Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
La simplicité et la facilité d’utilisation qui permettent aux utilisateurs power BI de collecter rapidement des données et de générer des rapports intéressants et puissants pour prendre des décisions métier intelligentes permettent également aux utilisateurs de générer facilement des requêtes mal performantes. Cela se produit souvent lorsqu’il existe deux tables associées de la façon dont une clé étrangère associe des tables SQL ou des listes SharePoint. (Pour l’enregistrement, ce problème n’est pas spécifique à SQL ou SharePoint et se produit dans de nombreux scénarios d’extraction de données back-end, en particulier lorsque le schéma est fluide et personnalisable.) Il n’y a pas non plus de problème inhérent au stockage des données dans des tables distinctes qui partagent une clé commune. En fait, il s’agit d’un ensemble fondamental de conception et de normalisation de la base de données. Mais cela implique une meilleure façon d’élargir la relation.
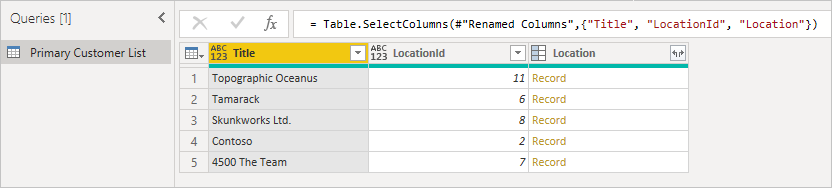
Prenons l’exemple suivant d’une liste de clients SharePoint.
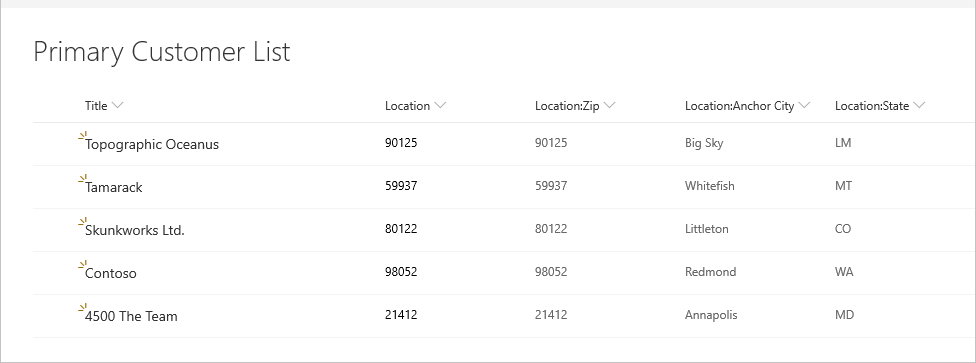
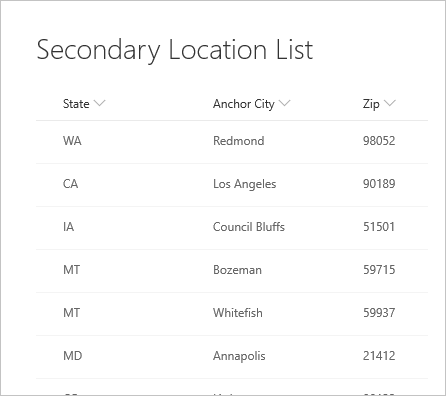
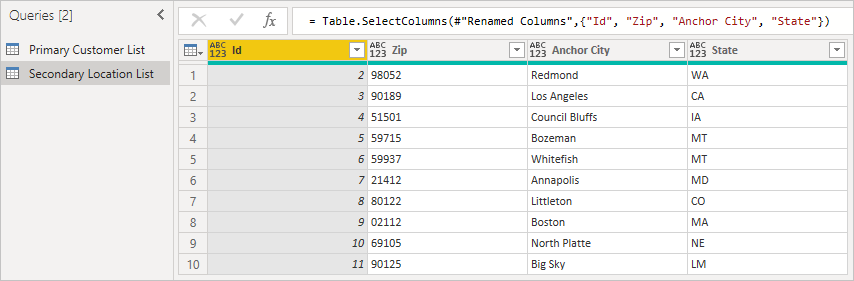
La liste d'emplacements suivante à laquelle elle se réfère.
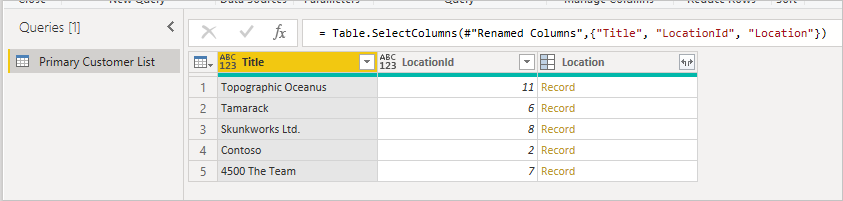
Lors de la première connexion à la liste, l’emplacement s’affiche sous forme d’enregistrement.
Ces données de niveau supérieur sont collectées via un seul appel HTTP à l’API SharePoint (en ignorant l’appel de métadonnées), que vous pouvez voir dans n’importe quel débogueur web.

Lorsque vous affichez l’enregistrement, vous voyez les champs joints à partir de la table secondaire.

Lorsque vous développez des lignes associées d’une table à une autre, le comportement par défaut de Power BI consiste à générer un appel à Table.ExpandTableColumn. Vous pouvez le voir dans le champ de formule généré. Malheureusement, cette méthode génère un appel individuel à la deuxième table pour chaque ligne de la première table.
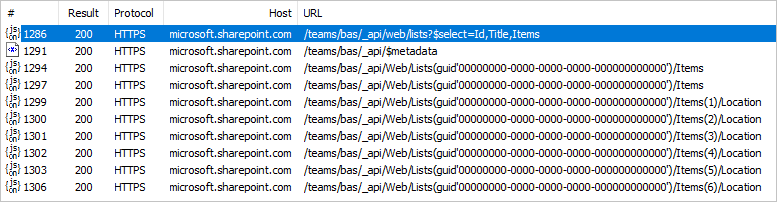
Cela augmente le nombre d’appels HTTP d’un pour chaque ligne de la liste primaire. Cela peut ne pas sembler beaucoup dans l’exemple ci-dessus de cinq ou six lignes, mais dans les systèmes de production où les listes SharePoint atteignent des centaines de milliers de lignes, cela peut entraîner une dégradation significative de l’expérience.
Lorsque les requêtes atteignent ce goulot d’étranglement, la meilleure atténuation consiste à éviter le comportement d’appel par ligne à l’aide d’une jointure de table classique. Cela garantit qu’il n’y aura qu’un seul appel pour récupérer la deuxième table, et le reste de l’expansion peut se produire en mémoire à l’aide de la clé commune entre les deux tables. La différence de performances peut être massive dans certains cas.
Tout d’abord, commencez par la table d’origine, notez la colonne que vous souhaitez développer et vérifiez que vous disposez de l’ID de l’élément pour pouvoir le faire correspondre. En règle générale, la clé étrangère a un nom similaire au nom d'affichage de la colonne avec Id ajouté. Dans cet exemple, il s’agit de LocationId.
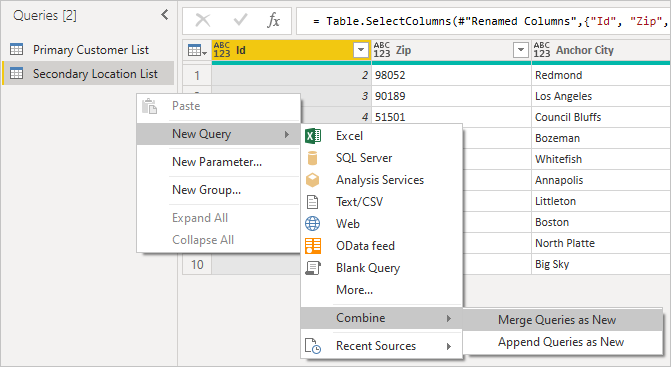
Ensuite, chargez la table secondaire, en veillant à inclure l’ID, qui est la clé étrangère. Cliquez avec le bouton droit sur le volet Requêtes pour créer une requête.
Enfin, joignez les deux tables en utilisant les noms de colonnes respectifs qui correspondent. Vous pouvez généralement trouver ce champ en développant d’abord la colonne, puis en recherchant les colonnes correspondantes dans l’aperçu.

Dans cet exemple, vous pouvez voir que LocationId dans la liste primaire correspond à l’ID de la liste secondaire. L’interface utilisateur renomme ce paramètre en Location.Id pour rendre le nom de colonne unique. Nous allons maintenant utiliser ces informations pour fusionner les tables.
En cliquant avec le bouton droit sur le volet de requête et en sélectionnant Nouvelle requête>combiner>des requêtes de fusion en tant que nouvelles, vous voyez une interface utilisateur conviviale pour vous aider à combiner ces deux requêtes.
Sélectionnez chaque table dans la liste déroulante pour afficher un aperçu de la requête.
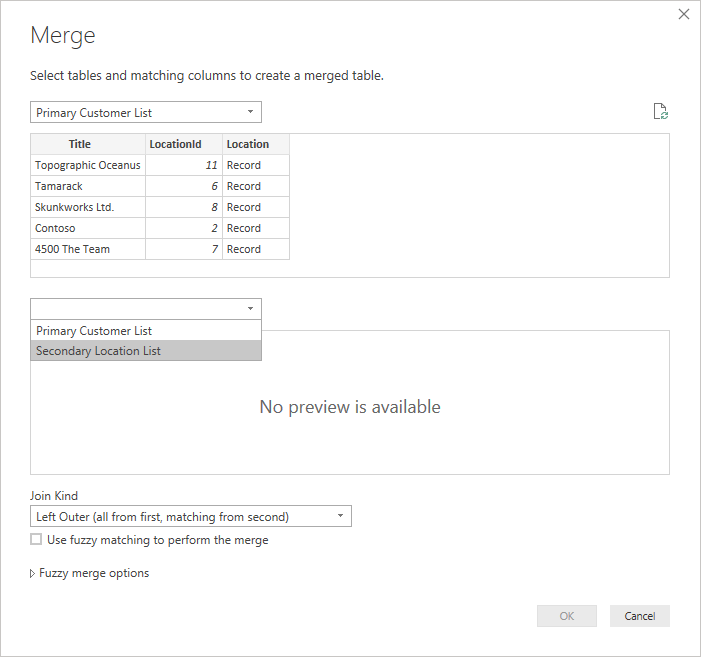
Une fois que vous avez sélectionné les deux tables, sélectionnez la colonne qui joint les tables logiquement (dans cet exemple, il s’agit de LocationId à partir de la table primaire et de l’ID de la table secondaire). La boîte de dialogue vous indiquera combien de lignes correspondent en utilisant cette clé étrangère. Vous souhaiterez probablement utiliser le type de jointure par défaut (externe gauche) pour ce type de données.
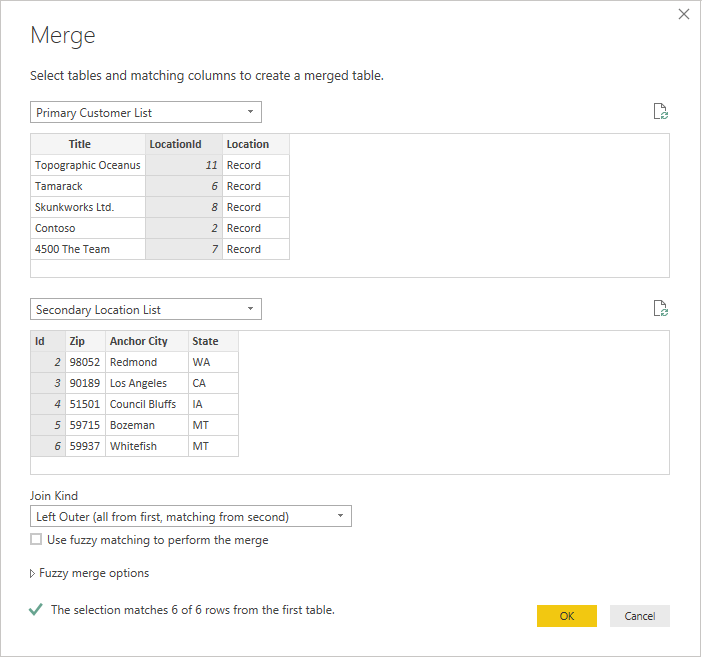
Sélectionnez OK et vous verrez une nouvelle requête, qui est le résultat de la jointure. Étendre l'enregistrement maintenant n'implique pas d'appels supplémentaires au backend.

L’actualisation de ces données entraîne seulement deux appels à SharePoint , un pour la liste principale et un pour la liste secondaire. La jointure sera effectuée en mémoire, réduisant considérablement le nombre d’appels à SharePoint.
Cette approche peut être utilisée pour deux tables dans PowerQuery qui ont une clé étrangère correspondante.
Note
Les listes d’utilisateurs et la taxonomie SharePoint sont également accessibles en tant que tables et peuvent être jointes exactement comme décrit ci-dessus, à condition que l’utilisateur dispose de privilèges adéquats pour accéder à ces listes.