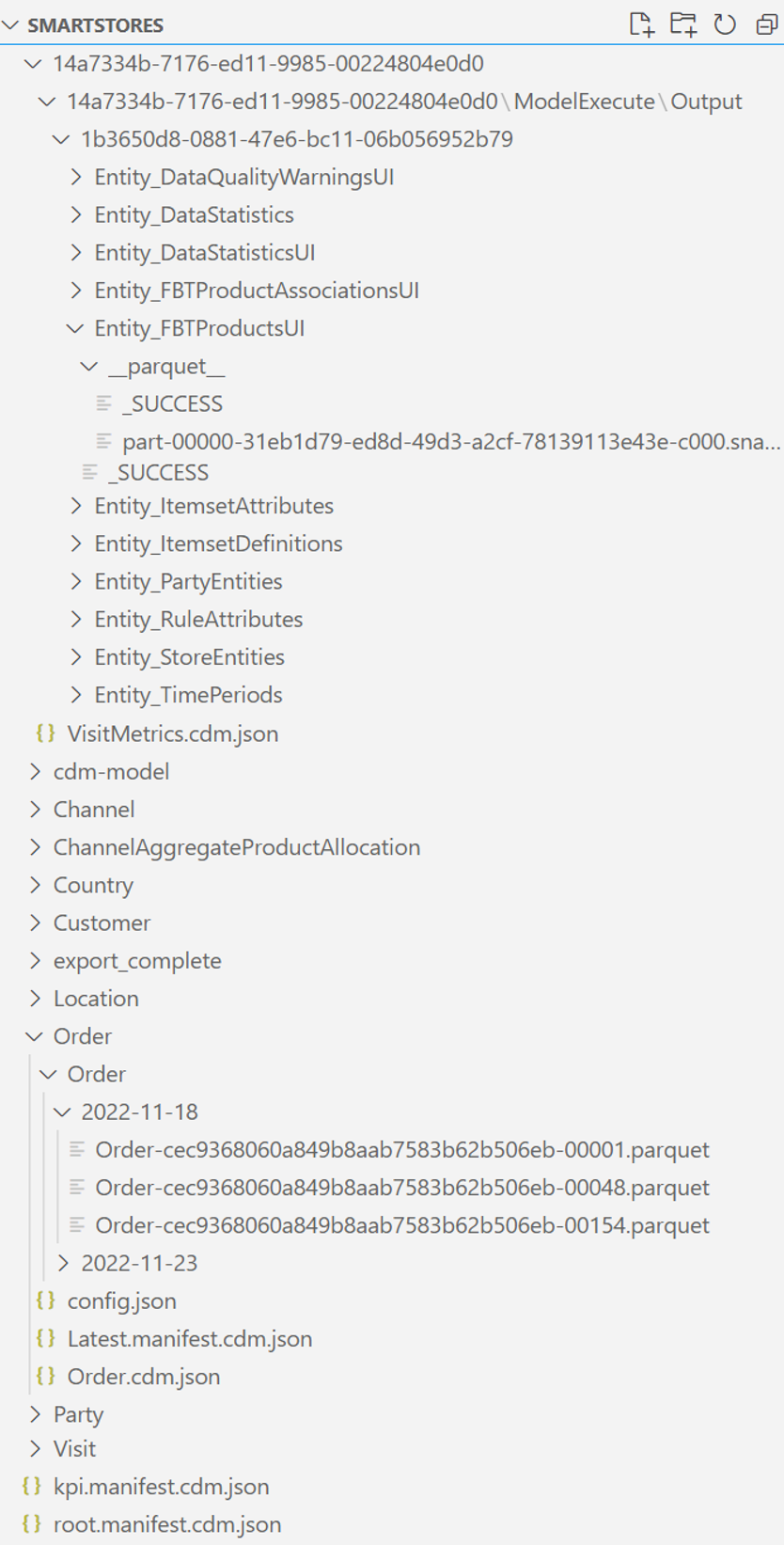
Le dossier racine est nommé smartstores/. Sous le dossier racine, il y a deux instantanés de données :
Données transformées à partir du fournisseur du magasin intelligent (données brutes du magasin intelligent)
Le manifeste Common Data Model racine pour les données brutes est root.manifest.cdm.json. Le fichier de manifeste fait référence aux fichiers de schéma et aux fichiers de données réels situés dans les sous-dossiers (nommés d’après les tables), par exemple, smartstores/Order/.
Le sous-dossier de chaque table contient :
un fichier de schéma, qui définit les métadonnées, les colonnes et les types de table, au format table-name.cdm.json, par exemple les fichiers de données Order.cdm.json,
également appelés partitions de données ou enregistrements de table, au format parquet, par exemple Order-cec9368060a849b8aab7583b62b506eb-00001.parquet
Données générées par les modules d’analytique de la vente au détail et d’IA à partir des données brutes des magasins intelligents
Toutes les données générées se trouvent dans un dossier nommé GUID, par exemple, smartstores/14a7334b-7176-ed11-9985-00224804e0d0/. Le manifeste Common Data Model racine pour ces données est kpi.manifest.cdm.json. Le fichier de manifeste fait référence aux fichiers de schéma et aux fichiers de données réels situés dans le dossier nommé GUID.
Le dossier nommé GUID contient :
Un fichier de schéma pour chaque table, qui définit les métadonnées, les colonnes et les types de table, au format table-name.cdm.json, par exemple les fichiers de données OrderMetrics.cdm.json,
également appelés partitions de données ou enregistrements de table, au format parquet, par exemple part-00000-1e110bf0-6474-400b-b40a-086fce9f8e2a-c000.snappy.parquet
Important
Selon le contrat de métadonnées Common Data Model, les utilisateurs ont besoin de données provenant uniquement des fichiers manifest.cdm.json. Ils n’ont pas besoin d’interpréter la structure des dossiers ou d’autres fichiers internes présents dans le lac de données.
Utilisation du lac de données Smart Store Analytics
Voici quelques exemples de données synchronisées dans des informations analytiques/AI Insights par Microsoft Cloud for Retail.
Pipeline de données avec Microsoft Azure Data Factory
Pour créer un pipeline de données :
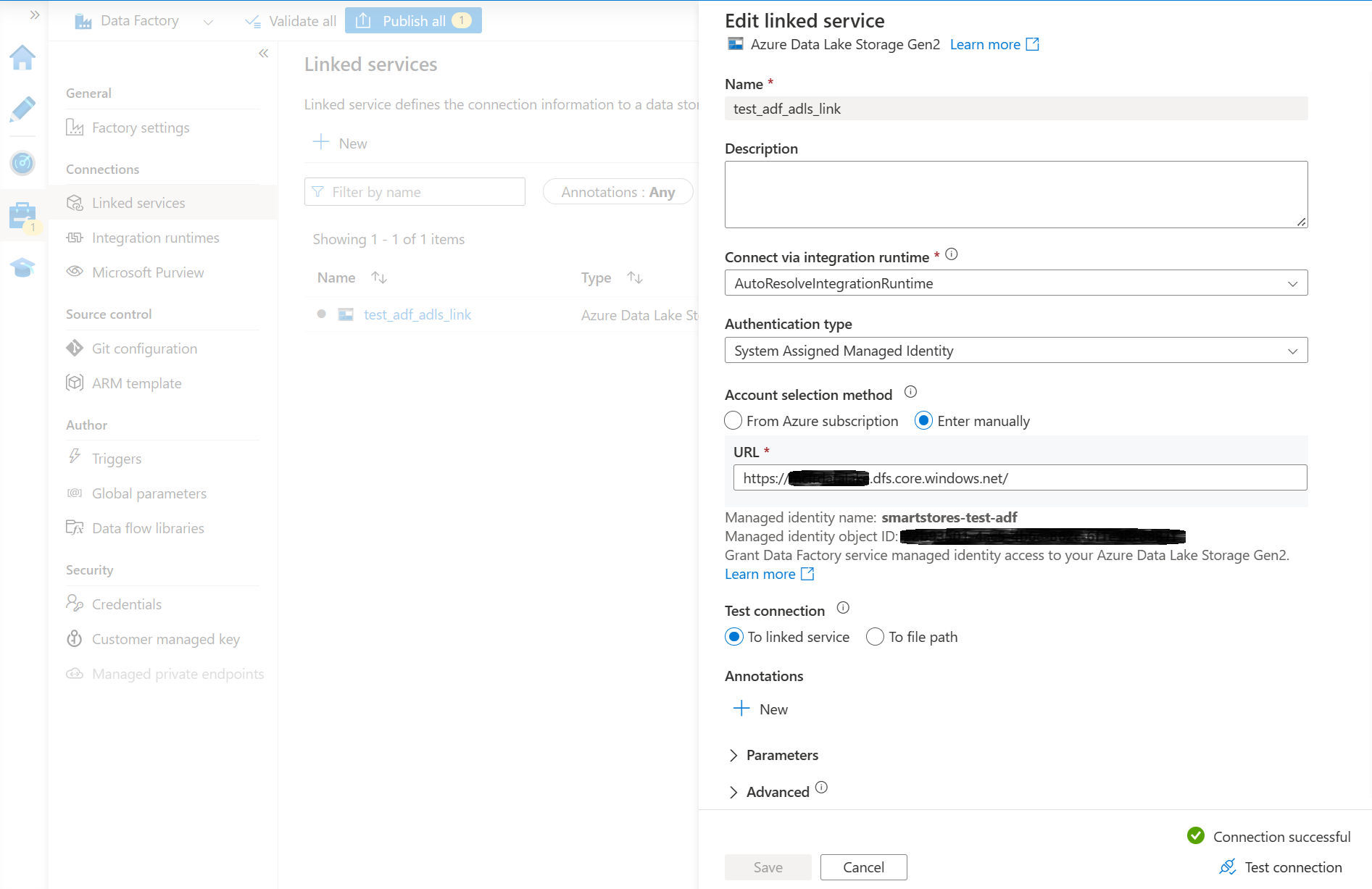
- Créez une instance d’Azure Data Factory et liez-la au stockage du lac de données Smart Store Analytics. Vous devriez avoir un service lié avec un test de connexion réussi.
Note
Le moyen le plus simple de connecter une instance d’Azure Data Factory à Azure Data Lake Storage est d’affecter un rôle de collaborateur à une identité managée Azure Data Factory dans le compte Azure Data Lake Storage. Pour des détails, voir la documentation Azure Data Factory.
- Sélectionnez Publier tout pour publier le nouveau lien.
Créer un pipeline de données avec Microsoft Azure Data Factory
Pour créer un pipeline de copie pour le dossier smartstores/ en tant que source, procédez comme suit :
- Dans la section Auteur, sélectionnez Nouveau flux de données pour créer un flux de données.
- Démarrez le débogage pour une vérification plus rapide de la configuration du pipeline.
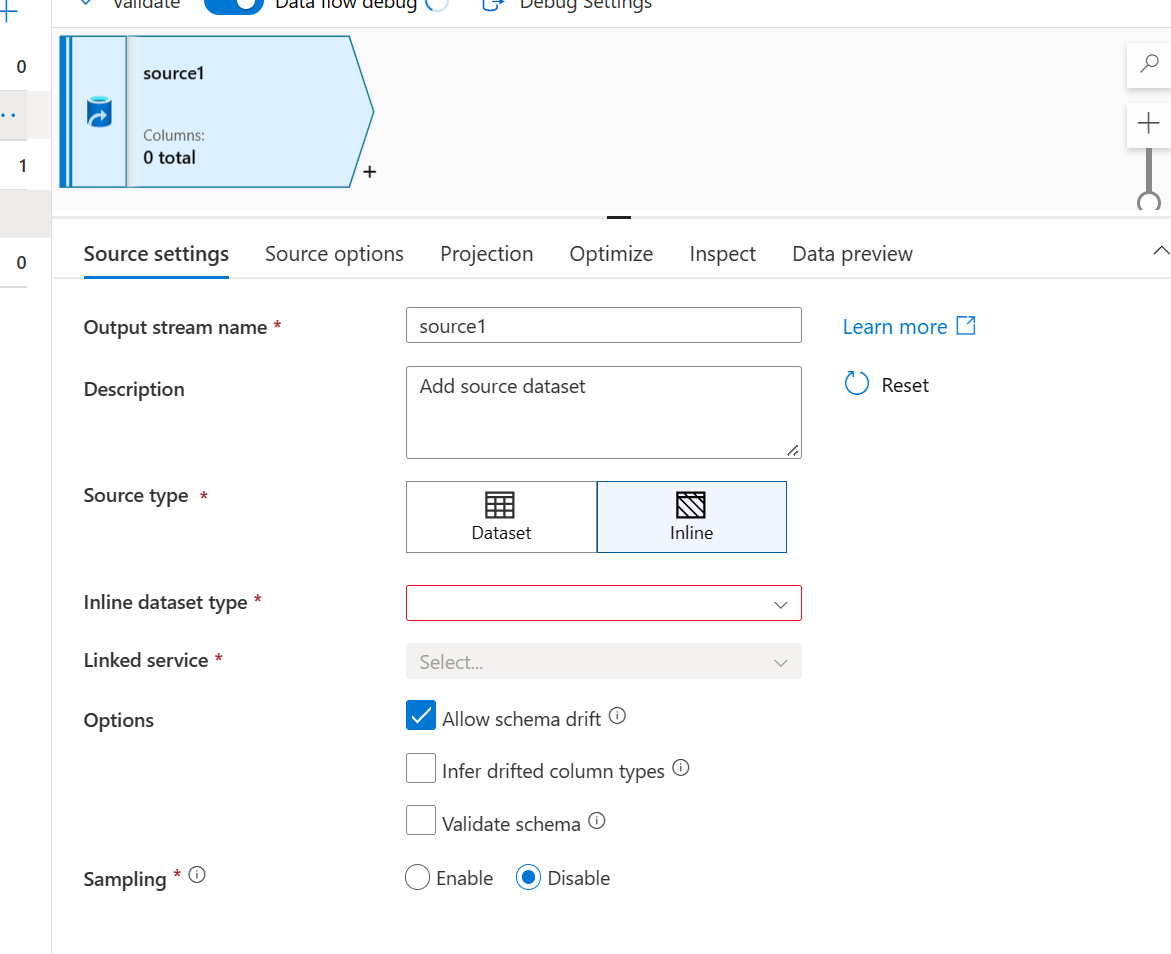
- Configurez les paramètres sources comme suit :
- Pour le type de source, sélectionnez En ligne
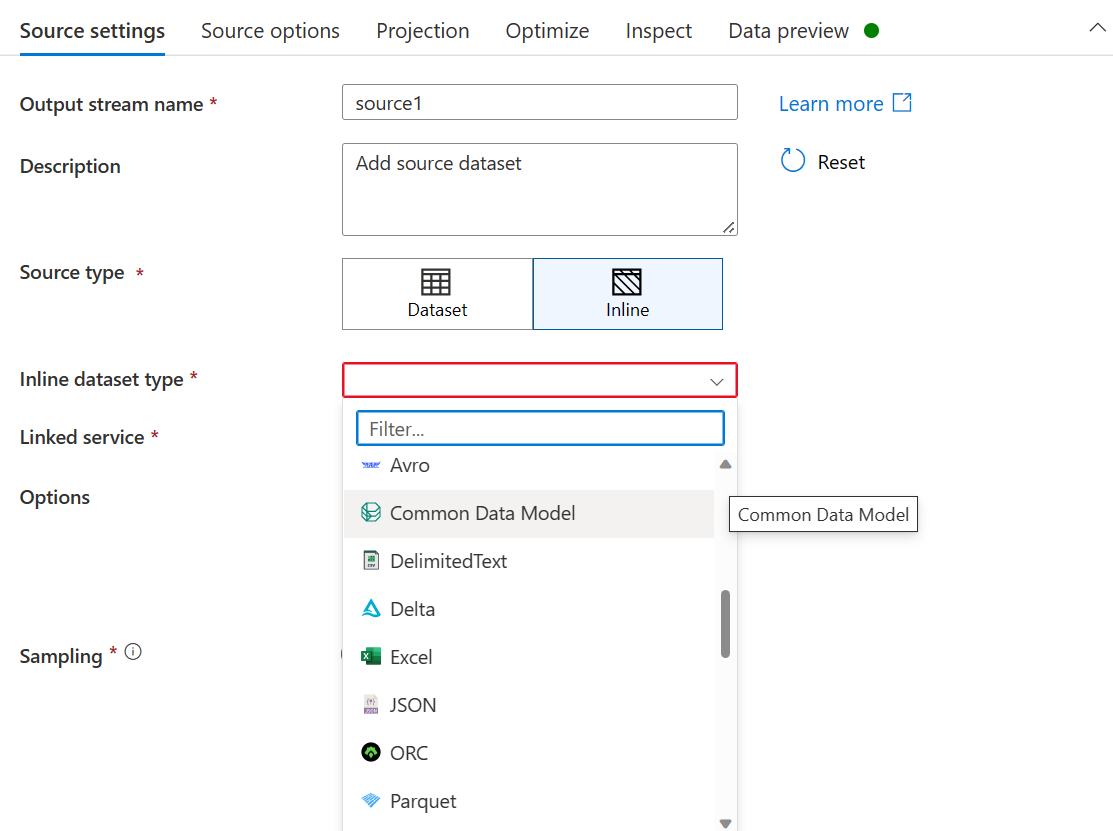
- Pour le type de jeu de données en ligne, sélectionnez Common Data Model
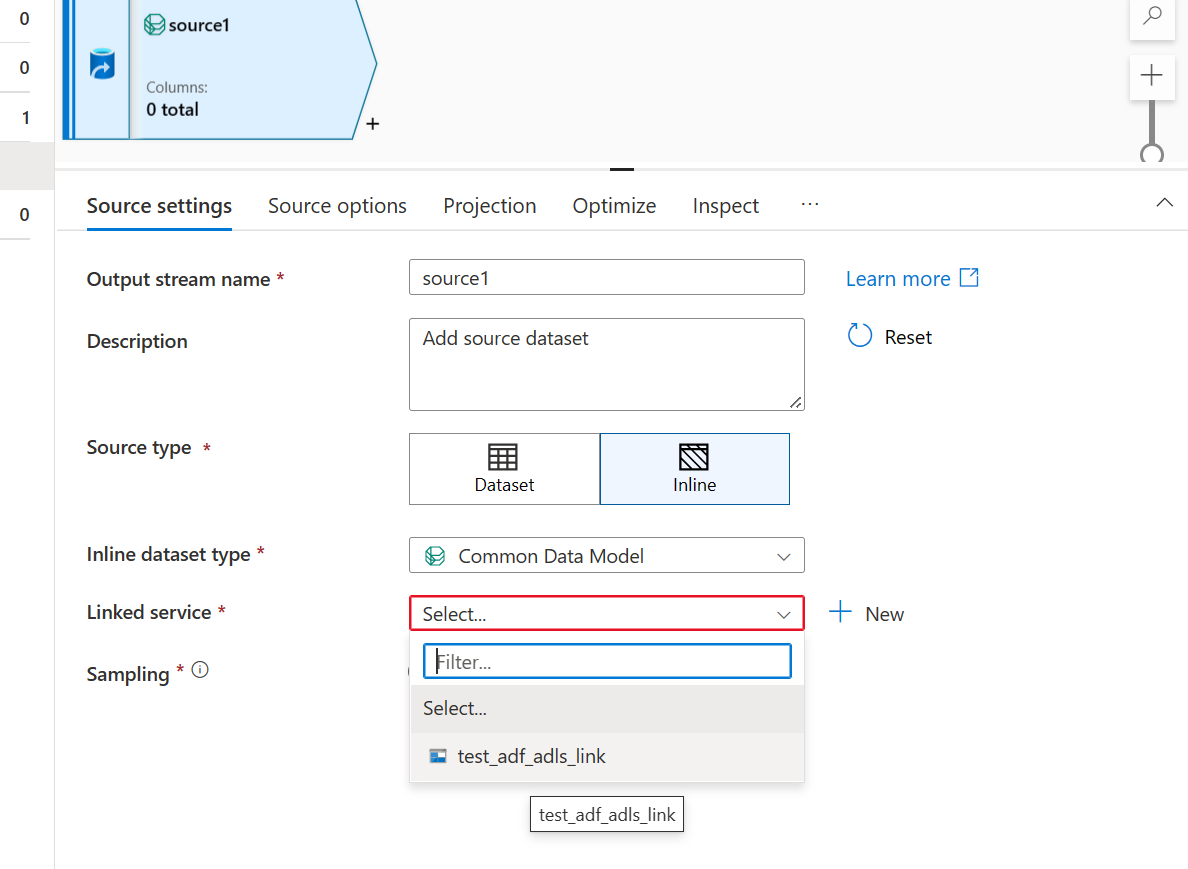
- Utilisez le lien Azure Data Lake Storage créé pour le lac de données Smart Stores.
- Dans la section Options sources, configurez la source du schéma Common Data Model comme suit :
- Sélectionnez Manifeste comme format des métadonnées.
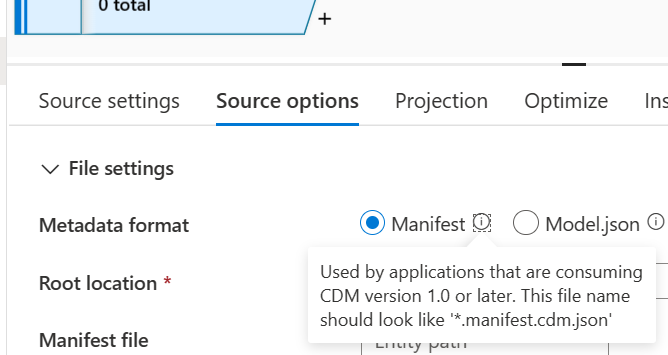
Dans l’emplacement racine, parcourez et sélectionnez le dossier smartstores.
Dans la section Fichier manifeste, parcourez pour sélectionner le manifeste racine requis. Sélectionnez le fichier racine pour les données analytiques et AI Insights, kpi.manifest.cdm.json.
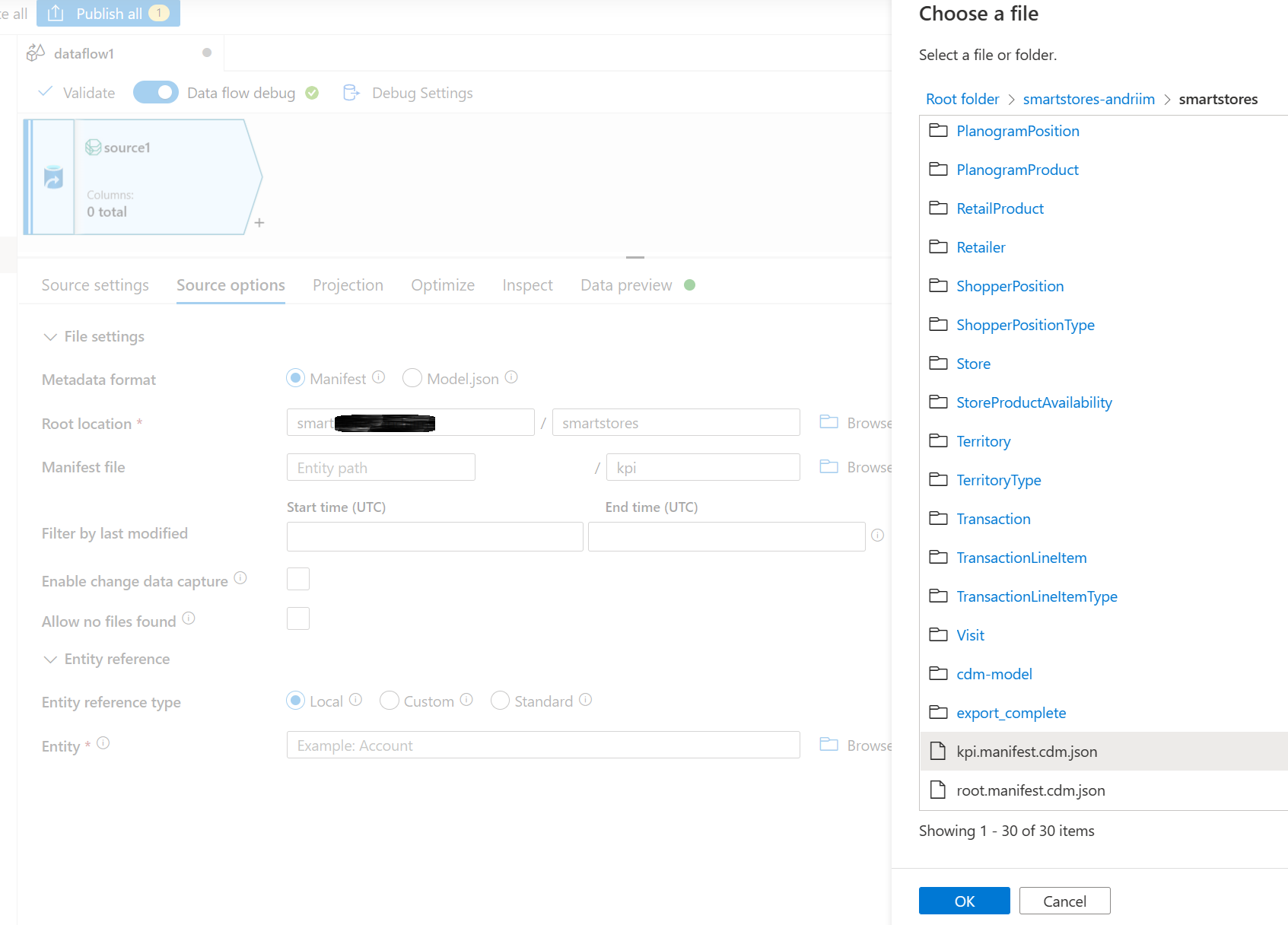
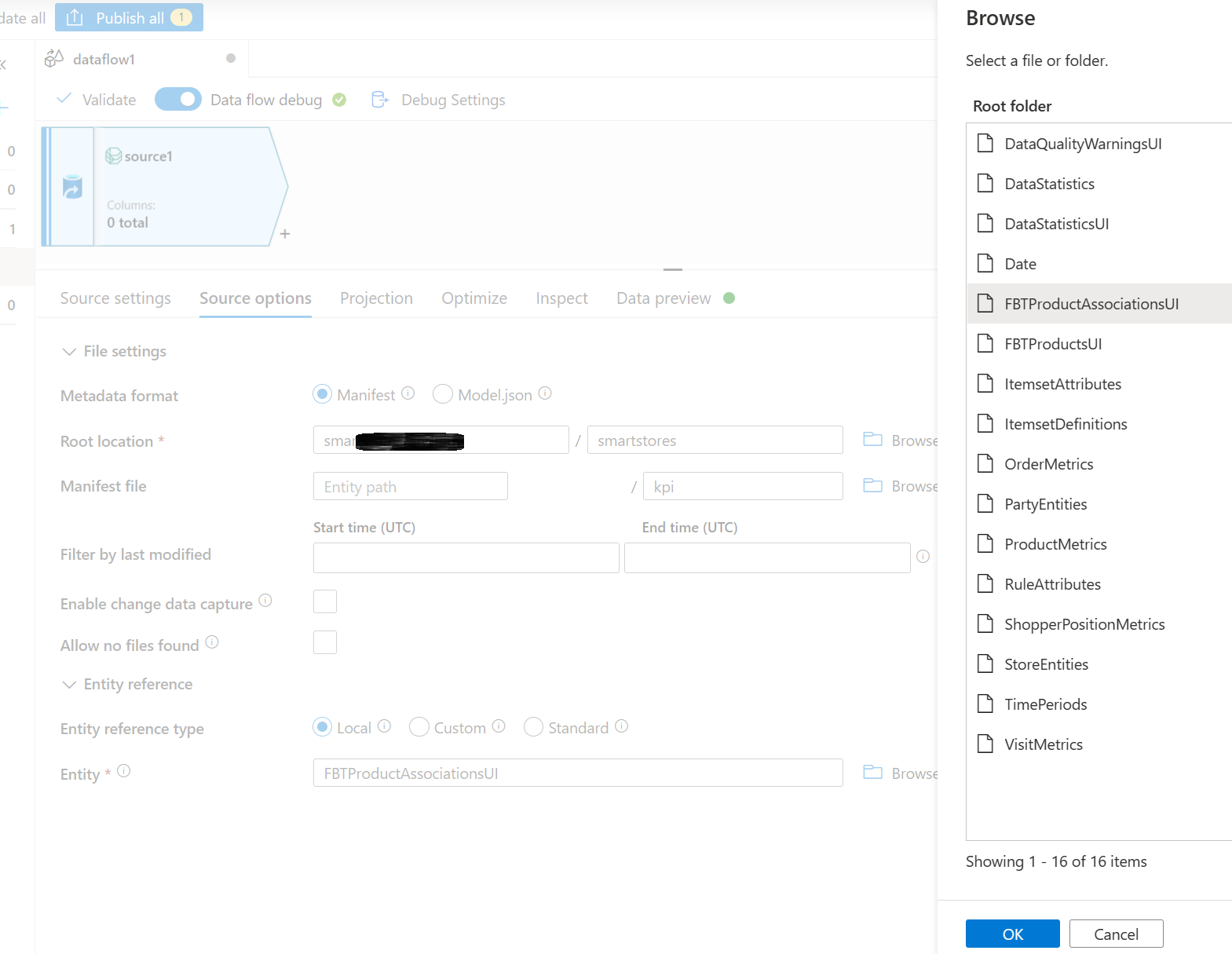
Dans la section Entité, sélectionnez l’entité (table) que vous devez copier/transformer, par exemple, FBTProductAssociationsUI du forfait Fréquemment achetés ensemble.
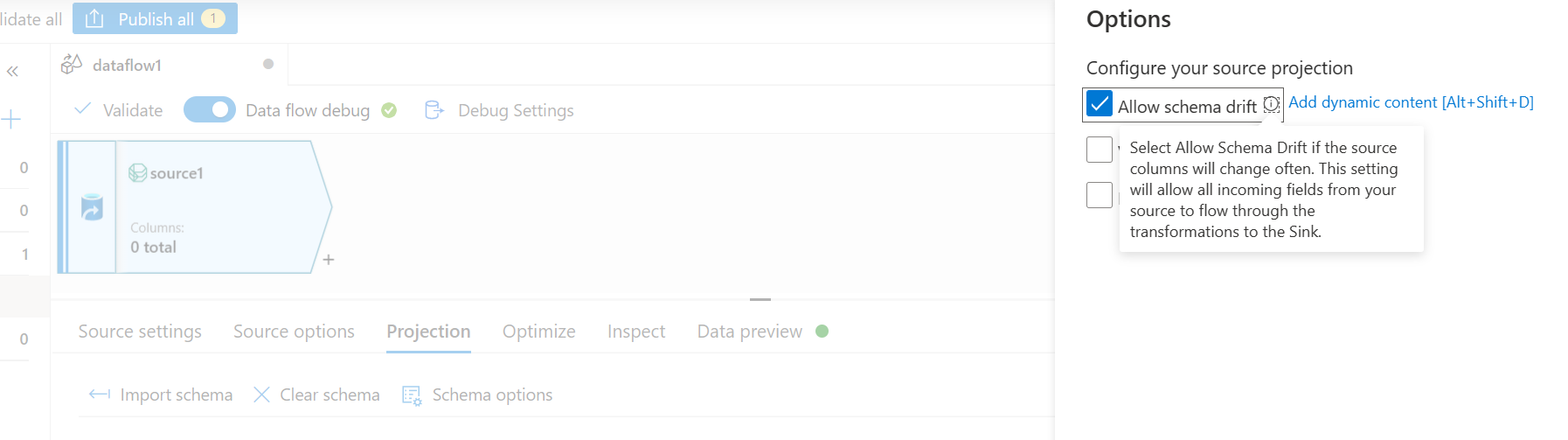
- Dans l’onglet Projection, sélectionnez Autoriser la dérive de schéma. Cette sélection garantira que le schéma ne sera pas validé à la source mais dérivera vers d’autres étapes de transformation/récepteur.
- Dans l’onglet Aperçu des données, sélectionnez Recharger pour valider la configuration source de données.
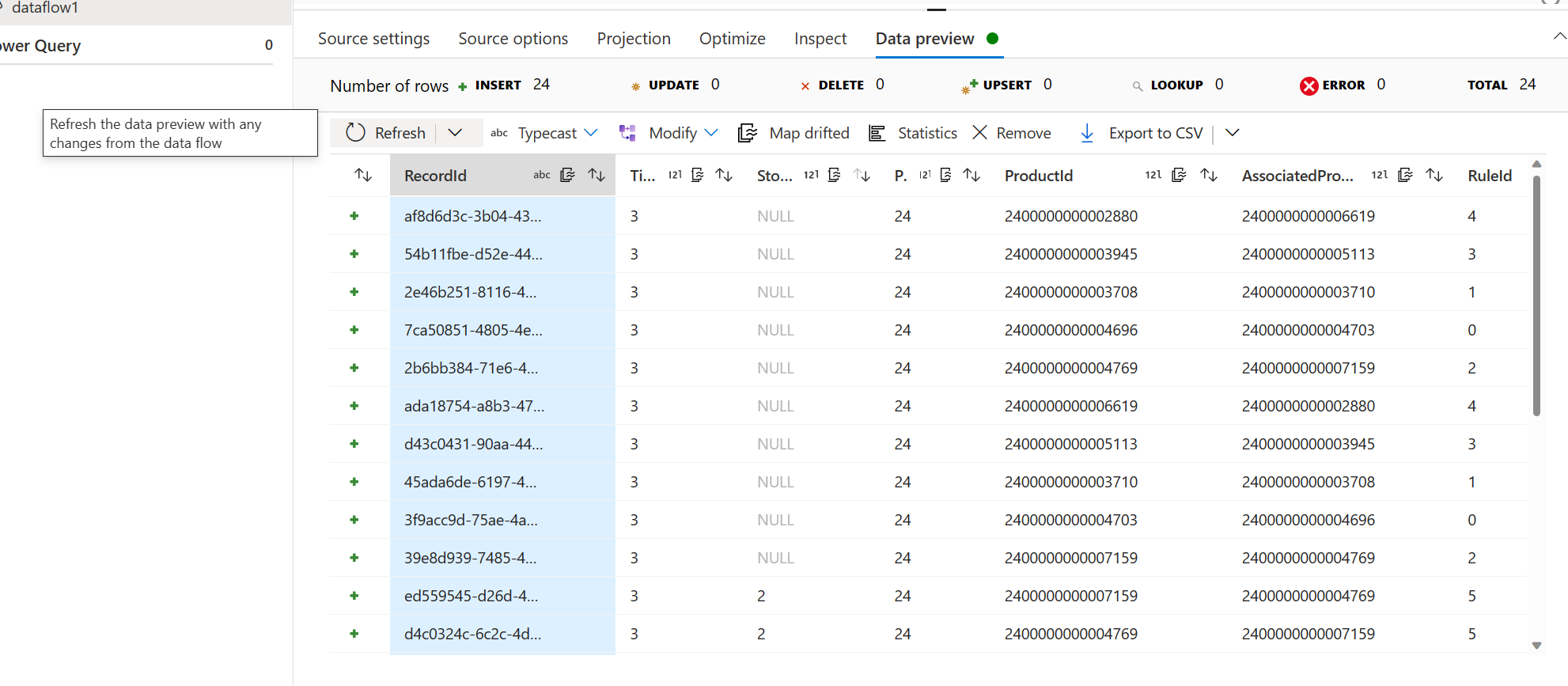
Ajouter une étape de récepteur – définissez les paramètres et le mappage des données selon les besoins de votre scénario.
Sélectionnez Publier pour publier les modifications.