Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Les modèles sémantiques d’une capacité Premium avec le point de terminaison XMLA activé pour les opérations de lecture/écriture autorisent une actualisation, une gestion des partitions et des métadonnées plus avancées uniquement par le biais d’outils, de scripts et de prise en charge des API. En outre, les opérations d’actualisation via le point de terminaison XMLA ne sont pas limitées à 48 actualisations par jour et la limite de temps d’actualisation planifiée n’est pas imposée.
Partitions
Les partitions de table de modèle sémantique ne sont pas visibles et ne peuvent pas être gérées à l’aide de Power BI Desktop ou du service Power BI. Pour les modèles d’un espace de travail affecté à une capacité Premium, les partitions peuvent être gérées via le point de terminaison XMLA. Vous pouvez utiliser des outils tels que SQL Server Management Studio (SSMS) ou l’éditeur tabulaire open source pour gérer les partitions via des scripts avec tmSL (Tabular Model Scripting Language) et par programmation avec le modèle objet tabulaire (TOM).
Lorsque vous publiez d’abord un modèle sur le service Power BI, chaque table du nouveau modèle comporte une partition. Pour les tables sans stratégie d’actualisation incrémentielle, qu’une partition contient toutes les lignes de données de cette table, sauf si des filtres sont appliqués. Pour les tables avec une stratégie d’actualisation incrémentielle, il n’existe qu’une seule partition initiale, car Power BI n’a pas encore appliqué la stratégie. Vous configurez la partition initiale dans Power BI Desktop lorsque vous définissez le filtre de plage de date/heure de votre table en fonction des paramètres RangeStart et des autres filtres appliqués dans l’éditeur Power Query. Cette partition initiale contient uniquement les lignes de données qui répondent à vos critères de filtre.
Lorsque vous effectuez la première opération d’actualisation, les tables sans stratégie d’actualisation incrémentielle actualisent toutes les lignes contenues dans la partition unique par défaut de cette table. Pour les tables avec une stratégie d’actualisation incrémentielle, les partitions d’actualisation et d’historique sont automatiquement créées et les lignes sont chargées en fonction de la date/heure de chaque ligne. Si la stratégie d’actualisation incrémentielle inclut l’obtention de données en temps réel, Power BI ajoute également une partition DirectQuery à la table.
Important
Lorsque vous utilisez l’actualisation incrémentielle avec des données en temps réel (mode hybride), les tables associées à la table hybride doivent utiliser le mode de stockage double pour éviter les pénalités de performances. En outre, la mise en cache visuelle peut retarder les mises à jour en direct jusqu’à ce que les visuels réinterrogent les données. Pour plus d’informations, consultez Résoudre les problèmes d’actualisation incrémentielle et de données en temps réel.
Cette première opération d’actualisation peut prendre un certain temps en fonction de la quantité de données qui doivent être chargées à partir de la source de données. La complexité du modèle peut également être un facteur significatif, car les opérations d’actualisation doivent effectuer davantage de traitement et de recalcul. Cette opération peut être auto-initialisée. Pour plus d’informations, consultez Empêcher les temps d'attente pendant la première actualisation complète.
Les partitions sont créées et nommées par granularité de période : années, trimestres, mois et jours. Les partitions les plus récentes, appelées partitions d’actualisation, contiennent des lignes pour la période d’actualisation que vous avez spécifiée dans votre politique. Les partitions historiques contiennent des lignes par période complète jusqu’à la période d’actualisation. Si le temps réel est activé, une partition DirectQuery récupère toutes les modifications de données qui se sont produites après la date de fin de la période d’actualisation. La granularité des partitions de rafraîchissement et historique dépend des périodes de rafraîchissement et de stockage historique que vous choisissez lors de la définition de la politique.
Par exemple, si la date d’aujourd’hui est le 2 février 2021 et que notre table FactInternetSales à la source de données contient des lignes jusqu’à aujourd’hui, si notre stratégie spécifie d’inclure des modifications en temps réel, d’actualiser les lignes dans la dernière période d’actualisation d’un jour et de stocker des lignes au cours des trois dernières années d’historique. Ensuite, avec la première opération d’actualisation, une partition DirectQuery est créée pour les modifications à l’avenir. Une nouvelle partition d’importation est créée pour les lignes d’aujourd’hui et une partition historique est créée pour hier, une période entière, le 1er février 2021. Une partition historique est créée pour la période du mois entier précédent (janvier 2021). Une partition historique est créée pour l’année entière précédente (2020). Et les partitions historiques pour les périodes complètes de 2019 et 2018 sont créées. Aucune partition de trimestre entier n’est créée car le 2 février, le premier trimestre complet de 2021 n’est pas encore terminé.
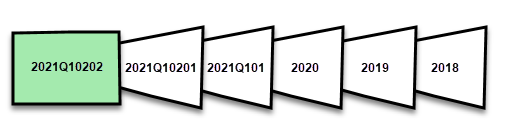
Avec chaque opération d’actualisation, seules les partitions de la période d’actualisation sont actualisées. Le filtre de date de la partition DirectQuery est mis à jour pour inclure uniquement les modifications qui se produisent après la période d’actualisation actuelle. Une nouvelle partition d’actualisation est créée pour les nouvelles lignes avec une nouvelle date/heure dans la période d’actualisation mise à jour. Les lignes existantes qui ont déjà une date/heure dans les partitions existantes pendant la période d’actualisation sont mises à jour. Les lignes dont la date/heure est antérieure à la période d’actualisation ne sont plus actualisées.
Lorsque des périodes complètes se terminent, les partitions sont fusionnées. Par exemple, si une période d'actualisation d'un jour et une période de conservation historique de trois ans sont spécifiées dans la politique, le premier jour du mois, toutes les partitions journalières du mois précédent sont fusionnées en une partition mensuelle. Le premier jour d’un nouveau trimestre, les trois partitions du mois précédent sont fusionnées dans une partition de trimestre. Le premier jour d’une nouvelle année, les quatre partitions du trimestre précédent sont fusionnées dans une partition d’année.
Un modèle conserve toujours les partitions pour l’ensemble de la période de magasin historique ainsi que toutes les partitions de la période jusqu'à la période d’actualisation actuelle. Dans l’exemple, une durée complète de trois ans de données historiques est conservée dans des partitions pour 2018, 2019, 2020, et également des partitions pour la période mensuelle 2021Q101, la période journalière 2021Q10201, et la partition de la période d'actualisation du jour actuel. Étant donné que l’exemple conserve les données historiques pendant trois ans, la partition 2018 est conservée jusqu’à la première actualisation le 1er janvier 2022.
Avec l’actualisation progressive Power BI et les données en temps réel, le service gère la gestion des partitions pour vous en fonction de la stratégie. Bien que le service puisse gérer toute la gestion des partitions pour vous, à l’aide d’outils via le point de terminaison XMLA, vous pouvez actualiser de manière sélective des partitions individuellement, séquentiellement ou en parallèle.
Modèles d’actualisation de partition courants
Lorsque vous utilisez des opérations de point de terminaison XMLA, tenez compte des modèles courants suivants pour la gestion des opérations d’actualisation :
- Actualisations fréquentes : exécutez plusieurs opérations d’actualisation ciblées de petite taille pendant les heures d’activité à l’aide de commandes de partition XMLA ou de l’API REST améliorée pour conserver les données récentes en cours sans traiter l’intégralité de la table.
-
Retours historiques sélectifs : effectuez des actualisations de partition historique plus volumineuses ou des corrections de données ponctuelles pendant les heures creuses à l’aide de TMSL avec
applyRefreshPolicy: falsepour reconstruire des périodes historiques spécifiques sans affecter le comportement de la stratégie automatique. - Chargements initiaux par étapes : Pour les longues périodes historiques, fractionnez l'actualisation initiale en plus petits lots en traitant les partitions de manière incrémentielle pour éviter les dépassements de délai et gérer efficacement la consommation des ressources.
Ces modèles vous permettent d’équilibrer la fraîcheur des données en temps réel avec les contraintes de performances système et de ressources.
Actualiser la gestion avec SQL Server Management Studio
SQL Server Management Studio (SSMS) peut être utilisé pour afficher et gérer les partitions créées par l’application de stratégies d’actualisation incrémentielle. En utilisant SSMS, vous pouvez, par exemple, actualiser une partition historique spécifique en dehors de la période d'actualisation incrémentielle pour effectuer une mise à jour rétroactive sans avoir à actualiser toutes les données historiques. SSMS peut également être utilisé lors de l’amorçage pour charger des données historiques pour les modèles volumineux en ajoutant/actualisant incrémentiellement des partitions historiques dans des lots.
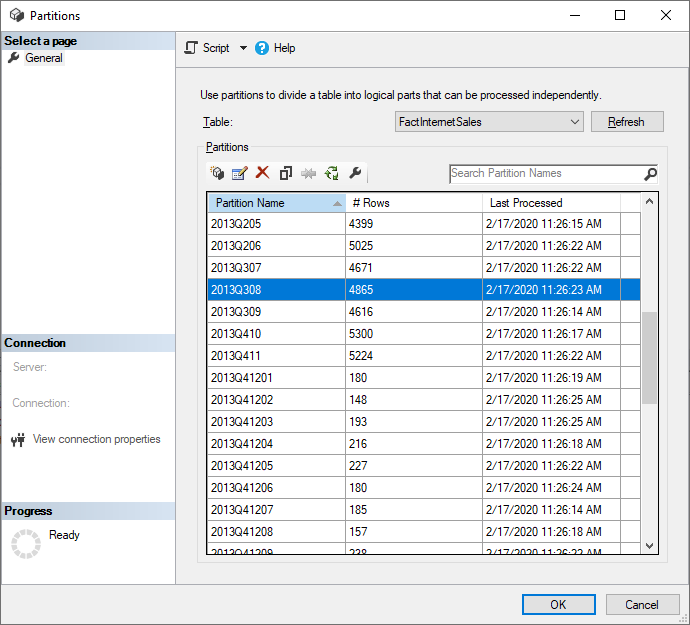
Remplacer le comportement d’actualisation incrémentielle
Avec SSMS, vous avez également plus de contrôle sur l’appel des actualisations à l’aide du langage de script de modèle tabulaire et du modèle objet tabulaire. Par exemple, dans SSMS, dans l’Explorateur d’objets, cliquez avec le bouton droit sur une table, puis sélectionnez l’option de menu Traiter le tableau , puis sélectionnez le bouton Script pour générer une commande d’actualisation TMSL.
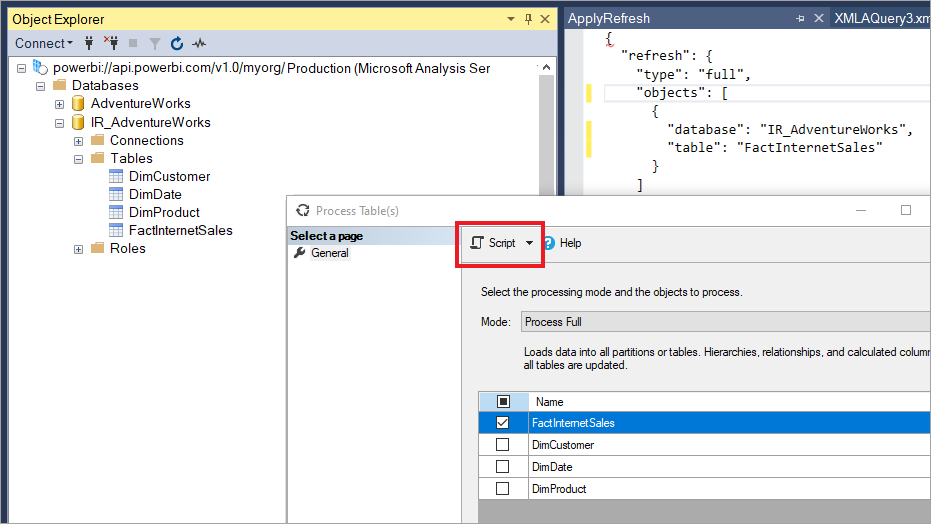
Ces paramètres peuvent être utilisés avec la commande d’actualisation TMSL pour remplacer le comportement d’actualisation incrémentielle par défaut :
applyRefreshPolicy. Si une table a une stratégie d’actualisation incrémentielle définie,
applyRefreshPolicydétermine si la stratégie est appliquée ou non. Si la stratégie n’est pas appliquée, une opération complète de processus laisse les définitions de partition inchangées et toutes les partitions de la table sont entièrement actualisées. La valeur par défaut est true.effectiveDate. Si une stratégie d’actualisation incrémentielle est appliquée, elle doit connaître la date actuelle afin de déterminer les plages de fenêtres mobiles pour les actualisations incrémentielles et les périodes historiques. Le
effectiveDateparamètre vous permet de remplacer la date actuelle. Ce paramètre est utile pour les tests, les démonstrations et les scénarios métier où les données sont actualisées de manière incrémentielle jusqu’à une date dans le passé ou à l’avenir, par exemple, des budgets à l’avenir. La valeur par défaut est la date actuelle.
{
"refresh": {
"type": "full",
"applyRefreshPolicy": true,
"effectiveDate": "12/31/2013",
"objects": [
{
"database": "IR_AdventureWorks",
"table": "FactInternetSales"
}
]
}
}
Pour en savoir plus sur la substitution du comportement d’actualisation incrémentielle par défaut avec TMSL, consultez commande Actualiser.
Gestion des stratégies avec l’éditeur tabulaire
Outre SSMS, vous pouvez utiliser l’éditeur tabulaire pour créer et modifier des stratégies d’actualisation incrémentielle directement sur des modèles sémantiques via le point de terminaison XMLA. Cette méthode vous permet d’ajuster les paramètres de stratégie, tels que les périodes d’actualisation, les périodes historiques et les expressions sources, sans avoir à republier le modèle à partir de Power BI Desktop. L'éditeur tabulaire peut également être utilisé pour appliquer des stratégies d’actualisation à des tables existantes et gérer les expressions de paramètre RangeStart et RangeEnd. Pour plus d’informations, consultez l’actualisation incrémentielle dans la documentation de l’éditeur tabulaire.
Actualiser l’orchestration et l’automatisation
Au-delà de l’utilisation de SSMS, TMSL et TOM pour la gestion des actualisations via le point de terminaison XMLA. Vous pouvez également orchestrer des opérations d’actualisation de modèle sémantique à l’aide de l’API REST Power BI. L’API d’actualisation améliorée offre davantage de fonctionnalités, notamment l’actualisation au niveau de la table et au niveau de la partition, la logique de nouvelle tentative, l’annulation et la gestion du délai d’attente personnalisé. Cette approche est utile pour intégrer des opérations d’actualisation dans des flux de travail automatisés et des pipelines CI/CD. Pour obtenir des instructions détaillées, consultez Actualisation améliorée avec l’API REST Power BI.
Garantir des performances optimales
Avec chaque opération d’actualisation, le service Power BI peut envoyer des requêtes d’initialisation à la source de données pour chaque partition d’actualisation incrémentielle. Vous pouvez peut-être améliorer les performances d’actualisation incrémentielle en réduisant le nombre de requêtes d’initialisation en garantissant la configuration suivante :
- La table pour laquelle vous configurez l’actualisation incrémentielle doit obtenir des données à partir d’une seule source de données. Si la table obtient des données de plusieurs sources de données, le nombre de requêtes envoyées par le service pour chaque opération d’actualisation est multiplié par le nombre de sources de données, ce qui peut réduire les performances d’actualisation. Vérifiez que la requête de la table d’actualisation incrémentielle concerne une seule source de données.
- Pour les solutions avec l’actualisation incrémentielle des partitions d’importation et des données en temps réel avec Direct Query, toutes les partitions doivent interroger des données à partir d’une seule source de données.
- Si vos exigences de sécurité autorisent, définissez le paramètre de niveau de confidentialité de la source de données sur Organisation ou Public. Par défaut, le niveau de confidentialité est privé. Toutefois, ce niveau peut empêcher l’échange de données avec d’autres sources cloud. Pour définir le niveau de confidentialité, sélectionnez le menu Autres options, puis choisissez Paramètres des>informations d’identification de la source de donnéesModifier le paramètre de niveau confidentialité> informations d’identification >pour cette source de données. Si le niveau de confidentialité est défini dans le modèle Power BI Desktop avant la publication sur le service, il n’est pas transféré au service lorsque vous publiez. Vous devez toujours le définir dans les paramètres de modèle sémantique dans le service. Pour en savoir plus, consultez les niveaux de confidentialité.
- Si vous utilisez une passerelle de données locale, veillez à utiliser la version 3000.77.3 ou ultérieure.
Empêcher les time-outs lors de l'actualisation complète initiale
Après avoir publié sur le service Power BI, l’opération d’actualisation complète initiale pour le modèle crée des partitions pour la table d’actualisation incrémentielle, charge et traite les données historiques pendant toute la période définie dans la stratégie d’actualisation incrémentielle. Pour certains modèles qui chargent et traitent de grandes quantités de données, la durée pendant laquelle l’opération d’actualisation initiale prend peut dépasser la limite de temps d’actualisation imposée par le service ou une limite de temps de requête imposée par la source de données.
Le démarrage de l’opération d’actualisation initiale permet au service de créer des objets de partition pour la table d’actualisation incrémentielle, mais pas de charger et de traiter les données historiques dans l’une des partitions. SSMS est ensuite utilisé pour traiter sélectivement les partitions. Selon la quantité de données à charger pour chaque partition, vous pouvez traiter chaque partition de manière séquentielle ou en petits lots. Cette méthode réduit le risque pour une ou plusieurs de ces partitions d’entraîner un délai d’expiration. Les méthodes suivantes fonctionnent pour n’importe quelle source de données.
Appliquer la stratégie d’actualisation
L’outil Éditeur tabulaire open source 2 offre un moyen simple de démarrer une opération d’actualisation initiale. Après avoir publié un modèle avec une stratégie d’actualisation incrémentielle définie pour celle-ci de Power BI Desktop au service, connectez-vous au modèle à l’aide du point de terminaison XMLA en mode Lecture/écriture. Exécutez Appliquer la stratégie de rafraîchissement sur la table de rafraîchissement incrémentiel. Avec uniquement la stratégie appliquée, les partitions sont créées, mais aucune donnée n’est chargée. Connectez-vous ensuite avec SSMS pour actualiser les partitions séquentiellement ou par lots pour charger et traiter les données. Pour plus d’informations, consultez Actualisation incrémentielle dans la documentation de l’éditeur tabulaire.
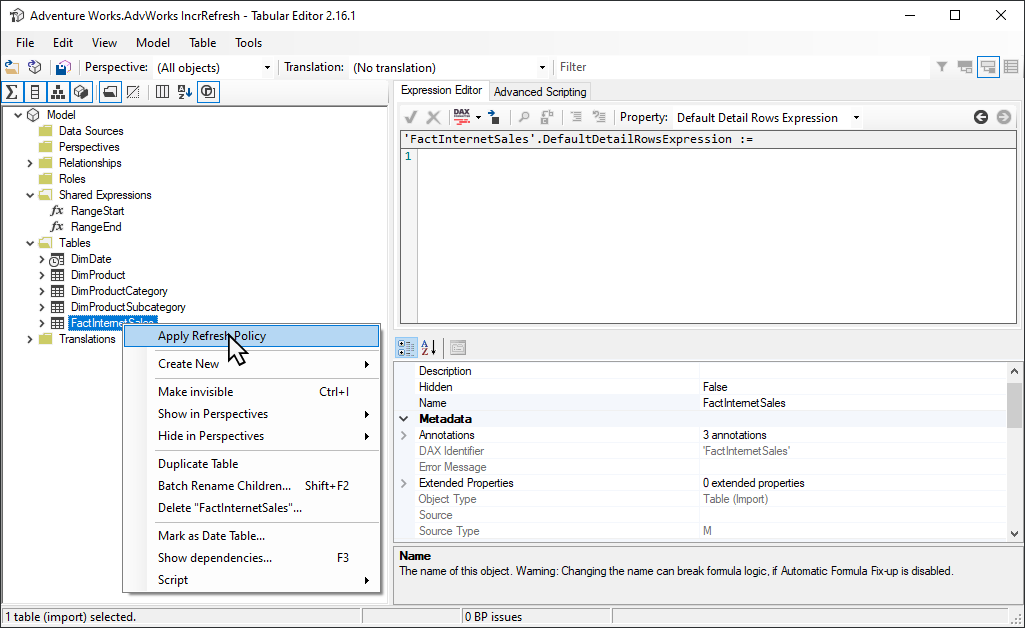
Filtre Power Query pour les partitions vides
Avant de publier le modèle sur le service, dans l'Éditeur Power Query, ajoutez un autre filtre à la colonne ProductKey qui exclut toute valeur autre que 0, de manière à filtrer efficacement toutes les données de la table FactInternetSales.
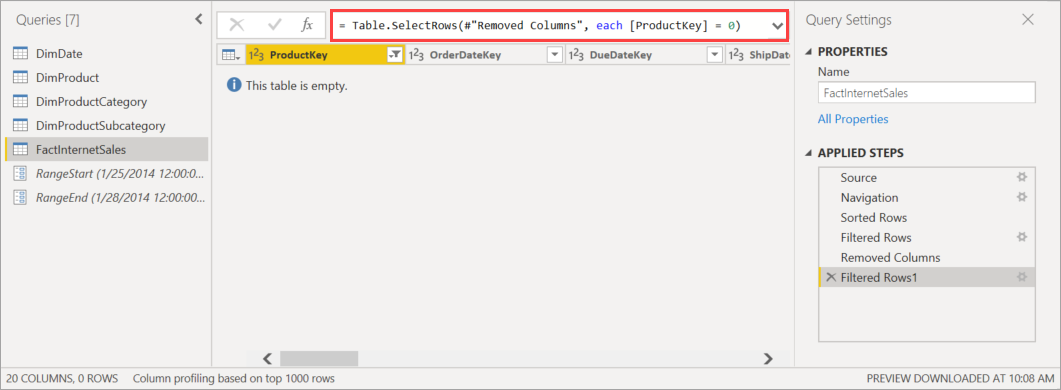
Après avoir sélectionné Fermer &Appliquer dans l’Éditeur Power Query, définir la stratégie d’actualisation incrémentielle et enregistrer le modèle, le modèle est publié sur le service. Depuis le service, l’opération d’actualisation initiale est exécutée sur le modèle. Les partitions de la table FactInternetSales sont créées en fonction de la stratégie, mais aucune donnée n’est chargée et traitée, car toutes les données sont filtrées.
Une fois l’opération d’actualisation initiale terminée, dans l’Éditeur Power Query, l’autre filtre de la ProductKey colonne est supprimé. Après avoir sélectionné Fermer & Appliquer dans l’Éditeur Power Query et enregistré le modèle, le modèle n’est plus publié. Si le modèle est à nouveau publié, il remplace les paramètres de stratégie d’actualisation incrémentielle et force une actualisation complète sur le modèle lorsqu’une opération d’actualisation ultérieure est effectuée à partir du service. Au lieu de cela, effectuez un déploiement de métadonnées uniquement à l’aide du Kit de ressources ALM (Application Lifecycle Management) qui supprime le filtre sur la ProductKey colonne du modèle. SSMS peut ensuite être utilisé pour traiter sélectivement les partitions. Lorsque toutes les partitions sont entièrement traitées, qui doivent inclure un recalcul de processus sur toutes les partitions, à partir de SSMS, les opérations d’actualisation suivantes sur le modèle à partir du service actualisent uniquement les partitions d’actualisation incrémentielle.
Conseil / Astuce
Veillez à consulter des vidéos, des blogs et plus encore fournis par la communauté d’experts de Power BI.
Pour en savoir plus sur le traitement des tables et des partitions à partir de SSMS, consultez Traiter la base de données, la table ou les partitions (Analysis Services). Pour en savoir plus sur le traitement des modèles, des tables et des partitions à l’aide de TMSL, consultez la commande Refresh (TMSL).
Requêtes personnalisées pour détecter les modifications de données
TMSL et TOM peuvent être utilisés pour remplacer le comportement des modifications de données détectées. Cette méthode peut être utilisée pour éviter la persistance de la colonne de dernière mise à jour dans le cache en mémoire. Il peut également activer des scénarios où une table de configuration ou d’instructions est préparée par des processus d’extraction, de transformation et de chargement (ETL). Vous permettant d’marquer uniquement les partitions qui doivent être actualisées. Cette méthode peut créer un processus d’actualisation incrémentielle plus efficace où seules les périodes requises sont actualisées, quelle que soit la durée pendant laquelle les mises à jour des données ont eu lieu.
L'élément pollingExpression est destiné à être une expression M légère ou le nom d'une autre requête M. Elle doit retourner une valeur scalaire et est exécutée pour chaque partition. Si la valeur retournée est différente de ce qu’elle était la dernière fois qu’une actualisation incrémentielle s’est produite, la partition est marquée pour un traitement complet.
L’exemple suivant couvre les 120 mois de la période historique pour les modifications rétroactives. La spécification de 120 mois au lieu de 10 ans signifie que la compression des données peut ne pas être aussi efficace. Toutefois, il évite d’avoir à actualiser une année historique entière, ce qui serait plus coûteux lorsqu’un mois serait suffisant pour un changement rétroactif.
"refreshPolicy": {
"policyType": "basic",
"rollingWindowGranularity": "month",
"rollingWindowPeriods": 120,
"incrementalGranularity": "month",
"incrementalPeriods": 120,
"pollingExpression": "<M expression or name of custom polling query>",
"sourceExpression": [
"let ..."
]
}
Conseil / Astuce
Veillez à consulter des vidéos, des blogs et plus encore fournis par la communauté d’experts de Power BI.
Déploiement des métadonnées uniquement
Lorsque vous publiez une nouvelle version d’un fichier .pbix à partir de Power BI Desktop dans un espace de travail. Vous voyez l’invite suivante pour remplacer le modèle existant, si un modèle portant le même nom existe déjà.
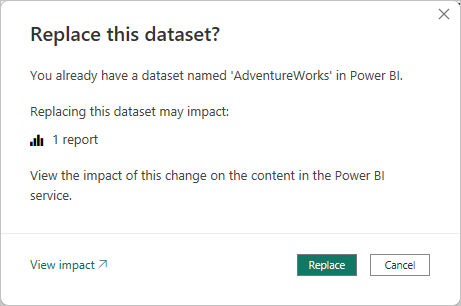
Dans certains cas, vous ne souhaiterez peut-être pas remplacer le modèle, surtout lors d'une actualisation incrémentielle. Le modèle dans Power BI Desktop peut être considérablement plus petit que celui du service Power BI. Si le modèle dans le service Power BI a une stratégie d’actualisation incrémentielle appliquée, vous risquez de perdre plusieurs années de données historiques si le modèle est remplacé. L’actualisation de toutes les données historiques peut prendre des heures et entraîner un temps d’arrêt système pour les utilisateurs.
Au lieu de cela, il est préférable d’effectuer un déploiement de métadonnées uniquement, ce qui permet le déploiement de nouveaux objets sans perdre les données historiques. Par exemple, si vous ajoutez uniquement quelques mesures, vous pouvez déployer uniquement les nouvelles mesures sans avoir à actualiser les données, ce qui permet de gagner du temps.
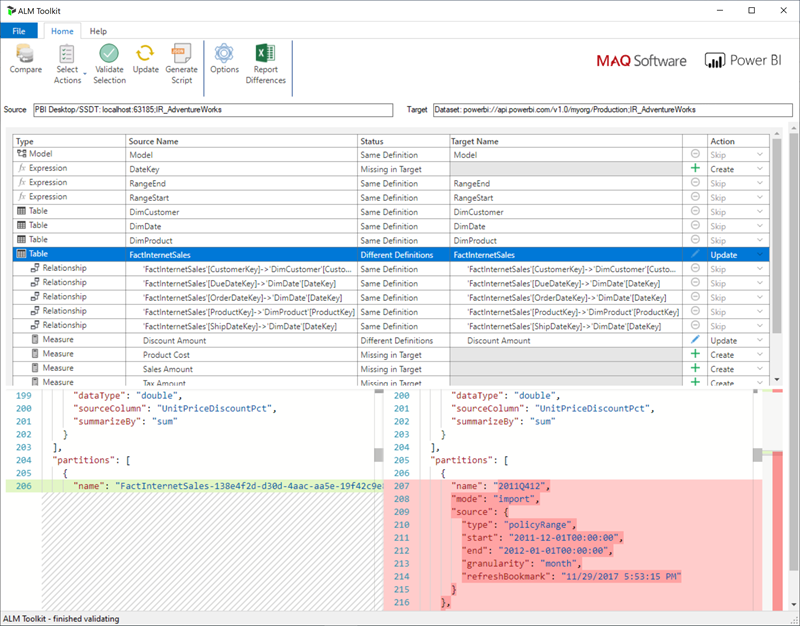
Pour les espaces de travail affectés à une capacité Premium configurée pour le point de terminaison XMLA en lecture/écriture, les outils compatibles activent uniquement le déploiement des métadonnées. Par exemple, l'ALM Toolkit est un outil de comparaison de schémas pour les modèles Power BI et peut être utilisé pour effectuer uniquement le déploiement de métadonnées.
Téléchargez et installez la dernière version du kit de ressources ALM à partir du dépôt Git Analysis Services. Les instructions pas à pas sur l’utilisation de ALM Toolkit ne sont pas incluses dans la documentation Microsoft. Les liens de documentation de ALM Toolkit et des informations sur la prise en charge sont disponibles sur le ruban d’aide . Pour effectuer un déploiement de métadonnées uniquement, effectuez une comparaison et sélectionnez l’instance Power BI Desktop en cours d’exécution comme source et le modèle existant dans le service Power BI comme cible. Tenez compte des différences affichées et ignorez la mise à jour de la table avec des partitions d'actualisation incrémentielle ou utilisez la boîte de dialogue Options pour conserver les partitions lors des mises à jour de la table. Validez la sélection pour garantir l’intégrité du modèle cible, puis mettez à jour.
Ajout d’une stratégie d’actualisation incrémentielle et de données en temps réel par programmation
Vous pouvez également utiliser TMSL et TOM pour ajouter une stratégie d’actualisation incrémentielle à un modèle existant via le point de terminaison XMLA.
Note
Pour éviter les problèmes de compatibilité, veillez à utiliser la dernière version des bibliothèques clientes Analysis Services. Par exemple, pour utiliser des stratégies hybrides, la version doit être 19.27.1.8 ou ultérieure.
Le processus comprend les étapes suivantes :
Vérifiez que le modèle cible a le niveau de compatibilité minimal requis. Dans SSMS, cliquez avec le bouton droit sur [nom du modèle]>, puis sur Propriétés>, et enfin sur Niveau de compatibilité. Pour augmenter le niveau de compatibilité, utilisez un script TMSL createOrReplace ou vérifiez l’exemple de code TOM suivant pour obtenir un exemple.
a. Import policy - 1550 b. Hybrid policy - 1565Ajoutez le paramètre
RangeStartet le paramètreRangeEndà l'expression de modèle. Si nécessaire, ajoutez également une fonction pour convertir les valeurs Date/Heure en clés de date.Définissez un objet
RefreshPolicyavec l'archivage souhaité (fenêtre glissante) et les périodes d'actualisation incrémentielle, ainsi qu'une expression source qui filtre la table cible en fonction des paramètresRangeStartetRangeEnd. Définissez le mode de stratégie d’actualisation sur Importer ou Hybride en fonction de vos besoins en données en temps réel. L’hybride entraîne l’ajout d’une partition DirectQuery à la table pour récupérer les dernières modifications de la source de données qui se sont produites après le moment de la dernière actualisation.Ajoutez la stratégie d’actualisation à la table et effectuez une actualisation complète afin que Power BI partitionne la table en fonction de vos besoins.
L’exemple de code suivant montre comment effectuer les étapes précédentes à l’aide de TOM. Si vous souhaitez utiliser cet exemple tel quel, vous devez avoir une copie pour la base de données AdventureWorksDW et importer la table FactInternetSales dans un modèle. L’exemple de code part du principe que les RangeStart paramètres et RangeEnd la DateKey fonction n’existent pas dans le modèle. Importez simplement la table FactInternetSales et publiez le modèle dans un espace de travail sur Power BI Premium. Mettez ensuite à jour l’exemple workspaceUrl de code afin que l’exemple de code puisse se connecter à votre modèle. Mettez à jour d’autres lignes de code si nécessaire.
using System;
using TOM = Microsoft.AnalysisServices.Tabular;
namespace Hybrid_Tables
{
class Program
{
static string workspaceUrl = "<Enter your Workspace URL here>";
static string databaseName = "AdventureWorks";
static string tableName = "FactInternetSales";
static void Main(string[] args)
{
using (var server = new TOM.Server())
{
// Connect to the dataset.
server.Connect(workspaceUrl);
TOM.Database database = server.Databases.FindByName(databaseName);
if (database == null)
{
throw new ApplicationException("Database cannot be found!");
}
if(database.CompatibilityLevel < 1565)
{
database.CompatibilityLevel = 1565;
database.Update();
}
TOM.Model model = database.Model;
// Add RangeStart, RangeEnd, and DateKey function.
model.Expressions.Add(new TOM.NamedExpression {
Name = "RangeStart",
Kind = TOM.ExpressionKind.M,
Expression = "#datetime(2021, 12, 30, 0, 0, 0) meta [IsParameterQuery=true, Type=\"DateTime\", IsParameterQueryRequired=true]"
});
model.Expressions.Add(new TOM.NamedExpression
{
Name = "RangeEnd",
Kind = TOM.ExpressionKind.M,
Expression = "#datetime(2021, 12, 31, 0, 0, 0) meta [IsParameterQuery=true, Type=\"DateTime\", IsParameterQueryRequired=true]"
});
model.Expressions.Add(new TOM.NamedExpression
{
Name = "DateKey",
Kind = TOM.ExpressionKind.M,
Expression =
"let\n" +
" Source = (x as datetime) => Date.Year(x)*10000 + Date.Month(x)*100 + Date.Day(x)\n" +
"in\n" +
" Source"
});
// Apply a RefreshPolicy with Real-Time to the target table.
TOM.Table salesTable = model.Tables[tableName];
TOM.RefreshPolicy hybridPolicy = new TOM.BasicRefreshPolicy
{
Mode = TOM.RefreshPolicyMode.Hybrid,
IncrementalPeriodsOffset = -1,
RollingWindowPeriods = 1,
RollingWindowGranularity = TOM.RefreshGranularityType.Year,
IncrementalPeriods = 1,
IncrementalGranularity = TOM.RefreshGranularityType.Day,
SourceExpression =
"let\n" +
" Source = Sql.Database(\"demopm.database.windows.net\", \"AdventureWorksDW\"),\n" +
" dbo_FactInternetSales = Source{[Schema=\"dbo\",Item=\"FactInternetSales\"]}[Data],\n" +
" #\"Filtered Rows\" = Table.SelectRows(dbo_FactInternetSales, each [OrderDateKey] >= DateKey(RangeStart) and [OrderDateKey] < DateKey(RangeEnd))\n" +
"in\n" +
" #\"Filtered Rows\""
};
salesTable.RefreshPolicy = hybridPolicy;
model.RequestRefresh(TOM.RefreshType.Full);
model.SaveChanges();
}
Console.WriteLine("{0}{1}", Environment.NewLine, "Press [Enter] to exit...");
Console.ReadLine();
}
}
}
Contenu connexe
- Configurer l’actualisation incrémentielle et les données en temps réel
- Résoudre les problèmes d’actualisation incrémentielle et de données en temps réel
- Actualisation améliorée avec l’API REST Power BI
- Partitions dans les modèles tabulaires
- Outils externes dans Power BI Desktop
- Configurer une actualisation planifiée