Notes
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
S’applique à : ✅Microsoft Fabric✅Azure Data Explorer
Le bag_unpack plug-in décompresse une seule colonne de type dynamic, en traitant chaque emplacement de niveau supérieur du conteneur de propriétés comme une colonne. Le plug-in est appelé avec l’opérateur evaluate .
Syntaxe
T|evaluatebag_unpack( Column [,OutputColumnPrefix ] [,columnsConflict ] [,ignoredProperties ] ) [:OutputSchema]
En savoir plus sur les conventions de syntaxe.
Paramètres
| Nom | Catégorie | Requise | Descriptif |
|---|---|---|---|
| T | string |
✔️ | Entrée tabulaire dont la colonne doit être décompressée. |
| Colonne | dynamic |
✔️ | Colonne de T à décompresser. |
| OutputColumnPrefix | string |
Préfixe courant à ajouter à toutes les colonnes produites par le plug-in. | |
| columnsConflict | string |
Direction de la résolution des conflits de colonne. Valeurs valides : error - La requête génère une erreur (par défaut)replace_source - La colonne source est remplacéekeep_source - La colonne source est conservée |
|
| ignoredProperties | dynamic |
Ensemble facultatif de propriétés de conteneur à ignorer. } | |
| OutputSchema | Spécifiez les noms et les types de colonnes pour la sortie du bag_unpack plug-in. Pour plus d’informations sur la syntaxe, consultez la syntaxe du schéma de sortie et pour comprendre les implications, consultez considérations relatives aux performances. |
Syntaxe de schéma de sortie
(
ColumnName:ColumnType [, ...])
Utilisez un caractère générique * comme premier paramètre pour inclure toutes les colonnes de la table source dans la sortie, comme suit :
(
*
,
ColumnName:ColumnType [, ...])
Considérations relatives aux performances
L’utilisation du plug-in sans OutputSchema peut avoir des conséquences graves sur les performances dans les jeux de données volumineux et doit être évitée.
Fournir un OutputSchema permet au moteur de requête d’optimiser l’exécution de la requête, car il peut déterminer le schéma de sortie sans avoir à analyser et analyser les données d’entrée. Cela est bénéfique lorsque les données d’entrée sont volumineuses ou complexes. Consultez les exemples avec des implications en matière de performances d’utilisation du plug-in avec et sans OutputSchema défini.
Retours
Le bag_unpack plug-in retourne une table avec autant d’enregistrements que son entrée tabulaire (T). Le schéma de la table est identique au schéma de son entrée tabulaire avec les modifications suivantes :
- La colonne d’entrée spécifiée (colonne) est supprimée.
- Le nom de chaque colonne correspond au nom de chaque emplacement, éventuellement préfixé par OutputColumnPrefix.
- Le type de chaque colonne est soit le type de l’emplacement, si toutes les valeurs du même emplacement ont le même type, soit
dynamicsi les valeurs diffèrent dans le type. - Le schéma est étendu avec autant de colonnes qu’il existe des emplacements distincts dans les valeurs de conteneur de propriétés de niveau supérieur de T.
Remarque
- Si vous ne spécifiez pas OutputSchema, le schéma de sortie du plug-in varie en fonction des valeurs de données d’entrée. Plusieurs exécutions du plug-in avec différentes entrées de données peuvent produire différents schémas de sortie.
- Si un OutputSchema est spécifié, le plug-in retourne uniquement les colonnes définies dans la syntaxe du schéma de sortie, sauf si un caractère générique
*est utilisé. - Pour retourner toutes les colonnes des données d’entrée et les colonnes définies dans OutputSchema, utilisez un caractère générique
*dans OutputSchema.
Les règles de schéma tabulaire s’appliquent aux données d’entrée. En particulier :
- Un nom de colonne de sortie ne peut pas être identique à une colonne existante dans l’entrée tabulaire T, sauf s’il s’agit de la colonne à décompresser (colonne). Sinon, la sortie comprend deux colonnes portant le même nom.
- Tous les noms d’emplacements, lorsqu’ils sont préfixés par OutputColumnPrefix, doivent être des noms d’entité valides et suivre les règles d’affectation de noms d’identificateur.
Le plug-in ignore les valeurs Null.
Exemples
Les exemples de cette section montrent comment utiliser la syntaxe pour vous aider à commencer.
Développez un sac :
datatable(d:dynamic)
[
dynamic({"Name": "John", "Age":20}),
dynamic({"Name": "Dave", "Age":40}),
dynamic({"Name": "Jasmine", "Age":30}),
]
| evaluate bag_unpack(d)
Sortie
| Âge | Nom |
|---|---|
| 20 | John |
| 40 | Dave |
| 30 | Jasmin |
Développez un conteneur et utilisez l’option OutputColumnPrefix pour produire des noms de colonnes avec un préfixe :
datatable(d:dynamic)
[
dynamic({"Name": "John", "Age":20}),
dynamic({"Name": "Dave", "Age":40}),
dynamic({"Name": "Jasmine", "Age":30}),
]
| evaluate bag_unpack(d, 'Property_')
Sortie
| Property_Age | Property_Name |
|---|---|
| 20 | John |
| 40 | Dave |
| 30 | Jasmin |
Développez un conteneur et utilisez l’option columnsConflict pour résoudre un conflit de colonne entre la colonne dynamique et la colonne existante :
datatable(Name:string, d:dynamic)
[
'Old_name', dynamic({"Name": "John", "Age":20}),
'Old_name', dynamic({"Name": "Dave", "Age":40}),
'Old_name', dynamic({"Name": "Jasmine", "Age":30}),
]
| evaluate bag_unpack(d, columnsConflict='replace_source') // Use new name
Sortie
| Âge | Nom |
|---|---|
| 20 | John |
| 40 | Dave |
| 30 | Jasmin |
datatable(Name:string, d:dynamic)
[
'Old_name', dynamic({"Name": "John", "Age":20}),
'Old_name', dynamic({"Name": "Dave", "Age":40}),
'Old_name', dynamic({"Name": "Jasmine", "Age":30}),
]
| evaluate bag_unpack(d, columnsConflict='keep_source') // Keep old name
Sortie
| Âge | Nom |
|---|---|
| 20 | Old_name |
| 40 | Old_name |
| 30 | Old_name |
Développez un conteneur et utilisez l’option ignoredProperties pour ignorer 2 des propriétés du conteneur de propriétés :
datatable(d:dynamic)
[
dynamic({"Name": "John", "Age":20, "Address": "Address-1" }),
dynamic({"Name": "Dave", "Age":40, "Address": "Address-2"}),
dynamic({"Name": "Jasmine", "Age":30, "Address": "Address-3"}),
]
// Ignore 'Age' and 'Address' properties
| evaluate bag_unpack(d, ignoredProperties=dynamic(['Address', 'Age']))
Sortie
| Nom |
|---|
| John |
| Dave |
| Jasmin |
Développez un conteneur et utilisez l’option OutputSchema :
datatable(d:dynamic)
[
dynamic({"Name": "John", "Age":20}),
dynamic({"Name": "Dave", "Age":40}),
dynamic({"Name": "Jasmine", "Age":30}),
]
| evaluate bag_unpack(d) : (Name:string, Age:long)
Sortie
| Nom | Âge |
|---|---|
| John | 20 |
| Dave | 40 |
| Jasmin | 30 |
Développez un conteneur avec un OutputSchema et utilisez l’option générique *:
Cette requête retourne la description de l’emplacement d’origine et les colonnes définies dans OutputSchema.
datatable(d:dynamic, Description: string)
[
dynamic({"Name": "John", "Age":20, "height":180}), "Student",
dynamic({"Name": "Dave", "Age":40, "height":160}), "Teacher",
dynamic({"Name": "Jasmine", "Age":30, "height":172}), "Student",
]
| evaluate bag_unpack(d) : (*, Name:string, Age:long)
Sortie
| Descriptif | Nom | Âge |
|---|---|---|
| Étudiant | John | 20 |
| Enseignant | Dave | 40 |
| Étudiant | Jasmin | 30 |
Exemples avec des implications sur les performances
Développez un conteneur avec et sans OutputSchema défini pour comparer les implications des performances :
Cet exemple utilise une table disponible publiquement dans le cluster d’aide. Dans la base de données ContosoSales , il existe une table appelée SalesDynamic. La table contient des données de ventes et inclut une colonne dynamique nommée Customer_Properties.
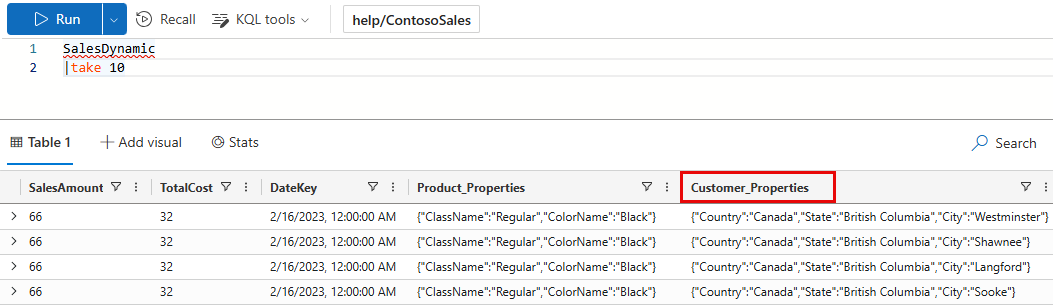
Exemple sans schéma de sortie : la première requête ne définit pas de OutputSchema. La requête prend 5,84 secondes de processeur et analyse 36,39 Mo de données.
SalesDynamic | evaluate bag_unpack(Customer_Properties) | summarize Sales=sum(SalesAmount) by Country, StateExemple avec le schéma de sortie : la deuxième requête fournit un OutputSchema. La requête prend 0,45 secondes de processeur et analyse 19,31 Mo de données. La requête n’a pas besoin d’analyser la table d’entrée, ce qui permet de gagner du temps de traitement.
SalesDynamic | evaluate bag_unpack(Customer_Properties) : (*, Country:string, State:string, City:string) | summarize Sales=sum(SalesAmount) by Country, State
Sortie
La sortie est la même pour les deux requêtes. Les 10 premières lignes de la sortie sont indiquées ci-dessous.
| Canada | Colombie-britannique | 56,101,083 |
|---|---|---|
| Royaume-Uni | Angleterre | 77,288,747 |
| Australie | Victoria | 31,242,423 |
| Australie | Queensland | 27,617,822 |
| Australie | Australie-Sud | 8,530,537 |
| Australie | Nouvelle-Galles du Sud | 54,765,786 |
| Australie | Tasmanie | 3,704,648 |
| Canada | Alberta | 375,061 |
| Canada | Ontario | 38,282 |
| États-Unis | Washington | 80,544,870 |
| ... | ... | ... |