Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Important
Le support de Machine Learning Studio (classique) prend fin le 31 août 2024. Nous vous recommandons de passer à Azure Machine Learning avant cette date.
À partir du 1er décembre 2021, vous ne pourrez plus créer de nouvelles ressources Machine Learning Studio (classique). Jusqu’au 31 août 2024, vous pouvez continuer à utiliser les ressources Machine Learning Studio (classique) existantes.
- Consultez les informations sur le déplacement des projets de machine learning de ML Studio (classique) à Azure Machine Learning.
- En savoir plus sur Azure Machine Learning.
La documentation ML Studio (classique) est en cours de retrait et ne sera probablement plus mise à jour.
Configure et initialise un modèle K-means clustering
Catégorie : Machine Learning / Initialiser le modèle / Clustering
Notes
S’applique à : Machine Learning Studio (classique) uniquement
Des modules par glisser-déposer similaires sont disponibles dans Concepteur Azure Machine Learning.
Vue d’ensemble du module
Cet article explique comment utiliser le module de clustering K-Means dans Machine Learning Studio (classique) pour créer un modèle K-means clustering non formé.
K-moyennes est l’un des algorithmes d’apprentissage non supervisés les plus simples et les plus connus, et peut être utilisé pour diverses tâches d’apprentissage automatique, telles que la détection de données anormales, clustering de documents texte et l’analyse d’un jeu de données avant d’utiliser d’autres méthodes de classification ou de régression. Pour créer un modèle clustering, vous ajoutez ce module à votre expérience, connectez un jeu de données et définissez des paramètres tels que le nombre de clusters que vous attendez, la métrique de distance à utiliser pour créer les clusters, etc.
Une fois que vous avez configuré les hyperparamètres de module, connectez le modèle non entraîné au modèle de clustering d’apprentissage ou aux modules de clustering de balayage pour entraîner le modèle sur les données d’entrée que vous fournissez. Étant donné que l’algorithme k-moyennes est une méthode d’apprentissage non supervisée, une colonne d’étiquette est facultative.
- Si vos données incluent une étiquette, vous pouvez utiliser les valeurs d’étiquette pour guider la sélection des clusters et optimiser le modèle.
- Si vos données n’ont aucune étiquette, l’algorithme crée des clusters qui représentent les catégories possibles, uniquement en fonction des données.
Conseil
Si vos données d’apprentissage ont des étiquettes, envisagez d’utiliser l’une des méthodes de classification supervisées fournies dans Machine Learning. Par exemple, vous pouvez comparer les résultats de clustering aux résultats lors de l’utilisation de l’un des algorithmes d’arborescence de décision multiclasse.
Présentation de k-moyennes clustering
En général, le clustering fait appel à des techniques itératives pour regrouper les cas d'un jeu de données dans des clusters qui présentent des caractéristiques similaires. Ces regroupements sont utiles pour explorer des données, identifier les anomalies dans les données et élaborer des prédictions. Les modèles de clustering peuvent aussi vous aider à identifier des relations dans un jeu de données que vous pourriez ne pas obtenir en naviguant ou simplement en observant. Pour ces raisons, le clustering est souvent utilisé dans les premières phases des tâches d’apprentissage automatique, pour explorer les données et découvrir des corrélations inattendues.
Lorsque vous configurez un modèle clustering à l’aide de la méthode k-means, vous devez spécifier un nombre cible k indiquant le nombre de centroïdes souhaités dans le modèle. Le centroïde est un point qui est représentatif de chaque cluster. L’algorithme k-moyennes attribue chaque point de données entrantes à l’un des clusters en minimisant la somme des carrés au sein du cluster.
Lors du traitement des données d’entraînement, l’algorithme K-moyennes commence par un ensemble initial de centroïdes choisis de manière aléatoire, qui servent de points de départ pour chaque cluster, et applique l’algorithme de Lloyd pour affiner de manière itérative les emplacements des centroïdes. L’algorithme k-moyennes cesse de créer et affiner des clusters lorsqu’il répond à une ou plusieurs de ces conditions :
Les centroïdes se stabilisent, ce qui signifie que les affectations de cluster pour des points individuels ne changent plus et que l’algorithme a convergé vers une solution.
L’algorithme a terminé l’exécution du nombre spécifié d’itérations.
Une fois la phase d’apprentissage terminée, vous utilisez le module Affecter des données à des clusters pour affecter de nouveaux cas à l’un des clusters trouvés par l’algorithme k-means. L’attribution de cluster est effectuée en calculant la distance entre le nouveau cas et le centroïde de chaque cluster. Chaque nouveau cas est attribué au cluster au centroïde le plus proche.
Comment configurer le clustering K-Means
Ajoutez le module Clustering k-moyennes à votre expérience.
Spécifiez le mode d’apprentissage du modèle en définissant l’option Créer un mode d’apprentissage.
Single Parameter (Paramètre unique) : Si vous connaissez les paramètres exacts que vous souhaitez utiliser dans le modèle de clustering, vous pouvez fournir un ensemble spécifique de valeurs comme arguments.
Plage de paramètres : si vous n’êtes pas sûr des meilleurs paramètres, vous pouvez trouver les paramètres optimaux en spécifiant plusieurs valeurs et en utilisant le module Balayage du clustering pour trouver la configuration optimale.
Le formateur itère sur plusieurs combinaisons des paramètres que vous avez fournis et détermine la combinaison de valeurs qui produit les résultats clustering optimaux.
Pour Nombre de centroïdes, tapez le nombre de clusters dont vous souhaitez que l’algorithme commence.
Il n’est pas garanti que le modèle produise exactement ce nombre de clusters. L’algorithn commence par ce nombre de points de données et itère pour trouver la configuration optimale, comme décrit dans la section Notes techniques .
Si vous effectuez un balayage de paramètre, le nom de la propriété devient Range for Number of Centroids. Vous pouvez utiliser le Générateur de plages pour spécifier une plage, ou vous pouvez taper une série de nombres représentant différents nombres de clusters à créer lors de l’initialisation de chaque modèle.
Les propriétés Initialisation ou Initialisation pour le balayage sont utilisées pour spécifier l’algorithme utilisé pour définir la configuration initiale du cluster.
Premier N : un nombre initial de points de données est choisi dans le jeu de données et utilisé comme moyen initial.
Également appelée méthode Forgy.
Aléatoire : L’algorithme place au hasard un point de données dans un cluster avant de calculer la moyenne initiale, qui sera le centroïde des points attribués aléatoirement du cluster.
Également appelée méthode de partition aléatoire .
K-moyennes ++ : Il s’agit de la méthode par défaut pour l’initialisation de clusters.
L’algorithme K-moyennes ++ a été proposé en 2007 par David Arthur et Sergei Vassilvitskii pour éviter les mauvaises clustering par l’algorithme k-moyennes standard. K-means ++ améliore les K-moyennes standard en utilisant une méthode différente pour choisir les centres de cluster initiaux.
K-Means++Fast : variante de l’algorithme K-moyennes ++ qui a été optimisée pour une clustering plus rapide.
Uniformément : les centroïdes sont situés à égale distance les uns des autres dans l’espace d-Dimension de n points de données.
Utiliser une colonne d’étiquette : les valeurs de la colonne d’étiquette sont utilisées pour guider la sélection des centroïdes.
Pour Valeur de départ numérique aléatoire, vous pouvez éventuellement saisir une valeur à utiliser comme valeur initiale pour l’initialisation de cluster. Cette valeur peut avoir un effet significatif sur la sélection du cluster.
Si vous utilisez un balayage de paramètre, vous pouvez spécifier que plusieurs graines initiales sont créées pour rechercher la meilleure valeur initiale. Pour Nombre de graines à balayer, tapez le nombre total de valeurs de départ aléatoires à utiliser comme points de départ.
Pour Métrique, choisissez la fonction à utiliser pour mesurer la distance entre des vecteurs de cluster, ou entre les nouveaux points de données et le centroïde choisi au hasard. Machine Learning prend en charge les métriques de distance de cluster suivantes :
Euclidienne : La distance Euclidienne est couramment utilisée pour mesure l’écart de cluster pour le clustering k-moyennes. Cette métrique est recommandée car elle minimise la distance moyenne entre les points et les centroïdes.
Cosinus : la fonction cosinus est utilisée pour mesurer la similarité du cluster. La similarité cosinus est utile dans les cas où vous ne vous souciez pas de la longueur d’un vecteur, seulement de son angle.
Pour Itérations, tapez le nombre de fois où l’algorithme doit itérer sur les données d’entraînement avant de finaliser la sélection des centroïdes.
Vous pouvez ajuster ce paramètre pour équilibrer la précision et le temps d’entraînement.
Pour Attribuer le mode d’étiquette, choisissez une option qui spécifie la façon dont une colonne d’étiquette, si elle est présente dans le jeu de données, doit être gérée.
Étant donné que le clustering k-moyennes est une méthode d’apprentissage automatique non supervisé, les étiquettes sont facultatives. Toutefois, si votre jeu de données a déjà une colonne d’étiquette, vous pouvez utiliser ces valeurs pour guider la sélection des clusters, ou vous pouvez spécifier que les valeurs sont ignorées.
Ignorer la colonne d’étiquette : Les valeurs dans la colonne d’étiquette sont ignorées et ne sont pas utilisées pour générer le modèle.
Indiquer les valeurs manquantes : Les valeurs de la colonne d’étiquette sont utilisées en tant que fonctionnalités pour aider à créer les clusters. S’il manque une étiquette à une valeur, cette dernière est attribuée à l’aide d’autres fonctionnalités.
Remplacer du plus proche au centre : Les valeurs de la colonne d’étiquette sont remplacées par les valeurs d’étiquette prédites, à l’aide de l’étiquette du point le plus proche du centroïde actuel.
Effectuez l’apprentissage du modèle.
Si vous définissez le mode Create trainer (Créer formateur) sur Paramètre unique, ajoutez un jeu de données balisé et formez le modèle à l’aide du module Train Clustering Model.
Si vous définissez Le mode Créer un formateur sur Plage de paramètres, ajoutez un jeu de données étiqueté et entraînez le modèle à l’aide du balayage du clustering. Vous pouvez utiliser le modèle formé à l'aide de ces paramètres, ou vous noter les paramètres à utiliser lors de la configuration d'un apprenant.
Résultats
Une fois que vous avez terminé la configuration et l’entraînement du modèle, vous disposez d’un modèle que vous pouvez utiliser pour générer des scores. Toutefois, il existe plusieurs façons de former le modèle, ainsi que plusieurs méthodes pour afficher et utiliser les résultats :
Capturer un instantané du modèle dans votre espace de travail
Si vous avez utilisé le module Entraîner le modèle de clustering
- Cliquez avec le bouton droit sur le module Train Clustering Model.
- Sélectionnez Modèle entraîné , puis cliquez sur Enregistrer en tant que modèle entraîné.
Si vous avez utilisé le module Balayage du clustering pour entraîner le modèle
- Cliquez avec le bouton droit sur le module Balayage du clustering .
- Sélectionnez Meilleur modèle entraîné , puis cliquez sur Enregistrer en tant que modèle entraîné.
Le modèle enregistré représentera les données d’entraînement au moment où vous avez enregistré le modèle. Si vous mettez à jour ultérieurement les données d’entraînement utilisées dans l’expérience, le modèle enregistré ne sera pas mis à jour.
Voir une représentation visuelle des clusters dans le modèle
Si vous avez utilisé le module Entraîner le modèle de clustering
- Cliquez avec le bouton droit sur le module, puis sélectionnez Jeu de données Résultats.
- Sélectionnez Visualiser.
Si vous avez utilisé le module Balayage du clustering
Ajoutez un instance du module Affecter des données à des clusters et générez des scores à l’aide du modèle le mieux entraîné.
Cliquez avec le bouton droit sur le module Attribuer des données à des clusters , sélectionnez Jeu de données résultats, puis sélectionnez Visualiser.
Le graphique est généré à l’aide de l’analyse des composants principaux, qui est une technique de science des données permettant de compresser l’espace de fonctionnalité d’un modèle. Le graphique montre un ensemble de fonctionnalités, compressées en deux dimensions, qui caractérisent le mieux la différence entre les clusters. En examinant visuellement la taille générale de l’espace de fonctionnalité pour chaque cluster et la quantité de chevauchement des clusters, vous pouvez avoir une idée de la performance de votre modèle.
Par exemple, les graphiques PCA suivants représentent les résultats de deux modèles entraînés à l’aide des mêmes données : le premier a été configuré pour générer deux clusters et le second a été configuré pour générer trois clusters. À partir de ces graphiques, vous pouvez voir que l’augmentation du nombre de clusters n’a pas nécessairement amélioré la séparation des classes.
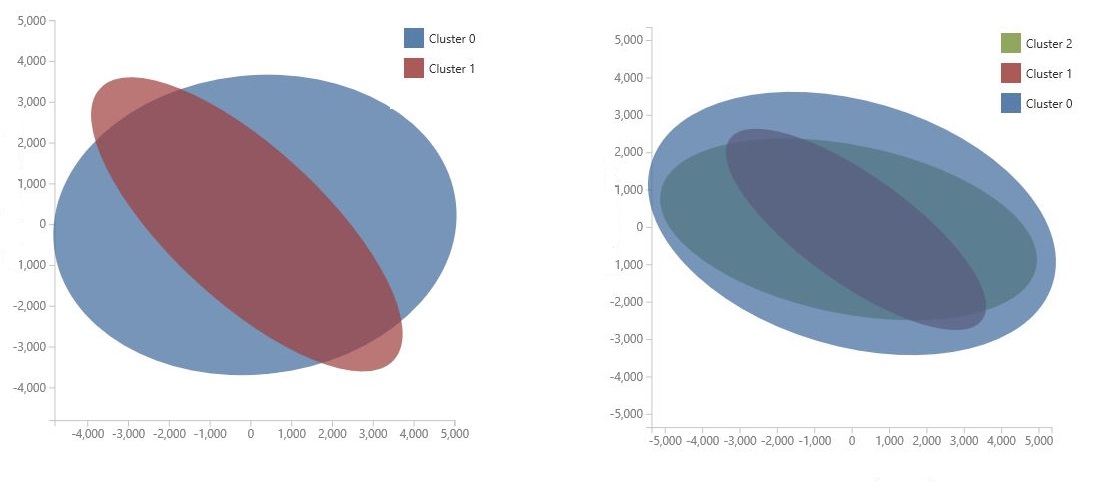
Conseil
Utilisez le module Clustering de balayage pour choisir l’ensemble optimal d’hyperparamètres, y compris la valeur initiale aléatoire et le nombre de centroïdes de départ.
Consultez la liste des points de données et les clusters auxquels ils appartiennent
Il existe deux options pour afficher le jeu de données avec des résultats, selon la façon dont vous avez entraîné le modèle :
Si vous avez utilisé le module Balayage de clustering pour entraîner le modèle
- Utilisez la case à cocher dans le module Clustering de balayage pour spécifier si vous souhaitez voir les données d’entrée avec les résultats, ou afficher uniquement les résultats.
- Une fois l’entraînement terminé, cliquez avec le bouton droit sur le module, puis sélectionnez Jeu de données résultats (numéro de sortie 2)
- Cliquez sur Visualiser.
Si vous avez utilisé le module Entraîner le modèle de clustering
- Ajoutez le module Attribuer des données à des clusters et connectez le modèle entraîné à l’entrée de gauche. Connectez un jeu de données à l’entrée de droite.
- Ajoutez le module Convertir en jeu de données à votre expérience et connectez-le à la sortie d’Attribuer des données à des clusters.
- Utilisez la case à cocher dans le module Affecter des données à des clusters pour spécifier si vous souhaitez voir les données d’entrée avec les résultats, ou uniquement les résultats.
- Exécutez l’expérience ou exécutez uniquement le module Convertir en jeu de données .
- Cliquez avec le bouton droit sur Convertir en jeu de données, sélectionnez Jeu de données résultats, puis cliquez sur Visualiser.
La sortie contient d’abord les colonnes de données d’entrée, si vous les avez incluses, et les colonnes suivantes pour chaque ligne de données d’entrée :
Affectation : l’affectation est une valeur comprise entre 1 et n, où n est le nombre total de clusters dans le modèle. Chaque ligne de données ne peut être affectée qu’à un seul cluster.
DistancesToClusterCenter no.n : cette valeur mesure la distance entre le point de données actuel et le centroïde du cluster. Une colonne distincte dans la sortie pour chaque cluster dans le modèle entraîné.
Les valeurs de distance du cluster sont basées sur la métrique de distance que vous avez sélectionnée dans l’option Métrique pour mesurer le résultat du cluster. Même si vous effectuez un balayage de paramètres sur le modèle clustering, une seule métrique peut être appliquée pendant le balayage. Si vous modifiez la métrique, vous pouvez obtenir des valeurs de distance différentes.
Visualiser les distances intra-cluster
Dans le jeu de données des résultats de la section précédente, cliquez sur la colonne distances pour chaque cluster. Studio (classique) affiche un histogramme qui visualise la distribution des distances pour les points au sein du cluster.
Par exemple, les histogrammes suivants montrent la distribution des distances de cluster à partir de la même expérience, à l’aide de quatre métriques différentes. Tous les autres paramètres du balayage des paramètres étaient identiques. La modification de la métrique a entraîné un nombre différent de clusters dans un modèle.
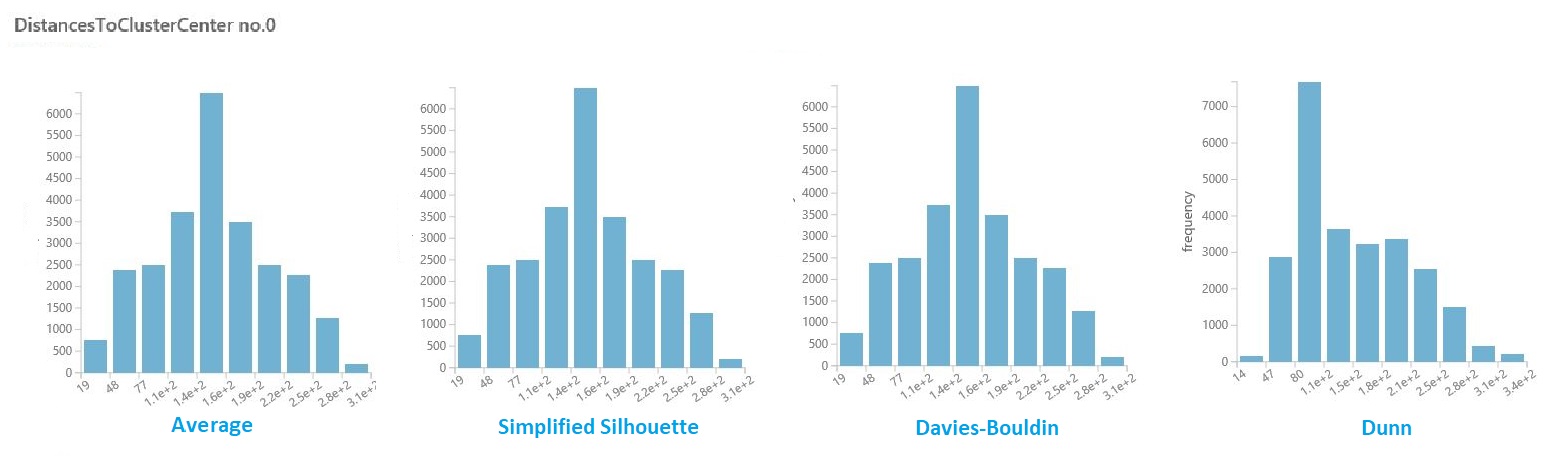
En général, vous devez choisir une métrique qui optimise la distance entre les points de données dans différentes classes et réduit les distances au sein d’une classe. Vous pouvez utiliser les moyennes précalculées et d’autres valeurs dans le volet Statistiques pour vous guider dans cette décision.
Conseil
Vous pouvez extraire des moyennes et d’autres valeurs utilisées dans les visualisations à l’aide du module PowerShell pour Le Machine Learning.
Vous pouvez également utiliser le module Exécuter un script R pour calculer une matrice de distance personnalisée.
Conseils pour générer le meilleur modèle de clustering
Il est connu que le processus d’amorçage utilisé pendant clustering peut affecter considérablement le modèle. L’ensemencement signifie le placement initial des points dans des centroïdes puissants.
Par exemple, si le jeu de données contient de nombreuses valeurs aberrantes et qu’une valeur hors norme est choisie pour amorcer les clusters, aucun autre point de données ne convient à ce cluster et le cluster peut être un singleton, c’est-à-dire un cluster avec un seul point.
Il existe plusieurs façons d’éviter ce problème :
Utilisez un balayage de paramètres pour modifier le nombre de centroïdes et essayez plusieurs valeurs de départ.
Créez plusieurs modèles, en variant la métrique ou en effectuant davantage d’itérations.
Utilisez une méthode telle que PCA pour rechercher des variables qui ont un effet néfaste sur clustering. Pour une démonstration de cette technique, consultez l’exemple Rechercher des entreprises similaires .
En général, avec clustering modèles, il est possible qu’une configuration donnée entraîne un ensemble de clusters optimisé localement. En d’autres termes, l’ensemble de clusters retourné par le modèle convient uniquement aux points de données actuels et n’est pas généralisable à d’autres données. Si vous avez utilisé une autre configuration initiale, la méthode K-means risque d'en trouver une autre, peut-être supérieure.
Important
Nous vous recommandons de toujours tester les paramètres, de créer plusieurs modèles et de comparer les modèles résultants.
Exemples
Pour obtenir des exemples d’utilisation de K-moyennes clustering dans machine learning, consultez ces expériences dans la galerie Azure AI :
Données iris de groupe : compare les résultats du clustering K-Moyennes et de la régression logistique multiclasse pour une tâche de classification.
Exemple de quantisation des couleurs : génère plusieurs modèles K-moyennes avec différents paramètres pour trouver la compression d’image optimale.
Clustering : Entreprises similaires : varie le nombre de centroïdes pour trouver des groupes de sociétés similaires dans le S&P500.
Notes techniques
À partir d'un nombre spécifique de clusters (K) à trouver pour un ensemble de points de données D-dimensionnels avec N points de données, voici comment la méthode K-means génère les clusters :
Le module initialise un tableau K-by-D avec les centroïdes finaux qui définissent les clusters K trouvés.
Par défaut, le module attribue les premiers points de données K aux clusters K .
À partir d'un ensemble initial de K centroïdes, la méthode utilise l'algorithme de Lloyd pour affiner de manière interactive les emplacements des centroïdes.
L'algorithme prend fin quand les centroïdes se stabilisent ou au bout d'un nombre déterminé d'itérations.
Une mesure de similarité (par défaut, la distance euclidienne) est utilisée pour affecter chaque point de données au cluster qui a le centroïde le plus proche.
Avertissement
- Si vous passez une plage de paramètres à Entraîner le modèle de clustering, elle utilise uniquement la première valeur de la liste de plages de paramètres.
- Si vous transmettez un ensemble unique de valeurs de paramètres au module Balayage en clustering , lorsqu’il attend une plage de paramètres pour chaque paramètre, il ignore les valeurs et utilise les valeurs par défaut pour l’apprenant.
- Si vous sélectionnez l’option Plage de paramètres et que vous entrez une valeur unique pour un paramètre, cette valeur unique que vous avez spécifiée est utilisée tout au long du balayage, même si d’autres paramètres changent sur une plage de valeurs.
Paramètres du module
| Nom | Plage | Type | Default | Description |
|---|---|---|---|---|
| Nombre de centroïdes | >=2 | Integer | 2 | Nombre de centroïdes |
| Métrique | Liste (sous-ensemble) | Métrique | Euclidien | Mesure sélectionnée |
| Initialisation | List | Méthode d'initialisation centroïde | K-Means++ | Algorithme d'initialisation |
| Itérations | >=1 | Integer | 100 | Nombre d'itérations |
Sorties
| Nom | Type | Description |
|---|---|---|
| Untrained model (Modèle non entraîné) | Interface ICluster | Modèle de clustering K-Means non entraîné |
Exceptions
Pour obtenir la liste de toutes les exceptions, consultez Codes d’erreur du module Machine Learning.
| Exception | Description |
|---|---|
| Erreur 0003 | Cette exception se produit si une ou plusieurs entrées sont null ou vide. |
Voir aussi
Clustering
Attribuer des données à des clusters
Entraîner un modèle de clustering
Sweep Clustering