Notes
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
La reconnaissance optique de caractères (OCR) vous permet de localiser et d’extraire du texte à partir d’images ou de l’écran.
Bien que la plupart des scénarios exigent que vous manipuliez du texte dans une langue spécifique, il existe des cas où les sources sont multilingues.
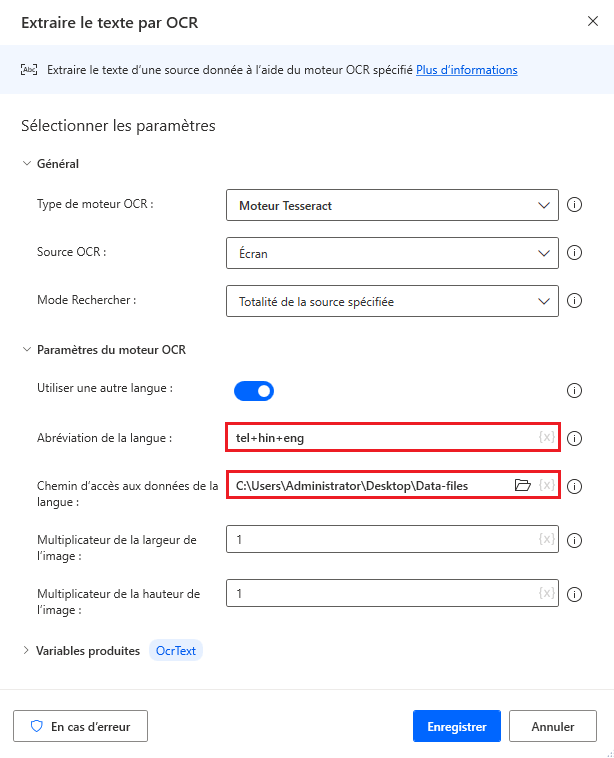
Pour effectuer l’OCR sur ces sources, utilisez un moteur Tesseract dans l’action OCR respective et activez l’option Utiliser une autre langue dans les paramètres du moteur.
Quand l’option Utiliser une autre langue est activée, l’action affiche deux paramètres supplémentaires : le champ Abréviation de la langue et le champ Chemin d’accès aux données de la langue.
Le champ Abréviation de la langue indique au moteur quelle langue rechercher lors de l’OCR. Le champ Chemin d’accès aux données de la langue contient les fichiers de données de langue (.traineddata) utilisés pour entraîner le moteur OCR.
Après avoir téléchargé les fichiers de données pour les langues nécessaires, déplacez-les vers un dossier commun pour les rendre disponibles sous le même chemin.
Ensuite, sélectionnez le dossier créé dans le champ Chemin d’accès aux données de la langue et renseignez les codes de langue correspondants dans le champ Abréviation de la langue. Pour séparer les codes de langue, utilisez le caractère plus (+).
Note
Vous pouvez trouver tous les codes de langue disponibles dans la source des fichiers de données de langue. Dans l’exemple suivant, les codes utilisés représentent le telugu, l’hindi et l’anglais.