Notes
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Les flux de données Microsoft Power Platform et Azure Data Factory sont souvent considérés comme faisant la même chose : extraire des données à partir de systèmes sources, transformer les données et charger les données transformées dans une destination. Toutefois, il existe des différences entre ces deux types de flux de données, et vous pouvez avoir une solution implémentée qui fonctionne avec une combinaison de ces technologies. Cet article décrit cette relation plus en détail.
Dataflows Power Platform
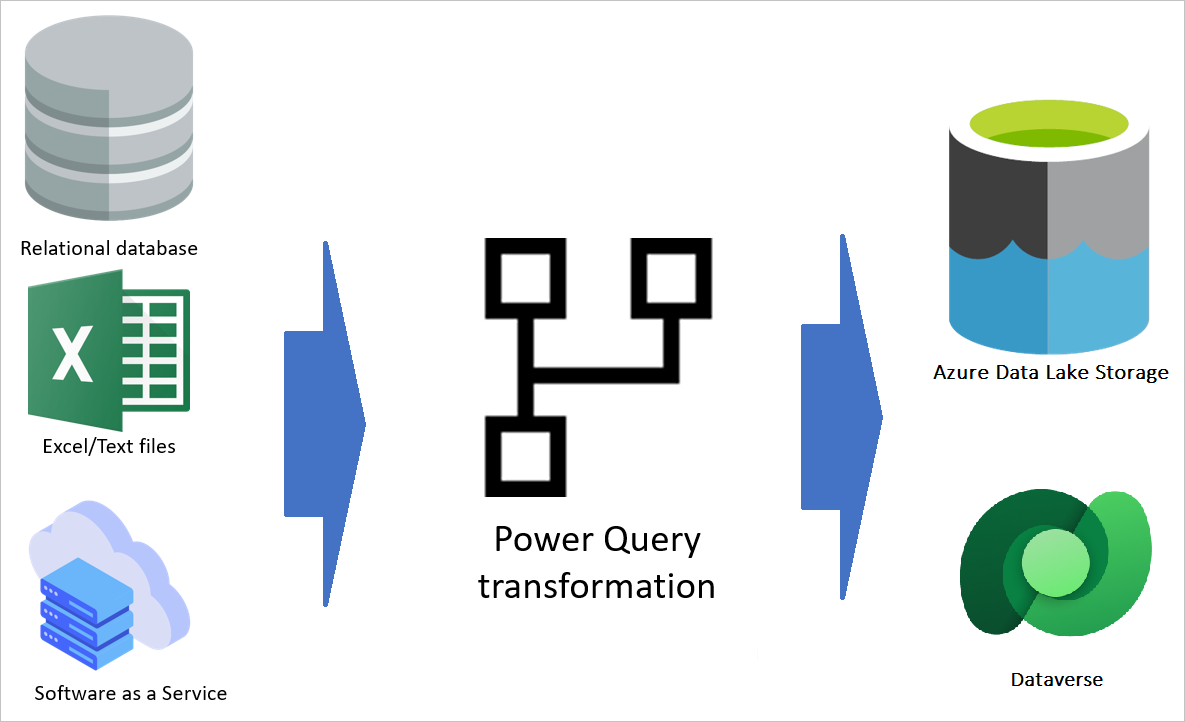
Les flux de données Power Platform sont des services de transformation de données optimisés par le moteur Power Query et hébergés dans le cloud. Ces flux de données obtiennent des données de différentes sources et, après avoir appliqué des transformations, les stockent dans Dataverse ou dans Azure Data Lake Storage.
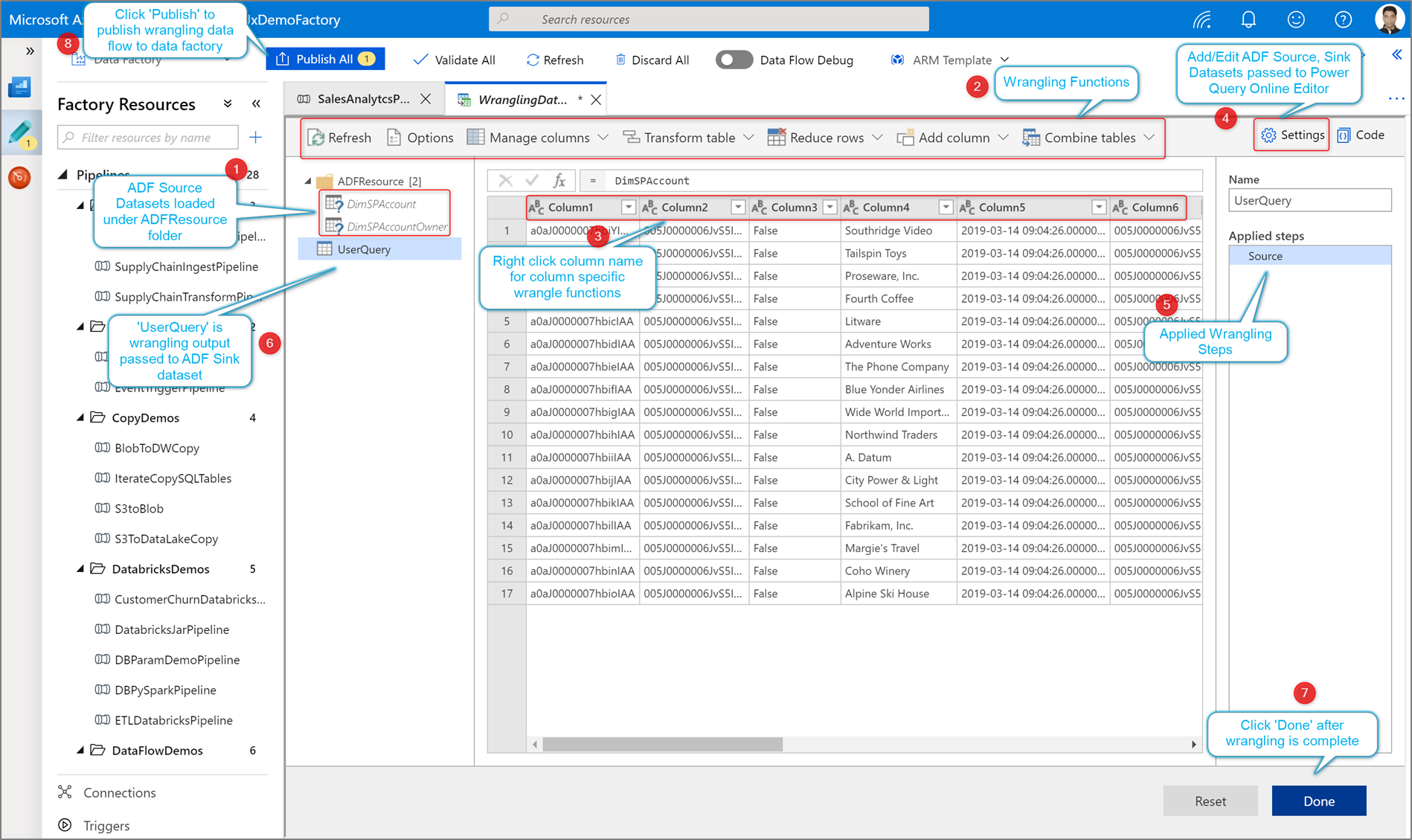
Flux de wrangling data dans Data Factory
Data Factory est un service d’extraction, de transformation, de chargement (ETL) basé sur le cloud, qui prend en charge de nombreuses sources et destinations différentes. Cette technologie englobe deux types de flux de données : les flux de données de mappage et les flux de données de préparation. Les flux de données de préparation sont optimisés par le moteur Power Query pour la transformation des données.
Qu’est-ce qu’ils ont en commun ?
Les flux de données Power Platform et les flux de données de préparation Data Factory sont tous deux utiles pour obtenir des données d’une ou plusieurs sources, en appliquant des transformations aux données à l’aide de Power Query et en chargeant les données transformées dans des destinations. De plus :
- Les deux sont optimisés par une transformation de données Power Query.
- Les deux sont des technologies basées sur le cloud.
Quelle est la différence ?
L’essentiel est de connaître leurs différences, car vous pouvez réfléchir à des scénarios où vous décidez d’utiliser l’un ou l’autre.
| Fonctionnalités | Dataflows Power Platform | Flux de wrangling data dans Data Factory |
|---|---|---|
| Destinations | Dataverse ou Azure Data Lake Storage | De nombreuses destinations (aller à la liste ici) |
| Transformation Power Query | Toutes les fonctions Power Query sont prises en charge | Un ensemble limité de fonctions est pris en charge (aller à la liste ici) |
| Sources | De nombreuses sources sont prises en charge | Seulement quelques sources (aller à la liste ici) |
| Évolutivité | Dépend de la capacité Premium et de l’utilisation du moteur de calcul amélioré | Hautement évolutif |
Quelle genre d’utilisateur convient à quel type de flux de données ?
Si vous êtes un développeur d’applications citoyen ou un analyste de données citoyen avec des données de petite à moyenne échelle à intégrer et transformer, vous trouverez les flux de données Power Platform plus pratiques. Le grand nombre de transformations disponibles, la possibilité de travailler avec elles sans avoir de connaissances en développement et le fait que les flux de données peuvent être créés, surveillés et modifiés dans Power BI ou Power Platform, sont autant de raisons qui font des flux de données Power Platform une excellente solution d’intégration de données pour ce type de développeur.
Si vous êtes un développeur de données travaillant sur le Big Data et d’énormes jeux de données, avec un grand nombre de lignes à ingérer à chaque fois, vous trouverez dans les flux de données de préparation Data Factory un meilleur outil pour accomplir votre travail. Le flux de données de wrangling convertit le M généré par l’éditeur mashup Power Query Online en code Spark pour l’exécution à l’échelle du cloud. L’utilisation du portail Azure pour créer, surveiller et modifier des flux de données de préparation nécessite une courbe d’apprentissage de développeur plus exigeantes que l’expérience des flux de données Power Platform. Les flux de données de préparations sont les mieux adaptés à ce type de public.