Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Il existe des avantages à l’utilisation de tables calculées dans un dataflow. Cet article décrit les cas d’usage des tables calculées et décrit leur fonctionnement en arrière-plan.
Qu’est-ce qu’une table calculée ?
Une table représente la sortie de données d’une requête créée dans un dataflow, après l’actualisation du flux de données. Il représente les données d’une source et, éventuellement, les transformations qui lui ont été appliquées. Parfois, vous souhaiterez peut-être créer de nouvelles tables qui sont fonction d'une table ingérée précédemment.
Bien qu’il soit possible de répéter les requêtes qui ont créé une table et d’appliquer de nouvelles transformations, cette approche présente des inconvénients : les données sont ingérées deux fois et la charge sur la source de données est doublée.
Les tables calculées résolvent les deux problèmes. Les tables calculées sont similaires à d’autres tables dans lesquelles elles obtiennent des données à partir d’une source et vous pouvez appliquer d’autres transformations pour les créer. Mais leurs données proviennent du dataflow de stockage utilisé, et non de la source de données d’origine. Autrement dit, elles ont été créées précédemment par un flux de données, puis réutilisées.
Les tables calculées peuvent être créées en référençant une table dans le même dataflow ou en référençant une table créée dans un autre dataflow.

Pourquoi utiliser une table calculée ?
L’exécution de toutes les étapes de transformation dans une table peut être lente. Il peut y avoir de nombreuses raisons pour ce ralentissement : la source de données peut être lente ou les transformations que vous effectuez doivent peut-être être répliquées dans deux requêtes ou plus. Il peut être avantageux d’ingérer d’abord les données à partir de la source, puis de les réutiliser dans une ou plusieurs tables. Dans ce cas, vous pouvez choisir de créer deux tables : une qui obtient des données de la source de données et une autre table calculée qui applique davantage de transformations aux données déjà écrites dans le lac de données utilisé par un dataflow. Cette modification peut augmenter les performances et la réutilisation des données, gagner du temps et des ressources.
Par exemple, si deux tables partagent même une partie de leur logique de transformation, sans table calculée, la transformation doit être effectuée deux fois.
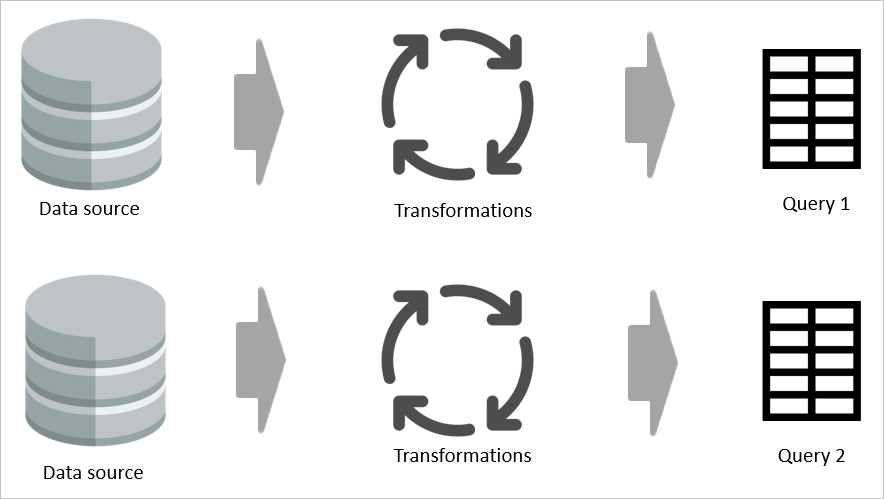
Toutefois, si une table calculée est utilisée, la partie commune (partagée) de la transformation est traitée une fois et stockée dans Azure Data Lake Storage. Les transformations restantes sont ensuite traitées à partir de la sortie de la transformation commune. Dans l’ensemble, ce traitement est beaucoup plus rapide.
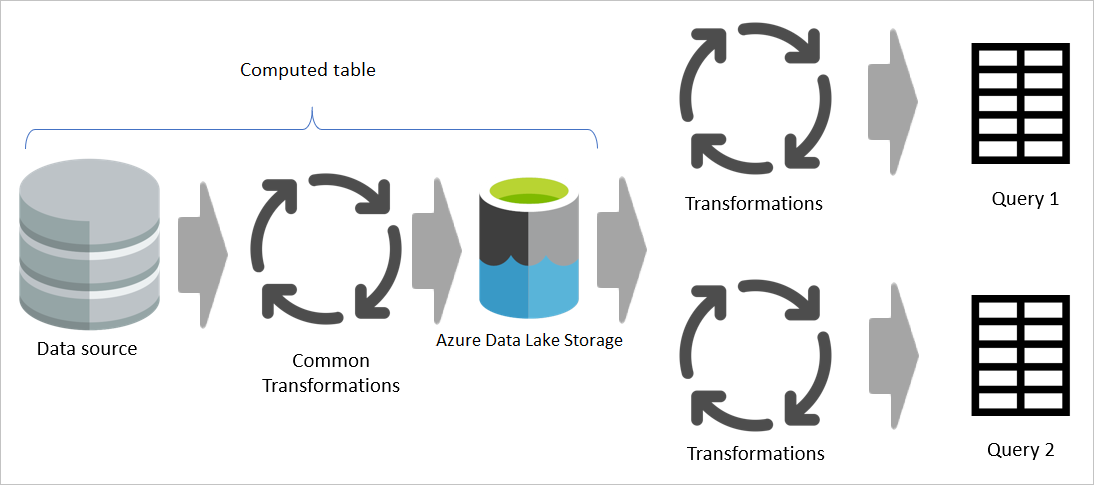
Une table calculée fournit un emplacement en tant que code source pour la transformation et accélère la transformation, car elle ne doit être effectuée qu’une seule fois au lieu de plusieurs fois. La charge sur la source de données est également réduite.
Exemple de scénario d’utilisation d’une table calculée
Si vous créez une table agrégée dans Power BI pour accélérer le modèle de données, vous pouvez générer la table agrégée en référençant la table d’origine et en y appliquant davantage de transformations. À l’aide de cette approche, vous n’avez pas besoin de répliquer votre transformation à partir de la source (partie qui provient de la table d’origine).
Par exemple, la figure suivante montre un tableau Commandes.

À l’aide d’une référence à partir de cette table, vous pouvez créer une table calculée.
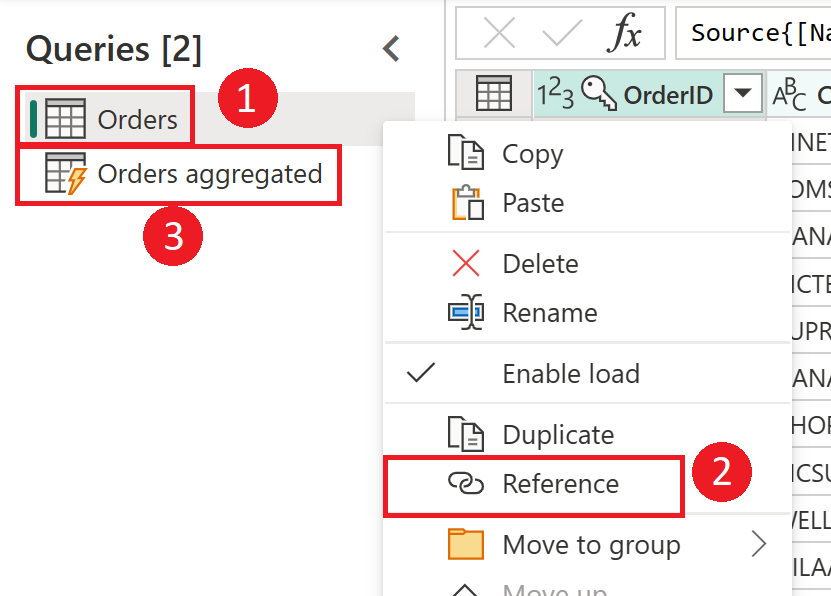
Capture d’écran montrant comment créer une table calculée à partir de la table Orders. Tout d’abord, cliquez avec le bouton droit sur la table Commandes dans le volet Requêtes, sélectionnez l’option Référence dans le menu déroulant. Cette action crée la table calculée, qui est renommée ici en Commandes agrégées.
La table calculée peut avoir d’autres transformations. Par exemple, vous pouvez utiliser Group By pour agréger les données au niveau du client.
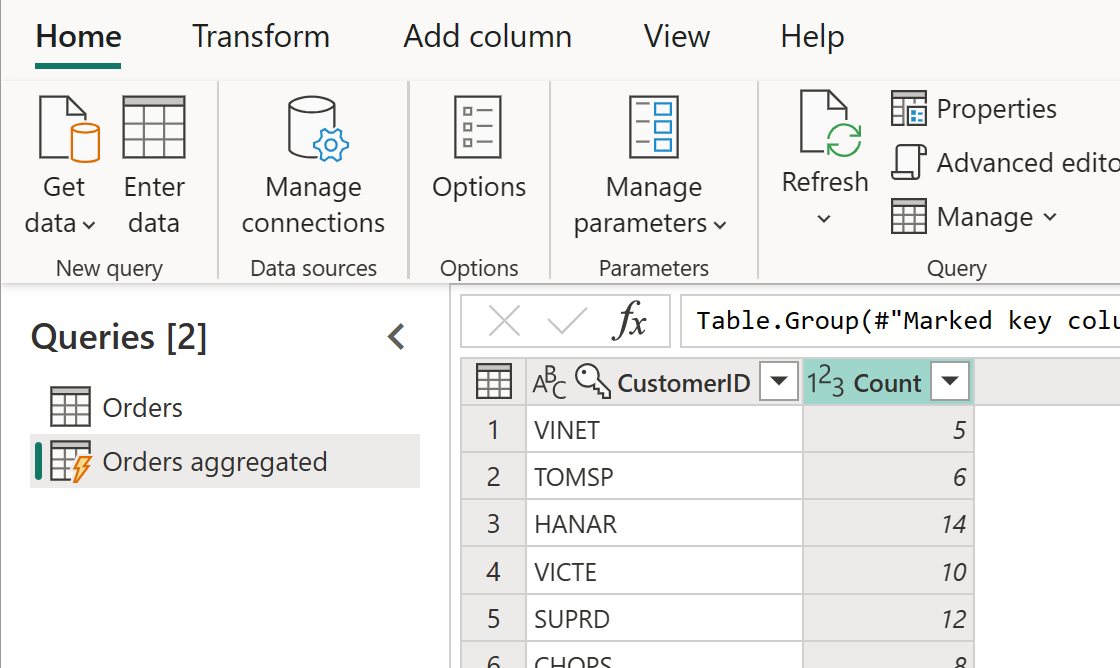
Cela signifie que la table des commandes agrégées tire ses données de la table des commandes et non directement de la source de données. Étant donné que certaines des transformations qui doivent être effectuées ont déjà été effectuées dans la table Orders, les performances sont meilleures et la transformation des données est plus rapide.
Table calculée dans d'autres flux de données
Vous pouvez également créer une table calculée dans d’autres dataflows. Il peut être créé en obtenant des données à partir d’un dataflow avec le connecteur de flux de données Microsoft Power Platform.
L’image met l’accent sur le connecteur Power Platform dataflows à partir de la fenêtre de source de données de Power Query. Il est également inclus une description indiquant qu'une table de flux de données peut être construite à partir des données d'une autre table de flux de données, déjà conservées dans le stockage.
Le concept de la table calculée est d’avoir une table persistante dans le stockage et d’autres tables sources à partir de celle-ci, afin que vous puissiez réduire le temps de lecture de la source de données et partager certaines des transformations courantes. Cette réduction peut être obtenue en obtenant des données d’autres dataflows via le connecteur de flux de données ou en référençant une autre requête dans le même dataflow.
Table calculée : avec des transformations ou sans ?
Maintenant que vous savez que les tables calculées sont idéales pour améliorer les performances de la transformation des données, une bonne question à poser est de savoir si les transformations doivent toujours être différées vers la table calculée ou si elles doivent être appliquées à la table source. Autrement dit, les données doivent-elles toujours être ingérées dans une table, puis transformées dans une table calculée ? Quels sont les avantages et les inconvénients ?
Charger des données sans transformation pour les fichiers Texte/CSV
Lorsqu’une source de données ne prend pas en charge le pliage des requêtes (par exemple, les fichiers Text/CSV), il est peu utile d’appliquer des transformations lors de l’obtention de données à partir de la source, en particulier si les volumes de données sont volumineux. La table source doit simplement charger des données à partir du fichier Text/CSV sans appliquer de transformations. Ensuite, les tables calculées peuvent obtenir des données de la table source et effectuer la transformation en plus des données ingérées.
Vous pouvez vous demander quelle est la valeur de la création d’une table source qui ingère uniquement des données ? Une telle table peut toujours être utile, car si les données de la source sont utilisées dans plusieurs tables, elle réduit la charge sur la source de données. En outre, les données peuvent désormais être réutilisées par d’autres personnes et flux de données. Les tables calculées sont particulièrement utiles dans les scénarios où le volume de données est volumineux ou lorsqu’une source de données est accessible via une passerelle de données locale, car elles réduisent le trafic de la passerelle et la charge sur les sources de données derrière elles.
Effectuer certaines des transformations courantes d’une table SQL
Si votre source de données prend en charge le pliage des requêtes, il est judicieux d’effectuer certaines transformations dans la table source, car la requête est pliée vers la source de données, et seules les données transformées sont extraites. Ces modifications améliorent les performances globales. L’ensemble de transformations courantes dans les tables calculées figurant en aval doivent pouvoir être appliquées dans la table source, afin qu’elles puissent être intégrées à la source. D’autres transformations qui s’appliquent uniquement aux tables en aval doivent être effectuées dans les tables calculées.