Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Après avoir enregistré les diagnostics que vous souhaitez utiliser, l’étape suivante consiste à comprendre ce qu’ils disent.
Il est utile d’avoir une bonne compréhension de ce que signifie chaque colonne du schéma de diagnostic de requête. Ce didacticiel ne couvre pas ces informations. Pour obtenir une description complète, consultez Diagnostics de requête.
En général, lorsque vous générez des visualisations, utilisez la table détaillée complète. Quel que soit le nombre de lignes qu’il contient, vous regardez probablement une représentation de la manière dont s’additionne le temps passé sur différentes ressources, ou la requête native générée.
Comme mentionné dans l’article sur l’enregistrement des diagnostics, cet exemple fonctionne avec les traces OData et SQL pour la table Customers de Northwind. En particulier, l’accent est mis sur une demande commune des clients et sur l’un des ensembles de traces plus faciles à interpréter : actualisation complète du modèle de données.
Créer les visualisations
Lorsque vous passez en revue les traces, vous pouvez les évaluer de plusieurs façons. Cet article décrit deux visualisations. La première visualisation montre les détails dont vous vous souciez, et l’autre montre les contributions temporelles de différents facteurs. Pour la première visualisation, utilisez une table. Vous pouvez choisir les champs que vous aimez, mais pour un aperçu simple et général de ce qui se passe, utilisez les champs suivants :
- Id
- Heure de début
- Requête
- Step
- Requête de source de données
- Durée exclusive (%)
- Nombre de lignes
- Catégorie
- Est une requête utilisateur
- Chemin d’accès
Pour la deuxième visualisation, utilisez un histogramme empilé. Dans le paramètre Axe , utilisez l’ID ou l’étape. Si vous regardez le Refresh, puisqu’il n’a rien à voir avec les étapes de l’Editor lui-même, vous voudrez probablement simplement consulter Id. Pour le paramètre Legend, définissez Category ou Operation (selon le niveau de granularité souhaité). Pour le paramètre Valeur , définissez La durée exclusive et assurez-vous qu’elle n’est pas la %, afin d’obtenir la valeur de durée brute. Enfin, pour le paramètre Info-bulle , définissez l’heure de début la plus ancienne.
Après avoir généré votre visualisation, veillez à trier par heure de début la plus ancienne par ordre croissant afin de voir l’ordre dans lequel les événements se produisent.
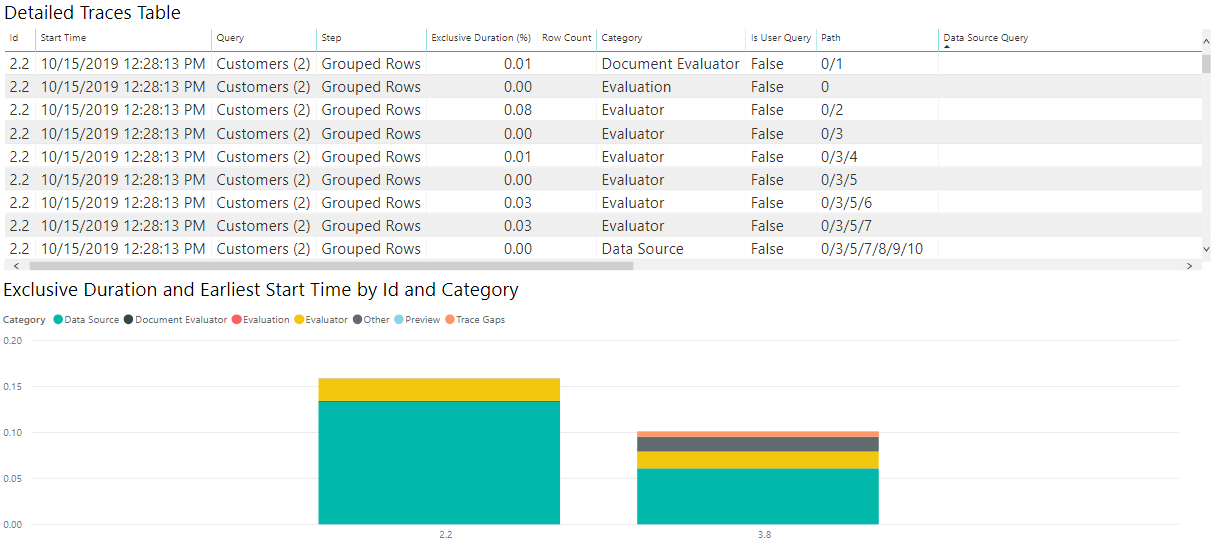
Bien que vos besoins exacts diffèrent, cette combinaison de graphiques est un bon endroit pour commencer à examiner de nombreux fichiers de diagnostic et à de nombreuses fins.
Interpréter les visualisations
Comme mentionné précédemment, les diagnostics de requête peuvent vous aider à répondre à de nombreuses questions. Les deux questions les plus courantes sont la façon dont le temps est passé et la requête envoyée à la source.
Il est simple de comprendre comment le temps est utilisé, et cela fonctionne de manière similaire pour la plupart des connecteurs. Toutefois, comme mentionné ailleurs, vous voyez des fonctionnalités radicalement différentes en fonction du connecteur. Par exemple, de nombreux connecteurs ODBC ne fournissent pas d'enregistrement précis de la requête que Power Query envoie au pilote ODBC.
Pour voir comment le temps est passé, passez en revue les visualisations que vous avez créées précédemment.
Étant donné que les valeurs temporelles des requêtes d’exemple utilisées ici sont très faibles, si vous souhaitez travailler avec la manière dont Power BI affiche les durées, il est préférable de convertir la colonne Durée exclusive en secondes dans l’éditeur Power Query. Après avoir effectué cette conversion, vous pouvez examiner votre graphique et obtenir une idée claire de l’endroit où le temps est passé.
Pour les résultats OData, l’image suivante montre que la plupart du temps est passé à récupérer les données de la source. Si vous sélectionnez l’élément source de données sur la légende, il affiche toutes les différentes opérations liées à l’envoi d’une requête à la source de données.
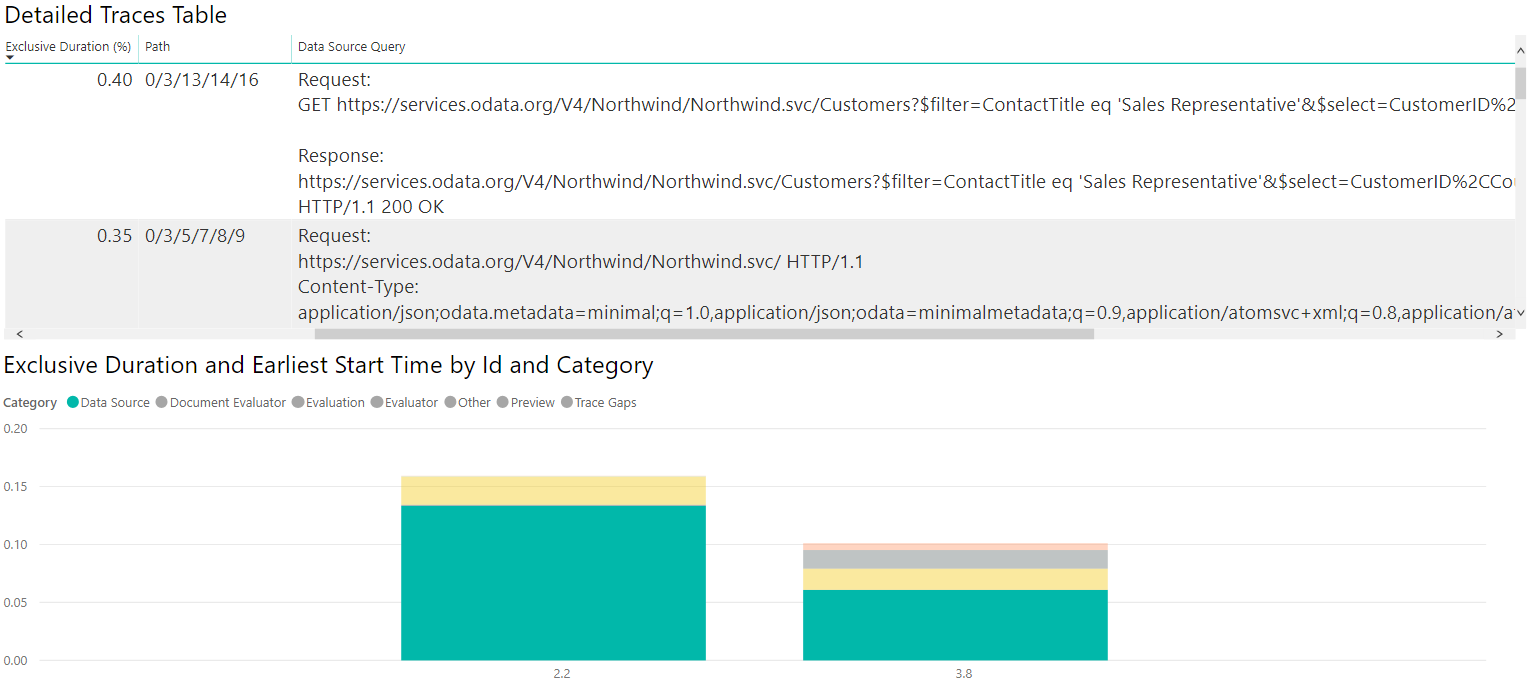
Si vous effectuez toutes les mêmes opérations et créez des visualisations similaires, mais utilisez les traces SQL au lieu des opérations ODATA, vous pouvez voir comment les deux sources de données sont comparées.
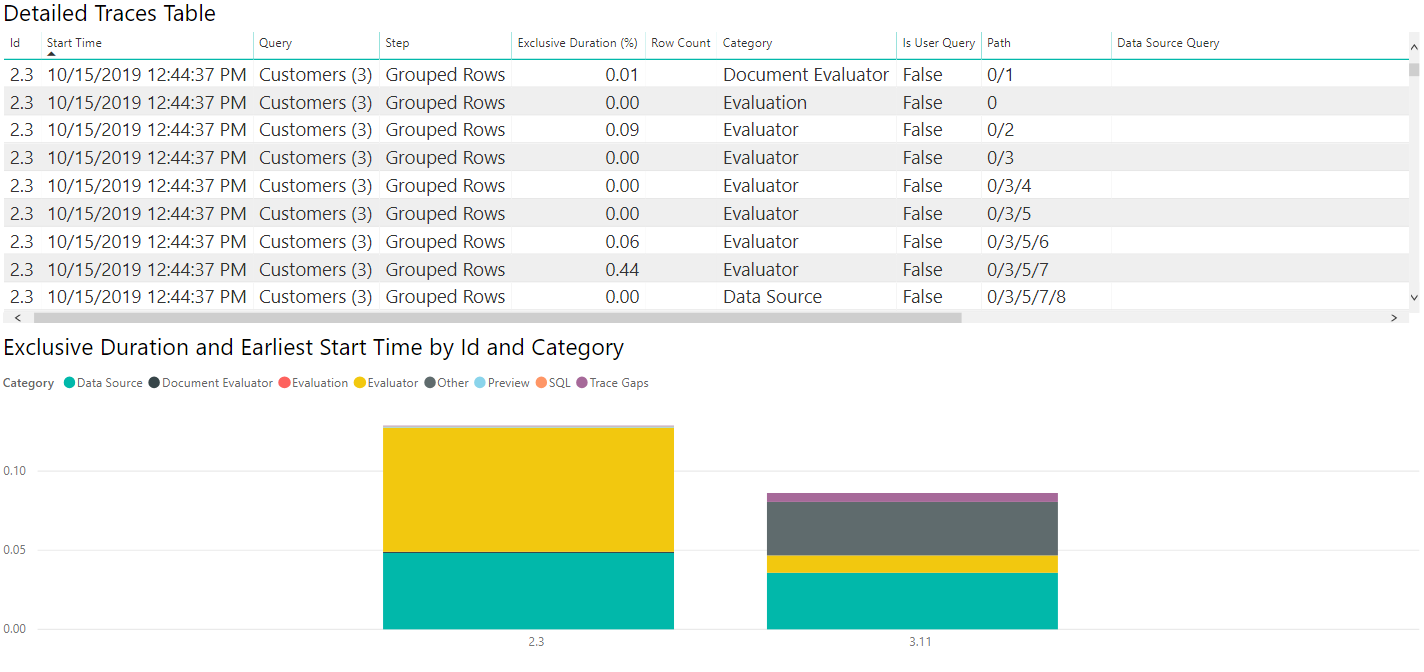
Si vous sélectionnez la table de source de données, comme avec les diagnostics ODATA, vous voyez que la première évaluation (2.3 dans cette image) envoie des requêtes de métadonnées, et la deuxième évaluation récupère les données dont vous vous souciez. Cet exemple récupère de petites quantités de données, de sorte que la récupération des données prend peu de temps (moins d’un dixième de seconde pour la deuxième évaluation dans son ensemble, et moins d’un vingtième de seconde pour la récupération des données elle-même), mais cette rapidité ne se vérifie pas dans tous les cas.
Comme précédemment, sélectionnez la catégorie source de données dans la légende pour afficher les requêtes émises.
Explorer les données
Examiner les chemins
Lorsque vous examinez ces données, vous remarquerez peut-être que le temps passé semble inhabituel. Par exemple, sur la requête OData, vous pouvez voir qu’il existe une requête de source de données avec la valeur suivante :
Request:
https://services.odata.org/V4/Northwind/Northwind.svc/Customers?$filter=ContactTitle%20eq%20%27Sales%20Representative%27&$select=CustomerID%2CCountry HTTP/1.1
Content-Type: application/json;odata.metadata=minimal;q=1.0,application/json;odata=minimalmetadata;q=0.9,application/atomsvc+xml;q=0.8,application/atom+xml;q=0.8,application/xml;q=0.7,text/plain;q=0.7
<Content placeholder>
Response:
Content-Type: application/json;odata.metadata=minimal;q=1.0,application/json;odata=minimalmetadata;q=0.9,application/atomsvc+xml;q=0.8,application/atom+xml;q=0.8,application/xml;q=0.7,text/plain;q=0.7
Content-Length: 435
<Content placeholder>
Cette requête de source de données est associée à une opération qui ne représente, par exemple, que 1 % de la durée exclusive. Entre-temps, il y en a un similaire :
Request:
GET https://services.odata.org/V4/Northwind/Northwind.svc/Customers?$filter=ContactTitle eq 'Sales Representative'&$select=CustomerID%2CCountry HTTP/1.1
Response:
https://services.odata.org/V4/Northwind/Northwind.svc/Customers?$filter=ContactTitle eq 'Sales Representative'&$select=CustomerID%2CCountry
HTTP/1.1 200 OK
Cette requête de source de données est associée à une opération qui représente près de 75 % de la durée exclusive. Si vous activez le Chemin, vous découvrez que ce dernier est en fait un enfant de l'autre. Ce constat signifie que la première requête n’ajoute en soi qu’un faible surcoût temporel, la récupération réelle des données étant mesurée par la requête inner.
Ces valeurs sont extrêmes, mais elles se trouvent dans les limites de ce que vous pouvez voir.