L’intelligence artificielle offre le potentiel permettant de transformer le secteur de la distribution tel que nous le connaissons aujourd’hui. Il est raisonnable de penser que les commerçants vont développer une architecture d’expérience client prise en charge par l’intelligence artificielle. Une plateforme améliorée avec l’intelligence artificielle devrait engendrer une hausse significative du chiffre d’affaires grâce à l’hyper-personnalisation. Le commerce numérique intensifie sans cesse les attentes, les préférences et le comportement des clients. Les exigences, comme les engagements en temps réel, les suggestions pertinentes et l’hyper-personnalisation, offrent un côté pratique et rapide à un clic de bouton. Nous mettons en œuvre l’intelligence dans les applications par l’intermédiaire du langage naturel, de la reconnaissance visuelle, etc. Cette intelligence entraîne des améliorations de la distribution qui suscitent un plus grand attrait tout en changeant le mode d’achat des clients.
Ce document se concentre sur le concept d’intelligence artificielle de recherche visuelle et formule quelques observations importantes sur son implémentation. Il fournit un exemple de workflow et établit une correspondance entre ses phases et les technologies Azure appropriées. Le concept se base sur la capacité des clients à exploiter une image prise avec leur appareil mobile ou trouvée sur Internet. Ils vont effectuer une recherche d’articles pertinents et similaires, en fonction de l’intention de l’expérience. Ainsi, la recherche visuelle améliore la vitesse, passant de l’entrée d’un texte à une image dont les différents points de métadonnées permettent d’exposer rapidement tous les articles pertinents disponibles.
Moteurs de recherche visuelle
Les moteurs de recherche visuelle récupèrent les informations en utilisant des images en tant qu’entrée et souvent, mais pas exclusivement, en tant que sortie.
Les moteurs sont de plus en plus courants dans le secteur de la distribution, et ce pour de très bonnes raisons :
- Environ 75 % des internautes recherchent des images ou des vidéos d’un produit avant d’effectuer un achat, selon un rapport Emarketer publié en 2017.
- De plus, 74 % des consommateurs trouvent que les recherches de texte sont inefficaces, selon un rapport de Slyce (société spécialisée dans la recherche visuelle) publié en 2015.
Ainsi, le marché de la reconnaissance d’image représentera plus de 25 milliards de dollars d’ici 2019, selon une étude effectuée par Markets & Markets.
La technologie a déjà séduit des marques e-commerce majeures, qui ont largement contribué à son développement. Les utilisateurs précoces les plus importants sont probablement :
- eBay, dont l’application propose les outils « Image Search » et « Find It on eBay » (il s’agit pour le moment uniquement d’une expérience mobile).
- Pinterest, avec l’outil de découverte visuelle Lens.
- Microsoft, avec Recherche visuelle Bing.
Adopter et adapter
Heureusement, vous n’avez pas besoin de quantités importantes de puissance de calcul pour bénéficier de la recherche visuelle. Toute entreprise disposant d’un catalogue d’images peut tirer parti de l’expertise d’intelligence artificielle de Microsoft intégrée à ses services Azure.
L’API Recherche visuelle Bing permet d’extraire des informations de contexte à partir d’images, en identifiant, par exemple, du mobilier, des vêtements, différents types de produits, etc.
En outre, elle retourne des images similaires à partir de son propre catalogue, de produits avec des sources d’achat connexes et de recherches associées. Bien que cette technologie soit intéressante, son utilité est limitée si votre entreprise n’est pas une de ces sources.
Bing fournit également :
- Des étiquettes qui vous permettent d’explorer les objets ou les concepts trouvés dans l’image.
- Des rectangles englobants pour les régions dignes d’intérêt dans l’image (comme les vêtements ou meubles).
Vous pouvez utiliser ces informations pour réduire l’espace de recherche (et le temps) dans le catalogue de produits d’une société de manière significative, la limitant aux objets tels que ceux de la catégorie et de la région dignes d’intérêt.
Implémenter votre propre recherche visuelle
Vous devez prendre en compte quelques éléments essentiels quand vous implémentez la recherche visuelle :
- Ingestion et filtrage des images
- Techniques de stockage et de récupération
- Caractérisation, encodage ou « hachage »
- Mesures de similarité ou distances et classement
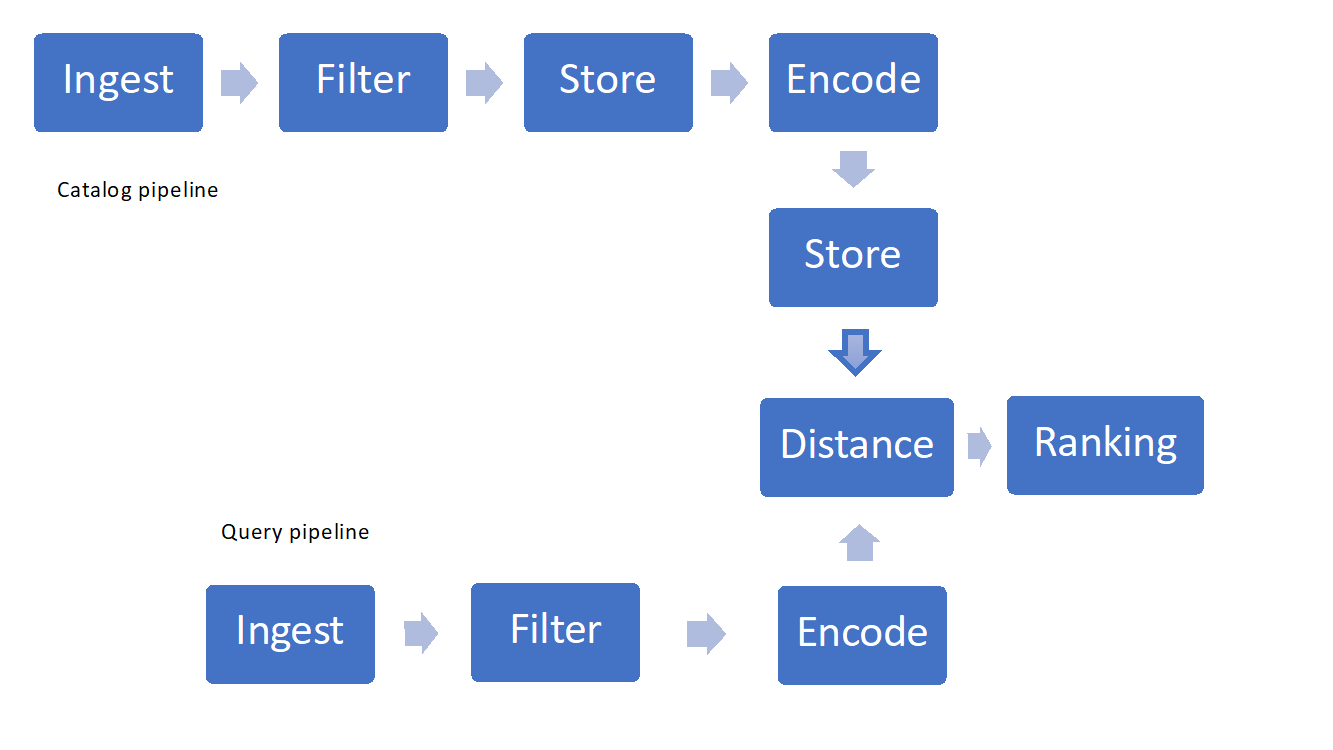
Figure 1 : exemple de pipeline de recherche visuelle
Approvisionnement en images
Si vous ne possédez pas de catalogue d’images, vous pouvez être amené à entraîner les algorithmes sur des jeux de données universellement disponibles, tels que Fashion MNIST, DeepFashion, etc. Ils contiennent plusieurs catégories de produits et sont couramment utilisés pour évaluer les algorithmes de catégorisation et de recherche d’image.

Figure 2 : exemple de jeu de données DeepFashion
Filtrage des images
La plupart des jeux de données d’évaluation, tels que ceux cités précédemment, ont déjà été prétraités.
Si vous générez le vôtre, il convient au minimum que les images aient toutes la même taille, principalement dictée par l’entrée pour laquelle votre modèle est entraîné.
Dans de nombreux cas, il convient également de normaliser la luminosité des images. Selon le niveau de détail de la recherche, la couleur peut être porteuse d’informations redondantes ; une conversion en noir et blanc peut donc aider à réduire les temps de traitement.
Enfin, le jeu de données d’images doit être équilibré entre les différentes classes qu’il représente.
Base de données d’images
La couche données est un composant particulièrement délicat de votre architecture. Elle contient les éléments suivants :
- Images
- Toutes les métadonnées sur les images (taille, étiquettes, références SKU de produit, description)
- Données générées par le modèle Machine Learning (par exemple, vecteur numérique de 4096 éléments par image)
Quand vous récupérez des images de différentes sources ou utilisez des modèles Machine Learning pour optimiser les performances, la structure des données change. Il est donc important de choisir une technologie ou une combinaison qui peut traiter des données semi-structurées, et non pas un schéma fixe.
Vous souhaiterez également obtenir un nombre minimal de points de données utiles (comme une clé ou un identificateur d’image, une référence SKU de produit, une description ou un champ d’étiquette).
Azure Cosmos DB offre la flexibilité nécessaire et une variété de mécanismes d’accès pour les applications qu’il prend en charge (ce qui facilite les recherches dans votre catalogue). Toutefois, vous devez déterminer le meilleur rapport prix/performances. Azure Cosmos DB permet le stockage d’attachements de documents, mais l’existence d’une limite totale par compte peut rendre cette offre onéreuse. Il est courant de stocker les fichiers image réels dans des objets blob et d’insérer un lien vers ces derniers dans la base de données. Dans le cas d’Azure Cosmos DB, cela implique la création d’un document qui contient les propriétés du catalogue associées à l’image concernée (comme une référence SKU, une étiquette, etc.) et d’un attachement qui contient l’URL du fichier image (par exemple, sur le stockage blob Azure, OneDrive, etc.).
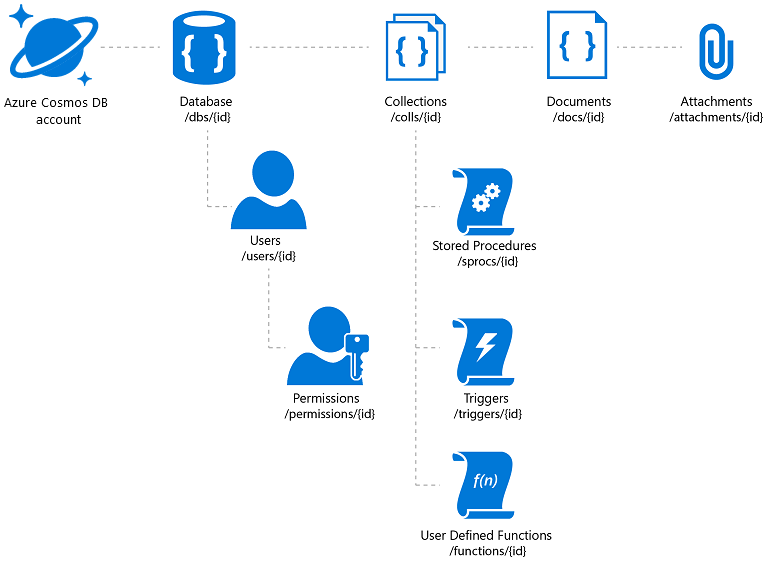
Figure 3 : modèle de ressource hiérarchique Azure Cosmos DB
Si vous souhaitez tirer parti de la distribution mondiale d’Azure Cosmos DB, notez qu’il réplique les documents et les attachements, mais pas les fichiers liés. Un réseau de distribution de contenu peut être envisageable pour ces derniers.
Parmi les autres technologies applicables citons une combinaison d’Azure SQL Database (si le schéma fixe est acceptable) et d’objets blob, ou même de tables Azure et d’objets blob pour un stockage et une récupération rapides et abordables.
Extraction des caractéristiques et encodage
Le processus d’encodage extrait les caractéristiques principales des images dans la base de données et mappe chacune d’elles à un vecteur de « caractéristiques » creux (vecteur comportant de nombreux zéros) qui peut avoir des milliers de composants. Ce vecteur est une représentation numérique des caractéristiques (comme les bords et les formes) de l’image. Il est similaire à un code.
Les techniques d’extraction des caractéristiques utilisent généralement des mécanismes d’apprentissage par transfert. Ces mécanismes entrent en jeu quand vous sélectionnez un réseau neuronal pré-entraîné, exécutez chaque image par son intermédiaire et stockez dans votre base de données d’images le vecteur de caractéristiques généré. De cette façon, vous « transférez » l’apprentissage réalisée par la personne qui a entraîné le réseau. Microsoft a développé et publié plusieurs réseaux pré-entraînés qui ont été largement utilisés pour les tâches de reconnaissance d’image, tels que ResNet-50.
En fonction du réseau neuronal, le vecteur de caractéristiques est plus ou moins long et creux ; les exigences en mémoire et stockage sont donc susceptibles de varier.
En outre, différents réseaux étant applicables à différentes catégories, une implémentation de la recherche visuelle peut générer des vecteurs de caractéristiques de taille variable.
Les réseaux neuronaux préentraînés sont relativement faciles à utiliser, mais peuvent ne pas être aussi efficaces qu’un modèle personnalisé entraîné sur votre catalogue d’images. Ces réseaux pré-entraînés sont généralement conçus pour la classification de jeux de données d’évaluation plutôt que pour la recherche sur votre propre collection d’images.
Vous pouvez les modifier et les ré-entraîner afin qu’ils produisent à la fois une prédiction de catégorie et un vecteur dense (autrement dit, plus petit, et non creux), ce qui permet de limiter efficacement l’espace de recherche et de réduire les besoins en mémoire et stockage. Vous pouvez utiliser des vecteurs binaires. Ces derniers sont souvent désignés par le terme « hachage sémantique », dérivé de techniques de codage et de récupération de document. La représentation binaire simplifie davantage les calculs.
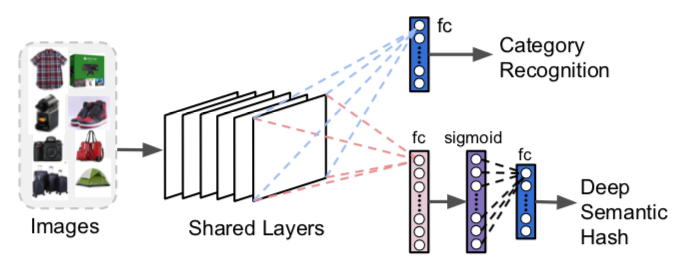
Figure 4 : modifications de ResNet pour la recherche visuelle – F. Yang et al., 2017
Que vous optiez pour des modèles pré-entraînés ou développiez votre modèle, vous devez toujours décider où exécuter la caractérisation et/ou l’entraînement du modèle lui-même.
Azure offre plusieurs options : clusters Databricks, Batch AI, Azure Batch et machines virtuelles. Dans tous les cas, toutefois, l’utilisation de GPU permet d’obtenir le meilleur rapport prix/performances.
En outre, Microsoft a récemment annoncé la disponibilité de FPGA pour le calcul rapide à un coût inférieur à celui des GPU (projet Brainwave). Toutefois, cette offre étant limitée à certaines architectures réseau au moment de la rédaction du présent document, vous devrez évaluer leurs performances minutieusement.
Mesure de similarité ou distance
Quand les images sont représentées dans l’espace du vecteur de caractéristiques, la recherche de similarités consiste à définir une mesure de distance entre les points de cet espace. Une fois qu’une distance est définie, vous pouvez calculer des clusters d’images similaires et/ou définir des matrices de similarité. Suivant la métrique de distance sélectionnée, les résultats peuvent varier. Par exemple, la mesure de la distance euclidienne sur des vecteurs de nombres réels, qui est la plus courante, est facile à comprendre : elle capture la grandeur de la distance. Toutefois, elle est plutôt inefficace en termes de calcul.
La distance cosinus est souvent utilisée pour capturer l’orientation du vecteur, plutôt que sa grandeur.
Des alternatives telles que la distance de Hamming sur des représentations binaires trouvent un équilibre entre précision d’une part, et efficacité et vitesse d’autre part.
La combinaison de la mesure de la distance et de la taille du vecteur détermine dans quelle proportion la recherche est susceptible d’être gourmande en calcul et en mémoire.
Recherche et classement
Une fois la similarité définie, nous devons concevoir une méthode efficace pour récupérer les N éléments les plus proches de celui transmis en entrée, puis retourner une liste d’identificateurs. Cette méthode s’appelle également « classement d’images ». Sur un grand jeu de données, le temps pour calculer chaque distance est prohibitif ; nous utilisons donc des algorithmes de type « plus proches voisins ». Plusieurs bibliothèques open source existant pour ces derniers, vous n’aurez pas à les coder à partir de zéro.
Enfin, les exigences de mémoire, de calcul et de haute disponibilité déterminent le choix de la technologie de déploiement pour le modèle entrainé. En règle générale, l’espace de recherche étant partitionné, plusieurs instances de l’algorithme de classement s’exécutent en parallèle. Les clusters Azure Kubernetes constituent une option permettant scalabilité et disponibilité. Dans ce cas, nous vous recommandons de déployer le modèle de classement sur plusieurs conteneurs (chacun gérant une partition de l’espace de recherche) et sur plusieurs nœuds (pour la haute disponibilité).
Contributeurs
Cet article est géré par Microsoft. Il a été écrit à l’origine par les contributeurs suivants.
Auteurs principaux :
- Giovanni Marchetti | Manager, architectes de solutions Azure
- Mariya Zorotovich | Head of Customer Experience, HLS & Emerging Technology
Autres contributeurs :
- Scott Seely | Architecte logiciel
Étapes suivantes
L’implémentation de la recherche visuelle n’a pas besoin d’être complexe. Vous pouvez utiliser Bing ou créer votre propre recherche visuelle avec des services Azure, tout en bénéficiant des outils et de la recherche en intelligence artificielle de Microsoft.
Développer
- Pour commencer à créer un service personnalisé, consultez Vue d’ensemble de l’API Recherche visuelle Bing.
- Pour créer votre première requête, consultez les guides de démarrage rapide : C# | Java | Node.js | Python
- Familiarisez-vous avec les informations de référence sur l’API Recherche visuelle.
Arrière-plan
- Segmentation d’image pour l’apprentissage profond : document Microsoft décrivant le processus de séparation des images de l’arrière-plan
- Recherche visuelle sur Ebay : recherche de l’Université Cornell
- Découverte visuelle sur Pinterest : recherche de l’Université Cornell
- Hachage sémantique : recherche de l’Université de Toronto