Notes
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Cet article décrit le connecteur SQL générique. Cet article s’applique aux produits suivants :
- Microsoft Identity Manager 2016 (MIM2016)
- Microsoft Entra ID
Pour MIM2016, le connecteur est disponible en téléchargement à partir du Centre de téléchargement Microsoft.
Pour voir ce connecteur en action, consultez l’article Generic SQL Connector step-by-step .
Remarque
Microsoft Entra ID fournit désormais une solution basée sur un agent léger pour l’approvisionnement d’utilisateurs dans une base de données SQL, sans avoir besoin d’un déploiement de synchronisation MIM. Nous vous recommandons de l’utiliser pour l’approvisionnement d’utilisateurs sortants. Plus d’informations
Vue d’ensemble du connecteur SQL générique
Le connecteur SQL générique vous permet d’intégrer le service de synchronisation avec un système de base de données qui offre la connectivité ODBC.
Globalement, la version actuelle du connecteur prend en charge les fonctionnalités suivantes :
| Fonctionnalité | Support |
|---|---|
| Source de données connectée | Le connecteur est compatible avec tous les pilotes ODBC 64 bits*. Il a été testé avec les éléments suivants : |
| Scénarios | |
| Opérations | |
| schéma |
Prérequis
Avant d’utiliser le connecteur, vérifiez que vous disposez des éléments suivants sur le serveur de synchronisation :
- Microsoft .NET 4.6.2 Framework ou version ultérieure
- Pilotes clients ODBC 64 bits
- Si vous utilisez le connecteur pour communiquer avec Oracle 12c, cela nécessite Oracle Instant Client 12.2.0.1 ou une version ultérieure avec le package ODBC.
- Si vous utilisez le connecteur pour communiquer avec Oracle 18c-23c, cela nécessite Oracle Instant Client 18-23 ou une version ultérieure avec le package ODBC, et la variable système NLS_LANG doit être définie pour prendre en charge les caractères UTF8, par exemple NLS_LANG=AMERICAN_AMERICA. AL32UTF8.
- Ce connecteur utilise des instructions préparées SQL et plusieurs instructions par transaction. Certains systèmes SGBDR peuvent rencontrer des problèmes dans leurs pilotes ODBC liés à la gestion des transactions, aux instructions SQL préparées côté serveur et à plusieurs instructions au sein de la même transaction. Configurez vos options de connexion DSN en conséquence pour vous assurer que ces instructions sont correctement envoyées à votre base de données. Par exemple, MySQL ODBC Driver version 8.0.32 a besoin d’options NO_SSPS=1 et MULTI_STATEMENTS=1. D’autres options telles que « autocommit » ou « commit on successful operations only » peuvent affecter la façon dont les exportations par lots sont gérées ; consultez votre administrateur de base de données pour plus d’informations. Pour résoudre les problèmes lors de l’exportation, définissez la taille des lots d’exportation sur 1 et activez la journalisation détaillée du connecteur.
Le déploiement de ce connecteur peut nécessiter des modifications de la configuration de la base de données ainsi que des modifications de configuration apportées à MIM. Pour les déploiements impliquant l’intégration de MIM à un serveur de base de données tiers dans un environnement de production, nous recommandons aux clients de travailler avec leur fournisseur de base de données ou un partenaire de déploiement pour obtenir de l’aide, des conseils et une prise en charge de cette intégration.
Autorisations dans la source de données connectée
Pour créer ou exécuter les tâches prises en charge dans le connecteur SQL générique, vous devez disposer de :
- db_datareader
- db_datawriter
Ports et protocoles
Concernant les ports requis pour que le pilote ODBC fonctionne, veuillez consulter la documentation accompagnant la base de données.
Créer un connecteur
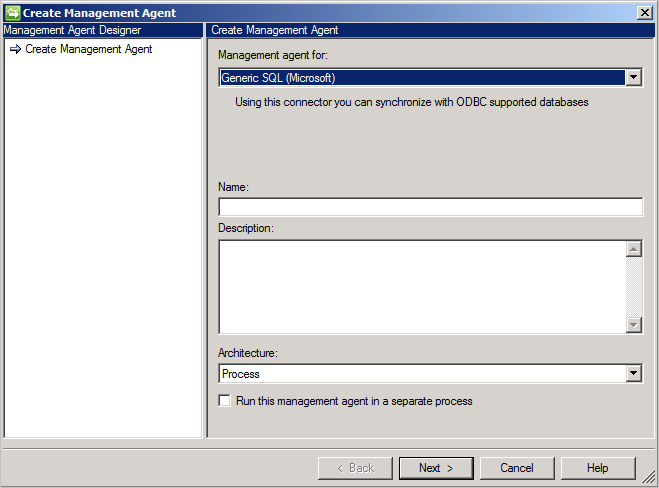
Pour créer un connecteur générique SQL, dans service de synchronisation, sélectionnez Agent de gestion et Créer. Sélectionnez le connecteur Generic SQL (Microsoft) .
Connectivité
Le connecteur utilise un fichier DSN ODBC pour la connectivité. Créez le fichier DSN en utilisant l’option Sources de données ODBC qui se trouve dans le menu Démarrer, sous Outils d’administration. Dans l’outil d’administration, créez un Fichier DSN pouvant être transmis au connecteur.
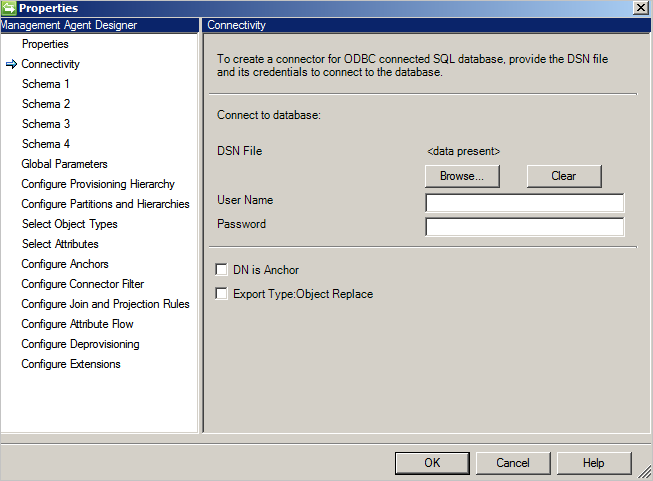
L’écran Connectivité est le premier qui s’affiche lorsque vous créez un nouveau connecteur SQL générique. Dans un premier temps, fournissez les informations suivantes :
- Chemin d'accès du fichier DSN
- Authentification
- Nom d’utilisateur
- Mot de passe
La base de données doit prendre en charge une de ces méthodes d’authentification :
- Authentification Windows: la base de données d’authentification utilise les informations d’identification Windows pour contrôler l’utilisateur. Le nom d’utilisateur/mot de passe spécifié est utilisé pour l’authentification auprès de la base de données. Ce compte a besoin des autorisations pour la base de données.
- Authentification SQL: la base de données d’authentification utilise les nom/mot de passe d’utilisateur définis dans l’écran Connectivité en vue de se connecter à la base de données. Si vous stockez le nom d’utilisateur/mot de passe dans le fichier DSN, les informations d’identification fournies sur l’écran Connectivité sont prioritaires.
- Authentification Azure SQL Database : Pour plus d’informations, consultez Connectez-vous à SQL Database via l’authentification Microsoft Entra.
Le nom unique est le point d’ancrage: si vous sélectionnez cette option, le nom unique est également utilisé comme attribut d’ancrage. Il peut être utilisé pour une implémentation simple mais présente également les limitations suivantes :
- Le connecteur ne prend en charge qu’un seul type d’objet. Les attributs de référence peuvent faire référence à un seul type d’objet.
Type d’exportation : remplacement d’objet: lors de l’exportation, lorsque seuls certains attributs ont été modifiés, l’ensemble de l’objet avec tous les attributs est exporté et remplace l’objet existant.
Schéma 1 (Détecter les types d’objets)
Sur cette page, vous allez configurer la manière dont le connecteur va rechercher les différents types d’objets dans la base de données.
Chaque type d’objet est présenté sous la forme d’une partition et configuré de manière plus approfondie sur Configurer des partitions et des hiérarchies.
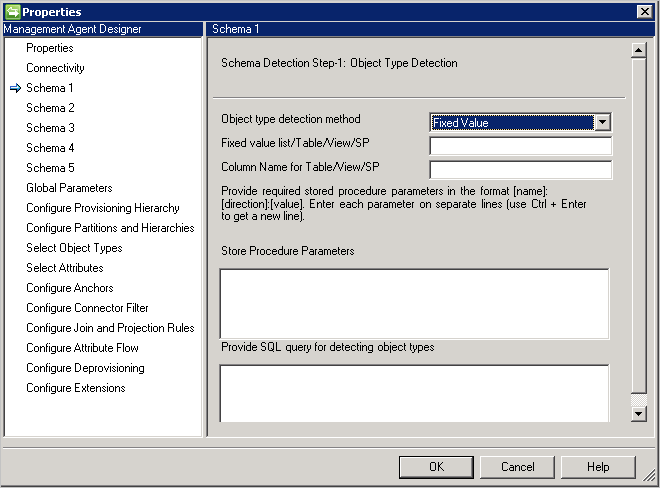
Méthode de détection du type d’objet: le connecteur prend en charge ces méthodes de détection de type objet.
- Valeur fixe: fournit la liste des types d’objets avec une liste séparée par des virgules. Par exemple :
User,Group,Department.
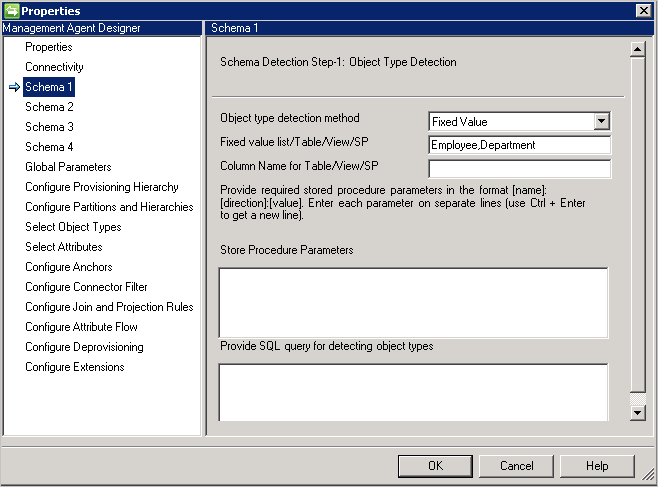
- Table/Vue/Procédure stockée: fournissez le nom de table/vue/procédure stockée, puis le nom de colonne qui fournit la liste des types d’objets. Si vous utilisez une procédure stockée, fournissez également des paramètres pour celle-ci au format [nom]:[Direction]:[Valeur]. Placez chacun des paramètres sur une ligne distincte (utilisez Ctrl + Entrée pour créer une ligne).
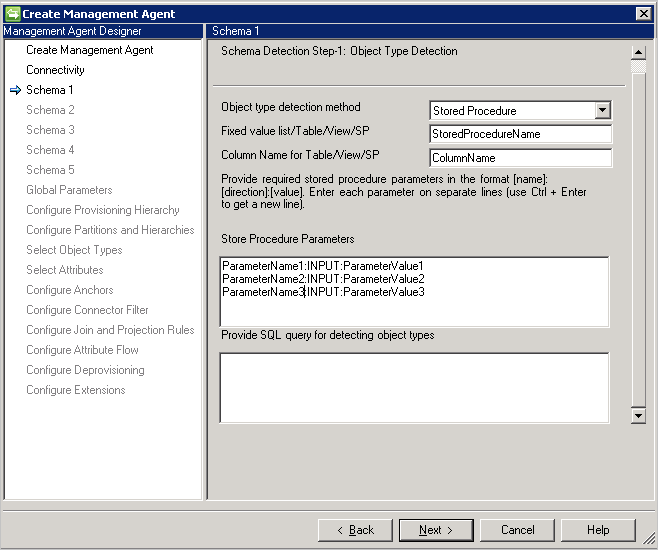
- Requête SQL : cette option permet de fournir une requête SQL qui renvoie une seule colonne avec les types d’objets, par exemple,
SELECT [Column Name] FROM TABLENAME. La colonne retournée doit être de type chaîne (varchar).
Schéma 2 (Détecter les types d’attribut)
Sur cette page, vous allez configurer la façon dont les noms et les types d’attribut vont être détectés. Les options de configuration sont répertoriées pour chaque type d’objet détecté dans la page précédente.
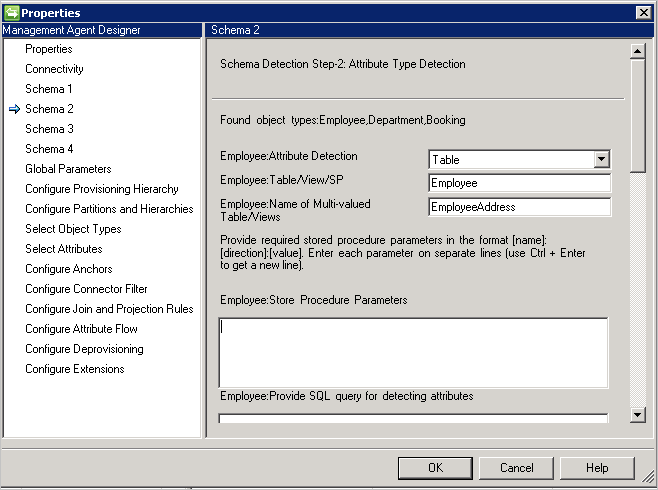
Méthode de détection de type d’attribut: le connecteur prend en charge ces méthodes de détection de type attribut avec chaque type d’objet détecté dans l’écran schéma 1.
- Table/Vue/Procédure stockée: indiquez le nom de table/vue/procédure stockée qui doit être utilisé pour trouver les noms d’attribut. Si vous utilisez une procédure stockée, fournissez également des paramètres pour celle-ci au format [nom]:[Direction]:[Valeur]. Placez chacun des paramètres sur une ligne distincte (utilisez Ctrl + Entrée pour créer une ligne). Pour détecter les noms d’attribut dans un attribut à valeurs multiples, fournissez une liste séparée par des virgules des tables ou des vues. Les scénarios à valeurs multiples ne sont pas pris en charge si les tables parent et enfant ont les mêmes noms de colonnes.
- Requête SQL : cette option permet de fournir une requête SQL qui renvoie une seule colonne avec les noms d’attributs, par exemple,
SELECT [Column Name] FROM TABLENAME. La colonne retournée doit être de type chaîne (varchar).
Schéma 3 (Définir le point d’ancrage et le nom unique)
Cette page vous permet de configurer le point d’ancrage et l’attribut de nom unique pour chaque type d’objet détecté. Vous pouvez sélectionner plusieurs attributs pour faire un point d’ancrage unique.
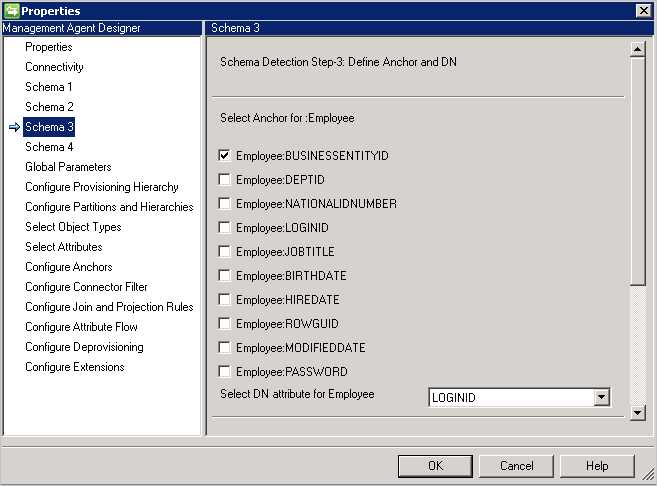
Les attributs à valeurs multiples et booléens ne sont pas répertoriés.
Le même attribut ne peut pas être utilisé à la fois pour DN et pour l'ancrage, sauf si l’option DN est le point d’ancrage est sélectionnée sur la page de connectivité.
Si DN est point d’ancrage est sélectionné sur la page Connectivité, cette page ne nécessite que l’attribut DN. Cet attribut peut également être utilisé en tant qu’attribut d’ancrage.
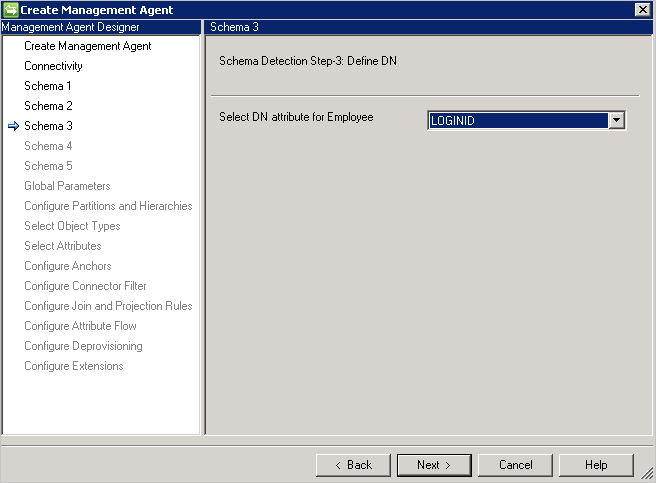
Schéma 4 (définir le type d’attribut, la référence et la direction)
Cette page permet de configurer le type d’attribut, par exemple un entier, une valeur binaire ou une valeur booléenne, ainsi que la direction pour chaque attribut. Tous les attributs de la page schéma 2 sont répertoriés, et notamment des attributs à valeurs multiples.
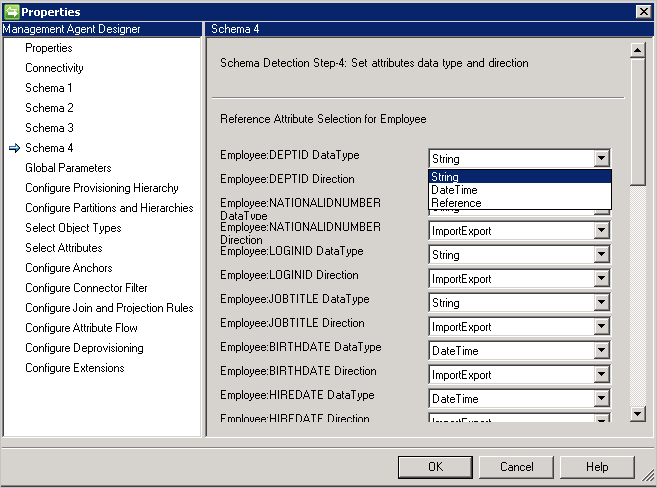
- Type de données: utilisé pour mapper le type d’attribut sur ceux connus par le moteur de synchronisation. La valeur par défaut consiste à utiliser le type détecté dans le schéma SQL, mais DateTime et Reference ne sont pas facilement détectables. Pour ces derniers, vous devez spécifier DateTime ou Reference.
- Direction: vous pouvez définir la direction d’attribut sur Import, Export ou ImportExport. ImportExport est la valeur par défaut.
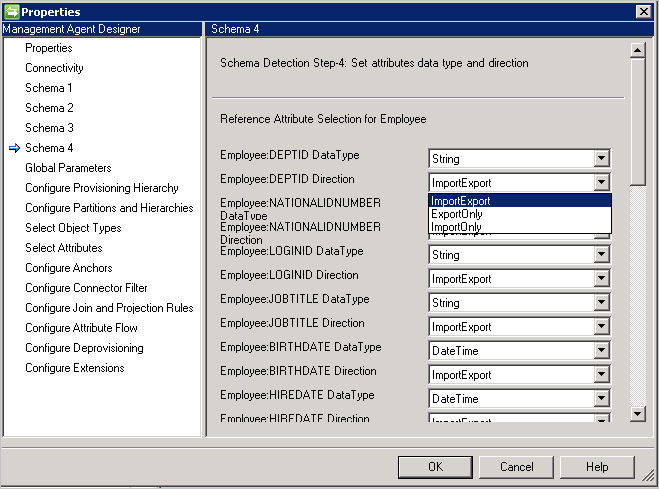
Remarques :
- Si un type d’attribut n’est pas détectable par le connecteur, il utilise le type de données chaîne.
- Tables imbriquées peuvent être considérées comme des tables de base de données à une colonne. Oracle stocke les lignes d’une table imbriquée sans aucun ordre particulier. Toutefois, lorsque vous récupérez la table imbriquée dans une variable PL/SQL, les lignes sont associées à des indices consécutifs en commençant à 1. Cela vous donne un accès de type tableau à des lignes individuelles.
- Les VARRYS ne sont pas pris en charge dans le connecteur.
Schéma 5 (Définir la partition pour les attributs de référence)
Sur cette page, pour tous les attributs de référence, vous configurez la partition (le type d’objet) à laquelle un attribut fait référence.
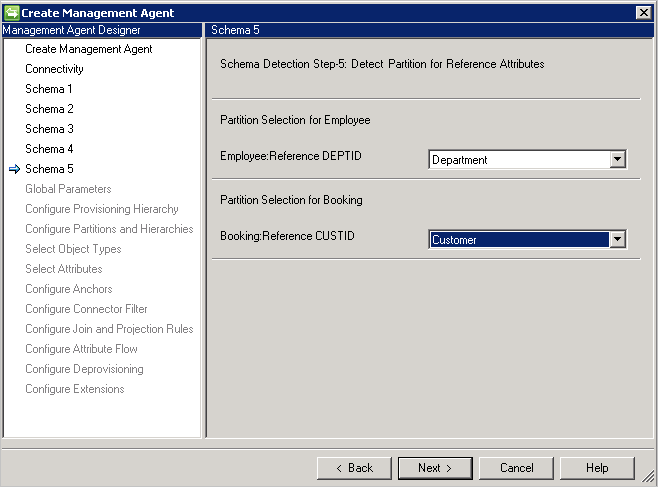
Si vous utilisez DN est l'ancre, vous devez utiliser le même type d'objet que celui référencé. Vous ne pouvez pas référencer un autre type d’objet.
Remarque
À compter de la mise à jour de mars 2017, il existe désormais une option pour « * ». Lorsque cette option est sélectionnée, tous les types de membres possibles seront importés.
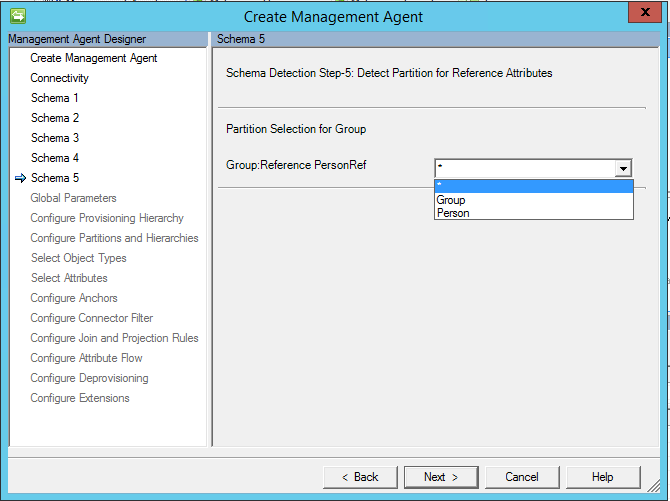
Importante
À compter de mai 2017 l’alias « * » toute option a été modifié pour prendre en charge l’importation et l’exportation des flux. Si vous souhaitez utiliser cette option, votre table ou vue à valeurs multiples doit avoir un attribut qui contient le type d’objet.

Si « * » est sélectionné, le nom de la colonne avec le type d’objet doit également être spécifié.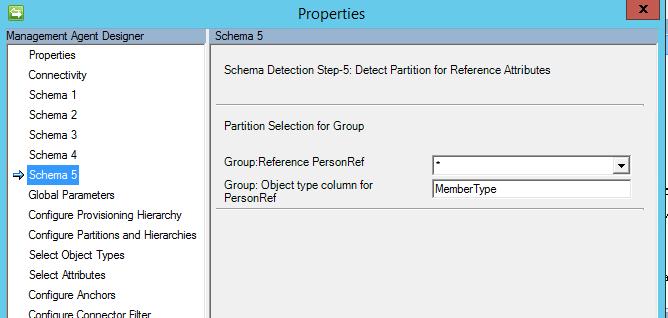
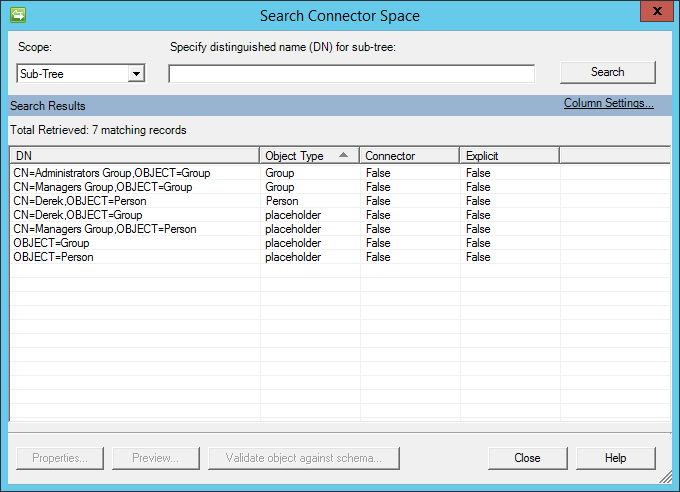
Après l’importation, vous obtiendrez un résultat similaire à ce qui suit :
Paramètres globaux
La page Paramètres globaux sert à configurer l’importation différentielle, le format Date/heure et la méthode de mot de passe.
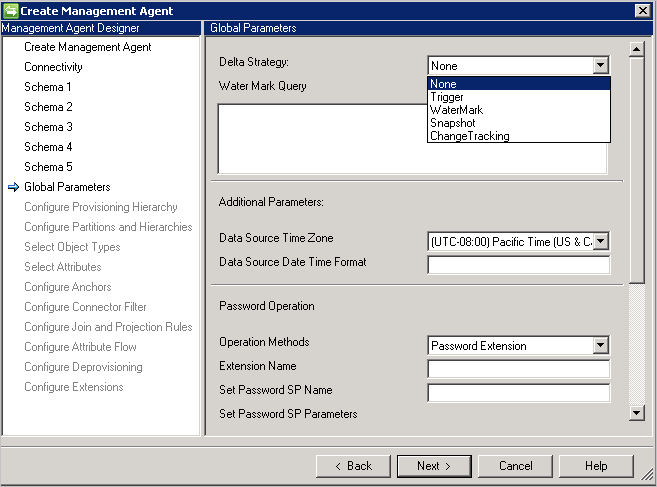
Le connecteur SQL générique prend en charge les méthodes suivantes pour l'importation Delta :
- Déclencheur : consultez Génération de vues Delta à l’aide de déclencheurs.
- Filigrane: il s’agit d’une approche numérique qui peut être utilisée avec n’importe quelle base de données. La requête en filigrane est prérenseignée en fonction du fournisseur de base de données. Une colonne de filigrane doit être présente sur chaque tableau/vue affichée. Cette colonne doit assurer les insertions et les mises à jour des tables, de même que les tables dépendantes (à valeurs multiples ou enfants). Les horloges entre le service de synchronisation et le serveur de base de données doivent être synchronisées. Dans le cas contraire, certaines entrées de l’importation différentielle peuvent être omises.
Limitation :- La stratégie de filigrane ne prend pas en charge les objets supprimés.
- Instantané: (fonctionne uniquement avec Microsoft SQL Server) Génération de vues delta à l’aide d’instantanés
- Suivi des modifications: (fonctionne uniquement avec Microsoft SQL Server) About Suivi des modifications
Limitations :- Le point d’ancrage et l’attribut de nom unique doivent faire partie de la clé primaire de l’objet sélectionné dans la table.
- La requête SQL n’est pas prise en charge pendant l’importation et l’exportation avec suivi des modifications.
Paramètres supplémentaires: spécifiez le fuseau horaire du serveur de base de données qui indique où se situe le serveur de base de données. Cette valeur est utilisée pour prendre en charge les différents formats d’attributs de date et heure.
Le connecteur stocke toujours les valeurs de date et date/heure au format UTC. Pour être en mesure d’établir une conversion correcte de la date et de l’heure, le fuseau horaire du serveur de base de données et le format utilisé doivent être spécifiés. Le format doit être exprimé au format .NET.
Pendant l’exportation, chaque attribut data/heure doit être fourni au connecteur au format horaire UTC.
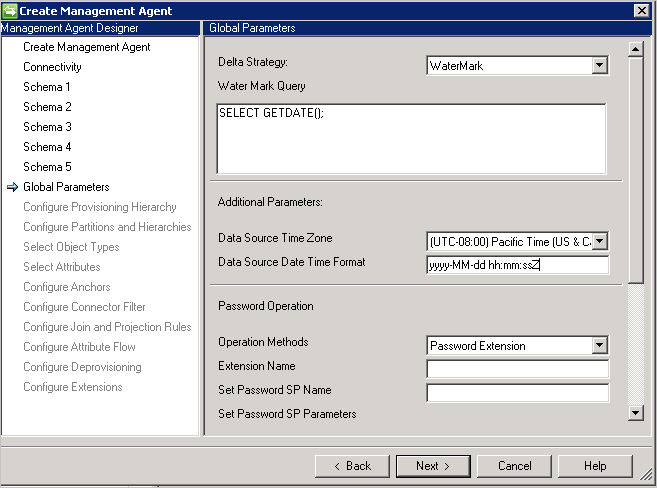
Configuration de mot de passe: le connecteur fournit des fonctionnalités de synchronisation de mot de passe et prend en charge la définition et la modification du mot de passe.
Le connecteur propose deux méthodes pour prendre en charge la synchronisation de mot de passe :
- Procédure stockée : cette méthode requiert deux procédures stockées pour prendre en charge la définition et la modification d’un mot de passe. Saisissez tous les paramètres pour ajouter et modifier le fonctionnement des mots de passe dans Set Password SP (SP de définition de mot de passe) et Change Password SP (SP de modification de mot de passe), conformément à l’exemple ci-dessous.
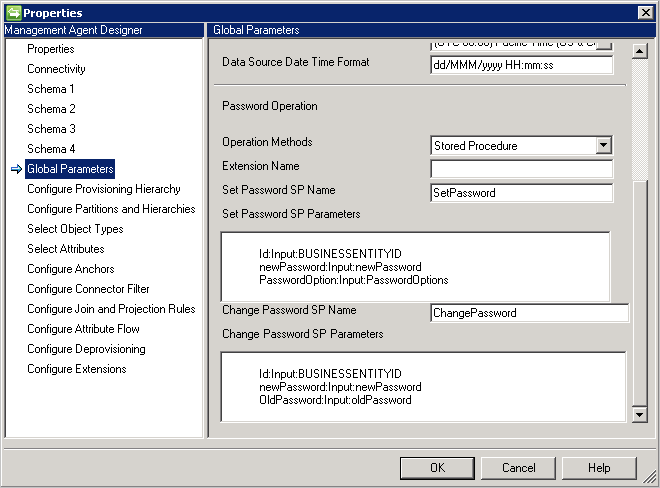
- Extension de mot de passe: cette méthode nécessite des DLL d’extension de mot de passe (vous devez fournir le nom de la DLL d’extension qui implémente l’interface IMAExtensible2Password ). L’assemblage d’extension de mot de passe doit être placé dans le dossier d’extension, de sorte que le connecteur puisse charger la DLL lors de l’exécution.
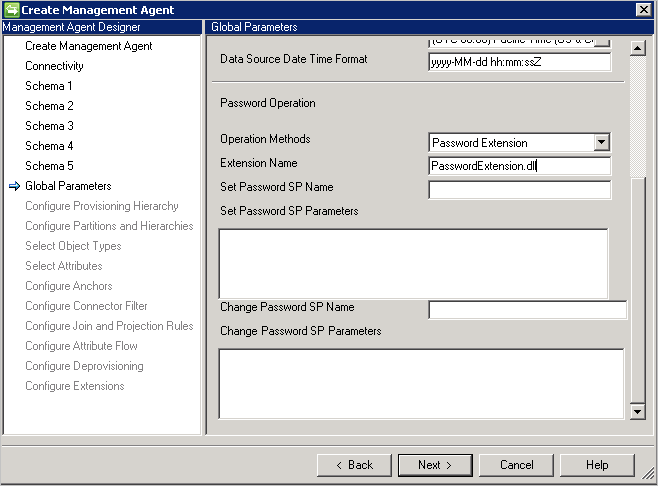
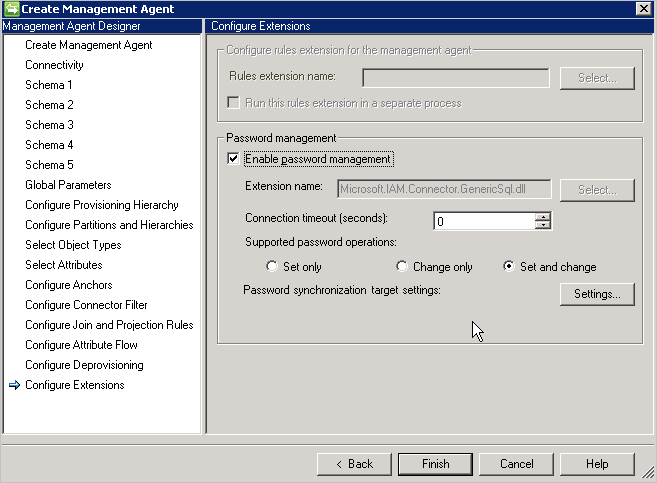
Vous devez également activer la gestion de mot de passe sur la page Configurer une Extension .
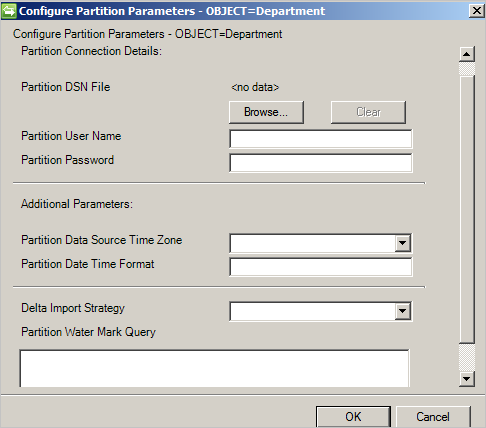
Configurer des partitions et des hiérarchies
Dans la page Partitions et hiérarchies, sélectionnez tous les types d’objets. Chaque type d’objet est sa propre partition.
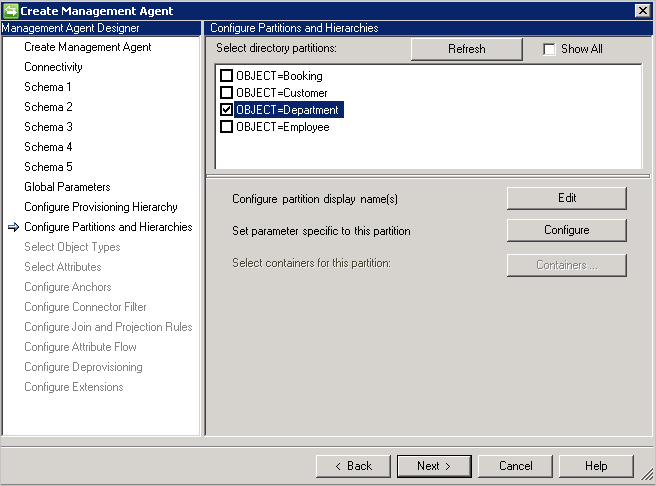
Vous pouvez également remplacer les valeurs définies sur la page Connectivité ou Paramètres globaux.
Configurer des points d'ancrage
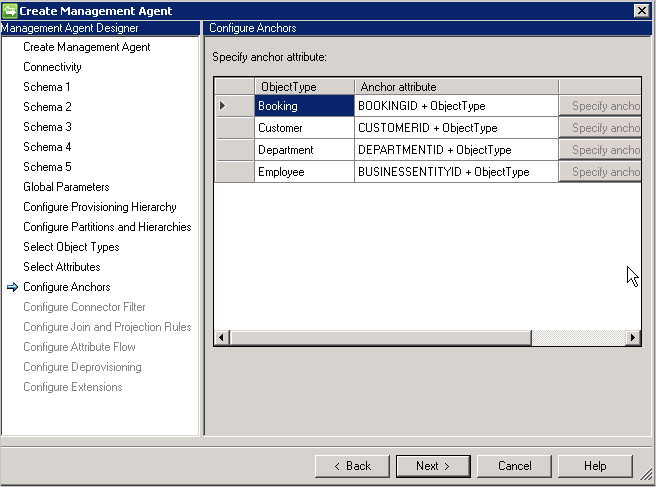
Cette page est en lecture seule, car le point d’ancrage a déjà été défini. L’attribut d’ancrage sélectionné est toujours ajouté avec le type d’objet pour s’assurer qu’il reste unique d’un type d’objet à l’autre.
Configurer le paramètre d’exécution d’étape
Ces étapes sont configurées sur les profils d'exécution sur le connecteur. Ces configurations font un réel travail d’importation et d’exportation de données.
Importation complète et différentielle
Le connecteur SQL générique prend en charge les importations complètes et différentielles par le biais des méthodes qui suivent :
- Table
- Affichage
- Procédure stockée
- Requête SQL
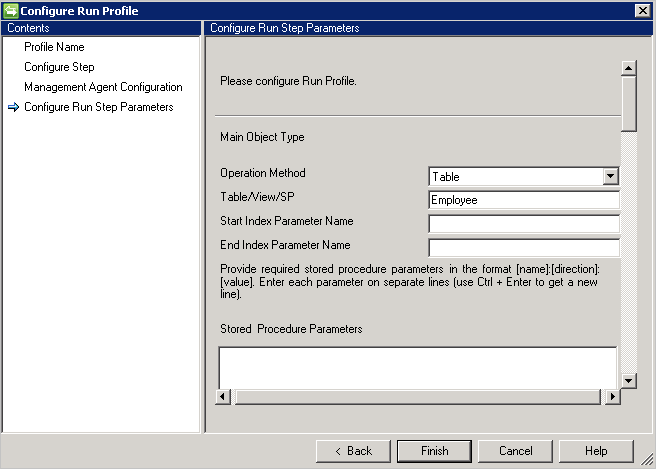
Table/Vue
Pour importer les attributs à plusieurs valeurs d’un objet, vous devez fournir le nom de table/vue dans le Nom de table/vues à plusieurs valeurs et les conditions de jointure respectives dans la Condition de jointure avec la table parente. S’il y a plus d’une table à valeurs multiples dans la source de données, vous pouvez utiliser une union pour obtenir une vue unique.
Importante
L’agent de gestion SQL générique ne peut fonctionner qu’avec une table à plusieurs valeurs. Ne placez pas plus d’un nom de table dans le nom de table/vues à plusieurs valeurs. Il s’agit d’une limitation du SQL générique.
Exemple : vous voulez importer l’objet Employé et tous ses attributs à plusieurs valeurs. Il y a deux tables appelées Employé (table principale) et Département (table à valeurs multiples). Effectuez les actions suivantes :
- Saisissez Employé dans Table/Vue/SP.
- Saisissez le service dans Nom de table/vue à valeurs multiples.
- Saisissez la condition de jointure entre Employé et Service dans Condition de jointure, par exemple,
Employee.DEPTID=Department.DepartmentID.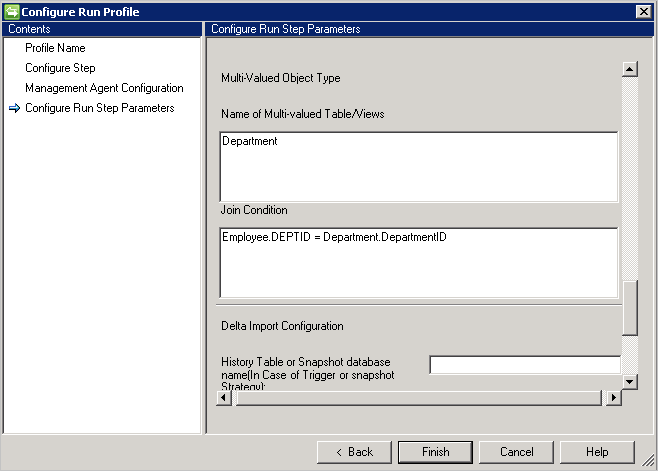
Procédures stockées
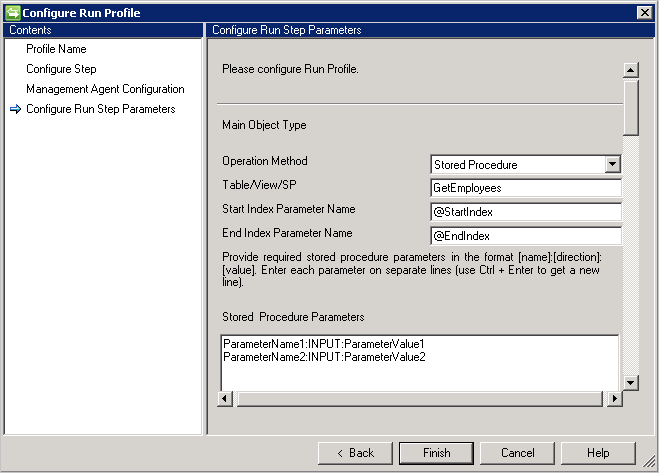
- Si vous avez beaucoup de données, il est conseillé de mettre en œuvre la pagination avec vos procédures stockées.
- Pour que votre procédure stockée prenne en charge la pagination, vous devez fournir un index de début et un index de fin. Voir : Pagination efficace dans de grandes quantités de données.
- @StartIndex et @EndIndex sont remplacés au moment de l’exécution par la valeur de taille configurée sur la page Étape de configuration. Par exemple, si le connecteur récupère la première page et que la taille de page est définie sur 500, @StartIndex serait 1 et @EndIndex 500. Ces valeurs augmentent lorsque le connecteur récupère les pages suivantes, ce qui a pour effet de modifier les valeurs @StartIndex et @EndIndex.
- Pour exécuter la procédure stockée paramétrable, fournissez les paramètres au format
[Name]:[Direction]:[Value]. Saisissez chaque paramètre sur une ligne différente (Utilisez Ctrl + Entrée pour passer à la ligne). - Le connecteur SQL générique prend également en charge l’opération d’importation à partir des serveurs liés dans Microsoft SQL Server. Si les informations doivent être extraites d’une table sur un serveur lié, la table doit être fournie au format :
[ServerName].[Database].[Schema].[TableName] - Le connecteur SQL générique prend en charge uniquement les objets dont la structure est similaire (les alias et le type de données) entre les informations d’étapes d’exécution et la détection de schéma. Si l’objet sélectionné dans le schéma et les informations fournies à l’étape d’exécution sont différents, le connecteur SQL est incapable de prendre en charge ce type de scénario.
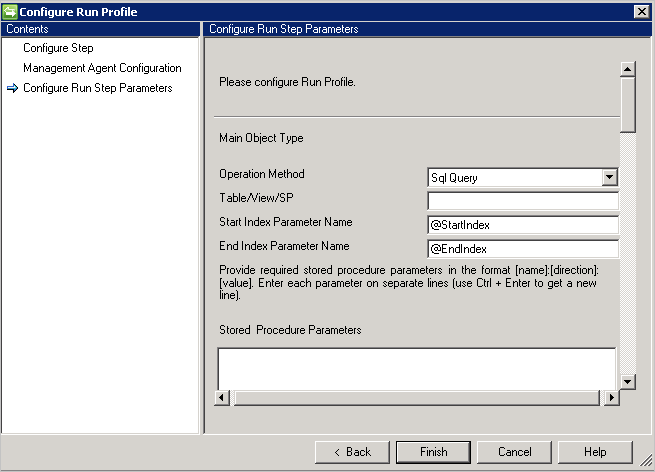
Requête SQL
Importante
CRLF ou le caractère de nouvelle ligne sert de séparateur entre plusieurs instructions.
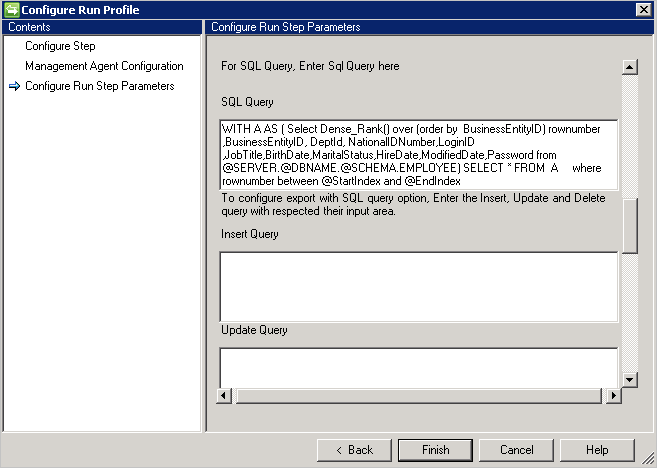
Exemple de requête SQL avec pagination : requête incorrecte, ne fonctionne pas car le nouveau caractère de ligne est utilisé :
WITH A AS
(select dense_rank() over (order by BusinessEntityID)
rownumber, BusinessEntityID, DeptID, NationalIDNumber, LoginID, JobTitle, BirthDate, MaritalStatus, HireDate, ModifiedDate, Password
from Employees
) select * from A where rownumber between @StartIndex and @EndIndex
Exemple de requête SQL avec pagination - requête correcte :
WITH A AS (select dense_rank() over (order by BusinessEntityID) rownumber, BusinessEntityID, DeptID, NationalIDNumber, LoginID, JobTitle, BirthDate, MaritalStatus, HireDate, ModifiedDate, Password from Employees) select * from A where rownumber between @StartIndex and @EndIndex
- Les requêtes à jeux de résultats multiples ne sont pas prises en charge.
- La requête SQL prend en charge la pagination et fournit l’index de début et d’index de fin en tant que variable pour prendre en charge la pagination.
Importation d’écart
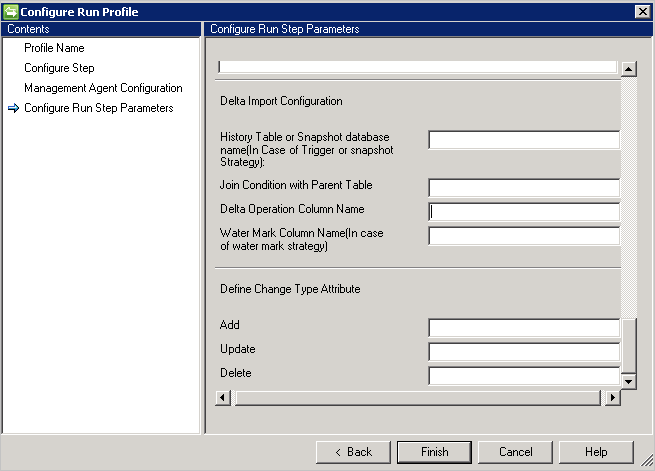
La configuration de l'importation Delta nécessite davantage de configuration par rapport à l'importation complète.
- Si vous choisissez l’approche de déclencheur ou de capture instantanée pour assurer le suivi des modifications différentielles, fournissez la table d’historique ou la base de données d’instantané dans la zone History Table or Snapshot database name (Table d’historique ou Nom de base de données par instantané).
- Vous devez également fournir une condition de jointure entre la table d’historique et la table parente, par exemple
Employee.ID=History.EmployeeID - Pour suivre la transaction sur la table parente à partir de la table d’historique, vous devez fournir le nom de la colonne qui contient les informations sur l’opération (Ajout/Mise à jour/Suppression).
- Si vous choisissez « Watermark » pour suivre les variations delta, fournissez le nom de la colonne qui contient les informations d’opération dans Water Mark Column Name.
- La colonne Modifier l’attribut de type est requise pour le type de modification. Cette colonne mappe une modification qui se produit dans la table principale ou une table à valeurs multiples sur un type de changement dans la vue delta. Cette colonne peut contenir le type de modification Modify_Attribute pour une modification au niveau de l’attribut ou un type d’ajout, de modification, de suppression pour un type de modification au niveau de l’objet. S’il s’agit d’autre chose que les valeurs par défaut Ajouter, Modifier ou Supprimer, vous pouvez définir ces valeurs à l’aide de cette option.
Export
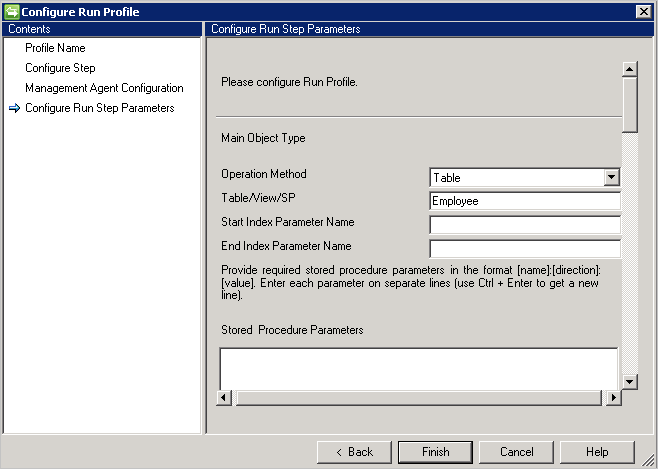
Le connecteur SQL générique prend en charge l’exportation en utilisant quatre méthodes prises en charge telles que :
- Tableau
- Affichage
- Procédure stockée
- Requête SQL
Table/Vue
Si vous choisissez l’option Table/Vue, le connecteur génère les requêtes respectives pour procéder à l’exportation.
Procédures stockées
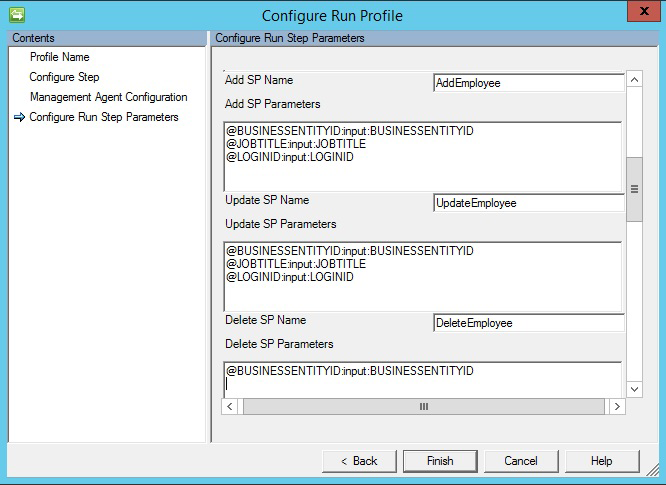
Si vous choisissez l’option Procédure stockée, l’exportation nécessite 3 procédures stockées différentes pour effectuer des opérations d’insertion/de mise à jour/de suppression.
- Ajouter un nom SP: Cette SP s’exécute si un objet arrive au connecteur pour une insertion dans la table concernée.
- Mettre à jour le nom du SP: cette SP s’exécute si un objet parvient au connecteur pour mise à jour dans la table concernée.
- Supprimer SP Name: cette SP s’exécute si un objet arrive au connecteur pour une suppression de la table respective.
- Attribut sélectionné à partir du schéma utilisé comme valeur de paramètre à la procédure stockée. Par exemple,
@EmployeeName: INPUT: EmployeeName(EmployeeName est sélectionné dans le schéma de connecteur et un connecteur remplace la valeur correspondante lors de l’exportation) - Pour exécuter la procédure stockée paramétrée, fournissez les paramètres au format
[Name]:[Direction]:[Value]. Saisissez chaque paramètre sur une ligne différente (Utilisez Ctrl + Entrée pour passer à la ligne).
Requête SQL
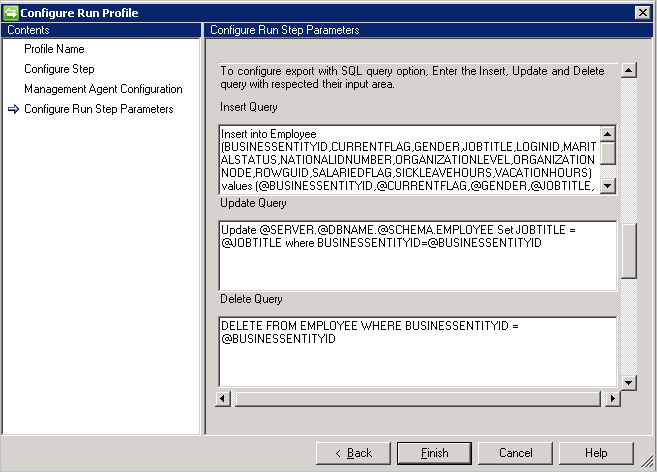
Si vous choisissez l’option Requête SQL, l’exportation nécessite trois requêtes différentes pour effectuer les opérations d’insertion/de mise à jour/de suppression.
- Requête d’insertion: cette requête s’exécute si un objet arrive au connecteur pour une insertion dans la table concernée.
- Requête de mise à jour: cette requête s’exécute si un objet arrive au connecteur pour une mise à jour dans la table concernée.
- Requête de suppression: cette requête s’exécute si un objet arrive au connecteur pour une suppression de la table concernée.
- Attribut sélectionné à partir du schéma utilisé comme valeur de paramètre à la requête, par exemple
Insert into Employee (ID, Name) Values (@ID, @EmployeeName)
Importante
CRLF ou le caractère de nouvelle ligne sert de séparateur entre plusieurs instructions.
Exemple de requête SQL de mise à jour en plusieurs étapes : le nouveau caractère de ligne est utilisé pour séparer les instructions SQL :
update Employee set jobTitle=@JOBTITLE where BusinessEntityID=@BUSINESSENTITYID
insert into ChangeLog VALUES (@BUSINESSENTITYID)
Dépannage
- Pour plus d’informations sur la façon d’activer la journalisation pour résoudre les problèmes du connecteur, consultez Comment activer le suivi ETW pour les connecteurs.