Échantillonnage à haute densité dans les nuages de points Power BI
L’algorithme d’échantillonnage Power BI améliore la façon dont les nuages de points représentent des données à haute densité.
Vous pouvez par exemple créer un nuage de points à partir de l’activité de ventes de votre organisation, chaque magasin ayant des dizaines de milliers de points de données chaque année. Un nuage de points formé en se basant sur ces informations échantillonne les données à partir d’une représentation explicite de ces données pour illustrer l’évolution des ventes au fil du temps. Les détails de l’échantillonnage des données à haute densité sont décrits dans cet article.

Remarque
L’algorithme Échantillonnage à haute densité décrit dans cet article est disponible dans les nuages de points pour Power BI Desktop et pour le service Power BI.
Fonctionnement des nuages de points à haute densité
Auparavant, Power BI sélectionnait une collection de points de données échantillons dans la plage complète des données sous-jacentes de manière déterministe afin de créer un nuage de points. Plus précisément, Power BI sélectionnait la première et la dernière ligne de données dans la série utilisée pour produire le nuage de points, puis divisait uniformément les lignes restantes de façon à ce qu’un total de 3 500 points de données soient représentés sur le nuage de points. Par exemple, si l’échantillon comptait 35 000 lignes, les première et dernière lignes étaient sélectionnées pour le traçage, puis chaque dixième ligne était également tracée (35 000 / 10 = chaque dixième ligne = 3 500 points de données). En outre, auparavant, les valeurs ou points nuls qui ne pouvaient pas être tracés, comme les valeurs de texte, dans une série de données n’étaient pas affichés et ils étaient donc ignorés lors de la génération du visuel. Avec ce type d’échantillonnage, la densité perçue du nuage de points était également basée sur les points de données représentatifs, de sorte que la densité du visuel obtenu dépendait des points échantillonnés, et non pas de la collection complète des données sous-jacentes.
Quand vous activez l’option Échantillonnage à haute densité, Power BI implémente un algorithme qui élimine les points se chevauchant et garantit ainsi que les points du visuel restent accessibles lors de l’interaction. L’algorithme garantit également que tous les points du jeu de données sont représentés dans le visuel, ce qui fournit un contexte pour comprendre la signification des points sélectionnés, au lieu de tracer seulement un échantillon représentatif.
Par définition, les données à haute densité sont échantillonnées pour créer des visualisations qui réagissent à l’interactivité. Trop de points de données sur un visuel peuvent le ralentir et nuire à la visibilité des tendances. La façon dont les données sont échantillonnées détermine la création de l’algorithme d’échantillonnage pour offrir une expérience de visualisation optimale et garantir que toutes les données sont représentées. Dans Power BI, l’algorithme est amélioré afin de fournir une combinaison optimale de réactivité, de représentation et de préservation claire des points importants de la totalité du jeu de données.
Notes
Les nuages de points utilisant l’algorithme Échantillonnage à haute densité sont tracés de façon optimale sur des visuels carrés, comme c’est le cas de tous les nuages de points.
Fonctionnement de l’algorithme d’échantillonnage de nuages de points
L’algorithme Échantillonnage à haute densité utilisé pour la génération des nuages de points utilise des méthodes qui capturent et représentent les données sous-jacentes plus efficacement. Il élimine les points qui se chevauchent. L’algorithme commence par un petit rayon pour chaque point de données de la taille de cercle du visuel pour un point donné sur la visualisation. Il augmente ensuite le rayon de l’ensemble des points de données. En cas de chevauchement de points de données, un cercle unique de la taille de rayon accrue représente les points de données qui se chevauchent. L’algorithme continue d’augmenter le rayon des points de données, jusqu’à ce que la taille de celui-ci permette d’afficher un nombre raisonnable de points de données (3 500) dans le nuage de points.
Les méthodes utilisées dans cet algorithme veillent que les valeurs hors norme soient représentées dans le visuel final. L’algorithme respecte également l’échelle lors de la détermination du chevauchement. Par exemple, les échelles exponentielles reflètent fidèlement les points de données sous-jacents visualisés.
L’algorithme conserve également la forme globale du nuage de points.
Notes
Quand vous utilisez l’algorithme Échantillonnage à haute densité pour des nuages de points, l’objectif est la distribution exacte des données, et non la densité du visuel obtenu. Par exemple, vous pouvez voir un nuage de points contenant un grand nombre de cercles qui se chevauchent (densité importante) dans une certaine zone et imaginer que de nombreux points de données y sont agglutinés. Étant donné que l’algorithme Échantillonnage à haute densité peut utiliser un cercle pour représenter de nombreux points de données, ce type de densité visuelle implicite ou « clustering » n’apparaît pas. Pour afficher plus de détails dans une zone donnée, vous pouvez utiliser des segments pour effectuer un zoom avant.
Par ailleurs, les points de données qui ne peuvent pas être tracés, comme les valeurs nulles ou des valeurs de texte, étant ignorés, une autre valeur traçable est sélectionnée. Cela garantit la conservation de la forme réelle du nuage de points.
Quand l’algorithme standard est utilisé pour les nuages de points
Dans certaines circonstances, l’algorithme Échantillonnage à haute densité ne peut pas être appliqué à un nuage de points. L’algorithme d’origine est alors utilisé. Ces circonstances sont les suivantes :
Si vous cliquez sur une valeur sous Valeurs et que vous la définissez sur Afficher les éléments sans données dans le menu, le nuage de points revient à l’algorithme d’origine.
Toute valeur dans le champ Axe de lecture a pour effet que le nuage de points revient à l’algorithme d’origine.
Si les deux axes, X et Y, sont manquants sur un nuage de points, le graphique revient à l’algorithme d’origine.
L’utilisation de l’option Ligne du ratio dans le volet Analytique a pour effet que le graphique revient à l’algorithme d’origine.
Activer l’échantillonnage à haute densité pour un nuage de points
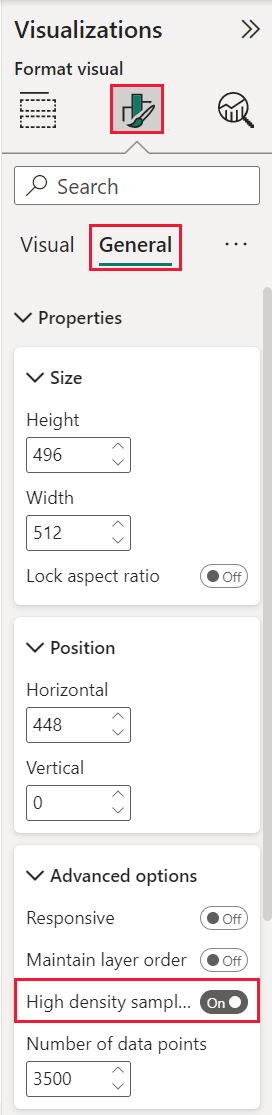
Pour définir l’option Échantillonnage à haute densité sur On, sélectionnez un nuage de points, accédez au volet Mise en forme, développez la carte Général, puis en bas de cette carte, faites glisser le curseur Échantillonnage à haute densité sur Activé.
Remarque
Une fois le commutateur activé, Power BI essaie d’utiliser l’algorithme Échantillonnage à haute densité dès que cela est possible. Quand l’algorithme ne peut pas être utilisé, par exemple si vous placez une valeur sur l’axe de Lecture, le commutateur reste défini sur Activé, même si le graphique est repassé à l’algorithme standard. Si vous supprimez ensuite une valeur de l’axe de Lecture, ou si les conditions changent pour permettre l’utilisation de l’algorithme d’échantillonnage à haute densité, le graphique utilise automatiquement l’échantillonnage à haute densité pour ce graphique, car la fonctionnalité est activée.
Notes
Les points de données sont groupés ou sélectionnés selon l’index. La présence d’une légende n’affecte pas l’échantillonnage pour l’algorithme. Cela affecte uniquement l’ordre de tri du visuel.
Observations et limitations
L’algorithme d’échantillonnage à haute densité représente une amélioration importante de Power BI. Toutefois, l’algorithme Échantillonnage à haute densité fonctionne uniquement avec des connexions actives à des modèles basés sur le service Power BI, à des modèles importés ou à DirectQuery.