SQL Server
Astuces pour une maintenance de base de données efficace
Paul S. Randal
En un coup d'œil :
- Gestion des fichiers de données et des fichiers journaux des transactions
- Élimination de la fragmentation de l'index
- Garantie de l'exactitude et de l'actualité des statistiques
- Détection des pages de bases de données corrompues
- Mise en place d'une stratégie de sauvegarde efficace
Sommaire
Gestion des fichiers de données et fichiers journaux
Fragmentation de l'index
Statistiques
Détection de corruption
Sauvegardes
Conclusion
On me demande plusieurs fois par semaine des conseils sur la façon de maintenir efficacement une base de données de production. Parfois, les questions proviennent d'administrateurs de bases de données qui implémentent de nouvelles solutions et ont besoin d'aide
pour ajuster les pratiques de maintenance aux caractéristiques de leurs nouvelles bases de données. Plus fréquemment, cependant, les questions proviennent de personnes qui ne sont pas des administrateurs de bases de données professionnels mais qui, pour une raison ou une autre, se sont retrouvées propriétaires ou responsables d'une base de données. Je les appelle « administrateurs de bases de données DBA involontaires ». Cet article vise à fournir les bases des meilleures pratiques de maintenance des bases de données pour tous les administrateurs de bases de données involontaires.
Comme pour la majorité des tâches et procédures de l'univers informatique, il n'existe pas de solution unique pour assurer une maintenance efficace des bases de données, mais certains aspects clés doivent presque toujours être traités. Mes cinq premiers domaines de préoccupation sont (dans aucun ordre d'importance particulier) :
- Gestion des fichiers de données et des fichiers journaux
- Fragmentation de l'index
- Statistiques
- Détection de corruption
- Sauvegardes
Une base de données non maintenue (ou mal maintenue) peut développer des problèmes dans un ou plusieurs de ces domaines, ce qui peut entraîner par la suite des performances médiocres des applications, voire des pannes et des pertes de données.
Dans cet article, j'expliquerai pourquoi ces questions sont importantes et vous montrerai des moyens simples de résoudre les problèmes. Je baserai mes explications sur SQL Server® 2005, mais je mettrai également en évidence les différences majeures que vous trouverez dans SQL Server 2000 et la prochaine version de SQL Server 2008.
Gestion des fichiers de données et des fichiers journaux
La première chose que je recommande toujours de vérifier lorsque l'on reprend la gestion d'une base de données concerne les paramètres liés à la gestion des fichiers de données et des fichiers journaux (des transactions). Vous devez notamment vous assurer que :
- les fichiers de données et fichiers journaux sont non seulement séparés les uns des autres, mais également isolés de tout le reste
- la croissance automatique est configurée correctement
- l'initialisation instantanée des fichiers est configurée
- la réduction automatique n'est pas activée et la réduction ne fait pas partie des plans de maintenance
Lorsque des fichiers de données et des fichiers journaux (qui devraient idéalement se trouver sur des volumes séparés) partagent un volume avec une autre application qui crée ou développe des fichiers, il existe un risque de fragmentation des fichiers. Dans les fichiers de données, une fragmentation excessive des fichiers peut contribuer à une baisse des performances des requêtes (en particulier les requêtes qui analysent de très grandes quantités de données). Dans les fichiers journaux, la fragmentation peut avoir un impact beaucoup plus important sur les performances, surtout si la croissance automatique est définie pour augmenter la taille de fichier seulement très légèrement à chaque fois que cela est nécessaire.
Les fichiers journaux sont intérieurement divisés en sections appelées Fichiers journaux virtuels et plus la fragmentation est importante dans le fichier journal (j'utilise le singulier ici parce qu'il n'y a aucun intérêt à avoir plusieurs fichiers journaux : il ne devrait y en avoir qu'un par base de données), plus le nombre de fichiers journaux virtuels est élevé. Lorsqu'un fichier journal a plus de, disons, 200 fichiers journaux virtuels, cela peut avoir un impact négatif sur les performances pour les opérations liées aux journaux telles que les lectures de journaux (pour une réplication/restauration transactionnelle, par exemple), les sauvegardes de journaux, voire les déclencheurs dans SQL Server 2000 (l'implémentation de déclencheurs est passée du journal de transactions à la structure de gestion des versions des lignes dans SQL Server 2005).
La meilleure pratique pour le calibrage des fichiers de données et fichiers journaux consiste à les créer avec une taille initiale appropriée. Pour les fichiers de données, la taille initiale doit prendre en compte l'ajout potentiel à court terme de données supplémentaires à la base de données. Par exemple, si la taille initiale des données est 50 Go, mais que vous savez que dans les six mois à venir 50 Go de données supplémentaires seront ajoutés, mieux vaut créer un fichier de données de 100 Go dès le départ, plutôt que de l'agrandir plusieurs fois jusqu'à ce qu'il atteigne cette taille.
C'est un peu plus compliqué pour les fichiers journaux, malheureusement, et vous devez tenir compte de facteurs tels que la taille des transactions (les transactions de longue durée ne peuvent pas être supprimées du journal tant qu'elles ne sont pas terminées) et la fréquence de sauvegarde du journal (puisque c'est ce qui supprime la portion inactive du journal). Pour plus d'informations, consultez « 8 Steps to Better Transaction Log Throughput », un blog très apprécié sur SQLskills.com écrit par ma femme, Kimberly Tripp.
Une fois configurées, les tailles de fichiers doivent être surveillées régulièrement et augmentées manuellement de façon proactive à une heure appropriée. La croissance automatique doit rester une protection au cas où pour que les fichiers puissent grandir au besoin si un événement anormal survient. L'argument contre la croissance automatique pour la gestion complète des fichiers est que la croissance automatique de petits volumes entraîne la fragmentation des fichiers et que la croissance automatique peut être un processus laborieux qui freine la charge de travail de l'application à des moments imprévisibles.
La taille de croissance automatique doit être définie sur une valeur spécifique, plutôt qu'un pourcentage, pour limiter le temps et l'espace nécessaires pour exécuter la croissance automatique, le cas échéant. Vous souhaiterez par exemple définir un fichier de données de 100 Go pour qu'il ait une taille de croissance automatique fixe de 5 Go, au lieu de, disons, 10 %. Ceci signifie qu'il grandira toujours de 5 Go, quelle que soit la taille finale du fichier, plutôt qu'un volume sans cesse croissant (10 Go, 11 Go, 12 Go et ainsi de suite) à chaque fois que le fichier augmente.
Lorsqu'un journal de transactions est agrandi (manuellement ou par croissance automatique), il est toujours initialisé à zéro. Les fichiers de données ont le même comportement par défaut dans SQL Server 2000, mais à partir de SQL Server 2005, vous pouvez activer l'initialisation instantanée des fichiers, qui ignore l'initialisation à zéro des fichiers et rend ainsi la croissance et la croissance automatique pratiquement instantanées. Contrairement aux idées reçues, cette fonctionnalité est disponible dans toutes les éditions de SQL Server. Pour plus d'informations, entrez « initialisation instantanée des fichiers » dans l'index de la documentation en ligne de SQL Server 2005 ou SQL Server 2008.
Enfin, il convient de s'assurer que la réduction n'est pas activée. La réduction peut être utilisée pour réduire la taille d'un fichier de données ou d'un fichier journal, mais il s'agit d'un processus très intrusif sollicitant un grand nombre de ressources qui entraîne des quantités importantes de fragmentation d'analyse logique dans les fichiers de données (voir ci-dessous pour plus de détails) et se traduit par une baisse des performances. J'ai modifié l'entrée de la documentation en ligne SQL Server 2005 pour que la réduction inclue un avertissement à cet effet. Une réduction manuelle des fichiers de données et des fichiers journaux peut cependant être acceptable dans certaines circonstances.
La réduction automatique est la plus dangereuse car elle démarre toutes les 30 minutes en arrière-plan et essaie de réduire les bases de données lorsque l'option de base de données Réduction automatique est définie sur True. Il s'agit d'un processus quelque peu imprévisible car il réduit uniquement les bases de données ayant plus de 25 % d'espace disponible. La réduction automatique utilise beaucoup de ressources et entraîne une fragmentation provoquant une chute des performances, ce qui veut dire qu'il vaut mieux l'éviter en toutes circonstances. Vous devez toujours désactiver la réduction automatique à l'aide de la commande suivante :
ALTER DATABASE MyDatabase SET AUTO_SHRINK OFF;
Un plan de maintenance régulier qui inclut une commande de réduction manuelle de la base de données est presque autant déconseillé. Si vous vous rendez compte que votre base de données ne cesse de grandir après sa réduction par le plan de maintenance, c'est parce que la base de données a besoin de cet espace pour son exécution.
Le mieux est de permettre à la base de données d'atteindre une taille d'état stable et d'éviter toute réduction. Vous trouverez plus d'informations sur les inconvénients de la réduction, ainsi que des commentaires sur les nouveaux algorithmes de SQL Server 2005 sur mon vieux blog MSDN® à l'adresse blogs.msdn.com/sqlserverstorageengine/archive/tags/Shrink/default.aspx.
Fragmentation de l’index
Outre la fragmentation au niveau du système de fichiers et à l'intérieur du fichier journal, il est également possible d'avoir une fragmentation au sein des fichiers de données, dans les structures qui stockent les données de tables et d'index. Il existe deux types de fragmentation de base pouvant survenir au sein d'un fichier de données :
- La fragmentation au sein des pages de données et d'index individuelles (appelée parfois fragmentation interne)
- La fragmentation au sein des structures d'index ou de tables composées de pages (appelée fragmentation d'analyse logique et fragmentation d'analyse d'extension)
La fragmentation interne survient lorsqu'une page contient beaucoup d'espace vide. Comme l'illustre la figure 1, chaque page d'une base de données fait 8 Ko et a un en-tête de 96 octets ; par conséquent, une page peut stocker environ 8096 octets de données de tables ou d'index (vous pouvez trouver les détails spécifiques des tables et index pour les structures des données et lignes sur mon blog à l'adresse sqlskills.com/blogs/paul dans la catégorie Inside The Storage Engine). Un espace vide peut apparaître si chaque enregistrement de table ou d'index fait plus de la moitié de la taille d'une page, car dans ce cas un seul enregistrement peut être stocké par page. Ceci peut être très difficile voire impossible à corriger, car il faudrait une modification du schéma de table ou d'index, par exemple en changeant la clé d'index pour qu'elle corresponde à quelque chose qui n'entraîne pas de points d'insertion aléatoires comme le fait un GUID.
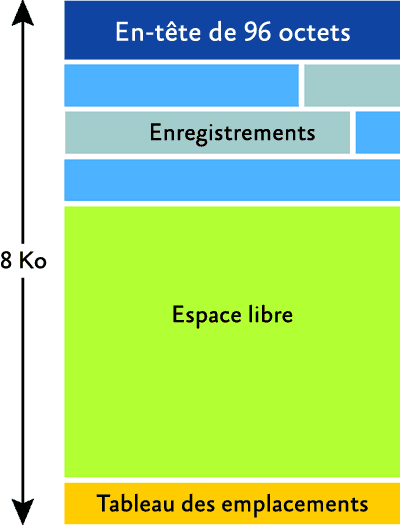
Figure 1 Structure d'une page de base de données (Cliquez sur l'image pour l'agrandir)
La fragmentation interne provient plus fréquemment de modifications des données, telles que des insertions, des mises à jour et des suppressions, qui peuvent laisser un espace vide sur une page. Un facteur de remplissage mal géré peut également contribuer à la fragmentation ; consultez la documentation en ligne pour plus de détails. Suivant le schéma de table/d'index et les caractéristiques de l'application, cet espace vide peut ne jamais être réutilisé une fois créé et peut entraîner des quantités d'espace inutilisable de plus en plus importantes dans la base de données.
Imaginons par exemple une table de 100 millions de lignes avec une taille d'enregistrement moyenne de 400 octets. Au fil du temps, le schéma de modification des données de l'application laisse en moyenne 2800 octets d'espace libre sur chaque page. L'espace total requis par la table est de 59 Go environ, calculé comme 8096-2800 / 400 = 13 enregistrements par page de 8 Ko, puis en divisant 100 millions par 13 pour obtenir le nombre de pages. Si l'espace n'était pas gaspillé, 20 enregistrements tiendraient sur chaque page, ce qui amènerait l'espace requis total à 38 Go. Ceci représente une économie énorme !
L'espace gaspillé sur des pages de données/d'index peut ainsi entraîner la nécessité de pages supplémentaires pour contenir la même quantité de données. Non seulement cela occupe davantage d'espace disque, mais cela signifie également qu'une requête doit émettre plus d'E/S pour lire la même quantité de données. Toutes ces pages supplémentaires occupent davantage d'espace dans le cache de données et utilisent par conséquent une plus grande part de la mémoire du serveur.
La fragmentation d'analyse logique est provoquée par une opération appelée « fractionnement de page ». Celle-ci survient lorsqu'un enregistrement doit être inséré sur une page d'index spécifique (selon la définition de touche clé) mais qu'il n'y a pas suffisamment d'espace sur la page pour toutes les données insérées. La page est fractionnée en deux et environ 50 % des enregistrements sont transférés sur une nouvelle page allouée. Cette nouvelle page n'est généralement pas physiquement contiguë à l'ancienne page et est donc appelée fragmentée. Le concept de fragmentation d'analyse d'extension est similaire. La fragmentation au sein des structures de tables/d'index affecte la capacité de SQL Server à réaliser des analyses efficaces, que ce soit sur l'intégralité d'une table/d'un index ou limitées par une clause WHERE de requête (telle que SELECT * FROM MyTable WHERE Column1 > 100 AND Column1 < 4000).
La figure 2 présente des pages d'index récemment créées avec un facteur de remplissage de 100 % et aucune fragmentation : les pages sont pleines et l'ordre physique des pages correspond à l'ordre logique. La figure 3 montre la fragmentation qui peut survenir après des insertions/mises à jour/suppressions aléatoires.
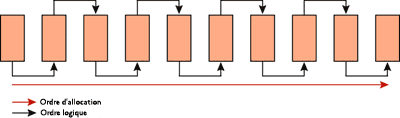
Figure 2 Nouvelles pages d'index sans fragmentation ; pages pleines à 100 % (Cliquez sur l'image pour l'agrandir)
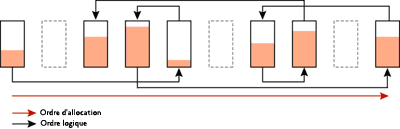
Figure 3 Pages d'index présentant une fragmentation interne et d'analyse logique après des insertions, mises à jour et suppressions aléatoires (Cliquez sur l'image pour l'agrandir)
Il est parfois possible d'empêcher la fragmentation en modifiant le schéma de table/d'index, mais comme je l'ai mentionné plus haut, cela peut être très difficile, voire impossible. S'il n'est pas possible d'empêcher la fragmentation, il existe des façons de supprimer la fragmentation une fois qu'elle est survenue, notamment en reconstruisant ou réorganisant un index.
La reconstruction d'un index nécessite la création d'une nouvelle copie de l'index (bien compactée et la plus contiguë possible), puis la suppression de l'ancien index fragmenté. Comme SQL Server crée une nouvelle copie de l'index avant de supprimer l'ancien, il a besoin d'un espace libre dans les fichiers de données à peu près équivalent à la taille de l'index. Dans SQL Server 2000, la reconstruction d'un index était toujours une opération hors connexion. Cependant, dans SQL Server 2005 Enterprise Edition, la reconstruction d'un index peut se faire en ligne, avec quelques restrictions. La réorganisation, en revanche, utilise un algorithme sur place pour compacter et défragmenter l'index ; elle nécessite uniquement 8 Ko d'espace supplémentaire pour s'exécuter, et elle s'exécute toujours en ligne. En fait, dans SQL Server 2000, j'ai spécifiquement écrit le code de réorganisation d'index comme une alternative occupant peu d'espace en ligne pour reconstruire un index.
Dans SQL Server 2005, les commandes à examiner sont ALTER INDEX … REBUILD pour reconstruire des index et ALTER INDEX … REORGANIZE pour les réorganiser. Cette syntaxe remplace respectivement les commandes DBCC DBREINDEX et DBCC INDEXDEFRAG de SQL Server 2000.
Il y a beaucoup de compromis entre ces méthodes, tels que la quantité de journalisation des transactions générée, la quantité d'espace libre dans la base de données requise et si le processus est interruptible sans perte de travail. Vous trouverez un livre blanc abordant entre autres ces compromis à l'adresse microsoft.com/technet/prodtechnol/sql/2000/maintain/ss2kidbp.mspx. Ce livre blanc s'appuie sur SQL Server 2000 mais les concepts restent valables dans les versions ultérieures.
Certains choisissent simplement de reconstruire ou réorganiser tous les index chaque soir ou chaque semaine (en utilisant par exemple une option de plan de maintenance) plutôt que de rechercher les index fragmentés et d'envisager les avantages d'une suppression de la fragmentation. Il peut s'agir d'une bonne solution pour un administrateur de base de données involontaire qui souhaite simplement mettre quelque chose en place avec le minimum d'effort, mais cela peut être un choix désastreux pour les bases de données ou systèmes plus volumineux où les ressources sont rares.
L'une des approches plus sophistiquées consiste à utiliser la vue de gestion dynamique sys.dm_db_index_physical_stats (ou DBCC SHOWCONTIG dans SQL Server 2000) pour déterminer périodiquement quels index sont fragmentés, puis à déterminer s'il convient d'y toucher et comment. Le livre blanc aborde également l'utilisation de ces choix plus ciblés. En outre, vous pouvez voir des exemples de code permettant d'effectuer ce filtrage dans l'Exemple D de l'entrée de la documentation en ligne pour la vue de gestion dynamique sys.dm_db_index_physical_stats dans SQL Server 2005 (msdn.microsoft.com/library/ms188917) ou l'exemple E de l'entrée de la documentation en ligne pour DBCC SHOWCONTIG dans SQL Server 2000 et versions ultérieures (à l'adresse msdn.microsoft.com/library/aa258803).
Quelle que soit la méthode que vous utilisez, il est vivement conseillé d'examiner et de réparer la fragmentation régulièrement.
Le Processeur de requête est la partie de SQL Server qui détermine la façon dont une requête doit être exécutée, plus précisément quels tables et index utiliser et quelles opérations réaliser sur ceux-ci pour obtenir les résultats ; c'est ce qu'on appelle un plan de requête. Certaines des entrées les plus importantes de ce processus de prise de décision sont des statistiques qui décrivent la distribution des valeurs de données pour les colonnes d'une table ou d'un index. Évidemment, les statistiques doivent être précises et à jour pour être utiles au Processeur de requête, sans quoi des plans de requêtes offrant des performances médiocres risquent d'être choisis.
Les statistiques sont générées en lisant les données de la table/l'index et en déterminant la distribution des données pour les colonnes pertinentes. Les statistiques peuvent être créées en analysant toutes les valeurs de données pour une colonne particulière (analyse complète) mais elles peuvent également se fonder sur un pourcentage spécifié par l'utilisateur des données (analyse échantillonnée). Si la distribution des valeurs dans une colonne est à peu près équilibrée, une analyse échantillonnée devrait suffire, ce qui permet une création et une mise à jour des statistiques plus rapides qu'avec une analyse complète.
Notez qu'il est possible de créer et de gérer automatiquement les statistiques en activant les options de base de données AUTO_CREATE_STATISTICS et AUTO_UPDATE_STATISTICS, comme illustré à la figure 4. Celles-ci sont activées par défaut, mais si vous venez d'hériter d'une base de données, mieux vaut vous en assurer. Il arrive que les statistiques deviennent obsolètes, auquel cas il est possible de les mettre à jour manuellement en utilisant l'opération UPDATE STATISTICS sur des jeux de statistiques spécifiques. Vous pouvez également utiliser la procédure stockée sp_updatestats, qui met à jour toutes les statistiques qui sont obsolètes (dans SQL Server 2000, sp_updatestats met à jour toutes les statistiques, quel que soit leur âge).
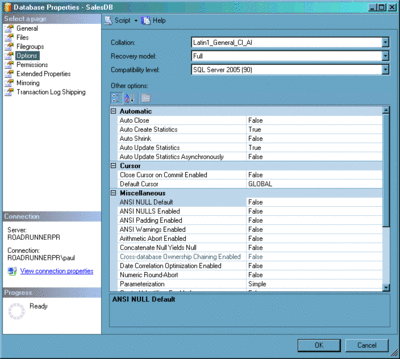
Figure 4 Modification des paramètres de bases de données via SQL Server Management Studio (Cliquez sur l'image pour l'agrandir)
Si vous souhaitez mettre à jour les statistiques dans le cadre de votre plan de maintenance habituel, il y a une chose dont vous devez être conscient. Par défaut, les options UPDATE STATISTICS et sp_updatestats utilisent le niveau d'échantillonnage spécifié précédemment (le cas échéant), ce qui peut correspondre à une analyse incomplète. Les reconstructions d'index mettent automatiquement à jour les statistiques avec une analyse complète. Si vous mettez les statistiques à jour manuellement après une reconstruction d'index, vous risquez de vous retrouver avec des statistiques moins précises ! Ceci peut arriver si une analyse échantillonnée à partir d'une mise à jour manuelle remplace l'analyse complète générée par la reconstruction d'index. En revanche, la réorganisation d'un index ne met pas du tout les statistiques à jour.
Encore une fois, beaucoup de gens ont un plan de maintenance qui met à jour toutes les statistiques à un moment donné, avant ou après la reconstruction de tous les index, et finissent ainsi par se retrouver, sans le savoir, avec des statistiques potentiellement moins précises. Si vous choisissez de reconstruire simplement tous les index de temps en temps, ces reconstructions s'occuperont aussi des statistiques. Si vous optez pour une option plus complexe avec la suppression de la fragmentation, vous devez faire de même avec la maintenance des statistiques. Voici ce que je suggère :
- Analysez les index et déterminez ceux qui doivent être traités et comment effectuer la suppression de la fragmentation.
- Pour tous les index qui n'ont pas été reconstruits, mettez les statistiques à jour.
- Mettez les statistiques à jour pour toutes les colonnes non indexées.
Pour plus d'informations sur les statistiques, consultez le livre blanc « Statistiques utilisées par l'optimiseur de requête dans Microsoft® SQL Server 2005 » (microsoft.com/technet/prodtechnol/sql/2005/qrystats.mspx).
Détection des corruptions
J'ai parlé de la maintenance liée aux performances. À présent, je veux passer à la détection et à l'atténuation des corruptions.
Il est très peu probable que la base de données que vous gérez contienne des informations totalement inutiles qui n'intéressent personne ; alors comment faites-vous pour vous assurer de l'intégrité et de la récupérabilité des données en cas de problème majeur ? Les détails de l'élaboration d'un plan de récupération après incident complet d'une stratégie de haute disponibilité n'entrent pas dans le cadre de cet article, mais il y a quelques mesures simples que vous pouvez prendre pour démarrer.
La grande majorité des corruptions sont dues au « matériel ». Pourquoi y ai-je mis des guillemets ? Eh bien, le matériel ici est vraiment un raccourci pour « quelque chose dans le sous-système d'E/S en-dessous de SQL Server ». Le sous-système d'E/S est constitué d'éléments tels que le système d'exploitation, les pilotes de système de fichiers, les pilotes de périphériques, les contrôleurs RAID, les câbles, les réseaux, et les lecteurs de disques. Cela signifie qu'il y a beaucoup d'endroits où des problèmes peuvent survenir (et surviennent).
L'un des problèmes les plus courants survient lorsqu'une panne d'électricité se produit et qu'un lecteur de disque est en train d'écrire une page de base de données. Si le lecteur ne peut pas compléter l'écriture avant de manquer d'électricité (ou que les opérations d'écriture sont mises en cache et qu'il n'y a pas assez de batterie de secours pour vider le cache du lecteur), vous risquez d'obtenir une image de page incomplète sur le disque. Ceci peut arriver parce qu'une page de base de données de 8 Ko est en fait composée de 16 secteurs de disque de 512 octets contigus. Une écriture incomplète pourrait écrire certains des secteurs de la nouvelle page mais laisser certains des secteurs de l'image de la page précédente. On parle dans ce cas de page endommagée. Comment détecter quand cela se produit ?
SQL Server est doté d'un mécanisme permettant de détecter cette situation. Il consiste à stocker quelques bits de chaque secteur de la page et à écrire un modèle spécifique à leur place (ceci se produit juste avant que la page soit écrite sur le disque). Si le modèle n'est pas le même lorsque la page est relue, SQL Server sait que la page a été « endommagée » et signale une erreur.
Dans SQL Server 2005 et les versions ultérieures, un mécanisme plus complet appelé total de contrôle de pagination est disponible pour détecter les éventuelles corruptions présentes sur une page. Celui-ci consiste à écrire un total de contrôle de pagination entier sur la page juste avant son écriture, puis de le tester lorsque la page est relue, comme pour la détection de page endommagée. Une fois les totaux de contrôle de pagination activés, la page doit être lue dans le pool de mémoires tampons, modifiée d'une façon ou d'une autre, puis réécrite sur le disque avant d'être protégée par un total de contrôle de pagination.
Il vaut donc mieux activer les totaux de contrôle de pagination pour SQL Server 2005 et les versions ultérieures et la détection de pages endommagées pour SQL Server 2000. Pour activer les totaux de contrôle de pagination, utilisez :
ALTER DATABASE MyDatabase SET PAGE_VERIFY CHECKSUM;
Pour activer la détection de pages endommagées pour SQL Server 2000, utilisez ceci :
ALTER DATABASE MyDatabase SET TORN_PAGE_DETECTION ON;
Ces mécanismes vous permettent de détecter les corruptions sur les pages, mais uniquement lorsque les pages sont lues. Comment forcer facilement la lecture de toutes les pages allouées ? La meilleure méthode pour ce faire (et pour trouver tous les autres types de corruption) consiste à utiliser la commande DBCC CHECKDB. Quelles que soient les options spécifiées, cette commande lira toujours toutes les pages de la base de données, ce qui entraîne la vérification de tous les totaux de contrôle de pagination ou de toutes les détections de pages endommagées. Vous devez également configurer des alertes pour être prévenu si des utilisateurs rencontrent des problèmes de corruption lorsqu'ils exécutent des requêtes. Vous pouvez être averti de tous les problèmes décrits ci-dessus grâce à une alerte pour les erreurs de gravité 24 (Figure 5).
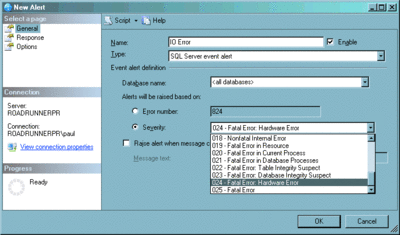
Figure 5 Configuration d'une alerte pour toutes les erreurs de gravité 24(Cliquez sur l'image pour l'agrandir)
Une autre méthode recommandée consiste à exécuter régulièrement DBCC CHECKDB sur les bases de données pour vérifier leur intégrité. Il existe de nombreuses variations de cette commande et de questions sur la fréquence d'exécution. Il n'y a malheureusement pas de livre blanc disponible sur ce sujet. Cependant, comme DBCC CHECKDB était le principal morceau de code que j'ai écrit pour SQL Server 2005, j'en ai beaucoup parlé dans mon blog. Vous trouverez dans la catégorie « CHECKDB From Every Angle » de mon blog (sqlskills.com/blogs/paul) de nombreux articles approfondis sur la vérification de la cohérence, les meilleures pratiques et des conseils concernant les procédures. Pour les administrateurs de bases de données involontaires, la règle de base est d'exécuter DBCC CHECKDB aussi souvent que vous exécutez une sauvegarde de base de données complète (vous trouverez davantage de détails à ce propos ci-dessous). Je recommande d'exécuter la commande suivante :
DBCC CHECKDB ('MyDatabase') WITH NO_INFOMSGS,
ALL_ERRORMSGS;
Si cette commande produit un résultat, c'est que DBCC a trouvé des corruptions dans la base de données. La question suivante est : que faire si DBCC CHECKDB trouve des corruptions ? C'est là qu'interviennent les sauvegardes.
Lorsqu'une corruption ou un autre incident survient, la méthode de récupération la plus efficace est la restauration de la base de données à partir de sauvegardes. Ceci suppose d'abord que vous disposez de sauvegardes et ensuite qu'elles ne sont pas corrompues. Bien trop souvent, les gens veulent savoir comment rétablir une base de données très corrompue alors qu'ils n'ont pas de sauvegarde. La réponse simple est que ne vous pouvez pas le faire, pas sans éprouver une certaine perte de données qui pourrait nuire à votre logique métier et à l'intégrité des données relationnelles.
Les sauvegardes régulières sont donc vivement recommandées. Les subtilités de l'utilisation de la sauvegarde et de la restauration n'entrent pas dans le cadre de cet article, mais permettez-moi de vous donner une introduction rapide à l'élaboration d'une stratégie de sauvegarde.
Premièrement, vous devez régulièrement réaliser des sauvegardes de bases de données complètes. Ceci vous donne un point dans le temps unique vers lequel vous pouvez effectuer la restauration ultérieurement. Vous pouvez effectuer une sauvegarde de base de données complète à l'aide de la commande BACKUP DATABASE. Consultez la documentation en ligne pour des exemples. Pour plus de protection, vous pouvez utiliser l'option AVEC TOTAL DE CONTRÔLE, qui vérifie les totaux de contrôle de pagination (le cas échéant) des pages lues et calcule un total de contrôle sur l'ensemble de la sauvegarde. Vous devez choisir une fréquence qui reflète le volume de données ou de travail que votre entreprise est prête à perdre. Ainsi, si vous effectuez une sauvegarde de base de données complète une fois par jour, vous risquez de perdre une journée de travail en cas d'incident. Si vous utilisez uniquement des sauvegardes de bases de données complètes, vous devez être dans le mode de récupération SIMPLE (appelé couramment mode de récupération) pour éviter des complexités liées à la gestion de la croissance du journal des transactions.
Deuxièmement, conservez toujours les sauvegardes pendant quelques jours au cas où l'une d'entre elles serait endommagée : une sauvegarde vieille de quelques jours vaut mieux qu'aucune sauvegarde. Vérifiez également l'intégrité de vos sauvegardes en utilisant la commande RESTORE WITH VERIFYONLY (voir la documentation en ligne). Si vous avez utilisé l'option AVEC TOTAL DE CONTRÔLE lorsque la sauvegarde a été créée, l'exécution de la commande de vérification vérifiera que le total de contrôle de la sauvegarde est toujours valide et elle revérifiera toutes les sommes de contrôle de pages des pages de la sauvegarde.
Troisièmement, si une sauvegarde de base de données complète quotidienne ne vous permet pas de satisfaire la perte de données/travail maximale que votre entreprise peut assumer, vous pouvez songer à des sauvegardes de bases de données différentielles. Une sauvegarde de base de données différentielle repose sur une sauvegarde de base de données complète et contient un enregistrement de toutes les modifications depuis la dernière sauvegarde de base de données complète (la croyance que les sauvegardes différentielles sont incrémentielles est une idée reçue : elles ne le sont pas). Exemple de stratégie : une sauvegarde de base de données quotidienne, avec une sauvegarde de base de données différentielle toutes les quatre heures. Une sauvegarde différentielle fournit un point unique supplémentaire pour l'option de récupération. Si vous utilisez uniquement des sauvegardes de bases de données complètes et différentielles, vous devez toujours utiliser le mode de récupération SIMPLE.
Pour finir, la meilleure option de récupérabilité est fournie par les sauvegardes de journaux. Celles-ci sont disponibles uniquement dans les modes de récupération COMPLÈTE (ou BULK_LOGGED) et fournissent une sauvegarde de tous les enregistrements de journaux générés depuis la sauvegarde précédente des journaux. Si vous conservez un jeu de sauvegardes de journaux avec sauvegardes de bases de données complètes périodiques (voire des sauvegardes de bases de données différentielles), vous disposez d'un nombre illimité de points dans le temps vers lesquels effectuer la récupération, y compris une récupération en temps réel. Le compromis réside dans le fait que le journal des transactions continuera de grandir à moins qu'il ne soit libéré par une sauvegarde de journal. Exemple de stratégie : une sauvegarde de base de données complète tous les jours, une sauvegarde de base de données différentielle toutes les quatre heures et une sauvegarde de journal toutes les demi-heures.
Le choix d'une stratégie de sauvegarde et sa configuration peuvent être compliqués. Il vous faut au minimum une sauvegarde de base de données complète régulière pour disposer d'au moins un point dans le temps vers lequel effectuer la récupération.
Comme vous pouvez le voir, pour garantir que votre base de données reste intègre et disponible, il y a quelques tâches indispensables. Voici ma liste de vérification finale pour un administrateur de base de données involontaire héritant d'une base de données :
- Supprimer toute fragmentation excessive du fichier journal des transactions.
- Définir la croissance automatique correctement.
- Désactiver toutes les opérations de réduction automatique planifiées.
- Activer l'initialisation instantanée des fichiers.
- Mettre en place un processus régulier pour détecter et supprimer la fragmentation d'index.
- Activer AUTO_CREATE_STATISTICS et AUTO_UPDATE_STATISTICS et prévoir un processus régulier pour la mise à jour des statistiques.
- Activer les totaux de contrôle de pagination (ou au moins la détection des pages endommagées sur SQL Server 2000).
- Avoir un processus régulier pour exécuter DBCC CHECKDB.
- Avoir un processus régulier en place pour effectuer des sauvegardes de bases de données complètes, plus des sauvegardes différentielles et de journaux pour une récupération ponctuelle.
J'ai donné des commandes T-SQL dans l'article, mais vous pouvez également faire beaucoup de chose à partir de Management Studio. J'espère vous avoir donné des astuces utiles pour une maintenance efficace des bases de données. Si vous avez des commentaires ou questions, envoyez-moi un message à l'adresse paul@sqlskills.com.
Paul S. Randal est directeur général de SQLskills.COM et MVP SQL Server. Il a travaillé sur le moteur de stockage de données de SQL Server chez Microsoft de 1999 à 2007. Paul est un spécialiste de la récupération après incident, de la haute disponibilité et de la maintenance de base de données. Vous trouverez son blog à l'adresse SQLskills.com/blogs/paul.
© 2008 Microsoft Corporation et CMP Media, LLC. Tous droits réservés. La reproduction partielle ou totale sans autorisation est interdite.