Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Note
Les niveaux de confidentialité ne sont actuellement pas disponibles dans les dataflows Power Platform, mais l’équipe produit travaille à activer cette fonctionnalité.
Si vous avez utilisé Power Query pendant une durée quelconque, vous l’avez probablement rencontré. Là, vous effectuez des requêtes, quand vous obtenez soudainement une erreur qu'aucune recherche en ligne, aucun ajustement de la requête ni même un martèlement de clavier ne peuvent remédier. Une erreur telle que :
Formula.Firewall: Query 'Query1' (step 'Source') references other queries or steps, so it may not directly access a data source. Please rebuild this data combination.
Ou peut-être :
Formula.Firewall: Query 'Query1' (step 'Source') is accessing data sources that have privacy levels which cannot be used together. Please rebuild this data combination.
Ces Formula.Firewall erreurs sont le résultat du pare-feu de confidentialité des données de Power Query (également appelé pare-feu), qui peut parfois sembler exister uniquement pour frustrer les analystes de données du monde entier. Croyez-le ou non, cependant, le pare-feu sert un objectif important. Dans cet article, nous allons nous plonger sous le capot pour mieux comprendre comment il fonctionne. Armé d’une meilleure compréhension, vous serez en mesure de mieux diagnostiquer et corriger les erreurs de pare-feu à l’avenir.
Qu’est-ce que c’est ?
L’objectif du pare-feu de confidentialité des données est simple : il existe pour empêcher Power Query de fuite involontaire de données entre sources.
Pourquoi cela est-il nécessaire ? Je veux dire, vous pouvez certainement créer un M qui passerait une valeur SQL à un flux OData. Mais il s’agirait d’une fuite de données intentionnelle. L’auteur de mashup devrait (ou du moins devrait) savoir qu’il fait cela. Pourquoi la nécessité d’une protection contre les fuites de données involontaires ?
La réponse ? Pliage.
Pliant?
Le pliage est un terme qui fait référence à la conversion d’expressions dans M (comme les filtres, les renommages, les jointures, etc.) en opérations sur une source de données brute (par exemple, SQL, OData, etc.). Une grande partie de la puissance de Power Query provient du fait que Power Query peut convertir les opérations qu’un utilisateur effectue via son interface utilisateur en langages sql complexes ou d’autres langages de source de données back-end, sans que l’utilisateur ait à connaître ces langues. Les utilisateurs bénéficient des performances des opérations de source de données natives, avec la facilité d’utilisation d’une interface utilisateur où toutes les sources de données peuvent être transformées à l’aide d’un ensemble commun de commandes.
Dans le cadre du pliage, Power Query peut parfois déterminer que le moyen le plus efficace d’exécuter un mashup donné consiste à prendre des données d’une source et à les transmettre à une autre. Par exemple, si vous joignez un petit fichier CSV à une table SQL énorme, vous ne souhaitez probablement pas que Power Query lise le fichier CSV, lit la table SQL entière, puis les associe sur votre ordinateur local. Vous souhaitez probablement que Power Query inline les données CSV dans une instruction SQL et demandez à la base de données SQL d’effectuer la jointure.
C’est ainsi que des fuites de données involontaires peuvent se produire.
Imaginez si vous joigniez des données SQL qui incluaient des numéros de sécurité sociale des employés avec les résultats d’un flux OData externe, et vous avez découvert soudainement que les numéros de sécurité sociale de SQL étaient envoyés au service OData. Mauvaises nouvelles, non ?
Il s’agit du type de scénario que le pare-feu est destiné à empêcher.
Comment fonctionne-t-il ?
Le pare-feu existe pour empêcher l’envoi involontaire de données d’une source à une autre source. Assez simple.
Comment accomplir cette mission ?
Pour ce faire, divisez vos requêtes M en quelque chose appelé partitions, puis en appliquant la règle suivante :
- Une partition peut accéder à des sources de données compatibles ou référencer d’autres partitions, mais pas les deux.
Simple... pourtant confus. Qu’est-ce qu’une partition ? Qu’est-ce qui rend deux sources de données « compatibles » ? Et pourquoi le pare-feu doit-il se soucier si une partition souhaite accéder à une source de données et référencer une partition ?
Analysons cela et examinons la règle précédente élément par élément.
Qu’est-ce qu’une partition ?
Au niveau le plus simple, une partition n’est qu’une collection d’une ou plusieurs étapes de requête. La partition la plus granulaire possible (au moins dans l’implémentation actuelle) est une étape unique. Les partitions les plus volumineuses peuvent parfois englober plusieurs requêtes. (Plus d'informations à venir plus tard.)
Si vous n’êtes pas familiarisé avec les étapes, vous pouvez les afficher à droite de la fenêtre Éditeur Power Query après avoir sélectionné une requête, dans le volet Étapes appliquées . Les étapes suivent tout ce que vous faites pour transformer vos données en sa forme finale.
Partitions qui référencent d’autres partitions
Lorsqu’une requête est évaluée avec le pare-feu activé, le pare-feu divise la requête et toutes ses dépendances en partitions (autrement dit, des groupes d’étapes). Chaque fois qu’une partition fait référence à quelque chose dans une autre partition, le pare-feu remplace la référence par un appel à une fonction spéciale appelée Value.Firewall. En d’autres termes, le pare-feu n’autorise pas les partitions à accéder directement les unes aux autres. Tous les référencements sont modifiés pour passer par le pare-feu. Considérez le pare-feu comme un gardien de contrôle. Une partition qui fait référence à une autre partition doit obtenir l’autorisation du pare-feu pour ce faire, et le pare-feu contrôle si les données référencées sont autorisées dans la partition.
Tout cela peut sembler assez abstrait, donc examinons un exemple.
Supposons que vous disposez d’une requête appelée Employees, qui extrait certaines données d’une base de données SQL. Supposons que vous disposez également d’une autre requête (EmployeesReference), qui fait simplement référence aux employés.
shared Employees = let
Source = Sql.Database(…),
EmployeesTable = …
in
EmployeesTable;
shared EmployeesReference = let
Source = Employees
in
Source;
Ces requêtes se divisent en deux partitions : une pour la requête Employees et une pour la requête EmployeesReference (qui fait référence à la partition Employees). Lorsqu’elles sont évaluées avec le pare-feu, ces requêtes sont réécrites comme suit :
shared Employees = let
Source = Sql.Database(…),
EmployeesTable = …
in
EmployeesTable;
shared EmployeesReference = let
Source = Value.Firewall("Section1/Employees")
in
Source;
Notez que la référence simple à la requête Employees est remplacée par un appel à Value.Firewall, qui reçoit la requête Employees avec son nom complet.
Lorsque EmployeesReference est évalué, le pare-feu intercepte l’appel à Value.Firewall("Section1/Employees"), qui peut désormais contrôler si les données demandées (et comment elles) circulent dans la partition EmployeesReference. Il peut effectuer n’importe quel nombre d’opérations : refuser la demande, mettre en mémoire tampon les données demandées (ce qui empêche tout repli supplémentaire vers sa source de données d’origine de se produire), et ainsi de suite.
Il s’agit de la façon dont le pare-feu gère le contrôle des données qui circulent entre les partitions.
Partitions qui accèdent directement aux sources de données
Supposons que vous définissez une requête Query1 avec une étape (notez que cette requête en une seule étape correspond à une partition de pare-feu) et que cette étape unique accède à deux sources de données : une table de base de données SQL et un fichier CSV. Comment le pare-feu traite-t-il cela, car il n’y a pas de référence de partition, et donc aucun appel à Value.Firewall pour l’intercepter ? Examinons la règle indiquée précédemment :
- Une partition peut accéder à des sources de données compatibles ou référencer d’autres partitions, mais pas les deux.
Pour que votre requête mono-partition-mais-deux sources de données soit autorisée à s’exécuter, ses deux sources de données doivent être « compatibles ». En d’autres termes, il doit être acceptable que les données soient partagées bidirectionnellement entre elles. Cela signifie que les niveaux de confidentialité des deux sources doivent être publics, ou les deux être organisationnels, car il s’agit des deux seules combinaisons qui autorisent le partage dans les deux directions. Si les deux sources sont marquées Private, ou si l’une est marquée Public et qu’elle est marquée Organisationnelle, ou qu’elles sont marquées à l’aide d’une autre combinaison de niveaux de confidentialité, le partage bidirectionnel n’est pas autorisé. Il n’est pas sûr que les deux soient évalués dans la même partition. Cela signifierait que des fuites de données non sécurisées pourraient se produire (en raison du repli) et que le pare-feu n’aurait aucun moyen de l’empêcher.
Que se passe-t-il si vous essayez d’accéder à des sources de données incompatibles dans la même partition ?
Formula.Firewall: Query 'Query1' (step 'Source') is accessing data sources that have privacy levels which cannot be used together. Please rebuild this data combination.
Espérons que vous comprenez maintenant mieux l’un des messages d’erreur répertoriés au début de cet article.
Cette exigence de compatibilité s’applique uniquement dans une partition donnée. Si une partition fait référence à d’autres partitions, les sources de données des partitions référencées n’ont pas besoin d’être compatibles les unes avec les autres. Cela est dû au fait que le pare-feu peut mettre en mémoire tampon les données, ce qui empêche tout repli supplémentaire sur la source de données d’origine. Les données sont chargées en mémoire et traitées comme si elles provenaient de nulle part.
Pourquoi ne pas faire les deux ?
Supposons que vous définissez une requête avec une étape (qui correspond de nouveau à une partition) qui accède à deux autres requêtes (autrement dit, deux autres partitions). Et si vous souhaitiez, dans la même étape, accéder directement à une base de données SQL ? Pourquoi une partition ne peut-elle pas référencer d’autres partitions et accéder directement aux sources de données compatibles ?
Comme vous l’avez vu précédemment, quand une partition référence une autre partition, le pare-feu agit comme le gardien de contrôle pour toutes les données qui circulent dans la partition. Pour ce faire, il doit être en mesure de contrôler les données autorisées. S’il existe des sources de données accessibles au sein de la partition et que les données circulent à partir d’autres partitions, elle perd sa capacité à être le gardien, car les données qui circulent peuvent être divulguées vers l’une des sources de données accessibles en interne sans qu’elles ne le sachent. Par conséquent, le pare-feu empêche une partition qui accède à d’autres partitions d’être autorisée à accéder directement à toutes les sources de données.
Que se passe-t-il si une partition tente de référencer d’autres partitions et d’accéder directement aux sources de données ?
Formula.Firewall: Query 'Query1' (step 'Source') references other queries or steps, so it may not directly access a data source. Please rebuild this data combination.
Maintenant, vous comprenez mieux l’autre message d’erreur répertorié au début de cet article.
Partitions en profondeur
Comme vous pouvez probablement deviner à partir des informations précédentes, la façon dont les requêtes sont partitionnée finit par être incroyablement importantes. Si vous avez des étapes qui font référence à d’autres requêtes et d’autres étapes qui accèdent aux sources de données, vous reconnaissez maintenant que le dessin des limites de partition à certains endroits provoque des erreurs de pare-feu, tout en les dessinant à d’autres endroits, permet à votre requête de s’exécuter correctement.
Comment les requêtes sont-elles partitionnées exactement ?
Cette section est probablement la plus importante pour comprendre pourquoi vous voyez des erreurs de pare-feu et comprendre comment les résoudre (le cas échéant).
Voici un résumé général de la logique de partitionnement.
- Partitionnement initial
- Crée une partition pour chaque étape de chaque requête
- Phase statique
- Cette phase ne dépend pas des résultats d’évaluation. Au lieu de cela, il s’appuie sur la façon dont les requêtes sont structurées.
- Découpage des paramètres
- Supprime les partitions qui ressemblent à des paramètres, autrement dit, celles qui :
- Ne fait référence à aucune autre partition
- Ne contient aucun appel de fonction
- N’est pas cyclique (autrement dit, elle ne fait pas référence à elle-même)
- Notez que la « suppression » d’une partition l’inclut efficacement dans les autres partitions qui la référencent.
- La réduction des partitions de paramètres permet aux références de paramètres utilisées dans les appels de fonctions de source de données (par exemple,
Web.Contents(myUrl)) de fonctionner, au lieu de générer des erreurs « la partition ne peut pas référencer les sources de données et d’autres étapes supplémentaires ».
- Supprime les partitions qui ressemblent à des paramètres, autrement dit, celles qui :
- Regroupement (statique)
- Les partitions sont fusionnées dans l’ordre de dépendance inférieur. Dans les partitions fusionnées résultantes, les éléments suivants sont distincts :
- Partitions dans différentes requêtes
- Partitions qui ne font pas référence à d’autres partitions (et sont donc autorisées à accéder à une source de données)
- Partitions qui référencent d’autres partitions (et sont donc interdites d’accéder à une source de données)
- Les partitions sont fusionnées dans l’ordre de dépendance inférieur. Dans les partitions fusionnées résultantes, les éléments suivants sont distincts :
- Découpage des paramètres
- Cette phase ne dépend pas des résultats d’évaluation. Au lieu de cela, il s’appuie sur la façon dont les requêtes sont structurées.
- Phase dynamique
- Cette phase dépend des résultats d’évaluation, y compris des informations sur les sources de données accessibles par différentes partitions.
- Ajustement
- Supprime les partitions qui répondent à toutes les exigences suivantes :
- N’accède à aucune source de données
- Ne référence aucune partition qui accède aux sources de données
- N’est pas cyclique
- Supprime les partitions qui répondent à toutes les exigences suivantes :
- Regroupement (dynamique)
- Maintenant que les partitions inutiles sont réduites, essayez de créer des partitions sources aussi volumineuses que possible. Cette création est effectuée en fusionnant les partitions à l’aide des mêmes règles décrites dans la phase de regroupement statique précédente.
Qu’est-ce que tout cela signifie ?
Examinons un exemple pour illustrer comment fonctionne cette logique complexe présentée précédemment.
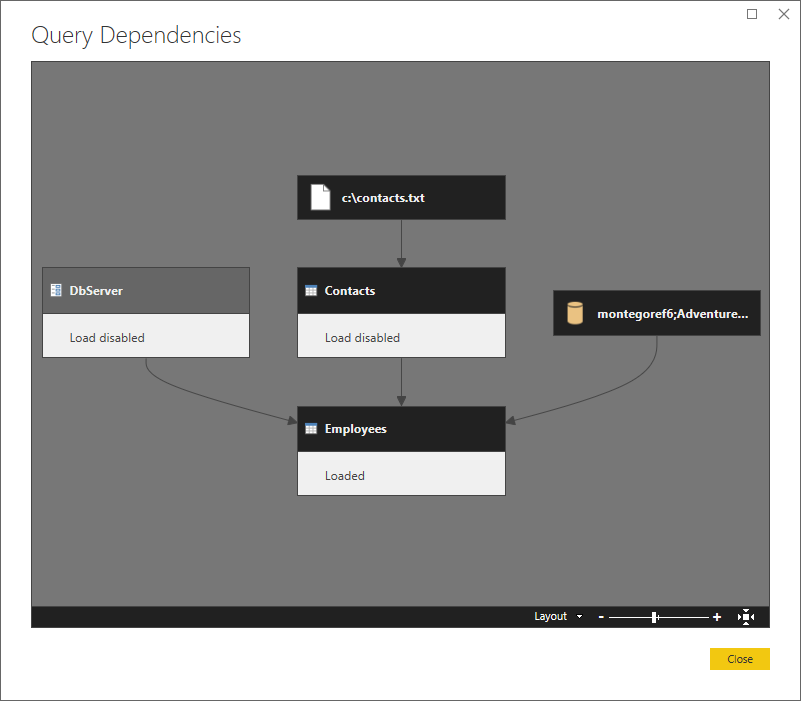
Voici un exemple de scénario. Il s’agit d’une fusion assez simple d’un fichier texte (Contacts) avec une base de données SQL (Employés), où le serveur SQL est un paramètre (DbServer).
Les trois requêtes
Voici le code M pour les trois requêtes utilisées dans cet exemple.
shared DbServer = "MySqlServer" meta [IsParameterQuery=true, Type="Text", IsParameterQueryRequired=true];
shared Contacts = let
Source = Csv.Document(File.Contents(
"C:\contacts.txt"),[Delimiter=" ", Columns=15, Encoding=1252, QuoteStyle=QuoteStyle.None]
),
#"Promoted Headers" = Table.PromoteHeaders(Source, [PromoteAllScalars=true]),
#"Changed Type" = Table.TransformColumnTypes(
#"Promoted Headers",
{
{"ContactID", Int64.Type},
{"NameStyle", type logical},
{"Title", type text},
{"FirstName", type text},
{"MiddleName", type text},
{"LastName", type text},
{"Suffix", type text},
{"EmailAddress", type text},
{"EmailPromotion", Int64.Type},
{"Phone", type text},
{"PasswordHash", type text},
{"PasswordSalt", type text},
{"AdditionalContactInfo", type text},
{"rowguid", type text},
{"ModifiedDate", type datetime}
}
)
in
#"Changed Type";
shared Employees = let
Source = Sql.Databases(DbServer),
AdventureWorks = Source{[Name="AdventureWorks"]}[Data],
HumanResources_Employee = AdventureWorks{[Schema="HumanResources",Item="Employee"]}[Data],
#"Removed Columns" = Table.RemoveColumns(
HumanResources_Employee,
{
"HumanResources.Employee(EmployeeID)",
"HumanResources.Employee(ManagerID)",
"HumanResources.EmployeeAddress",
"HumanResources.EmployeeDepartmentHistory",
"HumanResources.EmployeePayHistory",
"HumanResources.JobCandidate",
"Person.Contact",
"Purchasing.PurchaseOrderHeader",
"Sales.SalesPerson"
}
),
#"Merged Queries" = Table.NestedJoin(
#"Removed Columns",
{"ContactID"},
Contacts,
{"ContactID"},
"Contacts",
JoinKind.LeftOuter
),
#"Expanded Contacts" = Table.ExpandTableColumn(
#"Merged Queries",
"Contacts",
{"EmailAddress"},
{"EmailAddress"}
)
in
#"Expanded Contacts";
Voici une vue de niveau supérieur, montrant les dépendances.
Partitionner
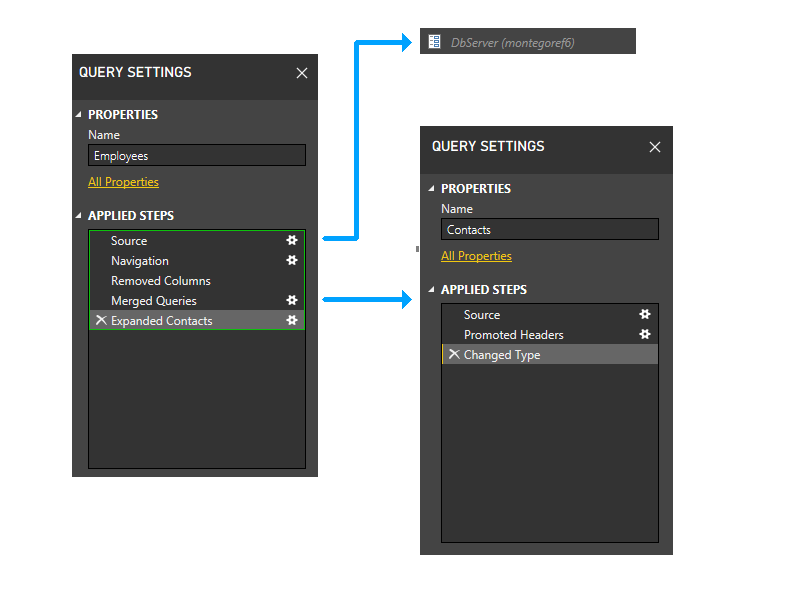
Zoomez un peu et incluez des étapes dans l'image, puis commencez à examiner la logique de partitionnement. Voici un diagramme des trois requêtes, montrant les partitions de pare-feu initiales en vert. Notez que chaque étape démarre dans sa propre partition.
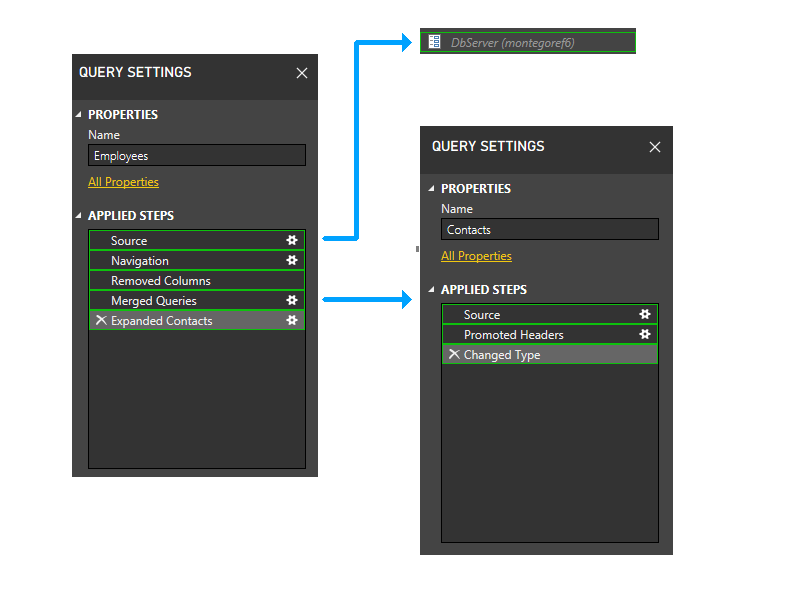
Ensuite, nous allons découper les partitions de paramètres. Par conséquent, DbServer est implicitement inclus dans la partition source.
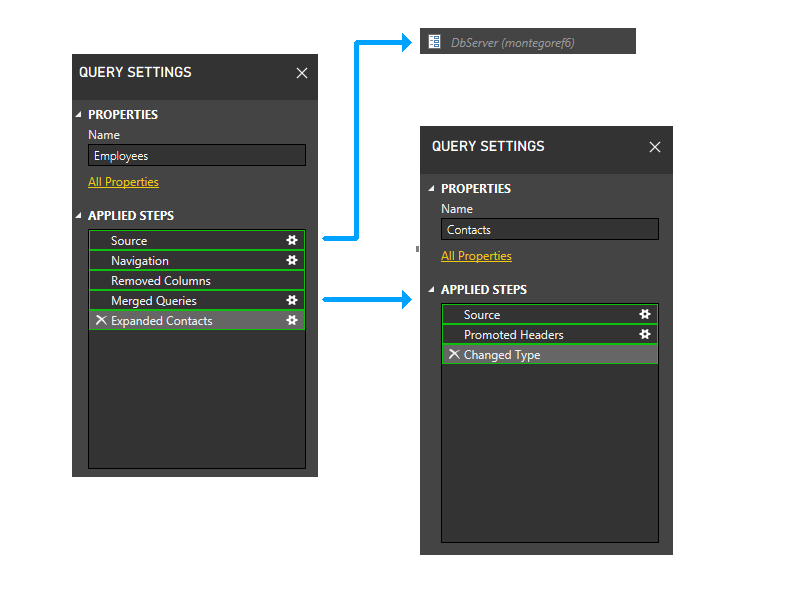
À présent, nous effectuons le regroupement statique. Ce regroupement maintient la séparation entre les partitions dans des requêtes distinctes (notez, par exemple, que les deux dernières étapes des employés ne sont pas regroupées avec les étapes des contacts) et entre les partitions qui référencent d’autres partitions (telles que les deux dernières étapes d’Employés) et celles qui ne le font pas (comme les trois premières étapes des employés).
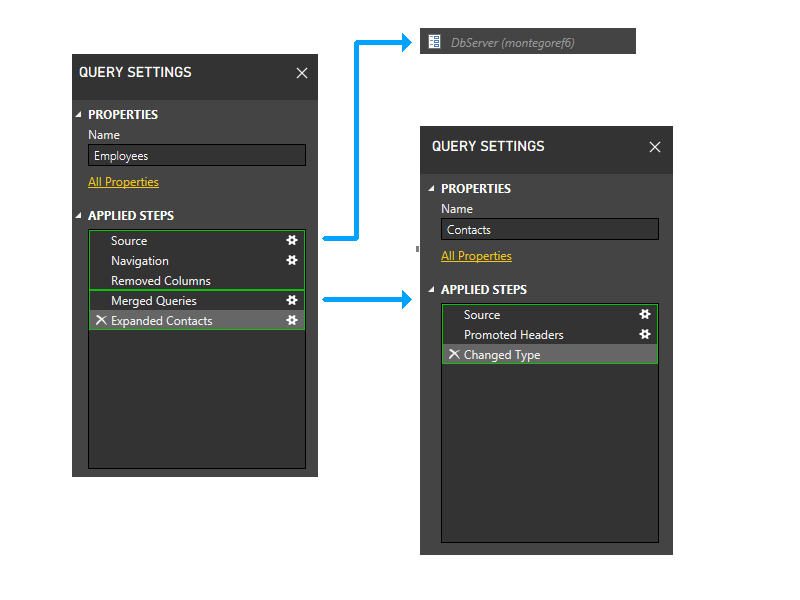
Maintenant, nous entrerons dans la phase dynamique. Dans cette phase, les partitions statiques ci-dessus sont évaluées. Les partitions qui n’accèdent à aucune source de données sont coupées. Les partitions sont ensuite regroupées pour créer des partitions sources aussi volumineuses que possible. Toutefois, dans cet exemple de scénario, toutes les partitions restantes accèdent aux sources de données, et aucun regroupement supplémentaire ne peut être effectué. Les partitions de notre exemple ne changent donc pas pendant cette phase.
Faisons semblant
Pour l’illustration, cependant, examinons ce qui se passerait si la requête Contacts, au lieu de provenir d’un fichier texte, était codée en dur dans M (peut-être via la boîte de dialogue Entrer des données ).
Dans ce cas, la requête Contacts n’accéderait à aucune source de données. Ainsi, elle serait réduite pendant la première partie de la phase dynamique.
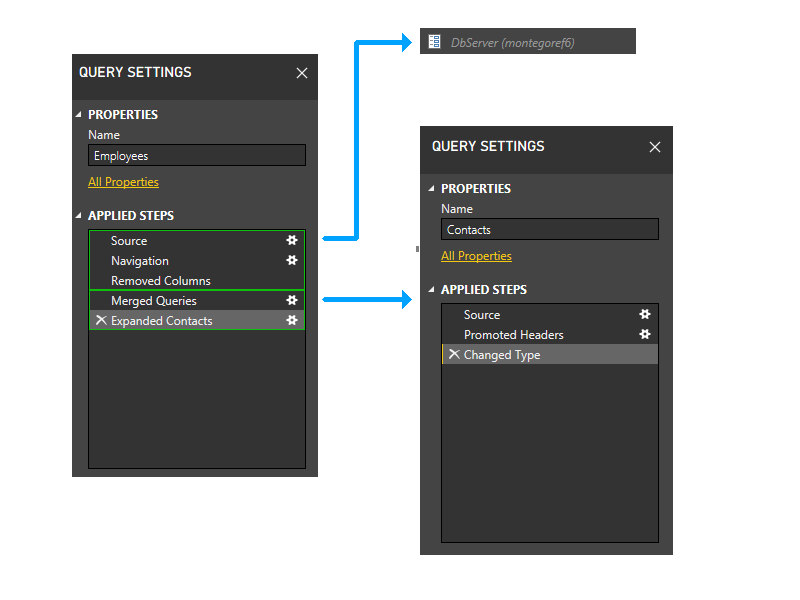
Une fois la partition Contacts supprimée, les deux dernières étapes des employés ne référencent plus de partitions, à l’exception de celle contenant les trois premières étapes des employés. Ainsi, les deux partitions seraient regroupées.
La partition résultante ressemblerait à ceci.
Exemple : passage de données d’une source de données à une autre
Ok, assez d’explication abstraite. Examinons un scénario courant où vous êtes susceptible de rencontrer une erreur de pare-feu et les étapes à suivre pour la résoudre.
Imaginez que vous souhaitez rechercher un nom de société à partir du service Northwind OData, puis utiliser le nom de la société pour effectuer une recherche Bing.
Tout d’abord, vous créez une requête d’entreprise pour récupérer le nom de la société.
let
Source = OData.Feed(
"https://services.odata.org/V4/Northwind/Northwind.svc/",
null,
[Implementation="2.0"]
),
Customers_table = Source{[Name="Customers",Signature="table"]}[Data],
CHOPS = Customers_table{[CustomerID="CHOPS"]}[CompanyName]
in
CHOPS
Ensuite, vous créez une requête de recherche qui fait référence à l’entreprise et la transmet à Bing.
let
Source = Text.FromBinary(Web.Contents("https://www.bing.com/search?q=" & Company))
in
Source
À ce stade, vous rencontrez des problèmes. L’évaluation de la recherche génère une erreur de pare-feu.
Formula.Firewall: Query 'Search' (step 'Source') references other queries or steps, so it may not directly access a data source. Please rebuild this data combination.
Cette erreur se produit parce que l’étape Source de la recherche fait référence à une source de données (bing.com) et fait également référence à une autre requête/partition (Société). Elle enfreint la règle mentionnée précédemment (« une partition peut accéder à des sources de données compatibles ou référencer d’autres partitions, mais pas les deux »).
Que faire, alors ? Une option consiste à désactiver complètement le pare-feu (via l’option Confidentialité étiquetée Ignorer les niveaux de confidentialité et potentiellement améliorer les performances). Mais que se passe-t-il si vous souhaitez laisser le pare-feu activé ?
Pour résoudre l’erreur sans désactiver le pare-feu, vous pouvez combiner l’entreprise et la recherche dans une seule requête, comme suit :
let
Source = OData.Feed(
"https://services.odata.org/V4/Northwind/Northwind.svc/",
null,
[Implementation="2.0"]
),
Customers_table = Source{[Name="Customers",Signature="table"]}[Data],
CHOPS = Customers_table{[CustomerID="CHOPS"]}[CompanyName],
Search = Text.FromBinary(Web.Contents("https://www.bing.com/search?q=" & CHOPS))
in
Search
Tout se passe maintenant à l’intérieur d’une seule partition. En supposant que les niveaux de confidentialité des deux sources de données sont compatibles, le pare-feu doit maintenant être heureux et vous ne recevez plus d’erreur.
C'est terminé
Bien qu’il y ait beaucoup plus à dire sur ce sujet, cet article d’introduction est déjà assez long. J’espère qu’il vous est donné une meilleure compréhension du pare-feu, et vous aide à comprendre et à corriger les erreurs de pare-feu lorsque vous les rencontrez à l’avenir.