Créer un bot RAG dans Teams
Les chatbots Q&A avancés sont des applications puissantes créées à l’aide de modèles de langage volumineux (LLM). Les chatbots répondent aux questions en extrayant des informations de sources spécifiques à l’aide d’une méthode appelée Retrieval-Augmented Generation (RAG). L’architecture RAG a deux flux main :
Ingestion des données : pipeline pour ingérer des données à partir d’une source et les indexer. Cela se produit généralement hors connexion.
Récupération et génération : la chaîne RAG, qui prend la requête de l’utilisateur au moment de l’exécution et récupère les données pertinentes à partir de l’index, puis les transmet au modèle.
Microsoft Teams vous permet de créer un bot conversationnel avec RAG pour créer une expérience améliorée afin d’optimiser la productivité. Teams Toolkit fournit une série de modèles d’application prêts à l’emploi dans la catégorie Conversation avec vos données qui combine les fonctionnalités de recherche Azure AI, Microsoft 365 SharePoint et l’API personnalisée en tant que source de données et llms différents pour créer une expérience de recherche conversationnelle dans Teams.
Configuration requise
| Installer | Pour l’utilisation... |
|---|---|
| Visual Studio Code | Environnements de build JavaScript, TypeScript ou Python. Utilisez la dernière version. |
| Toolkit Teams | Microsoft Visual Studio Code extension qui crée une structure de projet pour votre application. Utilisez la dernière version. |
| Node.js | Environnement runtime JavaScript principal. Pour plus d’informations, consultez Node.js table de compatibilité des versions pour le type de projet. |
| Microsoft Teams | Microsoft Teams pour collaborer avec toutes les personnes avec lesquelles vous travaillez via des applications de conversation, de réunions et d’appels au même endroit. |
| Azure OpenAI | Commencez par créer votre clé API OpenAI pour utiliser le transformateur préentraîné génératif (GPT) d’OpenAI. Si vous souhaitez héberger votre application ou accéder à des ressources dans Azure, vous devez créer un service Azure OpenAI. |
Créer un projet de chatbot IA de base
Ouvrez Visual Studio Code.
Sélectionnez l’icône Teams Toolkit
 dans la barre d’activité Visual Studio Code.
dans la barre d’activité Visual Studio Code.Sélectionnez Créer une application.
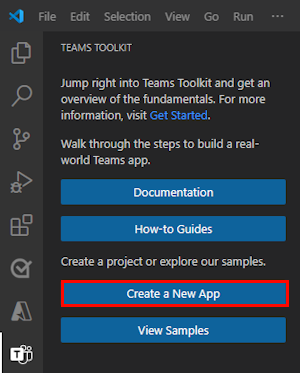
Sélectionnez Agent du moteur personnalisé.
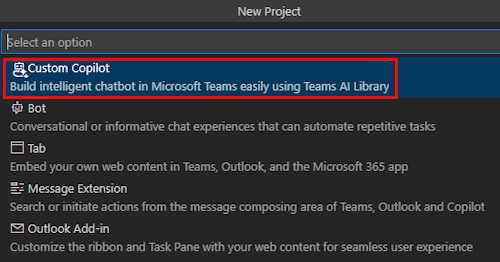
Sélectionnez Conversation avec vos données.
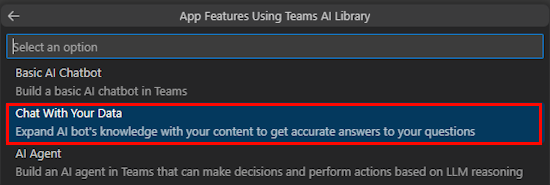
Sélectionnez Personnaliser.
Sélectionnez JavaScript.
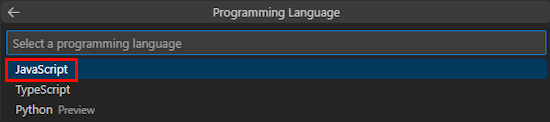
Sélectionnez Azure OpenAI ou OpenAI.
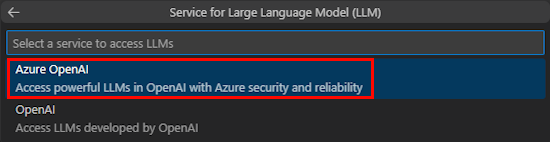
Entrez vos informations d’identification Azure OpenAI ou OpenAI en fonction du service que vous sélectionnez. Ensuite, sélectionnez Entrée.

Sélectionnez Dossier par défaut.

Pour modifier l’emplacement par défaut, procédez comme suit :
- Sélectionnez Parcourir.
- Sélectionnez l’emplacement de l’espace de travail du projet.
- Sélectionnez Sélectionner un dossier.
Entrez un nom d’application pour votre application, puis sélectionnez la touche Entrée .

Vous avez créé votre espace de travail de projet Conversation avec vos données .
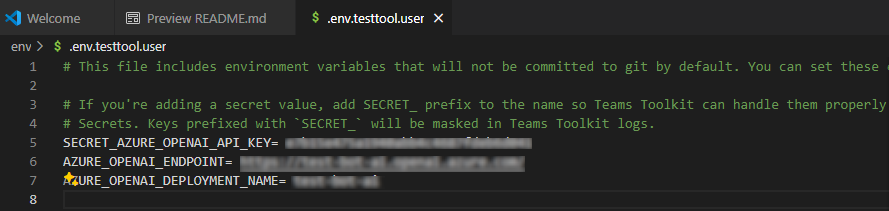
Sous EXPLORATEUR, accédez au fichier env.env.testtool.user>.
Mettez à jour les valeurs suivantes :
SECRET_AZURE_OPENAI_API_KEY=<your-key>AZURE_OPENAI_ENDPOINT=<your-endpoint>AZURE_OPENAI_DEPLOYMENT_NAME=<your-deployment>
Pour déboguer votre application, sélectionnez la touche F5 ou, dans le volet gauche, sélectionnez Exécuter et déboguer (Ctrl+Maj+D), puis sélectionnez Déboguer dans l’outil de test (préversion) dans la liste déroulante.
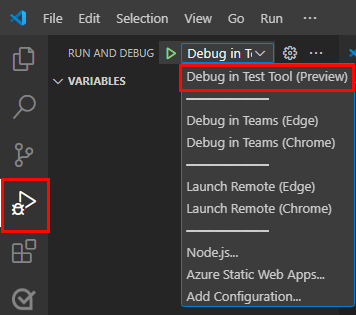
L’outil de test ouvre le bot dans une page web.

Découvrez le code source de l’application bot
| Folder | Sommaire |
|---|---|
.vscode |
Visual Studio Code des fichiers pour le débogage. |
appPackage |
Modèles pour le manifeste de l’application Teams. |
env |
Fichiers d’environnement. |
infra |
Modèles de provisionnement de ressources Azure. |
src |
Code source de l’application. |
src/index.js |
Configure le serveur d’applications bot. |
src/adapter.js |
Configure l’adaptateur de bot. |
src/config.js |
Définit les variables d’environnement. |
src/prompts/chat/skprompt.txt |
Définit l’invite. |
src/prompts/chat/config.json |
Configure l’invite. |
src/app/app.js |
Gère les logiques métier du bot RAG. |
src/app/myDataSource.js |
Définit la source de données. |
src/data/*.md |
Sources de données de texte brut. |
teamsapp.yml |
Il s’agit du fichier projet main Teams Toolkit. Le fichier projet définit les propriétés et les définitions d’étape de configuration. |
teamsapp.local.yml |
Cela remplace par des teamsapp.yml actions qui activent l’exécution et le débogage locaux. |
teamsapp.testtool.yml |
Cela remplace par des teamsapp.yml actions qui permettent l’exécution et le débogage locaux dans l’outil de test d’application Teams. |
Scénarios RAG pour Teams AI
Dans le contexte de l’IA, les bases de données vectorielles sont largement utilisées comme stockages RAG, qui stockent les données d’incorporation et fournissent une recherche de similarité vectorielle. La bibliothèque IA Teams fournit des utilitaires pour vous aider à créer des incorporations pour les entrées données.
Conseil
La bibliothèque IA Teams ne fournit pas l’implémentation de la base de données vectorielle. Vous devez donc ajouter votre propre logique pour traiter les incorporations créées.
// create OpenAIEmbeddings instance
const model = new OpenAIEmbeddings({ ... endpoint, apikey, model, ... });
// create embeddings for the given inputs
const embeddings = await model.createEmbeddings(model, inputs);
// your own logic to process embeddings
Le diagramme suivant montre comment la bibliothèque IA Teams fournit des fonctionnalités pour faciliter chaque étape du processus de récupération et de génération :
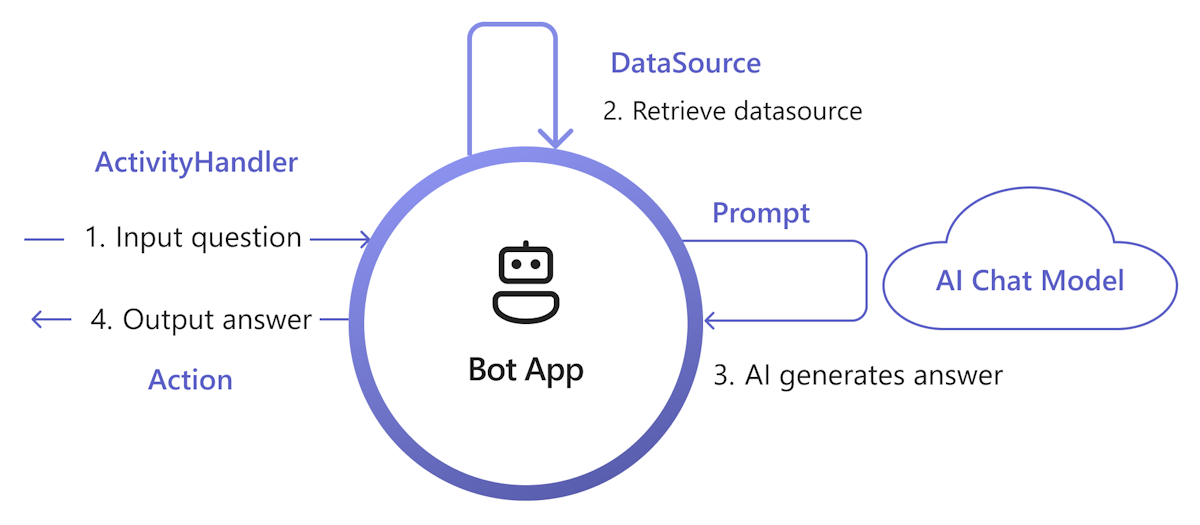
Gérer l’entrée : la méthode la plus simple consiste à passer l’entrée de l’utilisateur à la récupération sans aucune modification. Toutefois, si vous souhaitez personnaliser l’entrée avant la récupération, vous pouvez ajouter un gestionnaire d’activités à certaines activités entrantes.
Récupérer des donnéesSource : La bibliothèque IA Teams fournit une
DataSourceinterface pour vous permettre d’ajouter votre propre logique de récupération. Vous devez créer votre propreDataSourceinstance et la bibliothèque IA Teams l’appelle à la demande.class MyDataSource implements DataSource { /** * Name of the data source. */ public readonly name = "my-datasource"; /** * Renders the data source as a string of text. * @param context Turn context for the current turn of conversation with the user. * @param memory An interface for accessing state values. * @param tokenizer Tokenizer to use when rendering the data source. * @param maxTokens Maximum number of tokens allowed to be rendered. * @returns The text to inject into the prompt as a `RenderedPromptSection` object. */ renderData( context: TurnContext, memory: Memory, tokenizer: Tokenizer, maxTokens: number ): Promise<RenderedPromptSection<string>> { ... } }Appeler l’IA avec l’invite : dans le système d’invite IA Teams, vous pouvez facilement injecter un
DataSourceen ajustant laaugmentation.data_sourcessection de configuration. Cela connecte l’invite avec l’orchestrateurDataSourcede bibliothèque et pour injecter leDataSourcetexte dans l’invite finale. Pour plus d’informations, consultez authorprompt. Par exemple, dans le fichier de l’inviteconfig.json:{ "schema": 1.1, ... "augmentation": { "data_sources": { "my-datasource": 1200 } } }Générer une réponse : par défaut, la bibliothèque IA Teams répond à la réponse générée par l’IA sous forme de sms à l’utilisateur. Si vous souhaitez personnaliser la réponse, vous pouvez remplacer les actions SAY par défaut ou appeler explicitement le modèle IA pour générer vos réponses, par exemple, avec des cartes adaptatives.
Voici un ensemble minimal d’implémentations pour ajouter RAG à votre application. En général, il implémente DataSource pour injecter votre knowledge dans l’invite, afin que l’IA puisse générer une réponse basée sur le knowledge.
Créer un
myDataSource.tsfichier pour implémenterDataSourcel’interface :export class MyDataSource implements DataSource { public readonly name = "my-datasource"; public async renderData( context: TurnContext, memory: Memory, tokenizer: Tokenizer, maxTokens: number ): Promise<RenderedPromptSection<string>> { const input = memory.getValue('temp.input') as string; let knowledge = "There's no knowledge found."; // hard-code knowledge if (input?.includes("shuttle bus")) { knowledge = "Company's shuttle bus may be 15 minutes late on rainy days."; } else if (input?.includes("cafe")) { knowledge = "The Cafe's available time is 9:00 to 17:00 on working days and 10:00 to 16:00 on weekends and holidays." } return { output: knowledge, length: knowledge.length, tooLong: false } } }Inscrivez dans
app.tsleDataSourcefichier :// Register your data source to prompt manager planner.prompts.addDataSource(new MyDataSource());
Créez le
prompts/qa/skprompt.txtfichier et ajoutez le texte suivant :The following is a conversation with an AI assistant. The assistant is helpful, creative, clever, and very friendly to answer user's question. Base your answer off the text below:Créez le
prompts/qa/config.jsonfichier et ajoutez le code suivant pour vous connecter à la source de données :{ "schema": 1.1, "description": "Chat with QA Assistant", "type": "completion", "completion": { "model": "gpt-35-turbo", "completion_type": "chat", "include_history": true, "include_input": true, "max_input_tokens": 2800, "max_tokens": 1000, "temperature": 0.9, "top_p": 0.0, "presence_penalty": 0.6, "frequency_penalty": 0.0, "stop_sequences": [] }, "augmentation": { "data_sources": { "my-datasource": 1200 } } }
Sélectionner des sources de données
Dans les scénarios Chat With Your Data ou RAG, Teams Toolkit fournit les types de sources de données suivants :
Personnaliser : vous permet de contrôler entièrement l’ingestion des données pour créer votre propre index vectoriel et l’utiliser comme source de données. Pour plus d’informations, consultez Générer votre propre ingestion de données.
Vous pouvez également utiliser l’extension de base de données vectorielle Azure Cosmos DB ou l’extension vectorielle du serveur Azure PostgreSQL comme bases de données vectorielles, ou l’API Recherche web Bing pour obtenir le contenu web le plus récent afin d’implémenter n’importe quelle source de données instance de se connecter à votre propre source de données.
Recherche Azure AI : fournit un exemple pour ajouter vos documents au service Recherche Azure AI, puis utiliser l’index de recherche comme source de données.
API personnalisée : permet à votre chatbot d’appeler l’API définie dans le document de description OpenAPI pour récupérer des données de domaine à partir du service API.
Microsoft Graph et SharePoint : fournit un exemple d’utilisation du contenu Microsoft 365 de l’API Recherche Microsoft Graph comme source de données.
Créer votre propre ingestion de données
Pour générer votre ingestion de données, procédez comme suit :
Charger vos documents sources : assurez-vous que votre document comporte un texte explicite, car le modèle d’incorporation prend uniquement du texte comme entrée.
Fractionner en blocs : veillez à fractionner le document pour éviter les échecs d’appel d’API, car le modèle d’incorporation a une limitation de jeton d’entrée.
Modèle d’incorporation d’appel : appelez les API du modèle d’incorporation pour créer des incorporations pour les entrées données.
Stocker les incorporations : stockez les incorporations créées dans une base de données vectorielle. Incluez également des métadonnées utiles et du contenu brut pour plus de référence.
Exemple de code
loader.ts: texte brut comme entrée source.import * as fs from "node:fs"; export function loadTextFile(path: string): string { return fs.readFileSync(path, "utf-8"); }splitter.ts: fractionnez le texte en blocs, avec un chevauchement.// split words by delimiters. const delimiters = [" ", "\t", "\r", "\n"]; export function split(content: string, length: number, overlap: number): Array<string> { const results = new Array<string>(); let cursor = 0, curChunk = 0; results.push(""); while(cursor < content.length) { const curChar = content[cursor]; if (delimiters.includes(curChar)) { // check chunk length while (curChunk < results.length && results[curChunk].length >= length) { curChunk ++; } for (let i = curChunk; i < results.length; i++) { results[i] += curChar; } if (results[results.length - 1].length >= length - overlap) { results.push(""); } } else { // append for (let i = curChunk; i < results.length; i++) { results[i] += curChar; } } cursor ++; } while (curChunk < results.length - 1) { results.pop(); } return results; }embeddings.ts: utilisez la bibliothèqueOpenAIEmbeddingsIA Teams pour créer des incorporations.import { OpenAIEmbeddings } from "@microsoft/teams-ai"; const embeddingClient = new OpenAIEmbeddings({ azureApiKey: "<your-aoai-key>", azureEndpoint: "<your-aoai-endpoint>", azureDeployment: "<your-embedding-deployment, e.g., text-embedding-ada-002>" }); export async function createEmbeddings(content: string): Promise<number[]> { const response = await embeddingClient.createEmbeddings(content); return response.output[0]; }searchIndex.ts: créez un index recherche Azure AI.import { SearchIndexClient, AzureKeyCredential, SearchIndex } from "@azure/search-documents"; const endpoint = "<your-search-endpoint>"; const apiKey = "<your-search-key>"; const indexName = "<your-index-name>"; const indexDef: SearchIndex = { name: indexName, fields: [ { type: "Edm.String", name: "id", key: true, }, { type: "Edm.String", name: "content", searchable: true, }, { type: "Edm.String", name: "filepath", searchable: true, filterable: true, }, { type: "Collection(Edm.Single)", name: "contentVector", searchable: true, vectorSearchDimensions: 1536, vectorSearchProfileName: "default" } ], vectorSearch: { algorithms: [{ name: "default", kind: "hnsw" }], profiles: [{ name: "default", algorithmConfigurationName: "default" }] }, semanticSearch: { defaultConfigurationName: "default", configurations: [{ name: "default", prioritizedFields: { contentFields: [{ name: "content" }] } }] } }; export async function createNewIndex(): Promise<void> { const client = new SearchIndexClient(endpoint, new AzureKeyCredential(apiKey)); await client.createIndex(indexDef); }searchIndexer.ts: chargez les incorporations créées et d’autres champs dans l’index recherche Azure AI.import { AzureKeyCredential, SearchClient } from "@azure/search-documents"; export interface Doc { id: string, content: string, filepath: string, contentVector: number[] } const endpoint = "<your-search-endpoint>"; const apiKey = "<your-search-key>"; const indexName = "<your-index-name>"; const searchClient: SearchClient<Doc> = new SearchClient<Doc>(endpoint, indexName, new AzureKeyCredential(apiKey)); export async function indexDoc(doc: Doc): Promise<boolean> { const response = await searchClient.mergeOrUploadDocuments([doc]); return response.results.every((result) => result.succeeded); }index.ts: orchestrer les composants ci-dessus.import { createEmbeddings } from "./embeddings"; import { loadTextFile } from "./loader"; import { createNewIndex } from "./searchIndex"; import { indexDoc } from "./searchIndexer"; import { split } from "./splitter"; async function main() { // Only need to call once await createNewIndex(); // local files as source input const files = [`${__dirname}/data/A.md`, `${__dirname}/data/A.md`]; for (const file of files) { // load file const fullContent = loadTextFile(file); // split into chunks const contents = split(fullContent, 1000, 100); let partIndex = 0; for (const content of contents) { partIndex ++; // create embeddings const embeddings = await createEmbeddings(content); // upload to index await indexDoc({ id: `${file.replace(/[^a-z0-9]/ig, "")}___${partIndex}`, content: content, filepath: file, contentVector: embeddings, }); } } } main().then().finally();
Recherche Azure AI en tant que source de données
Dans cette section, vous allez apprendre à :
- Ajoutez votre document à Recherche Azure AI par le biais du service Azure OpenAI.
- Utilisez l’index Azure AI Search comme source de données dans l’application RAG.
Ajouter un document à Recherche Azure AI
Remarque
Cette approche crée une API de conversation de bout en bout appelée modèle IA. Vous pouvez également utiliser l’index créé précédemment comme source de données, et utiliser la bibliothèque IA Teams pour personnaliser la récupération et l’invite.
Vous pouvez ingérer vos documents de connaissances dans azure AI Search Service et créer un index vectoriel avec Azure OpenAI sur vos données. Après l’ingestion, vous pouvez utiliser l’index comme source de données.
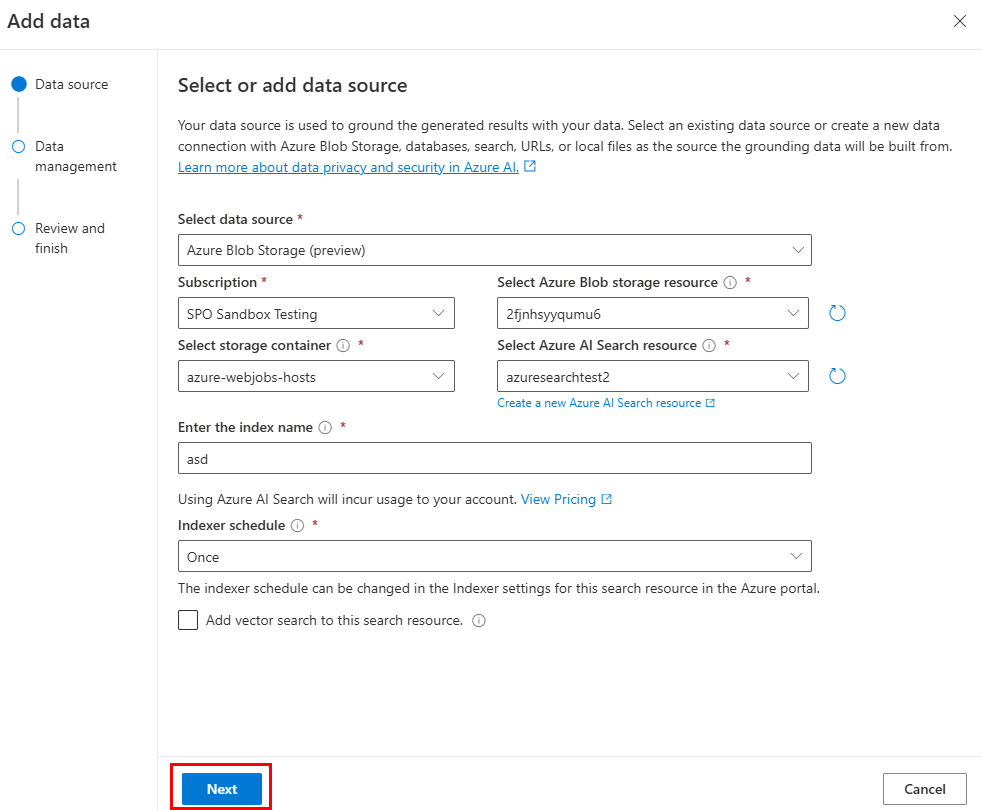
Préparez vos données dans Stockage Blob Azure.
Dans Azure OpenAI Studio, sélectionnez Ajouter une source de données.
Mettez à jour les champs obligatoires.
Sélectionnez Suivant.
La page Gestion des données s’affiche .
Mettez à jour les champs obligatoires.
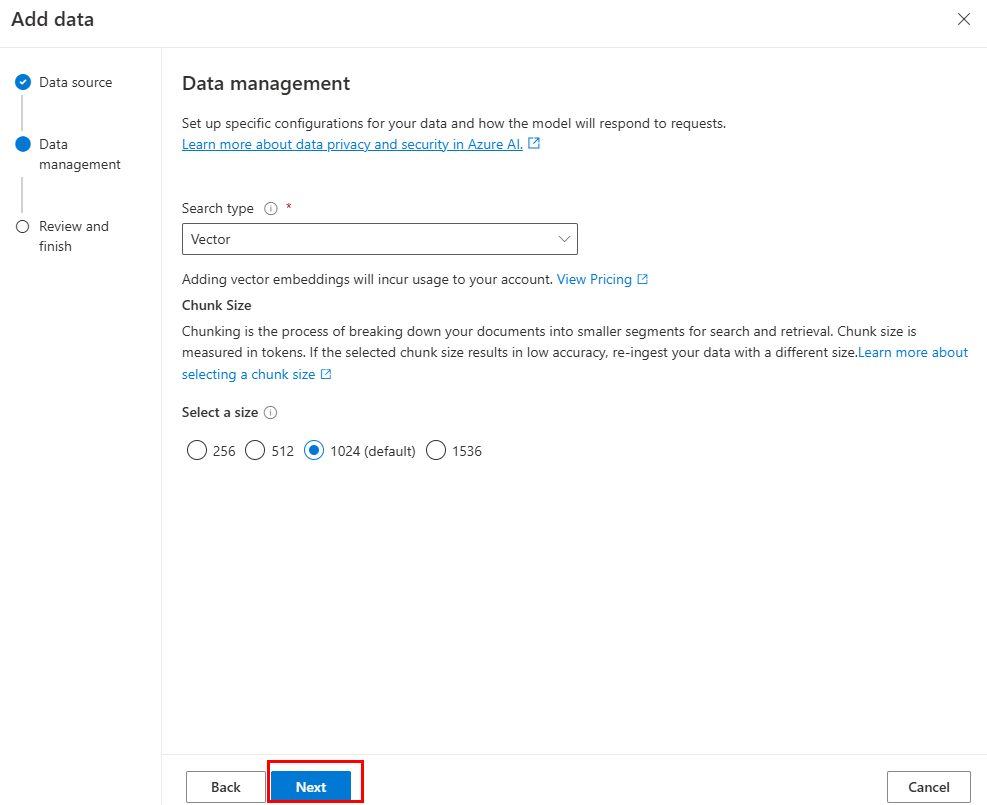
Sélectionnez Suivant.
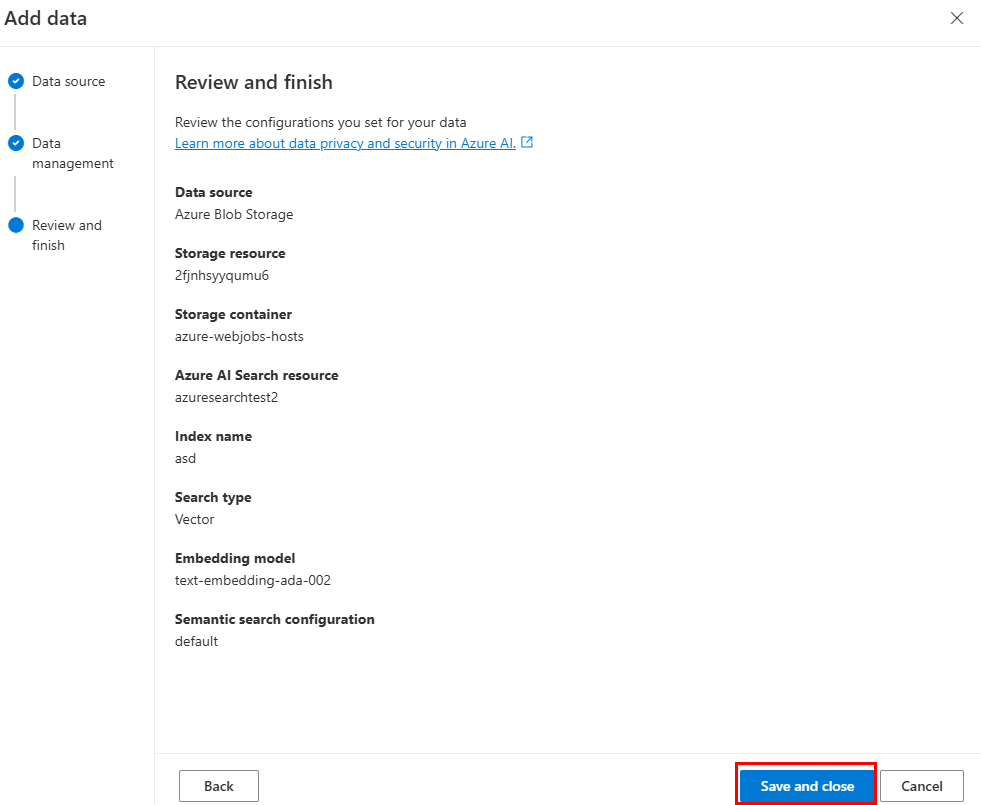
Mettez à jour les champs obligatoires. Sélectionnez Suivant.
Sélectionnez Enregistrer et fermer.
Utiliser la source de données d’index Recherche IA Azure
Après avoir ingéré des données dans Recherche Azure AI, vous pouvez implémenter les vôtres DataSource pour récupérer les données de l’index de recherche.
const { AzureKeyCredential, SearchClient } = require("@azure/search-documents");
const { DataSource, Memory, OpenAIEmbeddings, Tokenizer } = require("@microsoft/teams-ai");
const { TurnContext } = require("botbuilder");
// Define the interface for document
class Doc {
constructor(id, content, filepath) {
this.id = id;
this.content = content; // searchable
this.filepath = filepath;
}
}
// Azure OpenAI configuration
const aoaiEndpoint = "<your-aoai-endpoint>";
const aoaiApiKey = "<your-aoai-key>";
const aoaiDeployment = "<your-embedding-deployment, e.g., text-embedding-ada-002>";
// Azure AI Search configuration
const searchEndpoint = "<your-search-endpoint>";
const searchApiKey = "<your-search-apikey>";
const searchIndexName = "<your-index-name>";
// Define MyDataSource class implementing DataSource interface
class MyDataSource extends DataSource {
constructor() {
super();
this.name = "my-datasource";
this.embeddingClient = new OpenAIEmbeddings({
azureEndpoint: aoaiEndpoint,
azureApiKey: aoaiApiKey,
azureDeployment: aoaiDeployment
});
this.searchClient = new SearchClient(searchEndpoint, searchIndexName, new AzureKeyCredential(searchApiKey));
}
async renderData(context, memory, tokenizer, maxTokens) {
// use user input as query
const input = memory.getValue("temp.input");
// generate embeddings
const embeddings = (await this.embeddingClient.createEmbeddings(input)).output[0];
// query Azure AI Search
const response = await this.searchClient.search(input, {
select: [ "id", "content", "filepath" ],
searchFields: ["rawContent"],
vectorSearchOptions: {
queries: [{
kind: "vector",
fields: [ "contentVector" ],
vector: embeddings,
kNearestNeighborsCount: 3
}]
},
queryType: "semantic",
top: 3,
semanticSearchOptions: {
// your semantic configuration name
configurationName: "default",
}
});
// Add documents until you run out of tokens
let length = 0, output = '';
for await (const result of response.results) {
// Start a new doc
let doc = `${result.document.content}\n\n`;
let docLength = tokenizer.encode(doc).length;
const remainingTokens = maxTokens - (length + docLength);
if (remainingTokens <= 0) {
break;
}
// Append doc to output
output += doc;
length += docLength;
}
return { output, length, tooLong: length > maxTokens };
}
}
Ajouter d’autres API pour l’API personnalisée en tant que source de données
Suivez ces étapes pour étendre l’agent de moteur personnalisé à partir du modèle d’API personnalisée avec d’autres API.
Mettez à jour
./appPackage/apiSpecificationFile/openapi.*.Copiez la partie correspondante de l’API que vous souhaitez ajouter à partir de votre spécification et ajoutez à
./appPackage/apiSpecificationFile/openapi.*.Mettez à jour
./src/prompts/chat/actions.json.Mettez à jour les informations et les propriétés nécessaires pour le chemin, la requête et le corps de l’API dans l’objet suivant :
{ "name": "${{YOUR-API-NAME}}", "description": "${{YOUR-API-DESCRIPTION}}", "parameters": { "type": "object", "properties": { "query": { "type": "object", "properties": { "${{YOUR-PROPERTY-NAME}}": { "type": "${{YOUR-PROPERTY-TYPE}}", "description": "${{YOUR-PROPERTY-DESCRIPTION}}", } // You can add more query properties here } }, "path": { // Same as query properties }, "body": { // Same as query properties } } } }Mettez à jour
./src/adaptiveCards.Créez un fichier avec un nom
${{YOUR-API-NAME}}.jsonet renseignez la carte adaptative pour la réponse d’API de votre API.Mettez à jour le
./src/app/app.jsfichier.Ajoutez le code suivant avant
module.exports = app;:app.ai.action(${{YOUR-API-NAME}}, async (context: TurnContext, state: ApplicationTurnState, parameter: any) => { const client = await api.getClient(); const path = client.paths[${{YOUR-API-PATH}}]; if (path && path.${{YOUR-API-METHOD}}) { const result = await path.${{YOUR-API-METHOD}}(parameter.path, parameter.body, { params: parameter.query, }); const card = generateAdaptiveCard("../adaptiveCards/${{YOUR-API-NAME}}.json", result); await context.sendActivity({ attachments: [card] }); } else { await context.sendActivity("no result"); } return "result"; });
Microsoft 365 comme source de données
Découvrez comment utiliser l’API Recherche Microsoft Graph pour interroger du contenu Microsoft 365 en tant que source de données pour l’application RAG. Pour en savoir plus sur l’API Recherche Microsoft Graph, vous pouvez consulter utiliser l’API Recherche Microsoft pour rechercher du contenu OneDrive et SharePoint.
Prérequis : vous devez créer un client API Graph et lui accorder l’autorisation Files.Read.All d’accéder aux fichiers, dossiers, pages et actualités SharePoint et OneDrive.
Ingestion de données
L’API Recherche Microsoft Graph, qui peut rechercher du contenu SharePoint, est disponible. Par conséquent, vous devez uniquement vous assurer que votre document est chargé sur SharePoint ou OneDrive, sans aucune ingestion de données supplémentaire requise.
Remarque
SharePoint Server indexe un fichier uniquement si son extension de fichier est répertoriée sur la page Gérer les types de fichiers. Pour obtenir la liste complète des extensions de fichier prises en charge, reportez-vous aux extensions de nom de fichier indexées par défaut et aux types de fichiers analysés dans SharePoint Server et SharePoint dans Microsoft 365.
Implémentation de la source de données
Voici un exemple de recherche de fichiers texte dans SharePoint et OneDrive :
import {
DataSource,
Memory,
RenderedPromptSection,
Tokenizer,
} from "@microsoft/teams-ai";
import { TurnContext } from "botbuilder";
import { Client, ResponseType } from "@microsoft/microsoft-graph-client";
export class GraphApiSearchDataSource implements DataSource {
public readonly name = "my-datasource";
public readonly description =
"Searches the graph for documents related to the input";
public client: Client;
constructor(client: Client) {
this.client = client;
}
public async renderData(
context: TurnContext,
memory: Memory,
tokenizer: Tokenizer,
maxTokens: number
): Promise<RenderedPromptSection<string>> {
const input = memory.getValue("temp.input") as string;
const contentResults = [];
const response = await this.client.api("/search/query").post({
requests: [
{
entityTypes: ["driveItem"],
query: {
// Search for markdown files in the user's OneDrive and SharePoint
// The supported file types are listed here:
// https://learn.microsoft.com/sharepoint/technical-reference/default-crawled-file-name-extensions-and-parsed-file-types
queryString: `${input} filetype:txt`,
},
// This parameter is required only when searching with application permissions
// https://learn.microsoft.com/graph/search-concept-searchall
// region: "US",
},
],
});
for (const value of response?.value ?? []) {
for (const hitsContainer of value?.hitsContainers ?? []) {
contentResults.push(...(hitsContainer?.hits ?? []));
}
}
// Add documents until you run out of tokens
let length = 0,
output = "";
for (const result of contentResults) {
const rawContent = await this.downloadSharepointFile(
result.resource.webUrl
);
if (!rawContent) {
continue;
}
let doc = `${rawContent}\n\n`;
let docLength = tokenizer.encode(doc).length;
const remainingTokens = maxTokens - (length + docLength);
if (remainingTokens <= 0) {
break;
}
// Append do to output
output += doc;
length += docLength;
}
return { output, length, tooLong: length > maxTokens };
}
// Download the file from SharePoint
// https://docs.microsoft.com/en-us/graph/api/driveitem-get-content
private async downloadSharepointFile(
contentUrl: string
): Promise<string | undefined> {
const encodedUrl = this.encodeSharepointContentUrl(contentUrl);
const fileContentResponse = await this.client
.api(`/shares/${encodedUrl}/driveItem/content`)
.responseType(ResponseType.TEXT)
.get();
return fileContentResponse;
}
private encodeSharepointContentUrl(webUrl: string): string {
const byteData = Buffer.from(webUrl, "utf-8");
const base64String = byteData.toString("base64");
return (
"u!" + base64String.replace("=", "").replace("/", "_").replace("+", "_")
);
}
}