Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Conseil / Astuce
Power BI Dataflow Gen1 est désormais dans un état hérité et ne recevra pas de nouveaux investissements de fonctionnalités. Pour les clients Premium disposant d’un accès Fabric, Dataflow Gen2 est le chemin recommandé, offrant des améliorations des performances, de la mise à l’échelle, de la fiabilité, des fonctionnalités et de l’IA intégrée. Les clients Pro/PPU peuvent continuer à utiliser Gen1 car les orientations Gen2 pour ces scénarios évoluent. Pour obtenir des conseils sur la mise à niveau, consultez La mise à niveau de Dataflow Gen1 vers Dataflow Gen2 .
La conception d’un modèle dimensionnel est l’une des tâches les plus courantes que vous pouvez effectuer avec un dataflow. Cet article met en évidence certaines des meilleures pratiques de création d’un modèle dimensionnel à l’aide d’un dataflow.
Flux de données intermédiaires
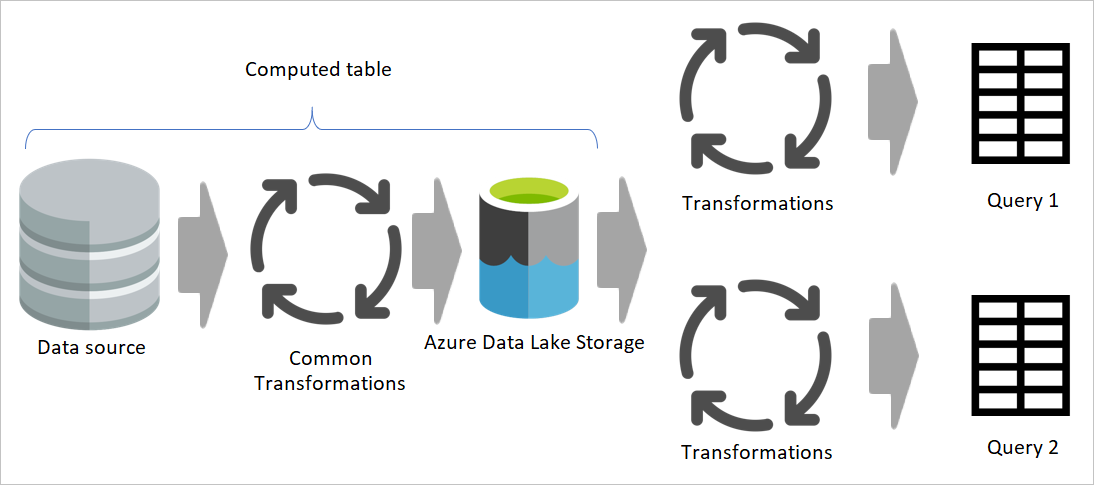
L’un des points clés de n’importe quel système d’intégration de données consiste à réduire le nombre de lectures du système opérationnel source. Dans l’architecture d’intégration de données traditionnelle, cette réduction est effectuée en créant une base de données appelée base de données intermédiaire. L’objectif de la base de données intermédiaire est de charger directement les données à partir de la source de données dans la base de données intermédiaire selon un calendrier régulier.
Le reste de l’intégration des données utilise ensuite la base de données intermédiaire comme source pour une transformation supplémentaire et la convertit en structure de modèle dimensionnel.
Nous vous recommandons de suivre la même approche à l’aide de dataflows. Créez un ensemble de flux de données qui sont chargés de transférer les données telles quelles à partir du système source (et uniquement pour les tables dont vous avez besoin). Le résultat est ensuite stocké dans la structure de stockage du flux de données (Azure Data Lake Storage ou Dataverse). Cette modification garantit que l’opération de lecture à partir du système source est minimale.
Ensuite, vous pouvez créer d'autres flux de données qui obtiennent leurs données à partir de flux de données de mise en scène. Les avantages de cette approche sont les suivants :
- Réduction du nombre d’opérations de lecture à partir du système source et réduction de la charge sur le système source en conséquence.
- Réduction de la charge sur les passerelles de données si une source de données locale est utilisée.
- Avoir une copie intermédiaire des données à des fins de rapprochement, au cas où les données système sources changent.
- Rendre les dataflows de transformation indépendants de la source.
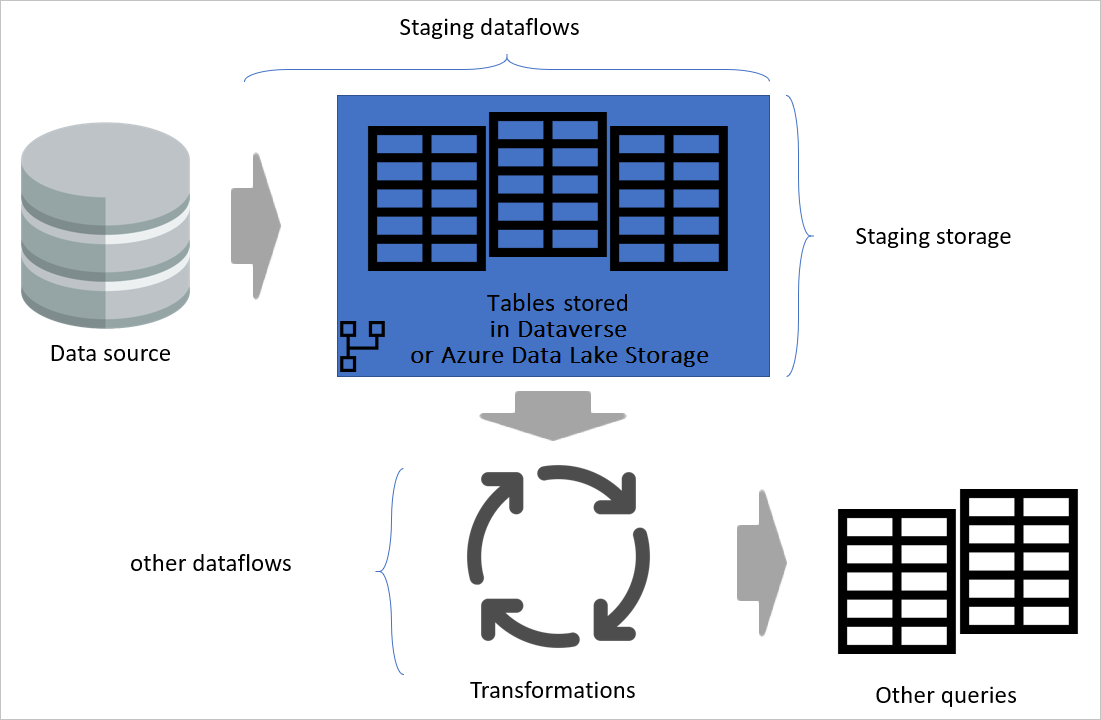
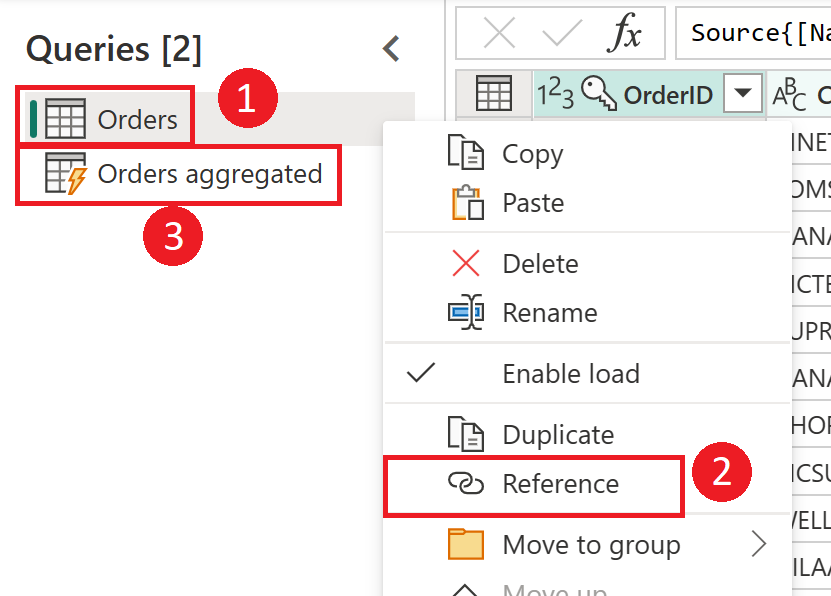
Diagramme mettant en évidence les flux de données intermédiaires et le stockage intermédiaire. Le diagramme montre les données accessibles à partir de la source de données par le flux de données intermédiaire et les tables stockées dans Cadavers ou Azure Data Lake Storage. Les tables sont présentées comme étant transformées avec d'autres flux de données, qui sont ensuite envoyées en tant que requêtes.
Flux de données de transformation
Lorsque vous séparez vos dataflows de transformation des dataflows intermédiaires, la transformation est indépendante de la source. Cette séparation vous permet de migrer le système source vers un nouveau système. Tout ce que vous devez faire dans ce cas est de modifier les flux de données intermédiaires. Les dataflows de transformation sont susceptibles de fonctionner sans problème, car ils sont générés uniquement à partir des dataflows intermédiaires.
Cette séparation est également utile au cas où la connexion au système source serait lente. Le flux de données de transformation n’a pas besoin d’attendre longtemps pour obtenir des enregistrements provenant d’une connexion lente à partir du système source. Le dataflow intermédiaire a déjà fait cette partie et les données sont prêtes pour la couche de transformation.
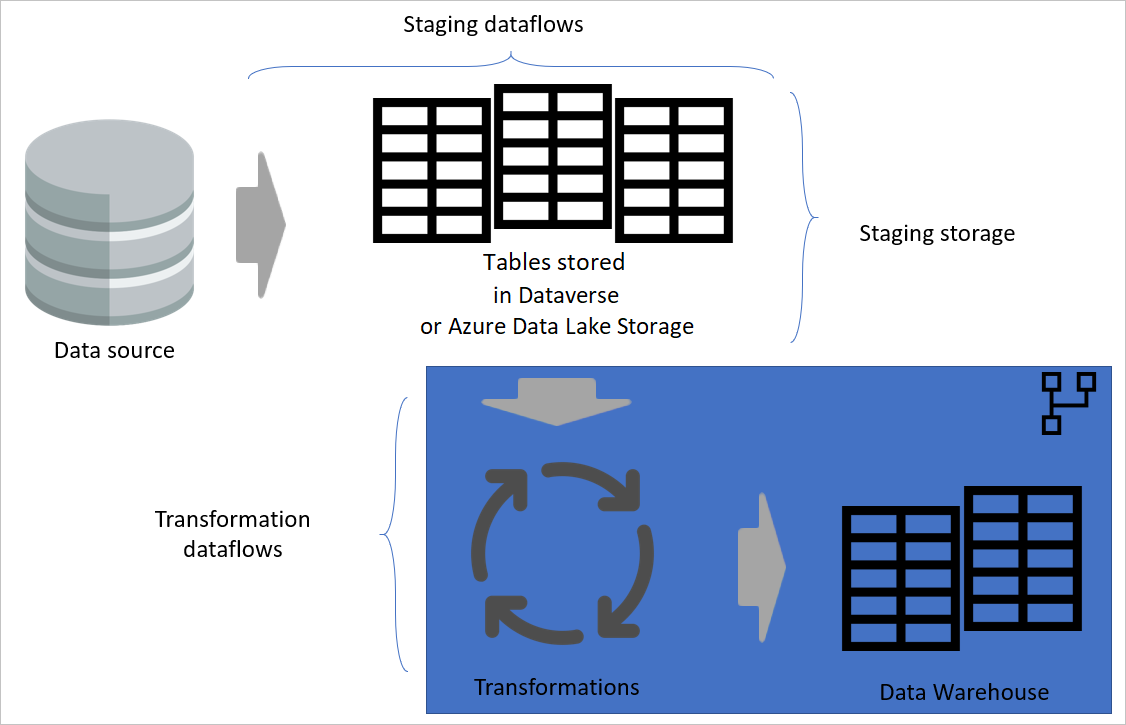
Architecture en couches
Une architecture en couches est une architecture dans laquelle vous effectuez des actions dans des couches distinctes. Les dataflows de préproduction et de transformation peuvent être deux couches d’une architecture de flux de données multicouche. La tentative d’effectuer des actions dans des couches garantit la maintenance minimale requise. Lorsque vous souhaitez modifier quelque chose, vous devez simplement le modifier dans la couche où elle se trouve. Les autres couches doivent continuer à fonctionner correctement.
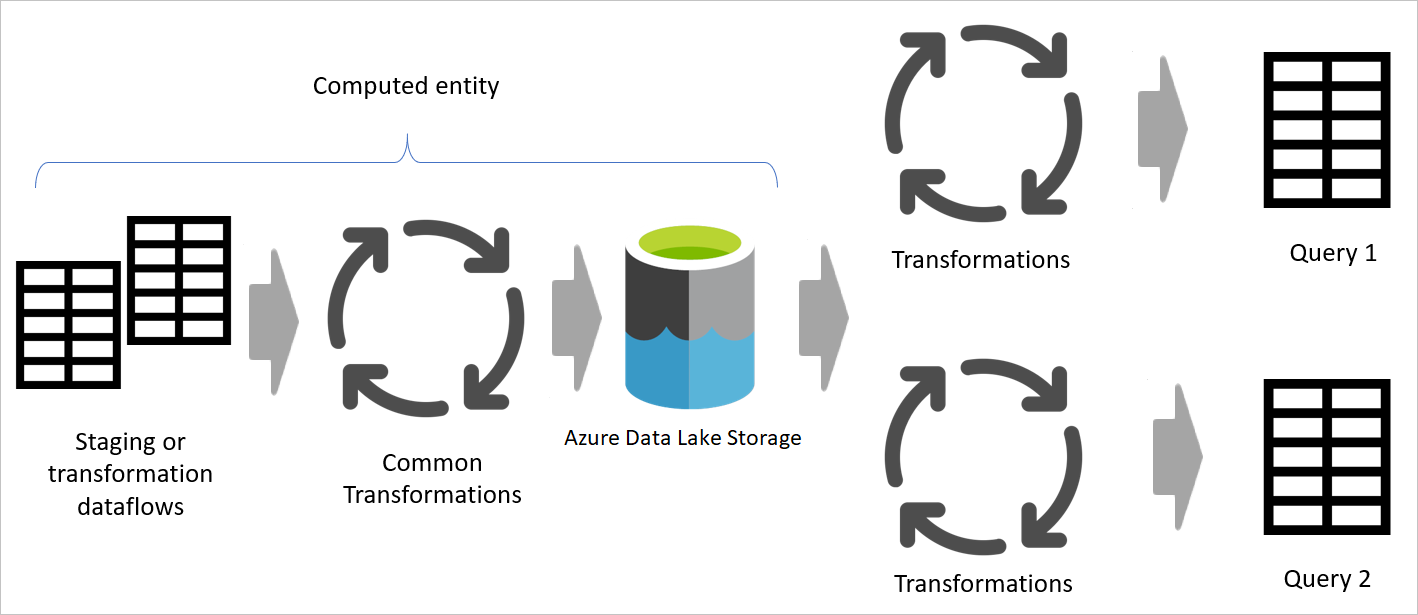
L’image suivante montre une architecture multicouche pour les flux de données dans lesquels leurs tables sont ensuite utilisées dans les modèles sémantiques Power BI.
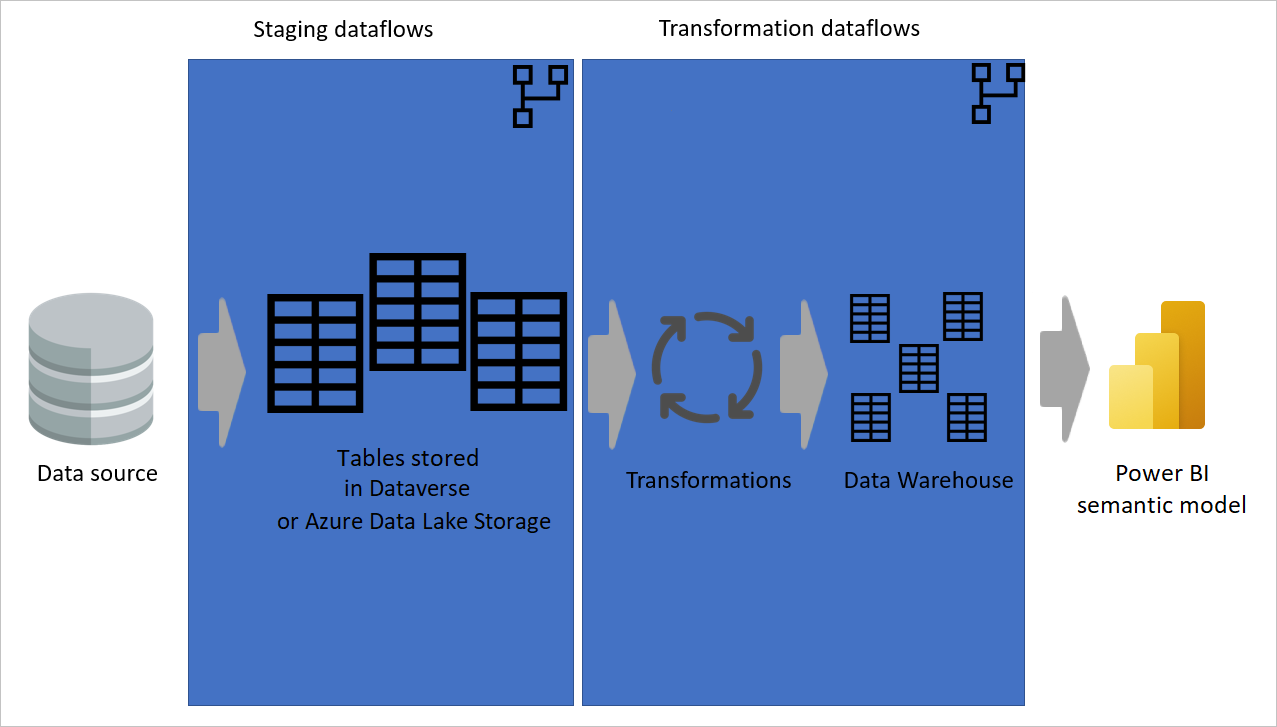
Utiliser une table calculée autant que possible
Lorsque vous utilisez le résultat d’un flux de données dans un autre flux de données, vous utilisez le concept de la table calculée, ce qui signifie obtenir des données à partir d’une table « déjà traitée et stockée ». La même chose peut se produire à l’intérieur d’un dataflow. Lorsque vous référencez une table à partir d’une autre table, vous pouvez utiliser la table calculée. Cette méthode est utile lorsque vous avez un ensemble de transformations qui doivent être effectuées dans plusieurs tables, appelées transformations courantes.
Dans l’image précédente, la table calculée obtient les données directement à partir de la source. Toutefois, dans l’architecture des dataflows de préproduction et de transformation, il est probable que les tables calculées proviennent des dataflows intermédiaires.
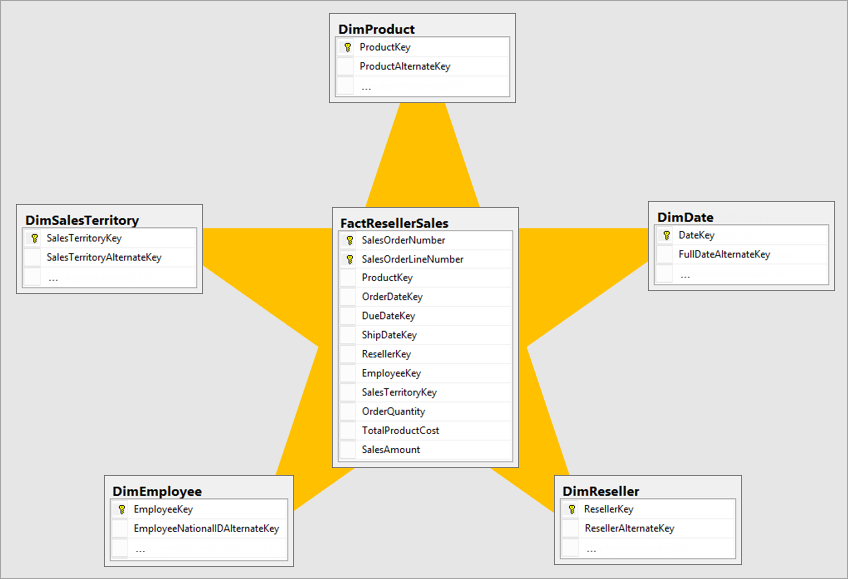
Créer un schéma en étoile
Le meilleur modèle dimensionnel est un modèle de schéma en étoile qui a des dimensions et des tables de faits conçues de manière à réduire la durée d’interrogation des données à partir du modèle. Un modèle de schéma en étoile facilite également la compréhension du visualiseur de données.
Il n’est pas idéal d’intégrer des données dans la même structure que celle du système opérationnel dans un système décisionnel. Les tables de données doivent être remodelées. Certaines des tables doivent prendre la forme d’une table de dimension, qui conserve les informations descriptives. Certaines des tables doivent prendre la forme d’une table de faits pour conserver les données aggregatables. La meilleure disposition pour les tables de faits et les tables de dimension à former est un schéma en étoile. Pour plus d’informations, accédez à Comprendre le schéma en étoile et l’importance de Power BI.
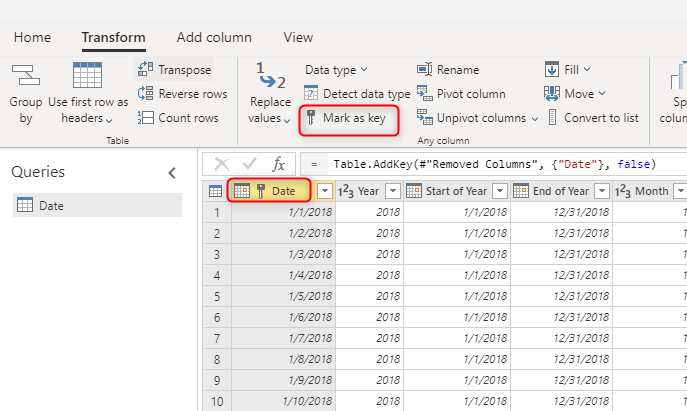
Utiliser une valeur de clé unique pour les dimensions
Lors de la création de tables de dimension, vérifiez que vous disposez d’une clé pour chacune d’elles. Cette clé garantit qu’il n’y a pas de relations plusieurs-à-plusieurs (ou en d’autres termes, « faibles ») entre les dimensions. Vous pouvez créer la clé en appliquant une transformation pour vous assurer qu’une colonne ou une combinaison de colonnes retourne des lignes uniques dans la dimension. Ensuite, cette combinaison de colonnes peut être marquée comme clé dans la table dans le flux de données.
Effectuer une actualisation incrémentielle pour les tables de faits volumineuses
Les tables de faits sont toujours les plus grandes tables du modèle dimensionnel. Nous vous recommandons de réduire le nombre de lignes transférées pour ces tables. Si vous disposez d’une table de faits très volumineuse, veillez à utiliser l’actualisation incrémentielle pour cette table. Une actualisation incrémentielle peut être effectuée dans le modèle sémantique Power BI, ainsi que dans les tables de flux de données.
Vous pouvez utiliser l’actualisation incrémentielle pour actualiser uniquement une partie des données, la partie qui a changé. Il existe plusieurs options pour choisir la partie des données à actualiser et la partie à conserver. Pour plus d’informations, accédez à l’utilisation de l’actualisation incrémentielle avec des dataflows Power BI.

Référencement pour créer des dimensions et des tables de faits
Dans le système source, vous disposez souvent d’une table que vous utilisez pour générer des tables de faits et de dimension dans l’entrepôt de données. Ces tables sont de bons candidats pour les tables calculées et également les flux de données intermédiaires. La partie courante du processus, comme le nettoyage des données et la suppression de lignes et de colonnes supplémentaires, peut être effectuée une seule fois. En utilisant une référence à partir des résultats de ces actions, vous pouvez produire les tables de dimension et de fait. Cette approche utilise la table calculée pour les transformations courantes.