SQL Server 2008
Suivi des modifications de la base de données entreprise
Paul S. Randal
À une vue d'ensemble :
- Le besoin de suivi des modifications
- Suivi des modifications dans SQL Server 2005
- Dans SQL Server 2008 le suivi des modifications
- Modifier la capture de données dans SQL Server 2008
Contenu
Vous suivi change dans SQL Server 2005
Méthodes de plus facile à modifications dans SQL Server 2008
Comment modifier données capture Works
Comment modifier le suivi de Works
Conclusion
Pour les développeurs, un problème difficile dans SQL Server est suivi les données ont été modifiées dans une base de données.Un défi encore plu conception d'une solution simple qui doesn’t affecter fortement les performances de charge de travail et n'est pas difficile à créer, mettre en œuvre et gérer.Ainsi, pourquoi accéder à des problèmes pour suivre les modifications apportées ?Est suivi des modifications très important de cet effort ?Deux exemples souvent citées sont pour prendre en charge les mises à jour pour un entrepôt de données et prendre en charge la synchronisation de hétérogènes, il peut arriver que des systèmes connectés.
Un magasin de données possède généralement une représentation des tables dans la base de données de traitement de transactions en ligne (OLTP), mais les schémas de table peuvent être fait très différents.Cela signifie qu'il doit être un processus ETL (extraction, transformation, charge), qui déplace des données à partir de la base de données OLTP vers le magasin de données.
J'AI pouvez envisager de trois possibilités pour cela.La première consiste à actualiser périodiquement le magasin de données entière.Il s'agit clairement peu commode de volumes de données volumineuses et également signifie que les mises à jour le magasin de données n'est pas continue.La deuxième consiste pour utiliser un schéma de partitionnement dans la base de données OLTP pour permettre le processus ETL pour utiliser uniquement des données sont une nouveauté depuis le processus ETL précédent.Cette méthode fonctionne uniquement pour insérer des données, pas mises à jour ou supprime et nécessite un mécanisme complexe pour gérer définition de limite de partition et le changement de partitions.La troisième méthode consiste à suivi des modifications aux données OLTP et uniquement effectuer le processus ETL en utilisant les données modifiées.Ceci est la méthode plus efficace en termes de volume de données.
Les périphériques mobiles sont omniprésents dans l'entreprise environnement actuel, qui signifie que traitement des systèmes connectés occasionnellement est une exigence.En termes de systèmes de base de données, le problème est comment efficacement mettre à jour un magasin de données sur un périphérique qui ne se connecte pas fréquemment, en particulier lorsque stocker les données lui-même peut être petit et radicalement différentes dans le schéma de la base de données principale.
Envisagez un commercial mobile responsable d'une partie d'un catalogue de produits très volumineux.Toutes les nuits elle connecte son périphérique de poche à la base de données principale pour télécharger les dernières données, toutes les modifications à cette partie du catalogue produit simplifié pour le stockage sur un périphérique de poche.Le transfert de données doit être aussi efficace que possible.
Maintenant, vous pourriez que le système de base de données préparer la partie entière appropriée du catalogue de produits pour le téléchargement sur le périphérique et les périphériques le télécharger.En d'autres termes, les toutes les données sont téléchargées des chaque fois que le périphérique se connecte, même si les données n'a pas modifiées.C'est évidemment une approche plutôt inefficace.
Une autre approche consiste à mettre le système de base de données de suivi des modifications à la partie appropriée du catalogue produit.Ensuite, lorsque le périphérique de poche se connecte, il vous demande des données qui a été modifié depuis la dernière fois qu'il connecté.Dans cette solution, le système de base de données a uniquement préparer un sous-ensemble de données et le téléchargement est aussi efficace que possible.
Une autre raison pour le suivi des modifications est pour prendre en charge l'audit, qui est essentiel de ces jours.L'audit effectue le suivi les modifications en cours, ainsi que lorsque modifiée et qui a effectué la modification.Vraiment accédez choses à un autre niveau avec des contraintes rigide durabilité, sécurité et l'exactitude d'une piste de vérification complète.
Les technologies qui ont été conçus pour le suivi des modifications de données dans SQL Server 2008 a été pas conçus pour prendre en charge l'audit ; Toutefois, SQL Server 2008 offre une nouvelle fonctionnalité qui est appelée vérification SQL Server, qui a été conçus spécifiquement pour l'audit.Rick Byham abordé la fonctionnalité de SQL Server d'audit dans son article « SQL Server 2008 : sécurité » de la avril 2008 de TechNet Magazine (disponible àtechnet.microsoft.com/Magazine/cc434691).
Comme vous pouvez le voir, il existe un certain nombre de raisons intéressantes pour le suivi des modifications à vos données.Donc la question importante est, comment mieux suivi faire ?
Vous suivi change dans SQL Server 2005
Avec SQL Server 2005 (et versions antérieures de SQL Server) il n'est pas une simple, canned solution.Donc pour ces plates-formes, les développeurs ont dû créer des solutions personnalisées pour leurs applications impliquant généralement colonnes timestamp, les déclencheurs DML (langage de manipulation de données) et les tables supplémentaires.Ces solutions présentent toutefois, divers problèmes potentiels.Par exemple :
- L'ajout de colonnes timestamp provoque le schéma de table à modifier (avec effets knock-on possible dans les procédures stockées et tout autre code).
- Un déclencheur DML est implicitement partie de la transaction contenant le DML par lequel il est déclenché, pour son exécution augmente la longueur de la transaction.La plus complexe un déclencheur, plus nécessaire pour exécuter et donc plu l'effet négatifs sur les performances de charge de travail.Déclencheurs DML utilisées pour le suivi des modifications doivent traiter les tables insérées et supprimées à collecter toutes les modifications et les insérer dans une autre table suivi.
- Le tableau de suivi doit être exprimé en une façon d'éviter sa croissance hors de contrôle pouvant vous obliger à créer quelque chose comme un travail Agent pour découper régulièrement les anciennes données.
Méthodes de plus facile à modifications dans SQL Server 2008
SQL Server 2008 introduit deux nouvelles technologies qui facilitent grandement effectuer le suivi des modifications aux données : modifier suivi et modifier capture de données.Ces deux fonctionnalités suivre des données qui a été modifié (ainsi que des utiliser l'insertion, mise à jour ou opérations de suppression pour suivre exactement comment les données a été modifiées), et elles éliminent la nécessité pour les solutions personnalisées.Les ressemblances côté, les mécanismes et exactement leur suivre sont en fait assez différents.
Capture de données modification utilise un mécanisme asynchrone qui assure le suivi toutes les modifications qui se produisent pour une table (ou un ensemble défini de colonnes de la table), y compris la colonne valeurs eux-mêmes.Il est conçu pour les scénarios tels que le processus ETL de magasin de données décrite précédemment.
La figure 1 illustre modifient des données consommées en secteurs de temps.Le mécanisme de capture de données modification extrait les données modifiées dans un ensemble de tables, des modifications plus récentes en cours en haut de la table.Le processus ETL permet ensuite d'interroger les tables contenant les données de modification pour tous les changements qui s'est produite dans une période définie.Ce mécanisme permet le processus ETL afin de limiter la quantité de données qui doivent être consommées dans chaque lot.
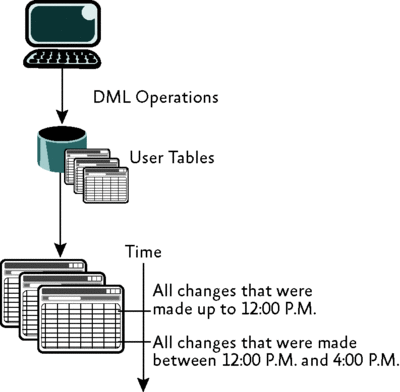
La figure 1 Historique modifier données consommées en secteurs de temps (cliquez sur l'image pour l'agrandir)
Le suivi des modifications utilise en revanche, un mécanisme de synchrone qui suit uniquement qu'une ligne particulière changé dans une table (et éventuellement la liste des colonnes modifiées).Il est conçu pour résoudre ces problèmes en tant que le scénario système occasionnellement connectées décrite précédemment.Cette approche est illustrée par la figure 2 .
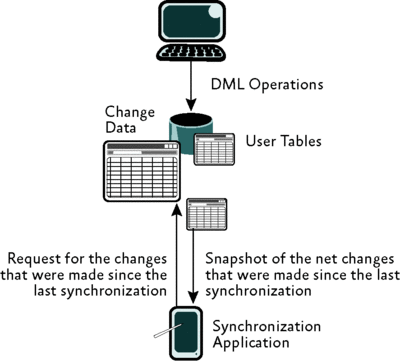
La figure 2 un système occasionnellement connectée en utilisant suivi des données des modifications (cliquez sur l'image pour l'agrandir)
Ces deux fonctionnalités introduisent une augmentation des e / S et de journalisation, mais cela est vrai avec solutions personnalisées ainsi, la modification de données doit être stockée ailleurs.Ce qui rend ces deux fonctionnalités potentiellement différente d'une solution personnalisée est que les tables utilisées pour stocker les données modification doivent être dans la même base de données en tant que les tables suivies.Cela signifie toutes les données modification sont incluses dans les sauvegardes et potentiellement transmises via le réseau par l'envoi de journaux ou la mise en miroir de base de données.
En termes de développement, ces deux fonctionnalités doivent supprimer beaucoup de la complexité de suivi des modifications.Il n'y a aucune changements de schéma de table ou des déclencheurs requis pour les deux technologies.Les technologies disposent de processus de nettoyage configurable, automatique, devient par transaction valider les heures et fournir des fonctions intégrées pour récupérer les informations de modification.
Du point de vue gestion, il et des inconvénients de chaque approche.Car avec toute technologie, il existe beaucoup d'informations, vous devez comprendre avant de développer et déployer des solutions qui utilisent ces fonctionnalités.Dans le reste de cet article je vous présentez de chacun de ces fonctionnalités, touche sur leur fonctionnement et les pratiques points à prendre en compte avant de les utiliser en production.
Comment modifier données capture Works
Capture de données modifier ne fait rien dans le cadre des transactions de modifier la table suivie.Au lieu de cela, l'insertion, mise à jour et opérations de suppression sont écrites dans le journal transactions, comme d'habitude et harvested périodiquement à partir du journal.Recueil est effectué par un travail SQL Agent journal lecteur, et les opérations harvested sont stockées dans une table distincte appelée une table de change.Ultérieurement, la table change peut être interrogée pour obtenir les données modification utilisant l'une des deux fonctions.La combinaison de la table change et deux fonctions est appelée une instance de capture.la figure 3 illustre le flux de données à l'aide de capture de données modification à un entrepôt de données processus ETL de lecteur.

L'activation de capture de données modifier est un processus en deux étape.Un membre du rôle serveur fixe sysadmin doit d'abord activer modifier capture de données de la base de données à l'aide de sys.sp_cdc_enable_db.Puis un membre du rôle serveur fixe db_owner devez activer la modification capture de données sur une table spécifique à l'aide de sys.sp_cdc_enable_table.Ces exigences de sécurité sont en raison de risque de l'utilisation du disque élevée Si modification automatisée est mal configurée.Il est judicieux parfait qu'un propriétaire de table ne peut pas activer la fonctionnalité et étonner administrateur de base de données et l'utilisation des disques supplémentaires.
Lorsque automatisée modification est activée pour une base de données, quelques éléments sont ajoutés à la base de données, y compris un nouveau schéma (appelé cdc), certaines tables de métadonnées et un déclencheur pour capturer les événements de langage de définition de données (LDD).(Une fonctionnalité qui je pense Qu'est utile fait que vous pouvez obtenez une liste des modifications DDL à un tableau.)
L'activation de capture de données modification crée également l'instance de capture de la table, la modification de table et de deux fonctions pour renvoyer modifier des données.Le nom de table modification est le même que l'instance capture, avec _CT ajouté.La première fonction est toujours créée et est celle utilisée pour renvoyer modifier des données de la table change.La deuxième fonction est créée si l'option Solde période est spécifiée.Cela signifie que seulement le résultat final des modifications capturées est renvoyé, plutôt que tous les intermédiaires modifie que la première fonction renvoie.Les fonction deux noms sont, respectivement, fn_cdc_get_all_changes_ et fn_cdc_get_net_changes_, le nom d'instance capture ajouté.Notez que (tels que la fonctionnalité de suivi modification), cette fonctionnalité nécessite le tableau possède une clé primaire ou autre index unique.
Lorsque vous vous vous traitez avec la première table dans la base de données afin d'avoir automatisée modification activée, les deux tâches SQL Agent peuvent être créés : le travail de capture et le travail de nettoyage.Je dis "peut être créé" car le travail de capture est identique à celui utilisé pour le recueil des transactions dans la réplication transactionnelle.Si réplication transactionnelle est déjà configurée, puis seulement le travail de nettoyage est créée et le travail de lecteur journal existant sera également utilisé comme le travail de capture.C'est bien parce que des deux projets de lecteur de journal très rapidement aboutirait à des problèmes de contention avec le journal et donc des problèmes de performances.Les deux cas, l'Agent SQL doit s'exécuter si vous souhaitez utiliser modification automatisée.
La logique dans le lecteur de journal copes automatiquement avec des tables est activé et désactivé pour modification données capturer et modifie les sont harvested du journal des transactions en conséquence.Un point principal à noter ici est se qu'une fois que modification automatisée est activée, le journal des transactions comporte uniquement comme avec la réplication transactionnelle, le journal ne peut pas être tronqué jusqu'à ce que le lecteur de journal a traité il.Cela signifie qu'une opération point de contrôle, même en mode de récupération SIMPLE, ne tronque pas le journal, sauf si elle a été traitée par le lecteur de journal.
En outre, si le modèle de récupération BULK_LOGGED est utilisé pour réduire la journalisation, capture de données modification force tout sont entièrement connecté, sauf pour les opérations de création/déplacement/reconstruction d'index.Si vous avez jamais rencontré ce problème, attention que cela peut entraîner transaction problèmes de taille de journal, en particulier si les valeurs par défaut de travail de capture sont modifiés pour le journal n'est pas traité comme fréquemment.
Par défaut, le travail capture exécute en continu, analyse le journal de toutes les cinq secondes et un maximum de 500 transactions dans le journal de traitement.Également par défaut, le travail de nettoyage exécute quotidiennement à 02et supprime tous les modifier entrées de données plues de trois jours dans les tables modification.Vous pouvez modifier ces paramètres à l'aide de la procédure sys.sp_cdc_change_job, et puis modifications ne prendront effet qu'après le redémarrage les tâches à l'aide sys.sp_cdc_stop_job et sys.sp_cdc_start_job.
Bien que le processus de lecteur de journal est généralement avoir un impact faible sur les performances du système, il est possible sur les systèmes OLTP très chargés avec beaucoup de modification des données que l'ajout d'un seul journal lecteur processus peut provoquer la contention sur le journal des transactions.La contention réelle serait être provoquée par les têtes de disque devoir déplacer entre le point auquel le journal est écrit dans par transactions et le point auquel il est en cours lu par le processus de lecteur du journal.Dans ce cas, il peut être nécessaire modifier la fréquence à laquelle la s'exécute travail capture afin de garantir des performances OLTP ne pas pâtir.Toutefois, crée un espace disque classique et performances commerciaux à désactiver, le journal continuera à s'agrandir jusqu'à ce que le travail capture traite.
Le même problème se produit si les nettoyage travail fréquence ou modifier données périodes de rétention sont modifiées, les tables de modification va continuer à augmenter jusqu'à ce que les données de modification sont nettoyées.Cela conduit à un compte de conception en gros de qu'obtient suivi et combien il est conservé.Les choses importantes à prendre en considération ici sont :
- La liste colonne requise pour l'instance de capture.Lorsque plus de colonnes sont capturées, plus modifient des données sont insérées dans les tables de modification.
- La quantité d'espace disque utilisé par les tables de modification.
- La fréquence à laquelle le processus s'exécute qui consomme les données de modification.N'oubliez pas que les données ne peut pas être supprimée si elle n'a pas été utilisé encore.
- La fréquence à laquelle le processus de nettoyage s'exécute, il peut y avoir afin beaucoup modifier données générées que le processus de nettoyage supprime peut être uniquement exécutée sur les jours du week-end, par exemple, car sinon, elle génère trop journal des transactions.
Capture de données modification permet de configurer pour simplement suivre toutes les modifications apportées à une table ou pour suivre un sous-ensemble des colonnes dans une table.À l'aide d'un sous-ensemble peut être utile si certains des colonnes sans importance sont varchar de nombreuses colonnes ou des colonnes d'objets volumineux binaire (BLOB) (telles que texte, image ou XML); sinon, l'espace utilisé par la table change peut croître lourd très rapidement.
Donnée la possibilité accrue de l'utilisation de l'espace disque, l'emplacement de groupe de fichiers de la table change peut être définie lorsque la capture de données modification est activée.Ainsi plus facile de gestion de l'espace disque sous-jacent et signifie que toutes les données modification peuvent potentiellement être stockées sur un volume avec un niveau RAID moins coûteux que la base de données principale.En outre, bien que les paramètres de travail de nettoyage s'appliquent à toutes les instances de capture, une instance de capture individuels peut être séparément nettoyée à tout moment si l'espace disque est un problème.Vous pouvez facilement contrôler l'utilisation d'espace du disque utilisant sp_spaceused sur les tables de capture.
La ligne réelle écrites dans la table change contient des métadonnées sur la transaction (le numéro de séquence journal validation ou numéro), ainsi que la commande dans la transaction que la modifiée, ce que l'opération a, un masque binaire dont les colonnes ont été modifiées, et les valeurs de colonne réel.
Les modifications DDL sont non restreinte modifier automatisée est activé.Toutefois, ils peuvent avoir des effet des données modification collectées si les colonnes sont ajoutés ou supprimés.Si une colonne de suivi est supprimée, toutes les écritures supplémentaires dans l'instance de capture ont NULL pour cette colonne.Si une colonne est ajoutée, il va être ignoré par l'instance de capture.Autrement dit, la forme de l'instance de capture est définie lorsqu'elle est créée.
Si des modifications de colonne sont nécessaires, il est possible créer une autre instance de capture d'une table (à un maximum de capture deux instances par table) et permettre des consommateurs de modifient des données à migrer vers le nouveau schéma de table.Mais attention doit être prises lorsque vous effectuez cela parce que deux instances de capture d'une table suivie signifie que deux fois la quantité de l'espace disque, e / S et la journalisation.
Sans entrer dans trop profondeur, modifications sont extraites les tables de modifier l'utilisation des fonctions que j'ai décrites.Les fonctions de prennent un enregistrement de démarrage et fin numéro et il autres fonctions fourni par qui vous permettent de convertir une heure standard en un enregistrement.Lors de la récupération des mises à jour, vous pouvez même spécifier si vous souhaitez voir l'avant et après les valeurs ou simplement l'avant.Il existe un screencast de moi à l'aide modification automatisée disponible àwww.technetmagazine.com/Video.
Comment modifier le suivi de Works
Comme je L'AI avons mentionné, suivi des modifications est un processus synchrone et est beaucoup moins complexe que modifier capture de données.Il fait partie de la transaction qui apporte une modification à une ligne dans une table suivi est activée, et le fait que la ligne a été modifié est suivi dans une table distincte.La table est ce qui est appelée une table interne et il n'est aucun contrôle sur son nom ou où il est stocké.JE ne considère cette un problème, qu'il doit être beaucoup moins de données dans cette table que dans une table modifier utilisée pour la capture de données modifier.Mais il peut toujours être des problèmes d'espace disque, comme je vais vous expliquer dans un instant.
Le fait que le suivi des modifications s'effectue de façon synchrone signifie qu'il y a traitement supplémentaire effectué dans chaque transaction qui modifie la table suivie.L'effet sur les performances est similaire à que lorsqu'un index non clusterisé existe dans la table et doivent être mises à jour avec chaque modification à la table.Transactions elles-mêmes font l'objet d'un également suivies lorsque leur validation à une ligne de la table sys.syscommittab interne.
Suivi des modifications est activé et désactivé à l'aide normal ALTER DATABASE et syntaxe ALTER TABLE, ainsi il suit le même modèle en tant que capture de données modification, où il doit être activé au niveau de base de données avant de niveau table.La séquence des opérations serait ressembler à ceci :
ALTER DATABASE AdventureWorks2000 SET CHANGE_TRACKING = ON
(CHANGE_RETENTION = 2 DAYS, AUTO_CLEANUP = ON);
GO
USE AdventureWorks2000;
GO
ALTER TABLE Person.Person ENABLE CHANGE_TRACKING
WITH (TRACK_COLUMNS_UPDATED = ON);
GO
Les autorisations requises pour activer modifier suivi à la base de données et niveaux de table est également différentes de celles pour permettre la capture de données modification : db_owner et le propriétaire de la table, respectivement. Lorsque le suivi des modifications est activé au niveau base de données, la période de rétention peut être définie, ainsi que si modifient des données sont automatiquement nettoyées. La période de rétention par défaut est 2 jours, avec un maximum de 90 jours et un minimum d'une minute.
Nettoyage automatique est également activé par défaut. Lorsque vous modifiez ces paramètres, vous devez évaluer les mêmes compromis comme J'AI expliqué avec modification automatisée, essentiellement disque espace et les performances par rapport aux besoins de l'application.
Par défaut, ce qui est capturé pour chaque ligne est simplement qu'il modifié. Pour ce faire, effectuer une note de la clé primaire de la ligne modifiée (qui signifie que le suivi d'une table des modifications nécessite qu'il possède une clé primaire), ainsi qu'ayant un numéro de version (dès qu'une base de données est activée pour modification suivi, un numéro de version est définie, qui permet de commander des opérations) et le type d'opération qui a effectué la modification. Vous pouvez également la possibilité suivre les colonnes modifiées ; cela requiert 4 octets par colonne modifiée.
Surveillance d'espace disque est légèrement différente avec modification suivi, étant donné que les données de modification sont stockées dans les tables internes. Pour connaître le nom des tables internes utilisés, utilisez simplement la vue de catalogue sys.internal_tables système :
SELECT [name] FROM sys.internal_tables
WHERE [internal_type_desc] = 'CHANGE_TRACKING';
GO
Puis passez le nom en sp_spaceused pour voir quelle quantité d'espace disque est en cours utilisé.
Contrairement avec modification capture de données, lorsque le suivi des modifications est activé, il existe restrictions sur le script DDL qui peuvent être effectuées sur une table suivie. La restriction plus notable est que la clé primaire ne peut pas être modifiée dans aucune façon. La autre restriction important appel des ici est qu'un commutateur de TABLE ALTER échouera si soit table impliquée a suivi des modifications activé. Ceci est probablement dû au fait qu'il n'est pas judicieux démarrer automatiquement ou supprimer suivi des modifications pour une partition est basculée hors d'un changement de suivi, table partitionnée ou une table de suivi de modification est passé dans une table partitionnée, respectivement.
Modifications apportées sont extraites les tables de modification interne utilisez une nouvelle fonction CHANGETABLES (modification …). Cela accepte le nom de la table suivi change plus le nombre version entre le moment précédent, il a été utilisé et renvoie des informations sur toutes les lignes qui ont été modifiés depuis cette période précédente. Il existe diverses fonctions pour rechercher la version valide actuelle et plus ancienne. L'application peut utiliser les informations qui sont renvoyées pour interroger la table en cours de modification suivie pour obtenir les valeurs colonne réel. Ceci, bien entendu, est un processus multi-step — vous obtenir la version actuelle, utiliser cette version à modification de requête de suivi et requête puis les tables réels pour les données de colonne correspondant à cette version.
Sur un système changent constamment, il est possible d'obtenir des résultats incohérentes ou incorrects, sauf si un type de vue invariable de la version, modifier des données et données des colonnes réel sont conservées. Pour ce faire, vous pouvez utiliser l'isolement de capture instantanée et encapsuler le processus multi-step dans une transaction explicite. Cela fonctionne bien, mais présente les inconvénients potentiels. Isolement de capture instantanée peut affecter les performances charge de travail, et elle affecte les performances et l'utilisation de l'espace de tempdb. Vous trouverez plus d'informations sur ce à technet.microsoft.com/library/cc280358.
Conclusion
figure 4 fournit une comparaison côte à côte de modifient suivi et la modification des données afin de vous pouvez avoir une meilleure idée des principales différences DBAs s'intéresse. Vous constatez de la table que modification automatisée est beaucoup plus lourd poids de suivi des modifications. Elle nécessite plus d'attention lorsque vous décidez de procédure à suivre en raison de risque de croissance rapide de la taille de la table suivi si, par exemple, la table qui est suivie contient des colonnes BLOB ou des lignes très large. Il est également le risque de transaction journal Gestion des problèmes, car le journal ne sera pas tronqué jusqu'à ce que le lecteur de journal a harvested enregistrements à partir du journal.
La figure 4 comparaison entre modifier suivi et modifier capture de données
| Fonction | Modifier le suivi | Modifier la capture de données |
|---|---|---|
| Synchrone | Oui | Non |
| Nécessite l'agent SQL | Non | Oui |
| Opérations en bloc les force complète de journalisation des | Non | Oui |
| Empêche la troncature des journaux | Non | Oui, jusqu'à ce que harvested des enregistrements du journal |
| Nécessite l'isolement de capture instantanée | Recommandé | Non |
| Nécessite des tables distinctes pour stocker les données de suivi | Oui | Oui |
| Nécessite la clé primaire | Oui | Pas par défaut |
| Permet de sélection élective de suivi des tables | Non | Oui |
| Risque de problèmes de consommation d'espace | Certains | Lots |
| Processus de nettoyage automatique | Oui | Oui |
| Restrictions sur DDL | Oui | Non |
| Autorisation nécessaire pour activer | Sysadmin | Propriétaire de la base de données |
Suivi des modifications ne sont pas sans ses propres exigences, cependant. Par exemple, une clé primaire est obligatoire et il est fortement recommandé d'utiliser l'isolement de capture instantanée lorsque le suivi des modifications est activé. Isolement de capture instantanée lui-même pouvez ajouter des surcharges de charge importante et nécessite beaucoup plus prudent de gestion de tempdb.
Il existe un problème supplémentaire qui DBAs et les développeurs doivent faire face : la récupération après incident. Même si cette étude en profondeur est abordée dans cet article, le sujet de la récupération après incident est trop important de ne préciser pas moins ici.
Ces deux fonctionnalités lire avec BACKUP et RESTORE. Le problème est lorsqu'une base de données obtient restauré et est utilisé essentiellement en dans le temps. Comment l'application globale/système doit comportement ? Des solutions personnalisées conçues pour le suivi des modifications face également ce problème, et il doit toujours prendre en considération lors de l'aide de SQL Server 2008.
Comme toujours, assurez-vous que vous lisez tout (la documentation disponible technet.microsoft.com/library/bb418491) et les blancs existants avant entrepris sur un projet conception et déploiement qui implique les nouvelles fonctionnalités pour suivre les modifications apportées. Vous devez tout d'abord savoir si les problèmes potentiels n'ont pas j'abordé ici peuvent s'appliquent à vous. Vous devez également obtenir des détails sur la nouvelle SP surveillance et les vues de gestion dynamique (DMV).
Global ces nouvelles fonctionnalités sont une avance énorme sur les méthodes précédentes pour le suivi des modifications de données. Maintenant qu'elles existent, vous pouvez être sûr développeurs devez les utiliser dans les solutions que vous gérez.
Il existe configuration importante et des problèmes de gestion à prendre en considération, et j'espère que cet article a donné un aperçu plein des technologies afin de pouvoir anticiper et préparer pour certains problèmes que j'ai abordé. Si vous avez des commentaires sur cet article ou des questions, poursuivez et me déplacer une ligne à Paul@SQLskills.com.
S Paul Randal est le directeur Gestion de SQLskills.comet un MVP de SQL Server. Il a travaillé dans l'équipe SQL Server Storage Engine chez Microsoft de 1999 à 2007. Paul écrit DBCC CHECKDB/réparation pour SQL Server 2005 et était responsable pour le moteur de stockage base pendant le développement de SQL Server 2008. Paul est un expert de la récupération après incident, haute disponibilité et la maintenance de base de données et un présentateur standard à des conférences dans le monde entier. Blogs il à SQLskills.com/blogs/paul.